Data manipulation and visualization
tidyverse: dplyr, tidyr, ggplot2
02.02.2017
1.1 Data Types
## [1] 42 99 43
matrix(1:12, nrow=3,ncol=4)
## [,1] [,2] [,3] [,4]
## [1,] 1 4 7 10
## [2,] 2 5 8 11
## [3,] 3 6 9 12
list(
n_lectures = 12,
l_topics = c("begining", "data manipulation", "descriptive stats"),
h_topics = c("data manipulations", "descriptive stats")
)
## $n_lectures
## [1] 12
##
## $l_topics
## [1] "begining" "data manipulation" "descriptive stats"
##
## $h_topics
## [1] "data manipulations" "descriptive stats"
data.frame(
names = c("Olya", "Ilya", "Sasha", "George"),
lecturer = c(TRUE, TRUE, FALSE, TRUE),
lecturer_experience = c(19, 6, 0, 3)
)
| Olya |
TRUE |
19 |
| Ilya |
TRUE |
6 |
| Sasha |
FALSE |
0 |
| George |
TRUE |
3 |
See Data Type Conversion page
1.2 Data Frame exploration
There are some embedded data frames (e. g. mtcars, cars, iris). How many rows and columns?
nrow(iris) # returns the number of rows
## [1] 150
ncol(mtcars) # returns the number of columns
## [1] 11
head(cars) # returns the first 6 rows
| 4 |
2 |
| 4 |
10 |
| 7 |
4 |
| 7 |
22 |
| 8 |
16 |
| 9 |
10 |
head(cars, 4) # returns the first 4 rows
tail(cars) # returns the last 6 rows
| 45 |
23 |
54 |
| 46 |
24 |
70 |
| 47 |
24 |
92 |
| 48 |
24 |
93 |
| 49 |
24 |
120 |
| 50 |
25 |
85 |
summary(cars) # produce some stats
## speed dist
## Min. : 4.0 Min. : 2.00
## 1st Qu.:12.0 1st Qu.: 26.00
## Median :15.0 Median : 36.00
## Mean :15.4 Mean : 42.98
## 3rd Qu.:19.0 3rd Qu.: 56.00
## Max. :25.0 Max. :120.00
str(cars) # shows the structure: variables, their type
## 'data.frame': 50 obs. of 2 variables:
## $ speed: num 4 4 7 7 8 9 10 10 10 11 ...
## $ dist : num 2 10 4 22 16 10 18 26 34 17 ...
1.3 Data Frame Indexing
mtcars$mpg # shows the mpg vector
## [1] 21.0 21.0 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 17.8 16.4 17.3 15.2
## [15] 10.4 10.4 14.7 32.4 30.4 33.9 21.5 15.5 15.2 13.3 19.2 27.3 26.0 30.4
## [29] 15.8 19.7 15.0 21.4
mtcars[3,7] # shows the 3. row, 7. column
## [1] 18.61
mtcars[3,] # shows the 3. row
| Datsun 710 |
22.8 |
4 |
108 |
93 |
3.85 |
2.32 |
18.61 |
1 |
1 |
4 |
1 |
mtcars[,7] # shows the 7. column
## [1] 16.46 17.02 18.61 19.44 17.02 20.22 15.84 20.00 22.90 18.30 18.90
## [12] 17.40 17.60 18.00 17.98 17.82 17.42 19.47 18.52 19.90 20.01 16.87
## [23] 17.30 15.41 17.05 18.90 16.70 16.90 14.50 15.50 14.60 18.60
mtcars[mtcars$mpg < 20, ] # show all rows with the mpg value lower then 20
| Hornet Sportabout |
18.7 |
8 |
360.0 |
175 |
3.15 |
3.440 |
17.02 |
0 |
0 |
3 |
2 |
| Valiant |
18.1 |
6 |
225.0 |
105 |
2.76 |
3.460 |
20.22 |
1 |
0 |
3 |
1 |
| Duster 360 |
14.3 |
8 |
360.0 |
245 |
3.21 |
3.570 |
15.84 |
0 |
0 |
3 |
4 |
| Merc 280 |
19.2 |
6 |
167.6 |
123 |
3.92 |
3.440 |
18.30 |
1 |
0 |
4 |
4 |
| Merc 280C |
17.8 |
6 |
167.6 |
123 |
3.92 |
3.440 |
18.90 |
1 |
0 |
4 |
4 |
| Merc 450SE |
16.4 |
8 |
275.8 |
180 |
3.07 |
4.070 |
17.40 |
0 |
0 |
3 |
3 |
| Merc 450SL |
17.3 |
8 |
275.8 |
180 |
3.07 |
3.730 |
17.60 |
0 |
0 |
3 |
3 |
| Merc 450SLC |
15.2 |
8 |
275.8 |
180 |
3.07 |
3.780 |
18.00 |
0 |
0 |
3 |
3 |
| Cadillac Fleetwood |
10.4 |
8 |
472.0 |
205 |
2.93 |
5.250 |
17.98 |
0 |
0 |
3 |
4 |
| Lincoln Continental |
10.4 |
8 |
460.0 |
215 |
3.00 |
5.424 |
17.82 |
0 |
0 |
3 |
4 |
| Chrysler Imperial |
14.7 |
8 |
440.0 |
230 |
3.23 |
5.345 |
17.42 |
0 |
0 |
3 |
4 |
| Dodge Challenger |
15.5 |
8 |
318.0 |
150 |
2.76 |
3.520 |
16.87 |
0 |
0 |
3 |
2 |
| AMC Javelin |
15.2 |
8 |
304.0 |
150 |
3.15 |
3.435 |
17.30 |
0 |
0 |
3 |
2 |
| Camaro Z28 |
13.3 |
8 |
350.0 |
245 |
3.73 |
3.840 |
15.41 |
0 |
0 |
3 |
4 |
| Pontiac Firebird |
19.2 |
8 |
400.0 |
175 |
3.08 |
3.845 |
17.05 |
0 |
0 |
3 |
2 |
| Ford Pantera L |
15.8 |
8 |
351.0 |
264 |
4.22 |
3.170 |
14.50 |
0 |
1 |
5 |
4 |
| Ferrari Dino |
19.7 |
6 |
145.0 |
175 |
3.62 |
2.770 |
15.50 |
0 |
1 |
5 |
6 |
| Maserati Bora |
15.0 |
8 |
301.0 |
335 |
3.54 |
3.570 |
14.60 |
0 |
1 |
5 |
8 |
2. Tidyverse
The tidyverse is a set of packages:
- dplyr, for data manipulation
- ggplot2, for data visualisation
- tidyr, for data tidying
- readr, for data import
- purrr, for functional programming
- tibble, for tibbles, a modern re-imagining of data frames
Install tidyverse package using install.packages(“tidyverse”)
Load tidyverse package
In this presentation the folowing version of tideverse, dplyr and ggplot2 are used:
packageVersion("tidyverse")
## [1] '1.1.1'
## [1] '0.7.2'
packageVersion("ggplot2")
## [1] '2.2.1'
3.1 Join dataframe by row or column
my_data_1 <- mtcars[5:20,] # select a subset of mtcars
my_data_2 <- mtcars[17:29,] # select a subset of mtcars
combine_rows <- rbind.data.frame(my_data_1, my_data_2)
nrow(my_data_1); nrow(my_data_2); nrow(combine_rows)
## [1] 16
## [1] 13
## [1] 29
my_data_3 <- mtcars[,3:7] # select a subset of mtcars
my_data_4 <- mtcars[,6:11] # select a subset of mtcars
combine_cols <- cbind.data.frame(my_data_3, my_data_4)
ncol(my_data_3); ncol(my_data_4); ncol(combine_cols)
## [1] 5
## [1] 6
## [1] 11
3.2 Joins (dplyr)
languages <- data.frame(
languages = c("Selkup", "French", "Chukchi", "Kashubian"),
countries = c("Russia", "France", "Russia", "Poland"),
iso = c("sel", "fra", "ckt", "pol")
)
languages
| Selkup |
Russia |
sel |
| French |
France |
fra |
| Chukchi |
Russia |
ckt |
| Kashubian |
Poland |
pol |
country_population <- data.frame(
countries = c("Russia", "Poland", "Finland"),
population_mln = c(143, 38, 5))
country_population
| Russia |
143 |
| Poland |
38 |
| Finland |
5 |
inner_join(languages, country_population)
## Joining, by = "countries"
## Warning: Column `countries` joining factors with different levels, coercing
## to character vector
| Selkup |
Russia |
sel |
143 |
| Chukchi |
Russia |
ckt |
143 |
| Kashubian |
Poland |
pol |
38 |
left_join(languages, country_population)
## Joining, by = "countries"
## Warning: Column `countries` joining factors with different levels, coercing
## to character vector
| Selkup |
Russia |
sel |
143 |
| French |
France |
fra |
NA |
| Chukchi |
Russia |
ckt |
143 |
| Kashubian |
Poland |
pol |
38 |
right_join(languages, country_population)
## Joining, by = "countries"
## Warning: Column `countries` joining factors with different levels, coercing
## to character vector
| Selkup |
Russia |
sel |
143 |
| Chukchi |
Russia |
ckt |
143 |
| Kashubian |
Poland |
pol |
38 |
| NA |
Finland |
NA |
5 |
anti_join(languages, country_population)
## Joining, by = "countries"
## Warning: Column `countries` joining factors with different levels, coercing
## to character vector
anti_join(country_population, languages)
## Joining, by = "countries"
## Warning: Column `countries` joining factors with different levels, coercing
## to character vector
full_join(country_population, languages)
## Joining, by = "countries"
## Warning: Column `countries` joining factors with different levels, coercing
## to character vector
| Russia |
143 |
Selkup |
sel |
| Russia |
143 |
Chukchi |
ckt |
| Poland |
38 |
Kashubian |
pol |
| Finland |
5 |
NA |
NA |
| France |
NA |
French |
fra |
3.3 Data
The majority of examples in that presentation are based on Chi-kuk 2007. Experiment consisted of a perception and judgment test aimed at measuring the correlation between acoustic cues and perceived sexual orientation. Naïve Cantonese speakers were asked to listen to the Cantonese speech samples collected in Experiment and judge whether the speakers were gay or heterosexual. There are 14 speakers and following parameters:
- [s] duration (s.duration.ms)
- vowel duration (vowel.duration.ms)
- fundamental frequencies mean (F0) (average.f0.Hz)
- fundamental frequencies range (f0.range.Hz)
- percentage of homosexual impression (perceived.as.homo)
- percentage of heterosexal impression (perceived.as.hetero)
- speakers orientation (orientation)
- speakers age (age)
Download data
homo <- read.csv("http://goo.gl/Zjr9aF")
homo
| A |
61.40 |
112.60 |
119.51 |
52.5 |
7 |
18 |
0.28 |
hetero |
30 |
| B |
63.90 |
126.49 |
100.29 |
114.0 |
20 |
5 |
0.80 |
hetero |
19 |
| C |
55.08 |
126.81 |
114.90 |
103.2 |
9 |
16 |
0.36 |
homo |
29 |
| D |
78.11 |
119.17 |
126.61 |
58.8 |
15 |
10 |
0.60 |
homo |
36 |
| E |
64.71 |
93.68 |
130.76 |
37.4 |
10 |
15 |
0.40 |
homo |
27 |
| F |
67.00 |
127.87 |
150.79 |
42.0 |
17 |
8 |
0.68 |
homo |
33 |
| G |
65.39 |
147.52 |
128.96 |
118.2 |
20 |
5 |
0.80 |
hetero |
28 |
| H |
62.46 |
120.13 |
105.26 |
55.7 |
21 |
4 |
0.84 |
hetero |
22 |
| I |
60.45 |
140.44 |
109.86 |
96.4 |
20 |
5 |
0.80 |
homo |
22 |
| J |
59.59 |
121.01 |
123.90 |
111.7 |
8 |
17 |
0.32 |
homo |
40 |
| K |
62.94 |
137.37 |
119.48 |
87.6 |
21 |
4 |
0.84 |
homo |
30 |
| L |
53.31 |
112.05 |
146.20 |
57.8 |
8 |
17 |
0.32 |
hetero |
25 |
| M |
45.13 |
133.74 |
155.34 |
100.5 |
9 |
16 |
0.36 |
hetero |
20 |
| N |
57.67 |
118.02 |
121.48 |
37.4 |
4 |
21 |
0.16 |
hetero |
29 |
3.4 Data Frame → Tibble (dplyr)
Tibble is a useful modification of Data Frame.
library(tidyverse)
homo <- tbl_df(homo)
homo
| A |
61.40 |
112.60 |
119.51 |
52.5 |
7 |
18 |
0.28 |
hetero |
30 |
| B |
63.90 |
126.49 |
100.29 |
114.0 |
20 |
5 |
0.80 |
hetero |
19 |
| C |
55.08 |
126.81 |
114.90 |
103.2 |
9 |
16 |
0.36 |
homo |
29 |
| D |
78.11 |
119.17 |
126.61 |
58.8 |
15 |
10 |
0.60 |
homo |
36 |
| E |
64.71 |
93.68 |
130.76 |
37.4 |
10 |
15 |
0.40 |
homo |
27 |
| F |
67.00 |
127.87 |
150.79 |
42.0 |
17 |
8 |
0.68 |
homo |
33 |
| G |
65.39 |
147.52 |
128.96 |
118.2 |
20 |
5 |
0.80 |
hetero |
28 |
| H |
62.46 |
120.13 |
105.26 |
55.7 |
21 |
4 |
0.84 |
hetero |
22 |
| I |
60.45 |
140.44 |
109.86 |
96.4 |
20 |
5 |
0.80 |
homo |
22 |
| J |
59.59 |
121.01 |
123.90 |
111.7 |
8 |
17 |
0.32 |
homo |
40 |
| K |
62.94 |
137.37 |
119.48 |
87.6 |
21 |
4 |
0.84 |
homo |
30 |
| L |
53.31 |
112.05 |
146.20 |
57.8 |
8 |
17 |
0.32 |
hetero |
25 |
| M |
45.13 |
133.74 |
155.34 |
100.5 |
9 |
16 |
0.36 |
hetero |
20 |
| N |
57.67 |
118.02 |
121.48 |
37.4 |
4 |
21 |
0.16 |
hetero |
29 |
3.5 Filter (dplyr)
How many speakers are older than 28?
| A |
61.40 |
112.60 |
119.51 |
52.5 |
7 |
18 |
0.28 |
hetero |
30 |
| C |
55.08 |
126.81 |
114.90 |
103.2 |
9 |
16 |
0.36 |
homo |
29 |
| D |
78.11 |
119.17 |
126.61 |
58.8 |
15 |
10 |
0.60 |
homo |
36 |
| F |
67.00 |
127.87 |
150.79 |
42.0 |
17 |
8 |
0.68 |
homo |
33 |
| J |
59.59 |
121.01 |
123.90 |
111.7 |
8 |
17 |
0.32 |
homo |
40 |
| K |
62.94 |
137.37 |
119.48 |
87.6 |
21 |
4 |
0.84 |
homo |
30 |
| N |
57.67 |
118.02 |
121.48 |
37.4 |
4 |
21 |
0.16 |
hetero |
29 |
homo %>%
filter(age > 28, s.duration.ms < 60)
| C |
55.08 |
126.81 |
114.90 |
103.2 |
9 |
16 |
0.36 |
homo |
29 |
| J |
59.59 |
121.01 |
123.90 |
111.7 |
8 |
17 |
0.32 |
homo |
40 |
| N |
57.67 |
118.02 |
121.48 |
37.4 |
4 |
21 |
0.16 |
hetero |
29 |
%>% is called pipe. Pipe is a technique for passing result of the work of one function to another.
sort(sqrt(abs(sin(1:22))), decreasing = TRUE)
## [1] 0.9999951 0.9952926 0.9946649 0.9805088 0.9792468 0.9554817 0.9535709
## [8] 0.9173173 0.9146888 0.8699440 0.8665952 0.8105471 0.8064043 0.7375779
## [15] 0.7325114 0.6482029 0.6419646 0.5365662 0.5285977 0.3871398 0.3756594
## [22] 0.0940814
1:22 %>%
sin() %>%
abs() %>%
sqrt() %>%
sort(., decreasing = TRUE) # dot here shows where should argument be
## [1] 0.9999951 0.9952926 0.9946649 0.9805088 0.9792468 0.9554817 0.9535709
## [8] 0.9173173 0.9146888 0.8699440 0.8665952 0.8105471 0.8064043 0.7375779
## [15] 0.7325114 0.6482029 0.6419646 0.5365662 0.5285977 0.3871398 0.3756594
## [22] 0.0940814
Pipes in tidyverse package came from magritr package. Sometimes it works incorrectly with not tidyverse functions.
3.6 Slice (dplyr)
| C |
55.08 |
126.81 |
114.90 |
103.2 |
9 |
16 |
0.36 |
homo |
29 |
| D |
78.11 |
119.17 |
126.61 |
58.8 |
15 |
10 |
0.60 |
homo |
36 |
| E |
64.71 |
93.68 |
130.76 |
37.4 |
10 |
15 |
0.40 |
homo |
27 |
| F |
67.00 |
127.87 |
150.79 |
42.0 |
17 |
8 |
0.68 |
homo |
33 |
| G |
65.39 |
147.52 |
128.96 |
118.2 |
20 |
5 |
0.80 |
hetero |
28 |
| C |
55.08 |
126.81 |
114.90 |
103.2 |
9 |
16 |
0.36 |
homo |
29 |
| D |
78.11 |
119.17 |
126.61 |
58.8 |
15 |
10 |
0.60 |
homo |
36 |
| E |
64.71 |
93.68 |
130.76 |
37.4 |
10 |
15 |
0.40 |
homo |
27 |
| F |
67.00 |
127.87 |
150.79 |
42.0 |
17 |
8 |
0.68 |
homo |
33 |
| G |
65.39 |
147.52 |
128.96 |
118.2 |
20 |
5 |
0.80 |
hetero |
28 |
3.7 Select (dplyr)
| 0.28 |
hetero |
30 |
| 0.80 |
hetero |
19 |
| 0.36 |
homo |
29 |
| 0.60 |
homo |
36 |
| 0.40 |
homo |
27 |
| 0.68 |
homo |
33 |
| 0.80 |
hetero |
28 |
| 0.84 |
hetero |
22 |
| 0.80 |
homo |
22 |
| 0.32 |
homo |
40 |
| 0.84 |
homo |
30 |
| 0.32 |
hetero |
25 |
| 0.36 |
hetero |
20 |
| 0.16 |
hetero |
29 |
| 0.28 |
hetero |
30 |
| 0.80 |
hetero |
19 |
| 0.36 |
homo |
29 |
| 0.60 |
homo |
36 |
| 0.40 |
homo |
27 |
| 0.68 |
homo |
33 |
| 0.80 |
hetero |
28 |
| 0.84 |
hetero |
22 |
| 0.80 |
homo |
22 |
| 0.32 |
homo |
40 |
| 0.84 |
homo |
30 |
| 0.32 |
hetero |
25 |
| 0.36 |
hetero |
20 |
| 0.16 |
hetero |
29 |
homo %>%
select(speaker:average.f0.Hz)
| A |
61.40 |
112.60 |
119.51 |
| B |
63.90 |
126.49 |
100.29 |
| C |
55.08 |
126.81 |
114.90 |
| D |
78.11 |
119.17 |
126.61 |
| E |
64.71 |
93.68 |
130.76 |
| F |
67.00 |
127.87 |
150.79 |
| G |
65.39 |
147.52 |
128.96 |
| H |
62.46 |
120.13 |
105.26 |
| I |
60.45 |
140.44 |
109.86 |
| J |
59.59 |
121.01 |
123.90 |
| K |
62.94 |
137.37 |
119.48 |
| L |
53.31 |
112.05 |
146.20 |
| M |
45.13 |
133.74 |
155.34 |
| N |
57.67 |
118.02 |
121.48 |
It is possible to use select() function to remove columns:
homo %>%
select(-c(speaker, perceived.as.hetero, perceived.as.homo, perceived.as.homo.percent))
| 61.40 |
112.60 |
119.51 |
52.5 |
hetero |
30 |
| 63.90 |
126.49 |
100.29 |
114.0 |
hetero |
19 |
| 55.08 |
126.81 |
114.90 |
103.2 |
homo |
29 |
| 78.11 |
119.17 |
126.61 |
58.8 |
homo |
36 |
| 64.71 |
93.68 |
130.76 |
37.4 |
homo |
27 |
| 67.00 |
127.87 |
150.79 |
42.0 |
homo |
33 |
| 65.39 |
147.52 |
128.96 |
118.2 |
hetero |
28 |
| 62.46 |
120.13 |
105.26 |
55.7 |
hetero |
22 |
| 60.45 |
140.44 |
109.86 |
96.4 |
homo |
22 |
| 59.59 |
121.01 |
123.90 |
111.7 |
homo |
40 |
| 62.94 |
137.37 |
119.48 |
87.6 |
homo |
30 |
| 53.31 |
112.05 |
146.20 |
57.8 |
hetero |
25 |
| 45.13 |
133.74 |
155.34 |
100.5 |
hetero |
20 |
| 57.67 |
118.02 |
121.48 |
37.4 |
hetero |
29 |
# When you want to remove one column you can write it without
# c() function, e. g. -speaker
It is possible to reorder columns using select() function:
homo %>%
select(speaker, age, s.duration.ms)
| A |
30 |
61.40 |
| B |
19 |
63.90 |
| C |
29 |
55.08 |
| D |
36 |
78.11 |
| E |
27 |
64.71 |
| F |
33 |
67.00 |
| G |
28 |
65.39 |
| H |
22 |
62.46 |
| I |
22 |
60.45 |
| J |
40 |
59.59 |
| K |
30 |
62.94 |
| L |
25 |
53.31 |
| M |
20 |
45.13 |
| N |
29 |
57.67 |
3.8 arrange (dplyr)
homo[order(homo$orientation, homo$age), ]
| B |
63.90 |
126.49 |
100.29 |
114.0 |
20 |
5 |
0.80 |
hetero |
19 |
| M |
45.13 |
133.74 |
155.34 |
100.5 |
9 |
16 |
0.36 |
hetero |
20 |
| H |
62.46 |
120.13 |
105.26 |
55.7 |
21 |
4 |
0.84 |
hetero |
22 |
| L |
53.31 |
112.05 |
146.20 |
57.8 |
8 |
17 |
0.32 |
hetero |
25 |
| G |
65.39 |
147.52 |
128.96 |
118.2 |
20 |
5 |
0.80 |
hetero |
28 |
| N |
57.67 |
118.02 |
121.48 |
37.4 |
4 |
21 |
0.16 |
hetero |
29 |
| A |
61.40 |
112.60 |
119.51 |
52.5 |
7 |
18 |
0.28 |
hetero |
30 |
| I |
60.45 |
140.44 |
109.86 |
96.4 |
20 |
5 |
0.80 |
homo |
22 |
| E |
64.71 |
93.68 |
130.76 |
37.4 |
10 |
15 |
0.40 |
homo |
27 |
| C |
55.08 |
126.81 |
114.90 |
103.2 |
9 |
16 |
0.36 |
homo |
29 |
| K |
62.94 |
137.37 |
119.48 |
87.6 |
21 |
4 |
0.84 |
homo |
30 |
| F |
67.00 |
127.87 |
150.79 |
42.0 |
17 |
8 |
0.68 |
homo |
33 |
| D |
78.11 |
119.17 |
126.61 |
58.8 |
15 |
10 |
0.60 |
homo |
36 |
| J |
59.59 |
121.01 |
123.90 |
111.7 |
8 |
17 |
0.32 |
homo |
40 |
homo %>%
arrange(orientation, desc(age))
| A |
61.40 |
112.60 |
119.51 |
52.5 |
7 |
18 |
0.28 |
hetero |
30 |
| N |
57.67 |
118.02 |
121.48 |
37.4 |
4 |
21 |
0.16 |
hetero |
29 |
| G |
65.39 |
147.52 |
128.96 |
118.2 |
20 |
5 |
0.80 |
hetero |
28 |
| L |
53.31 |
112.05 |
146.20 |
57.8 |
8 |
17 |
0.32 |
hetero |
25 |
| H |
62.46 |
120.13 |
105.26 |
55.7 |
21 |
4 |
0.84 |
hetero |
22 |
| M |
45.13 |
133.74 |
155.34 |
100.5 |
9 |
16 |
0.36 |
hetero |
20 |
| B |
63.90 |
126.49 |
100.29 |
114.0 |
20 |
5 |
0.80 |
hetero |
19 |
| J |
59.59 |
121.01 |
123.90 |
111.7 |
8 |
17 |
0.32 |
homo |
40 |
| D |
78.11 |
119.17 |
126.61 |
58.8 |
15 |
10 |
0.60 |
homo |
36 |
| F |
67.00 |
127.87 |
150.79 |
42.0 |
17 |
8 |
0.68 |
homo |
33 |
| K |
62.94 |
137.37 |
119.48 |
87.6 |
21 |
4 |
0.84 |
homo |
30 |
| C |
55.08 |
126.81 |
114.90 |
103.2 |
9 |
16 |
0.36 |
homo |
29 |
| E |
64.71 |
93.68 |
130.76 |
37.4 |
10 |
15 |
0.40 |
homo |
27 |
| I |
60.45 |
140.44 |
109.86 |
96.4 |
20 |
5 |
0.80 |
homo |
22 |
3.9 distinct
## [1] hetero homo
## Levels: hetero homo
homo %>%
distinct(orientation, age > 20)
| hetero |
TRUE |
| hetero |
FALSE |
| homo |
TRUE |
unique(homo[c("orientation", "perceived.as.homo")])
| hetero |
7 |
| hetero |
20 |
| homo |
9 |
| homo |
15 |
| homo |
10 |
| homo |
17 |
| hetero |
21 |
| homo |
20 |
| homo |
8 |
| homo |
21 |
| hetero |
8 |
| hetero |
9 |
| hetero |
4 |
homo %>%
distinct(orientation, perceived.as.homo)
| 7 |
hetero |
| 20 |
hetero |
| 9 |
homo |
| 15 |
homo |
| 10 |
homo |
| 17 |
homo |
| 21 |
hetero |
| 20 |
homo |
| 8 |
homo |
| 21 |
homo |
| 8 |
hetero |
| 9 |
hetero |
| 4 |
hetero |
3.10 mutate (dplyr)
homo$f0.min <- homo$average.f0.Hz - homo$f0.range.Hz/2
homo$f0.min
## [1] 93.26 43.29 63.30 97.21 112.06 129.79 69.86 77.41 61.66 68.05
## [11] 75.68 117.30 105.09 102.78
homo$f0.max <- homo$average.f0.Hz + homo$f0.range.Hz/2
homo$f0.max
## [1] 145.76 157.29 166.50 156.01 149.46 171.79 188.06 133.11 158.06 179.75
## [11] 163.28 175.10 205.59 140.18
homo %>%
mutate( f0.mn = average.f0.Hz - f0.range.Hz/2,
f0.mx = (average.f0.Hz + f0.range.Hz/2)) ->
homo
homo
| A |
61.40 |
112.60 |
119.51 |
52.5 |
7 |
18 |
0.28 |
hetero |
30 |
93.26 |
145.76 |
93.26 |
145.76 |
| B |
63.90 |
126.49 |
100.29 |
114.0 |
20 |
5 |
0.80 |
hetero |
19 |
43.29 |
157.29 |
43.29 |
157.29 |
| C |
55.08 |
126.81 |
114.90 |
103.2 |
9 |
16 |
0.36 |
homo |
29 |
63.30 |
166.50 |
63.30 |
166.50 |
| D |
78.11 |
119.17 |
126.61 |
58.8 |
15 |
10 |
0.60 |
homo |
36 |
97.21 |
156.01 |
97.21 |
156.01 |
| E |
64.71 |
93.68 |
130.76 |
37.4 |
10 |
15 |
0.40 |
homo |
27 |
112.06 |
149.46 |
112.06 |
149.46 |
| F |
67.00 |
127.87 |
150.79 |
42.0 |
17 |
8 |
0.68 |
homo |
33 |
129.79 |
171.79 |
129.79 |
171.79 |
| G |
65.39 |
147.52 |
128.96 |
118.2 |
20 |
5 |
0.80 |
hetero |
28 |
69.86 |
188.06 |
69.86 |
188.06 |
| H |
62.46 |
120.13 |
105.26 |
55.7 |
21 |
4 |
0.84 |
hetero |
22 |
77.41 |
133.11 |
77.41 |
133.11 |
| I |
60.45 |
140.44 |
109.86 |
96.4 |
20 |
5 |
0.80 |
homo |
22 |
61.66 |
158.06 |
61.66 |
158.06 |
| J |
59.59 |
121.01 |
123.90 |
111.7 |
8 |
17 |
0.32 |
homo |
40 |
68.05 |
179.75 |
68.05 |
179.75 |
| K |
62.94 |
137.37 |
119.48 |
87.6 |
21 |
4 |
0.84 |
homo |
30 |
75.68 |
163.28 |
75.68 |
163.28 |
| L |
53.31 |
112.05 |
146.20 |
57.8 |
8 |
17 |
0.32 |
hetero |
25 |
117.30 |
175.10 |
117.30 |
175.10 |
| M |
45.13 |
133.74 |
155.34 |
100.5 |
9 |
16 |
0.36 |
hetero |
20 |
105.09 |
205.59 |
105.09 |
205.59 |
| N |
57.67 |
118.02 |
121.48 |
37.4 |
4 |
21 |
0.16 |
hetero |
29 |
102.78 |
140.18 |
102.78 |
140.18 |
3.11 group_by and summarise (dplyr)
homo %>%
summarise(min(age), mean(s.duration.ms))
homo %>%
group_by(orientation) %>%
summarise(my_mean = mean(s.duration.ms))
| hetero |
58.46571 |
| homo |
63.98286 |
homo %>%
group_by(orientation) %>%
summarise(mean(s.duration.ms))
| hetero |
58.46571 |
| homo |
63.98286 |
homo %>%
group_by(orientation) %>%
summarise(mean_by_orientation = mean(s.duration.ms))
| hetero |
58.46571 |
| homo |
63.98286 |
4.1. tidyr package
df.short <- data.frame(
consonant = c("stops", "fricatives", "affricates", "nasals"),
initial = c(123, 87, 73, 7),
intervocal = c(57, 77, 82, 78),
final = c(30, 69, 12, 104))
df.short
| stops |
123 |
57 |
30 |
| fricatives |
87 |
77 |
69 |
| affricates |
73 |
82 |
12 |
| nasals |
7 |
78 |
104 |
- Long format
| stops |
initial |
123 |
| fricatives |
initial |
87 |
| affricates |
initial |
73 |
| nasals |
initial |
7 |
| stops |
intervocal |
57 |
| fricatives |
intervocal |
77 |
| affricates |
intervocal |
82 |
| nasals |
intervocal |
78 |
| stops |
final |
30 |
| fricatives |
final |
69 |
| affricates |
final |
12 |
| nasals |
final |
104 |
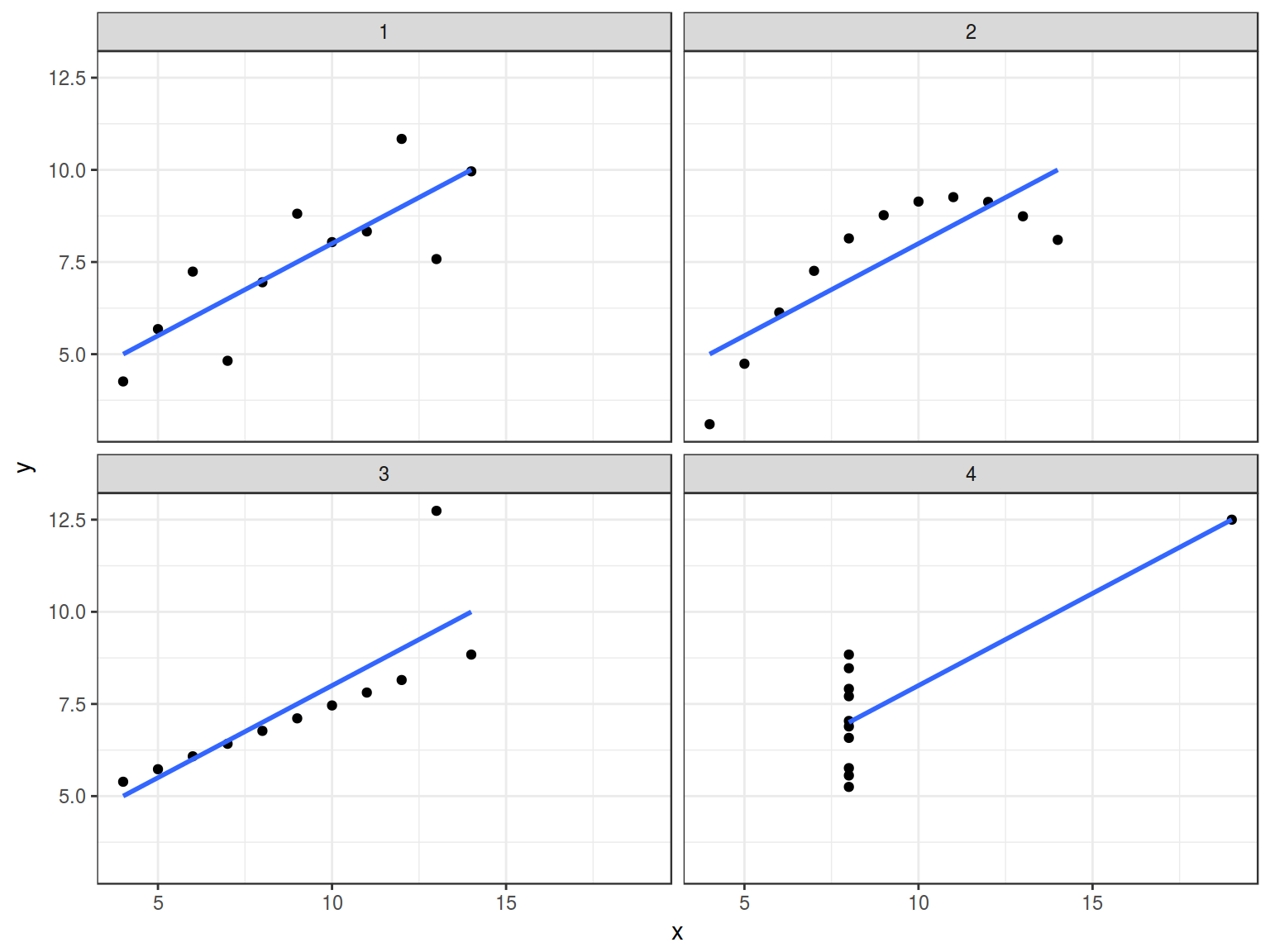
5.1 Anscombe’s quartet
In Anscombe, F. J. (1973). “Graphs in Statistical Analysis” was presented the next sets of data:
quartet <- read.csv("https://goo.gl/KuuzYy")
quartet
| 10 |
8.04 |
1 |
| 8 |
6.95 |
1 |
| 13 |
7.58 |
1 |
| 9 |
8.81 |
1 |
| 11 |
8.33 |
1 |
| 14 |
9.96 |
1 |
| 6 |
7.24 |
1 |
| 4 |
4.26 |
1 |
| 12 |
10.84 |
1 |
| 7 |
4.82 |
1 |
| 5 |
5.68 |
1 |
| 10 |
9.14 |
2 |
| 8 |
8.14 |
2 |
| 13 |
8.74 |
2 |
| 9 |
8.77 |
2 |
| 11 |
9.26 |
2 |
| 14 |
8.10 |
2 |
| 6 |
6.13 |
2 |
| 4 |
3.10 |
2 |
| 12 |
9.13 |
2 |
| 7 |
7.26 |
2 |
| 5 |
4.74 |
2 |
| 10 |
7.46 |
3 |
| 8 |
6.77 |
3 |
| 13 |
12.74 |
3 |
| 9 |
7.11 |
3 |
| 11 |
7.81 |
3 |
| 14 |
8.84 |
3 |
| 6 |
6.08 |
3 |
| 4 |
5.39 |
3 |
| 12 |
8.15 |
3 |
| 7 |
6.42 |
3 |
| 5 |
5.73 |
3 |
| 8 |
6.58 |
4 |
| 8 |
5.76 |
4 |
| 8 |
7.71 |
4 |
| 8 |
8.84 |
4 |
| 8 |
8.47 |
4 |
| 8 |
7.04 |
4 |
| 8 |
5.25 |
4 |
| 19 |
12.50 |
4 |
| 8 |
5.56 |
4 |
| 8 |
7.91 |
4 |
| 8 |
6.89 |
4 |
quartet %>%
group_by(dataset) %>%
summarise(mean_X = mean(x),
mean_Y = mean(y),
sd_X = sd(x),
sd_Y = sd(y),
cor = cor(x, y),
n_obs = n()) %>%
select(-dataset) %>%
round(., 2)
| 9 |
7.5 |
3.32 |
2.03 |
0.82 |
11 |
| 9 |
7.5 |
3.32 |
2.03 |
0.82 |
11 |
| 9 |
7.5 |
3.32 |
2.03 |
0.82 |
11 |
| 9 |
7.5 |
3.32 |
2.03 |
0.82 |
11 |
5.2 Datasaurus
In Matejka and Fitzmaurice (2017) “Same Stats, Different Graphs” was presented the next sets of data:
datasaurus <- read_tsv("https://goo.gl/gtaunr")
head(datasaurus)
| dino |
55.3846 |
97.1795 |
| dino |
51.5385 |
96.0256 |
| dino |
46.1538 |
94.4872 |
| dino |
42.8205 |
91.4103 |
| dino |
40.7692 |
88.3333 |
| dino |
38.7179 |
84.8718 |
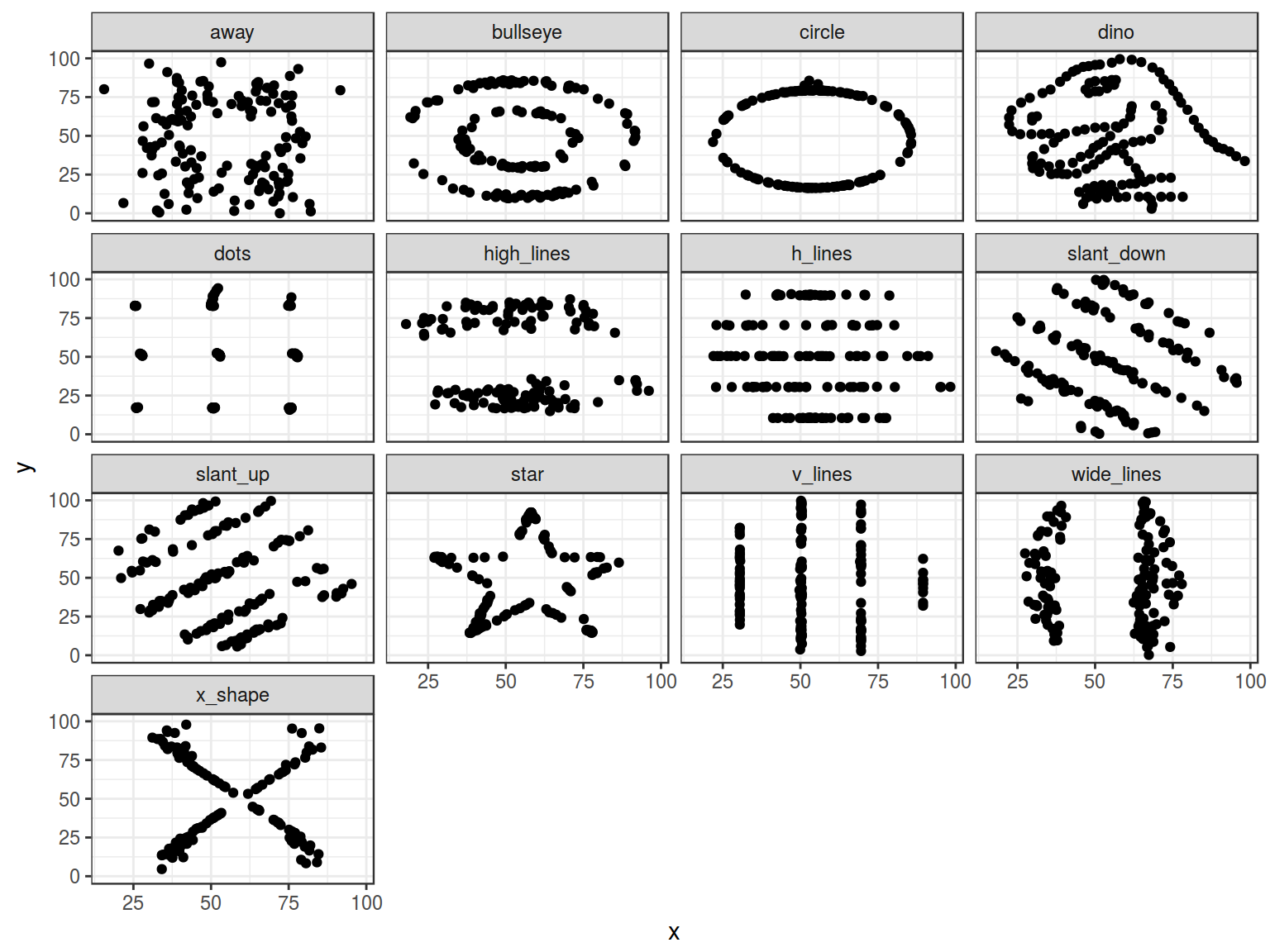
datasaurus %>%
group_by(dataset) %>%
summarise(mean_X = mean(x),
mean_Y = mean(y),
sd_X = sd(x),
sd_Y = sd(y),
cor = cor(x, y),
n_obs = n()) %>%
select(-dataset) %>%
round(., 1)
| 54.3 |
47.8 |
16.8 |
26.9 |
-0.1 |
142 |
| 54.3 |
47.8 |
16.8 |
26.9 |
-0.1 |
142 |
| 54.3 |
47.8 |
16.8 |
26.9 |
-0.1 |
142 |
| 54.3 |
47.8 |
16.8 |
26.9 |
-0.1 |
142 |
| 54.3 |
47.8 |
16.8 |
26.9 |
-0.1 |
142 |
| 54.3 |
47.8 |
16.8 |
26.9 |
-0.1 |
142 |
| 54.3 |
47.8 |
16.8 |
26.9 |
-0.1 |
142 |
| 54.3 |
47.8 |
16.8 |
26.9 |
-0.1 |
142 |
| 54.3 |
47.8 |
16.8 |
26.9 |
-0.1 |
142 |
| 54.3 |
47.8 |
16.8 |
26.9 |
-0.1 |
142 |
| 54.3 |
47.8 |
16.8 |
26.9 |
-0.1 |
142 |
| 54.3 |
47.8 |
16.8 |
26.9 |
-0.1 |
142 |
| 54.3 |
47.8 |
16.8 |
26.9 |
-0.1 |
142 |
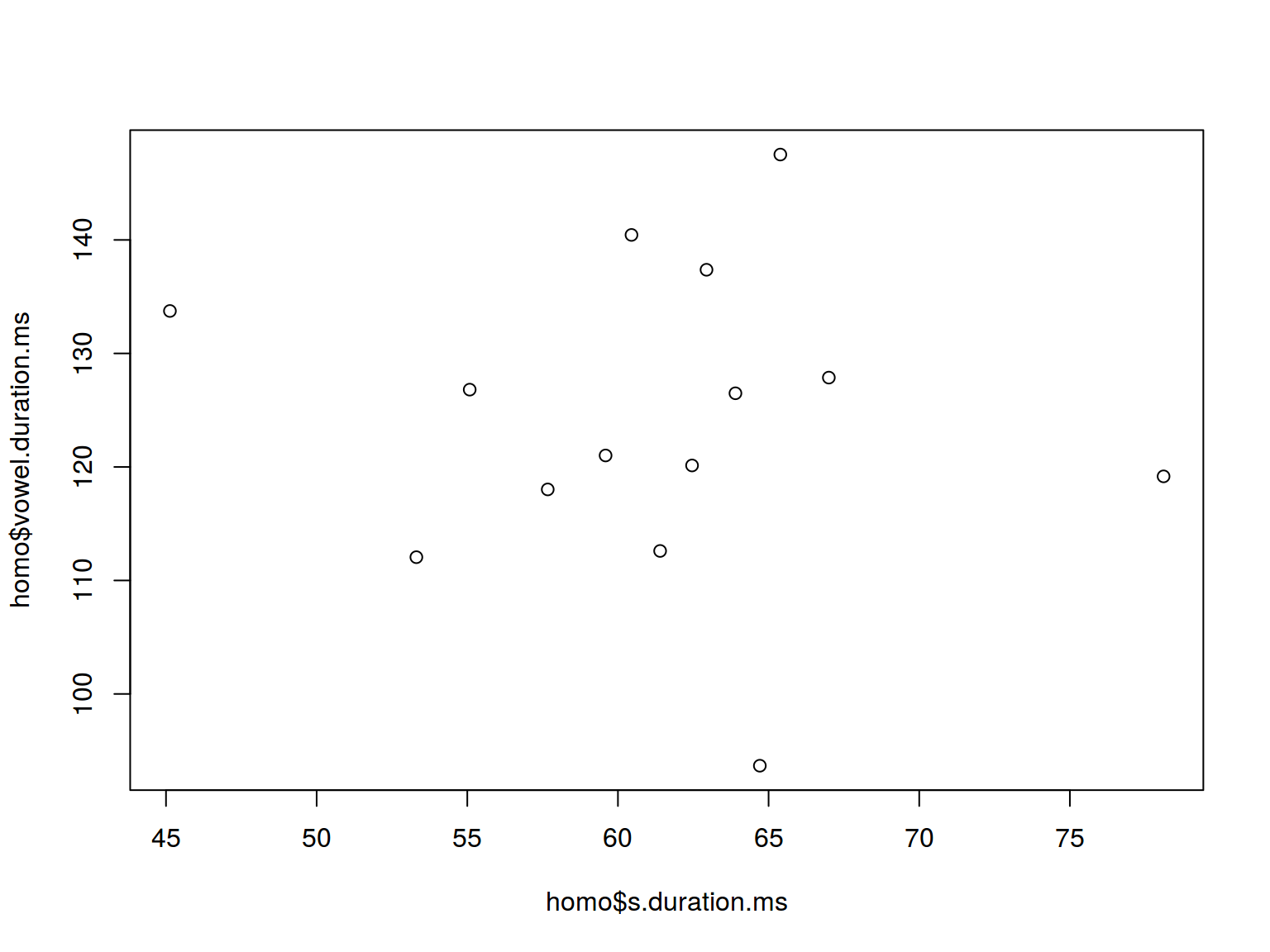
6.1 Scaterplot
plot(homo$s.duration.ms, homo$vowel.duration.ms)
ggplot(data = homo, aes(s.duration.ms, vowel.duration.ms)) +
geom_point()
homo %>%
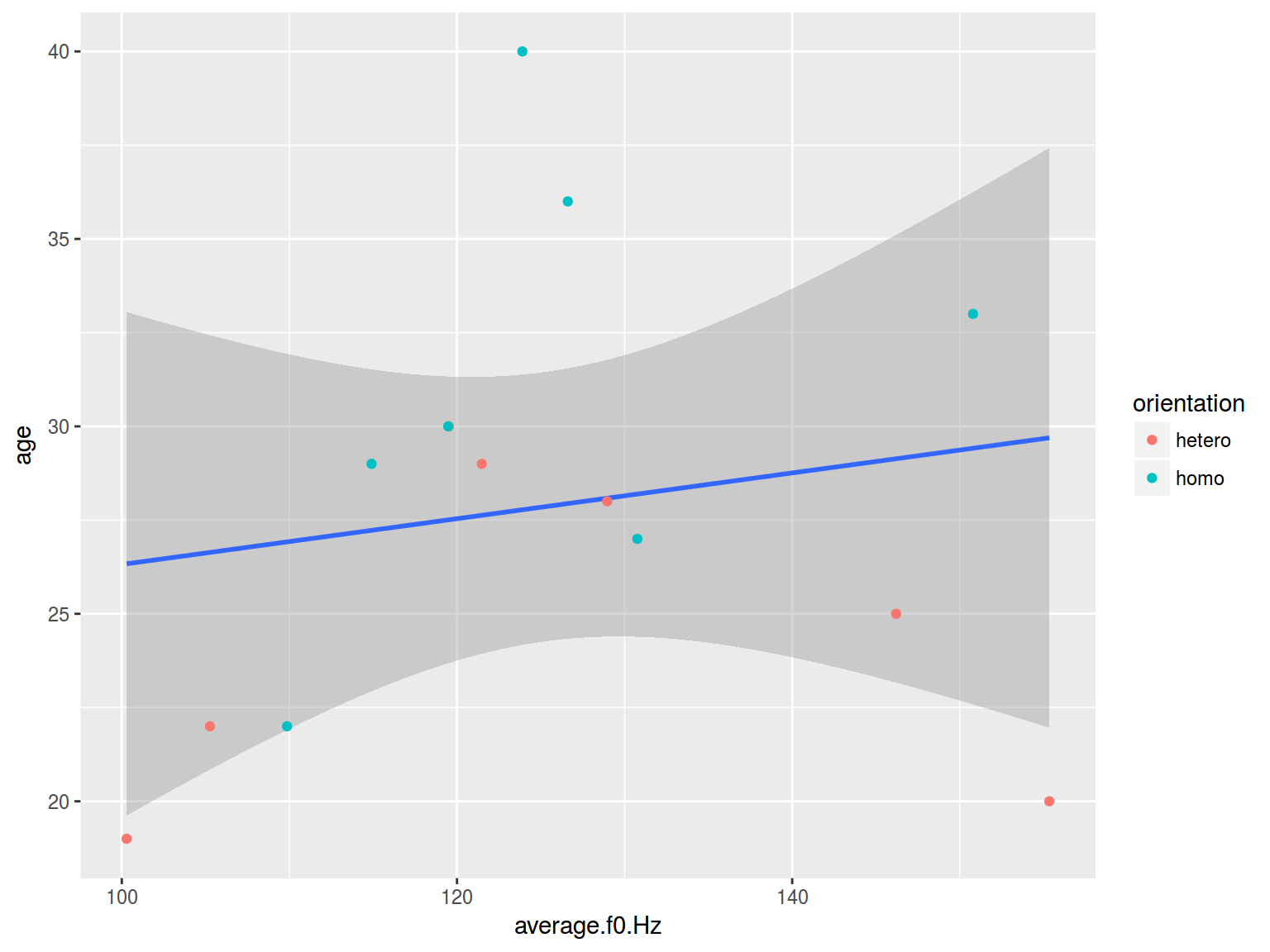
ggplot(aes(average.f0.Hz, age))+
geom_smooth(method = "lm")+
geom_point(aes(color = orientation))
6.1.1 Scaterplot: color
plot(homo$s.duration.ms, homo$vowel.duration.ms,
col = c("red", "blue")[homo$orientation])
homo %>%
ggplot(aes(s.duration.ms, vowel.duration.ms,
color = orientation)) +
geom_point()
6.1.2 Scaterplot: shape
plot(homo$s.duration.ms, homo$vowel.duration.ms,
pch = c(16, 17)[homo$orientation])
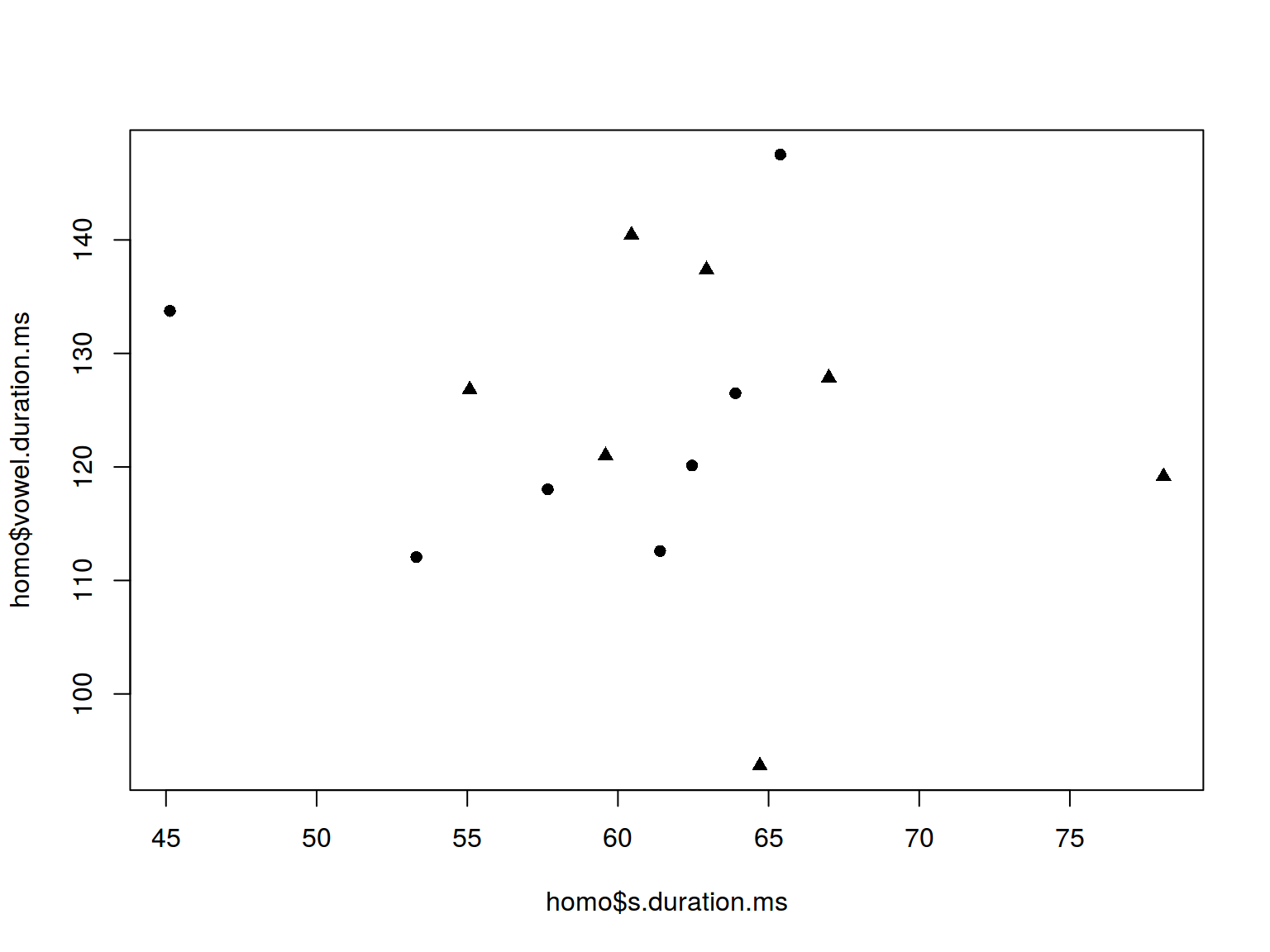
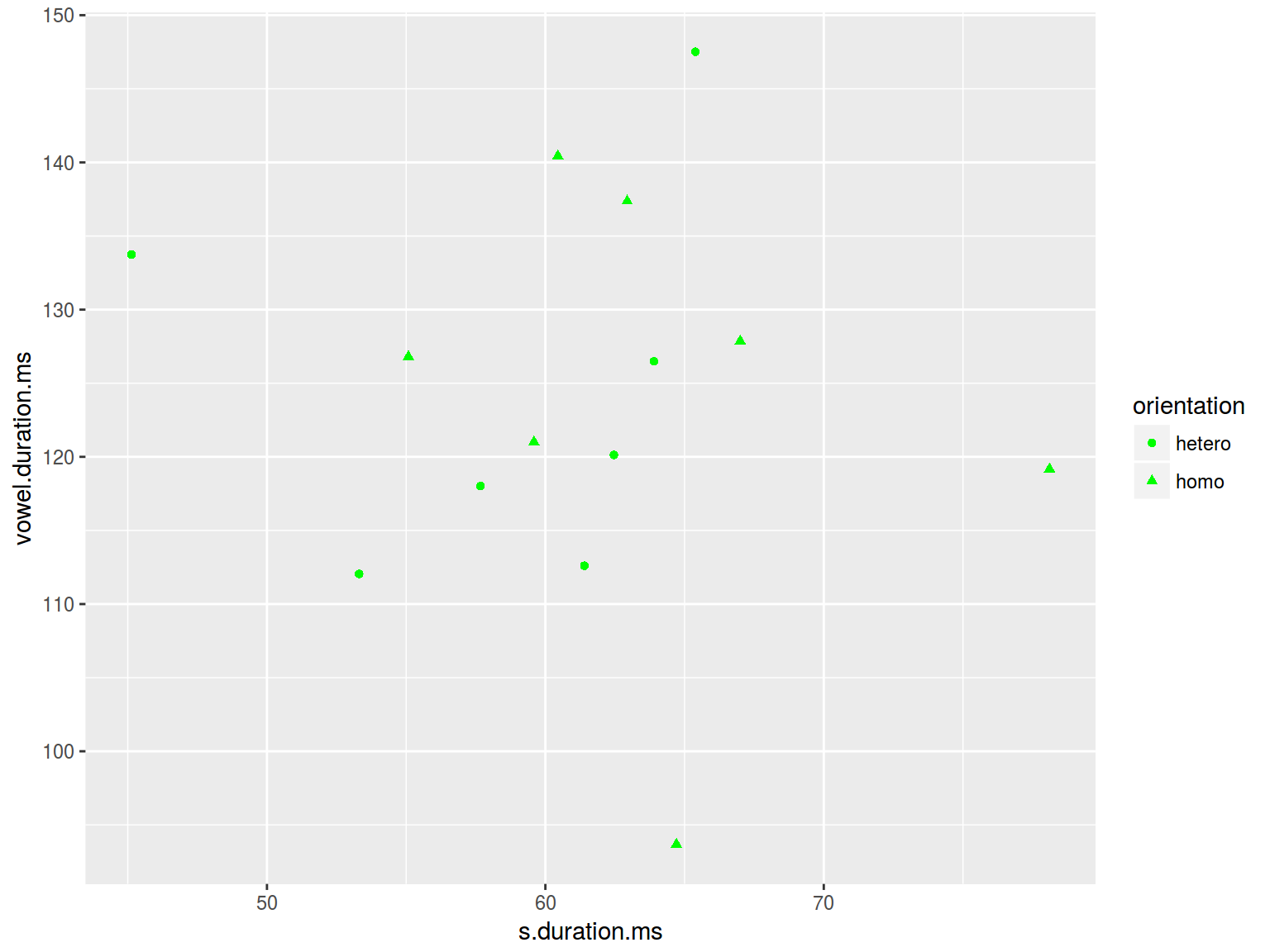
homo %>%
ggplot(aes(s.duration.ms, vowel.duration.ms,
shape = orientation)) +
geom_point(color = "green")
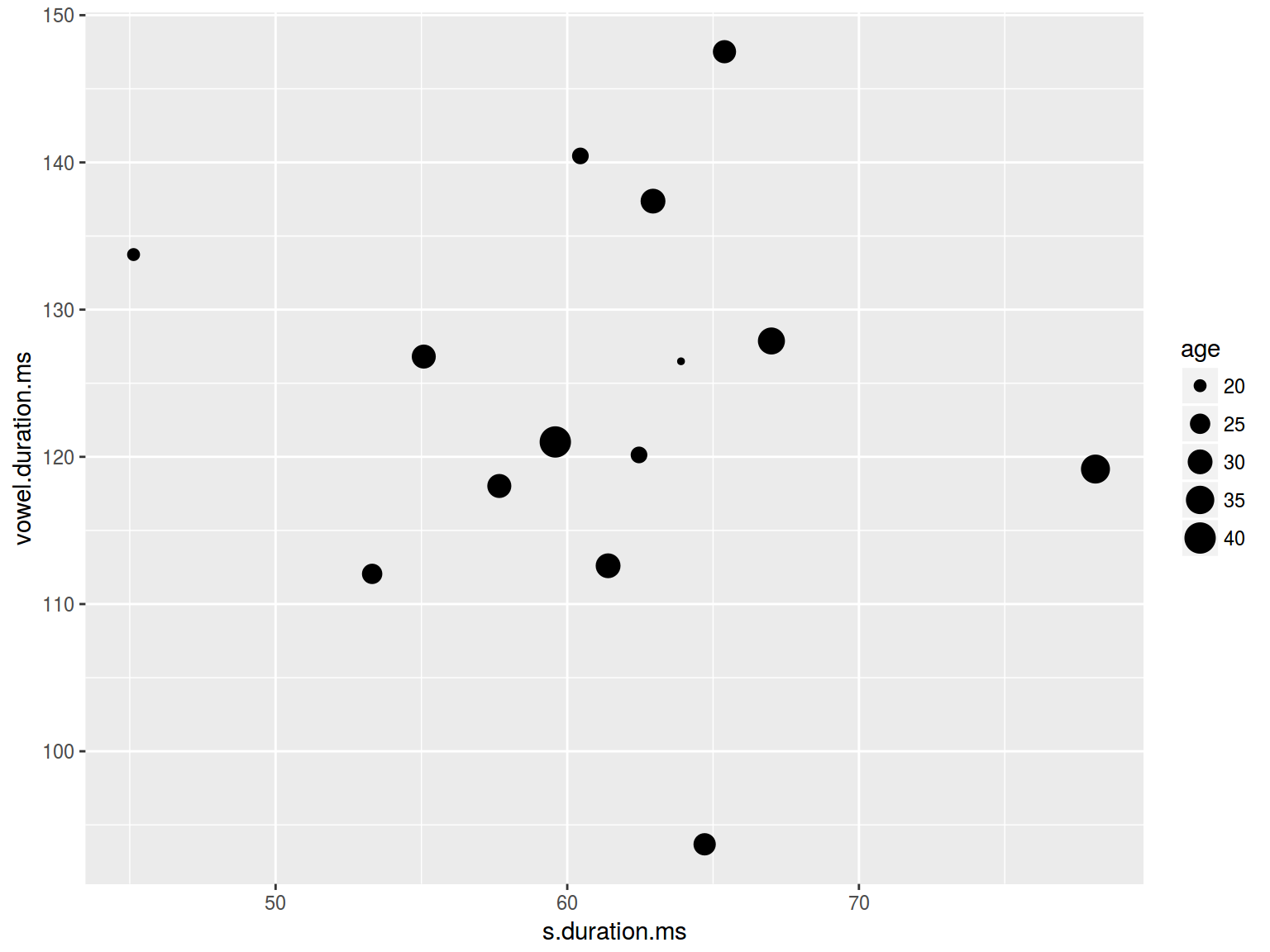
6.1.3 Scaterplot: size
plot(homo$s.duration.ms, homo$vowel.duration.ms,
cex = homo$age/20)
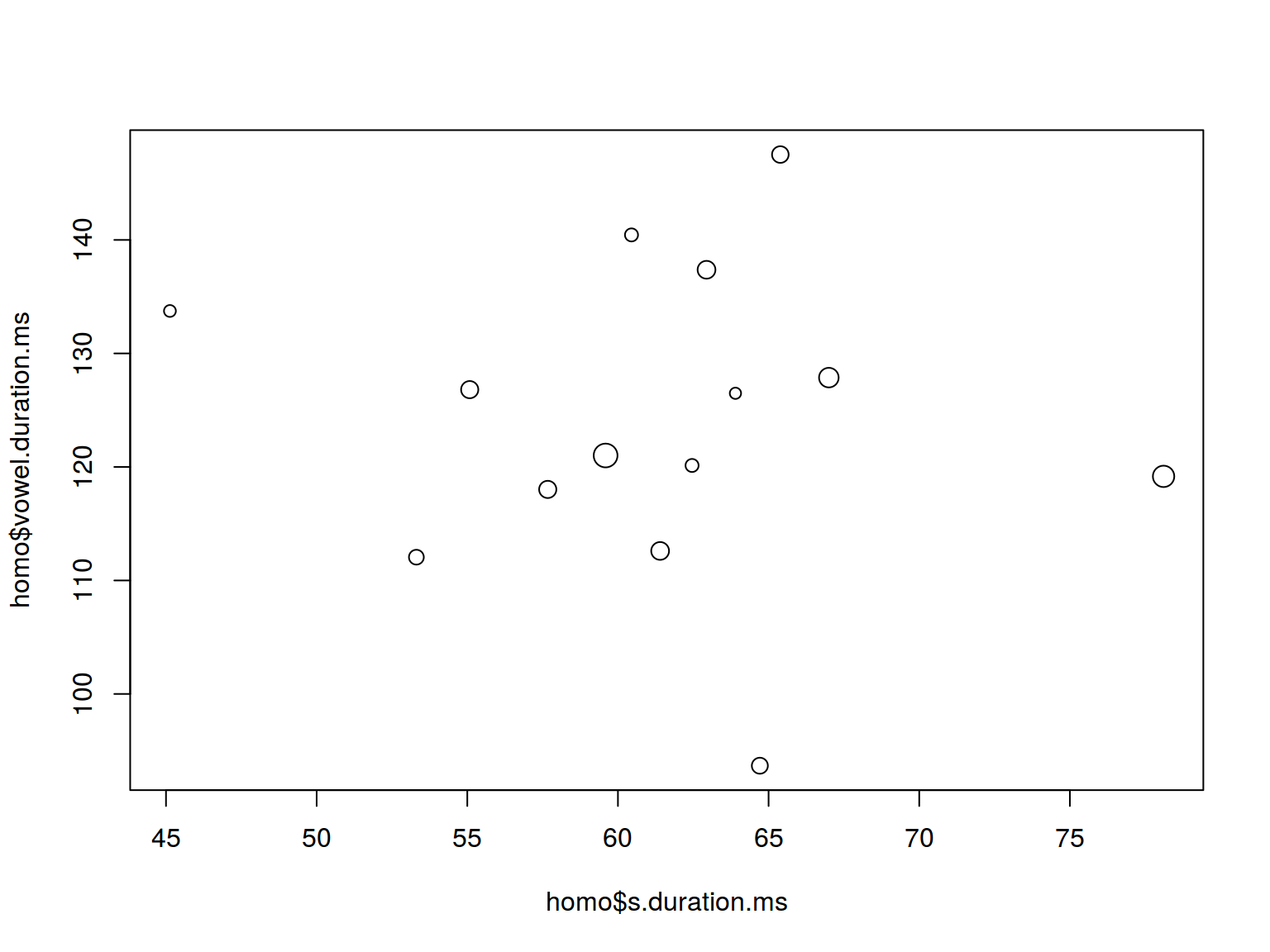
plot(homo$s.duration.ms, homo$vowel.duration.ms,
cex = homo$age)
homo %>%
ggplot(aes(s.duration.ms, vowel.duration.ms,
size = age)) +
geom_point()
6.1.4 Scaterplot: text
plot(homo$s.duration.ms, homo$vowel.duration.ms,
pch = c("⚤", "⚣")[homo$orientation])
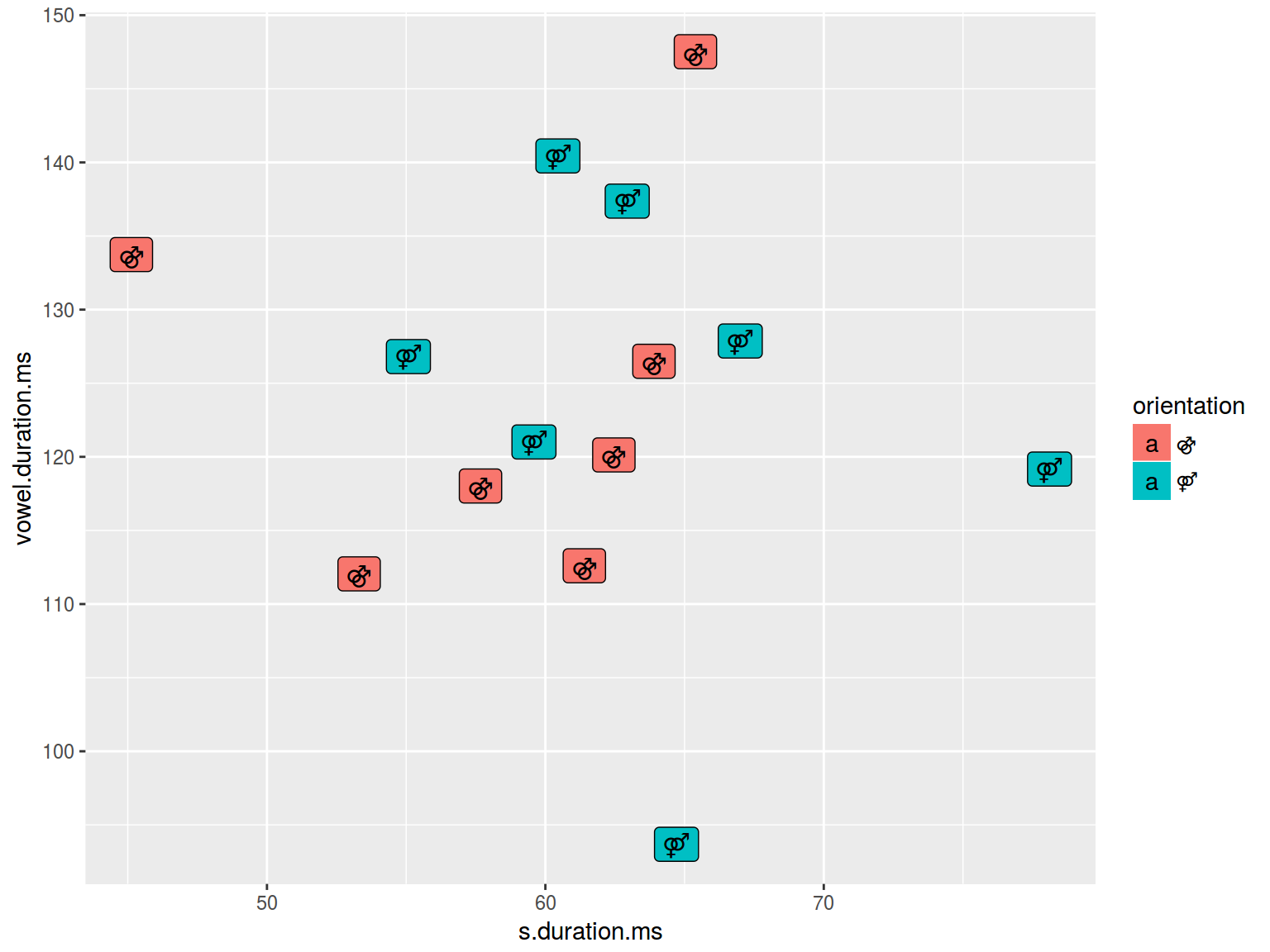
levels(homo$orientation) <- c("⚣", "⚤")
homo %>%
ggplot(aes(s.duration.ms, vowel.duration.ms, label = orientation, fill = orientation)) +
geom_label()
6.1.5 Scaterplot: title
plot(homo$s.duration.ms, homo$vowel.duration.ms,
main = "length of [s] vs. length of vowels")
homo %>%
ggplot(aes(s.duration.ms, vowel.duration.ms)) +
geom_point()+
labs(title = "length of [s] vs. length of vowels",
subtitle = "based on 14 speakers of Cantonese",
caption = "data from [Chi kuk 2007]")
6.1.6 Scaterplot: axis
plot(homo$s.duration.ms, homo$vowel.duration.ms,
xlab = "duration of [s] in ms", ylab = "vowel duration in ms")
homo %>%
ggplot(aes(s.duration.ms, vowel.duration.ms)) +
geom_point()+
xlab("duration of [s] in ms")+
ylab("vowel duration in ms")
6.1.7 Log scales
Lets use the frequency dictionary for Russian
freq <- read.csv("https://goo.gl/TlX7xW", sep = "\t")
freq %>%
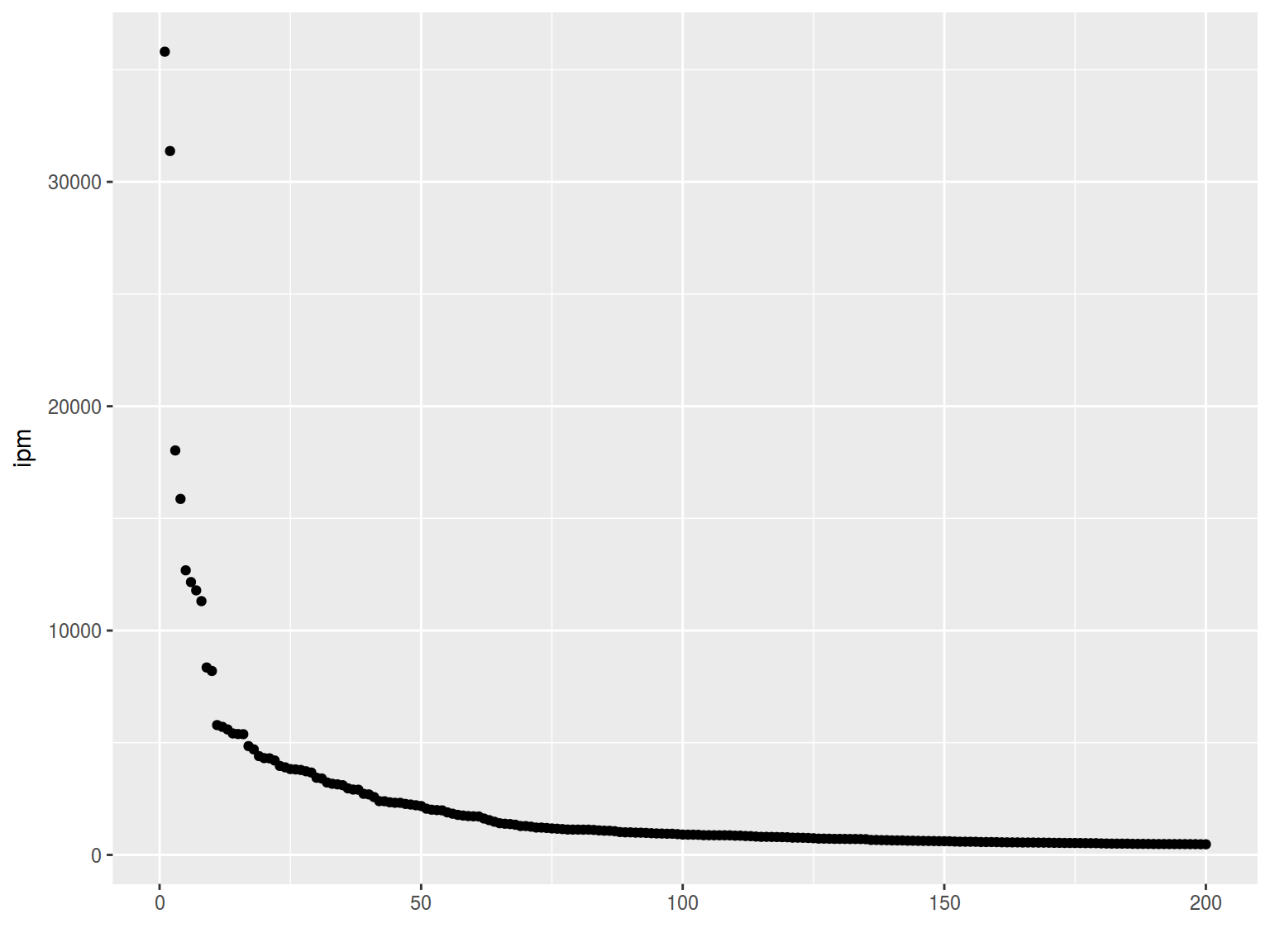
arrange(desc(Freq.ipm.)) %>%
slice(1:200) %>%
ggplot(aes(Rank, Freq.ipm.)) +
geom_point() +
xlab("") +
ylab("ipm")
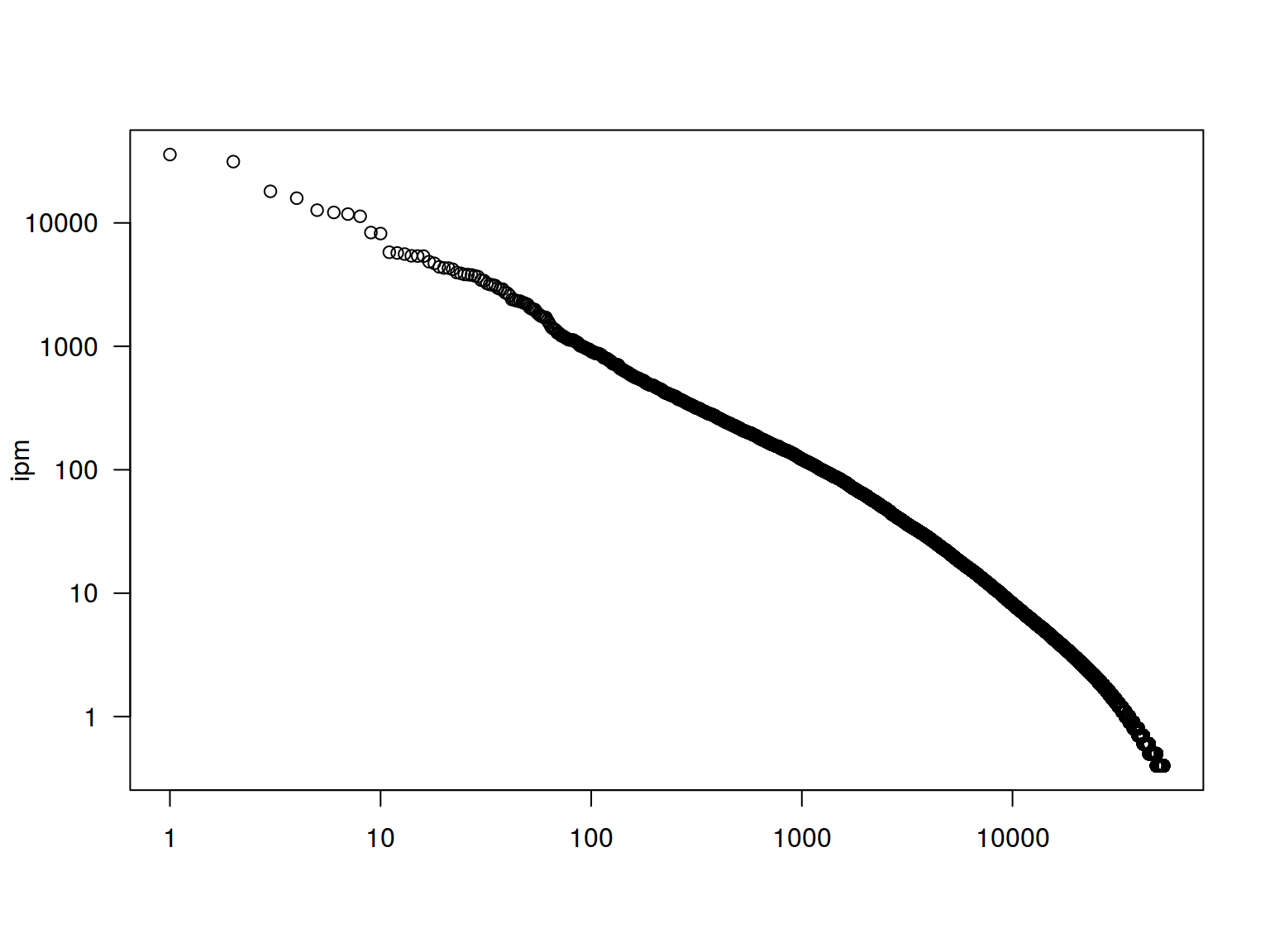
plot(1:52138, freq$Freq.ipm.,
xlab = NA, ylab = "ipm",
las = 1,
log = "yx")
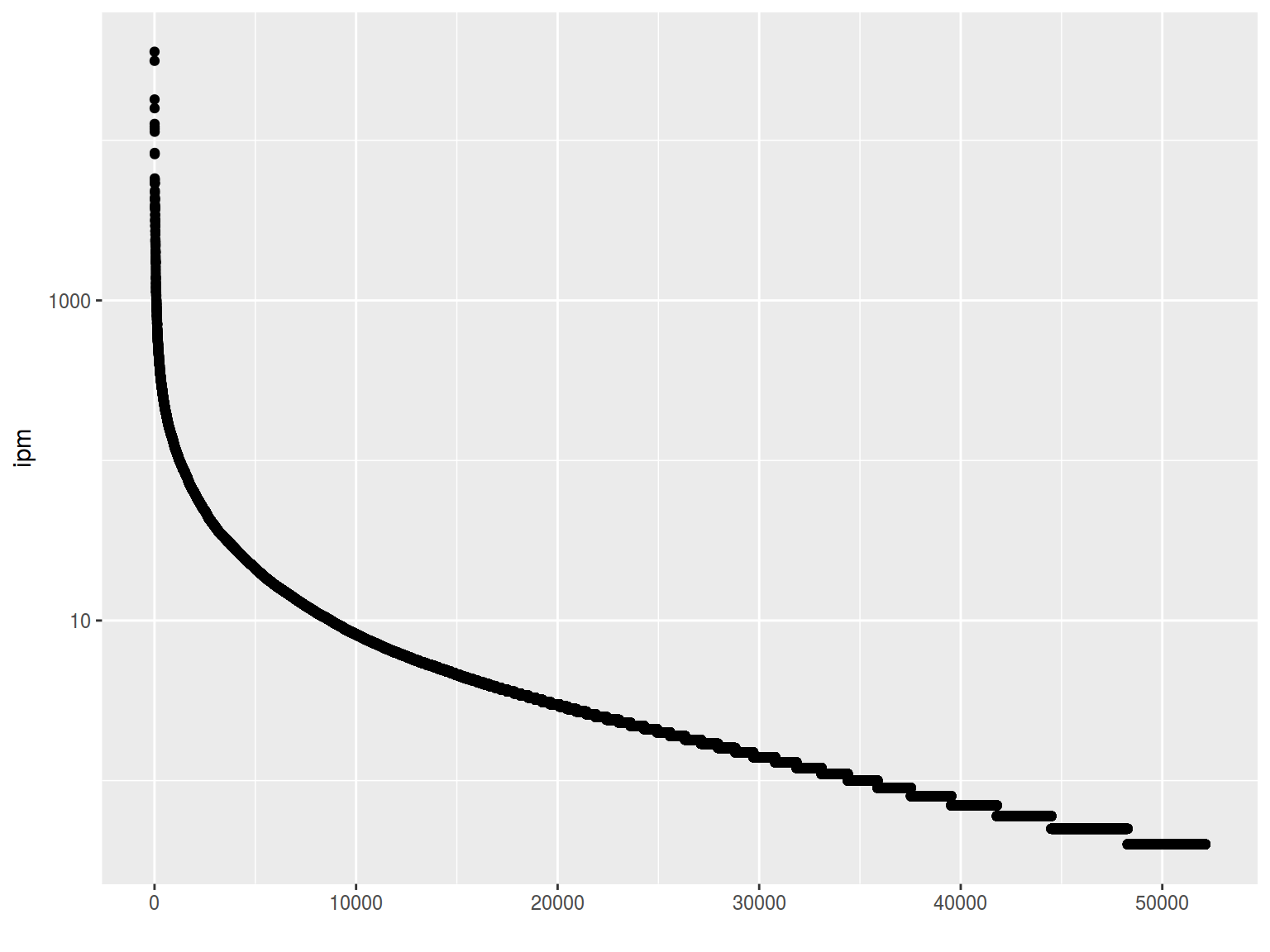
freq %>%
ggplot(aes(1:52138, Freq.ipm.))+
geom_point()+
xlab("")+
ylab("ipm")+
scale_y_log10()
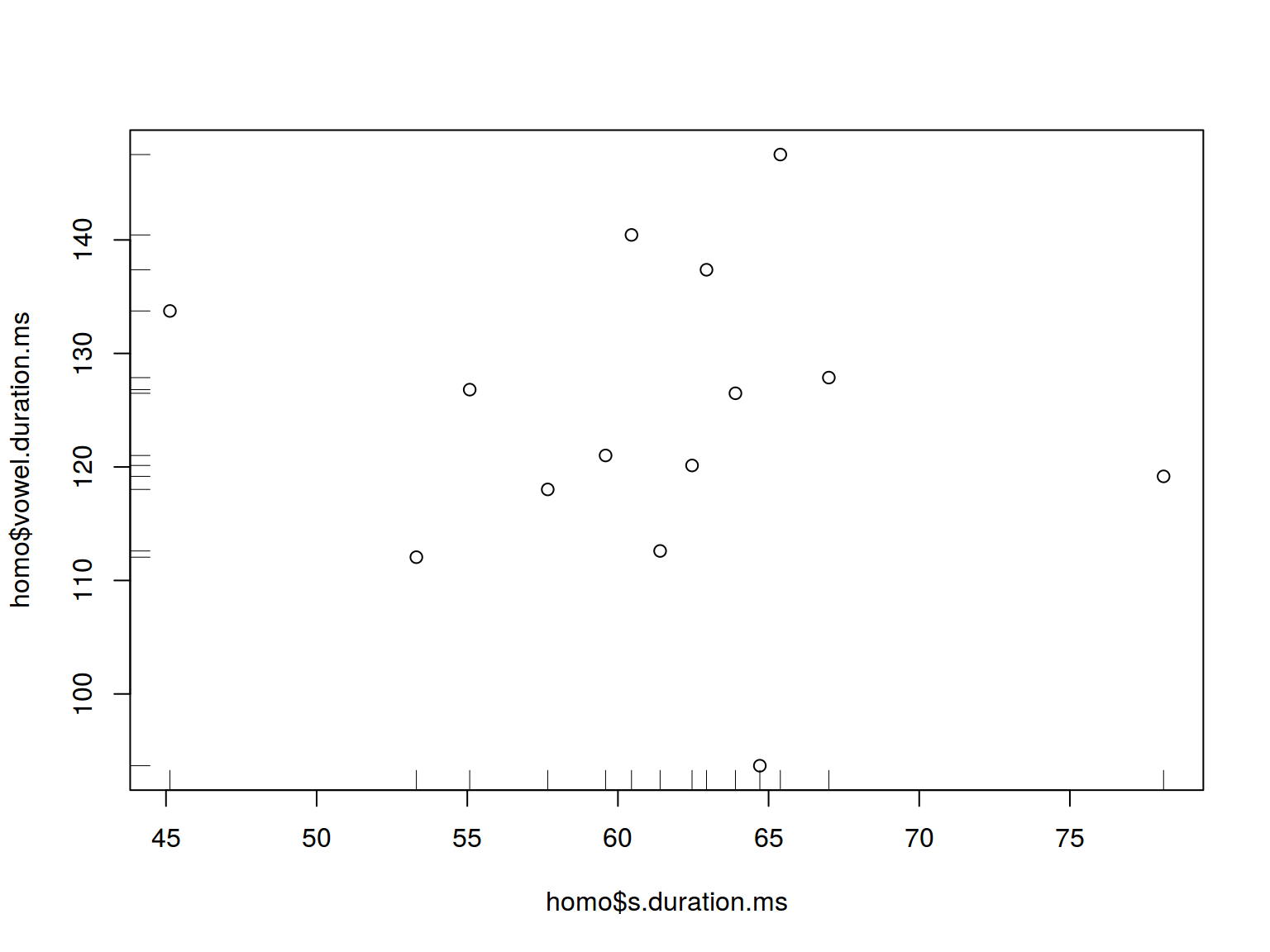
6.1.8 Scaterplot: rug
plot(homo$s.duration.ms, homo$vowel.duration.ms)
rug(homo$s.duration.ms)
rug(homo$vowel.duration.ms, side = 2)
homo %>%
ggplot(aes(s.duration.ms, vowel.duration.ms, color = orientation)) +
geom_point() +
geom_rug()
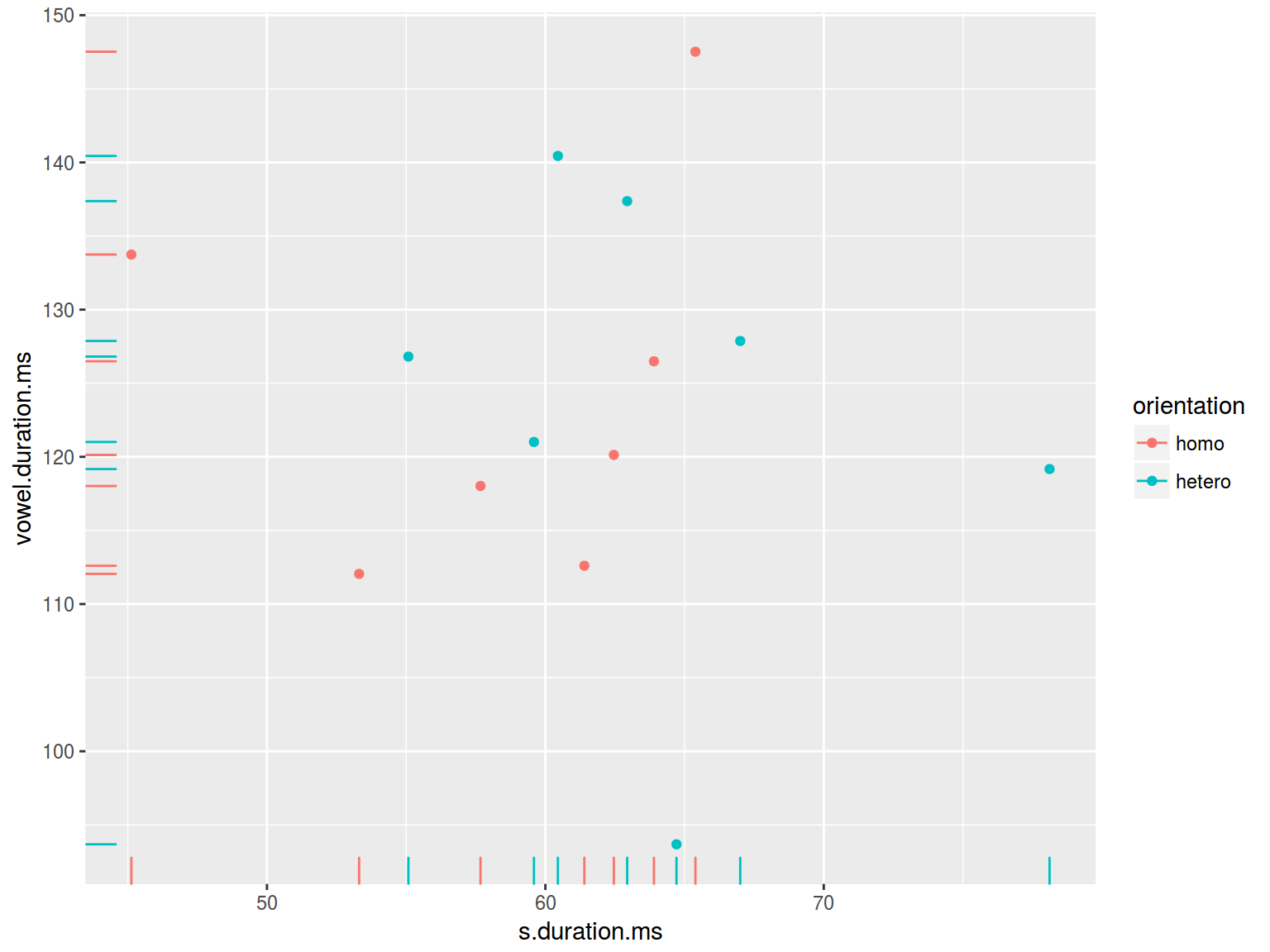
homo %>%
ggplot(aes(s.duration.ms, vowel.duration.ms, color = orientation)) +
geom_point() +
geom_rug()
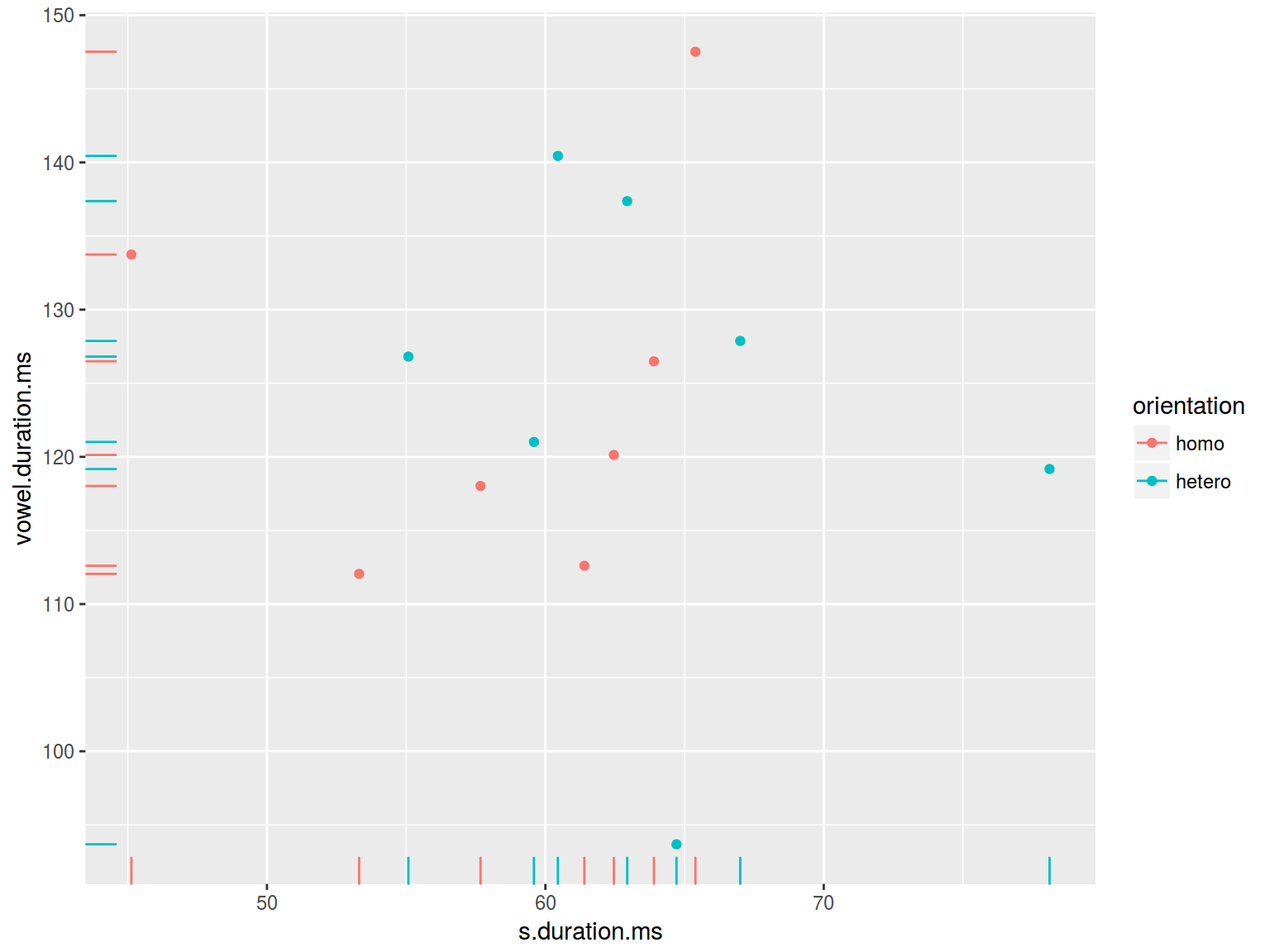
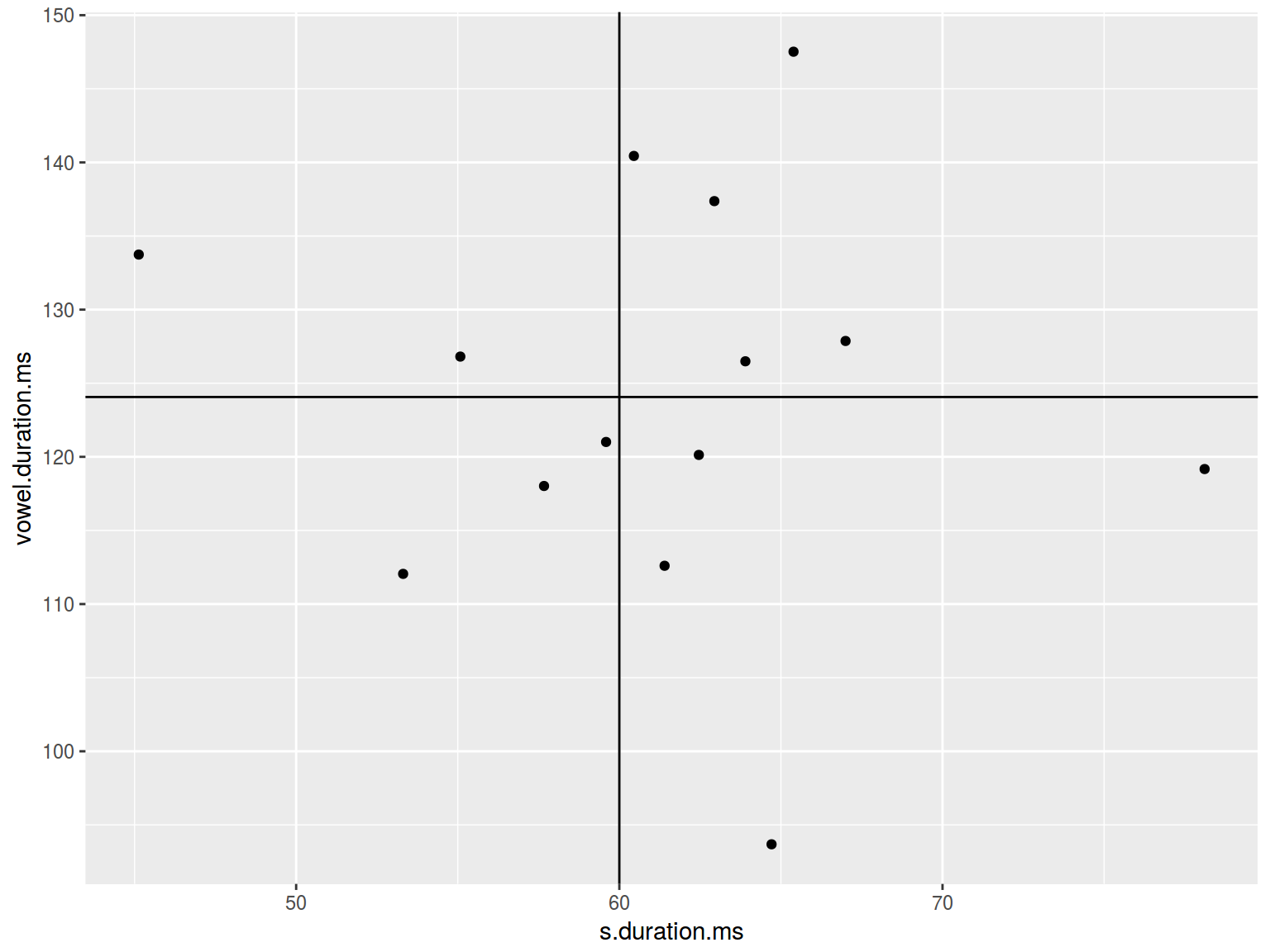
6.1.9 Scaterplot: lines
plot(homo$s.duration.ms, homo$vowel.duration.ms)
abline(h = 120, v = 60)
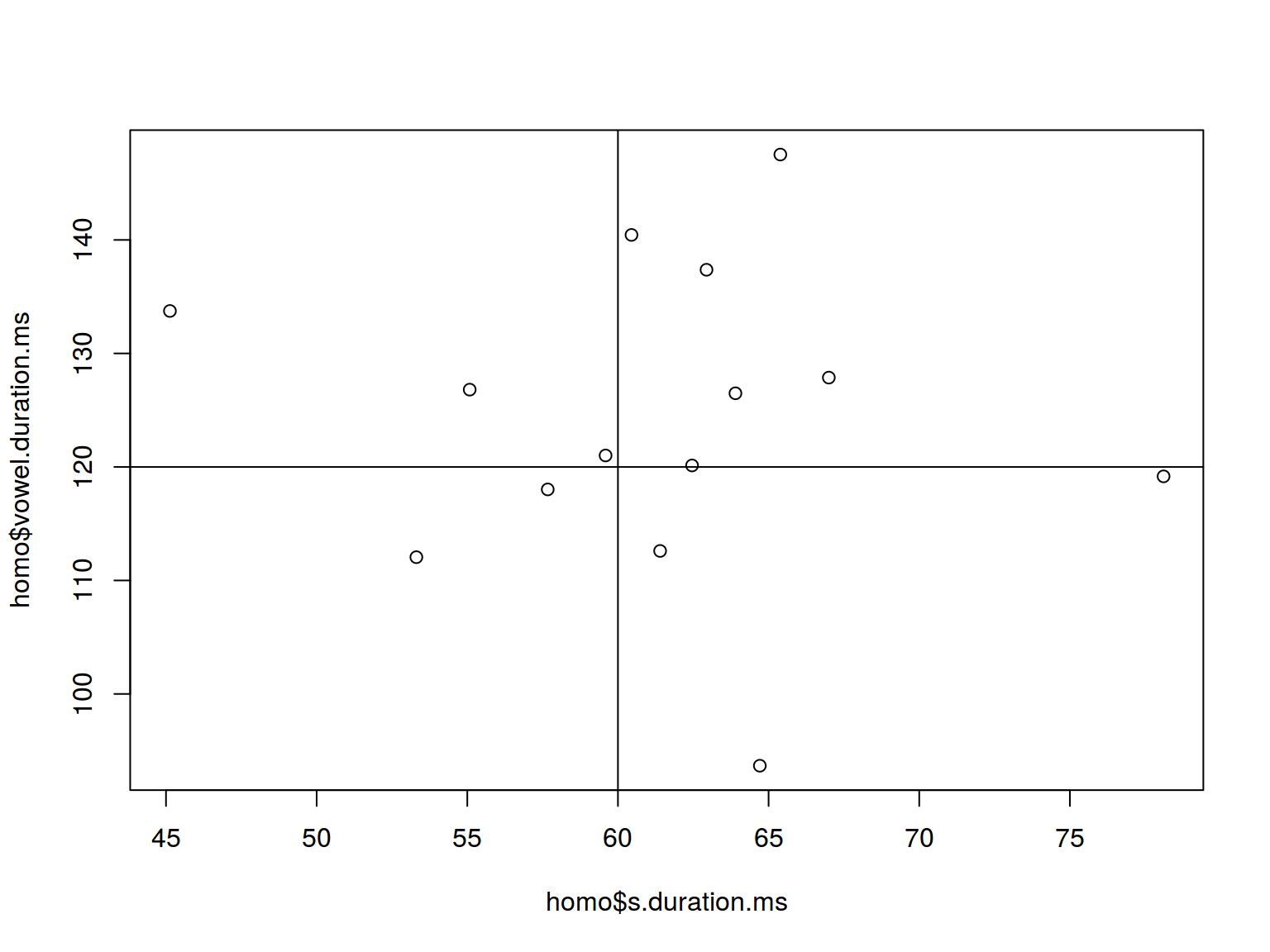
homo %>%
ggplot(aes(s.duration.ms, vowel.duration.ms)) +
geom_point() +
geom_hline(yintercept = mean(homo$vowel.duration.ms))+
geom_vline(xintercept = 60)
plot(homo$s.duration.ms, homo$vowel.duration.ms)
abline(h = 120, lty = 2)
abline(v = 60, lwd = 42)
homo %>%
ggplot(aes(s.duration.ms, vowel.duration.ms)) +
geom_point() +
geom_hline(yintercept = 120, linetype = 2)+
geom_vline(xintercept = 60, size = 5)
plot(homo$s.duration.ms, homo$vowel.duration.ms)
abline(h = 120, lty = 4)
abline(v = 60, col = "blue")
homo %>%
ggplot(aes(s.duration.ms, vowel.duration.ms)) +
geom_point() +
geom_hline(yintercept = 120, linetype = 4)+
geom_vline(xintercept = 60, color = "blue")
6.1.10 Scaterplot: annotate
The function annotate adds geoms to a plot.
homo %>%
ggplot(aes(s.duration.ms, vowel.duration.ms)) +
geom_point()+
annotate(geom = "rect", xmin = 77, xmax = 79,
ymin = 117, ymax = 122, fill = "red", alpha = 0.2) +
annotate(geom = "text", x = 78, y = 125,
label = "Who is that?\n Outlier?")
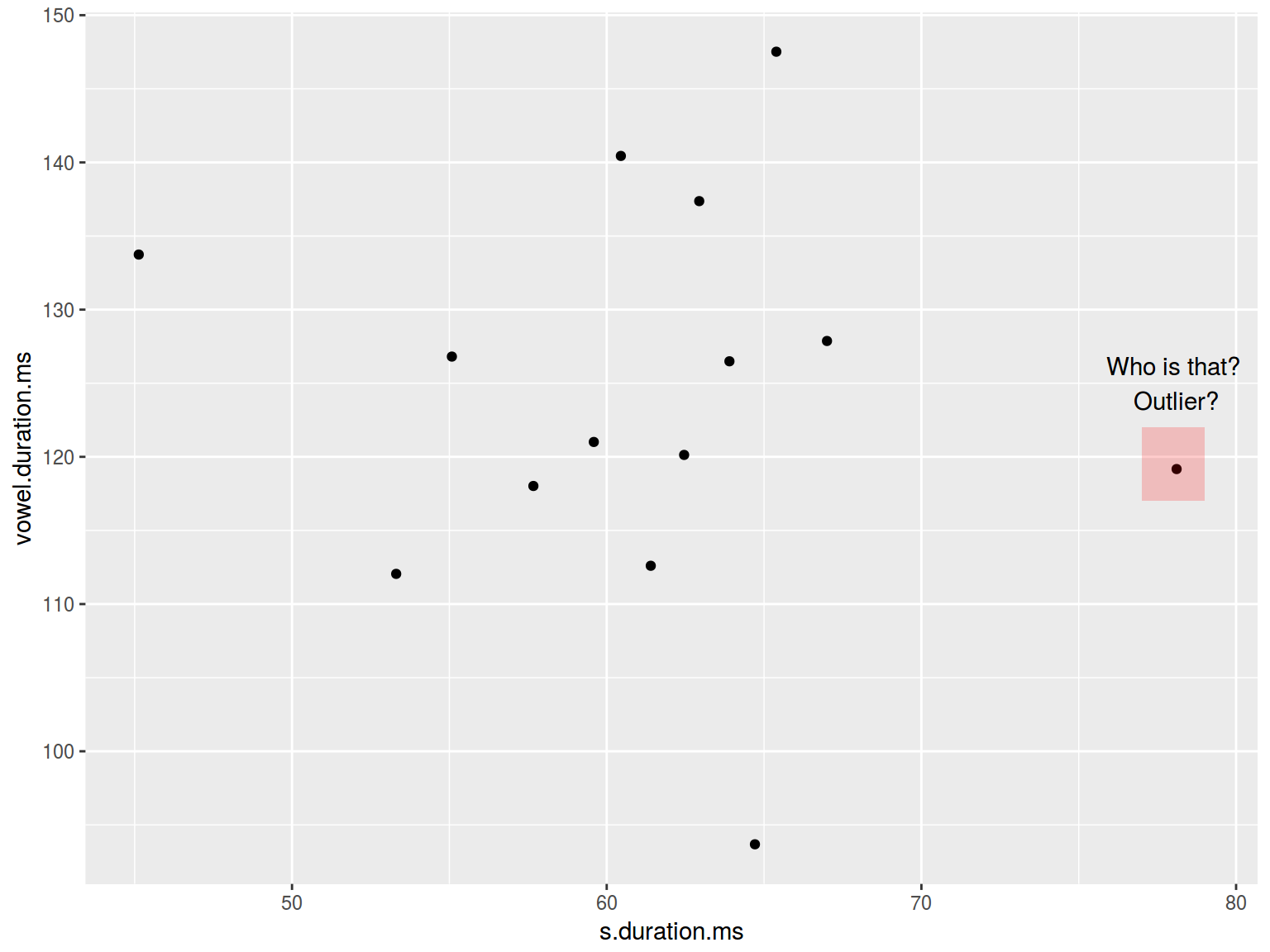
6.2.1 Barplots: basics
There are two possible situations:
| A |
homo |
| B |
homo |
| C |
hetero |
| D |
hetero |
| E |
hetero |
| F |
hetero |
| A |
30 |
| B |
19 |
| C |
29 |
| D |
36 |
| E |
27 |
| F |
33 |
Not aggregate data
barplot(table(homo$orientation))

homo %>%
ggplot(aes(orientation)) +
geom_bar()

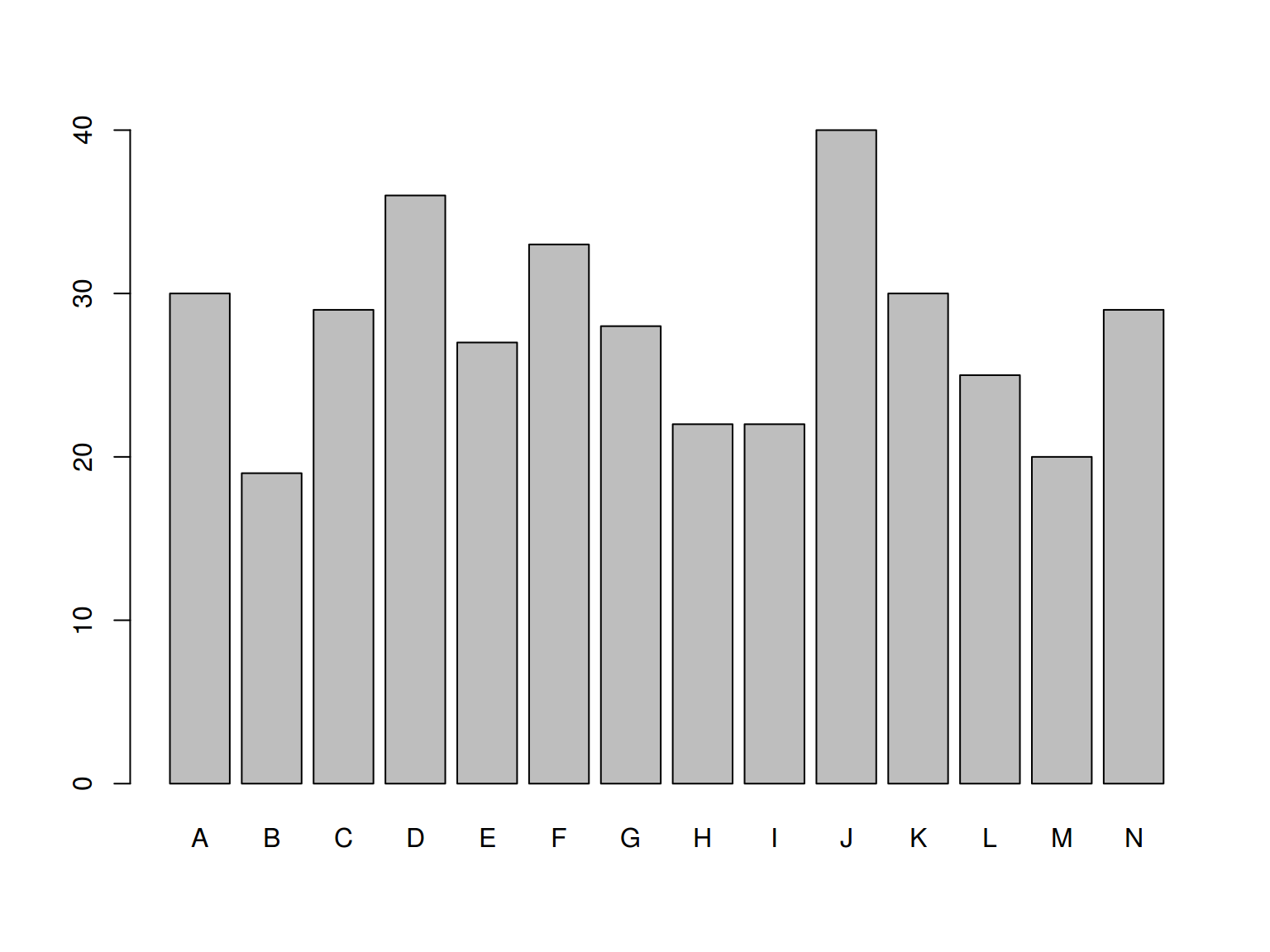
Aggregate data
barplot(homo$age, names.arg = homo$speaker)
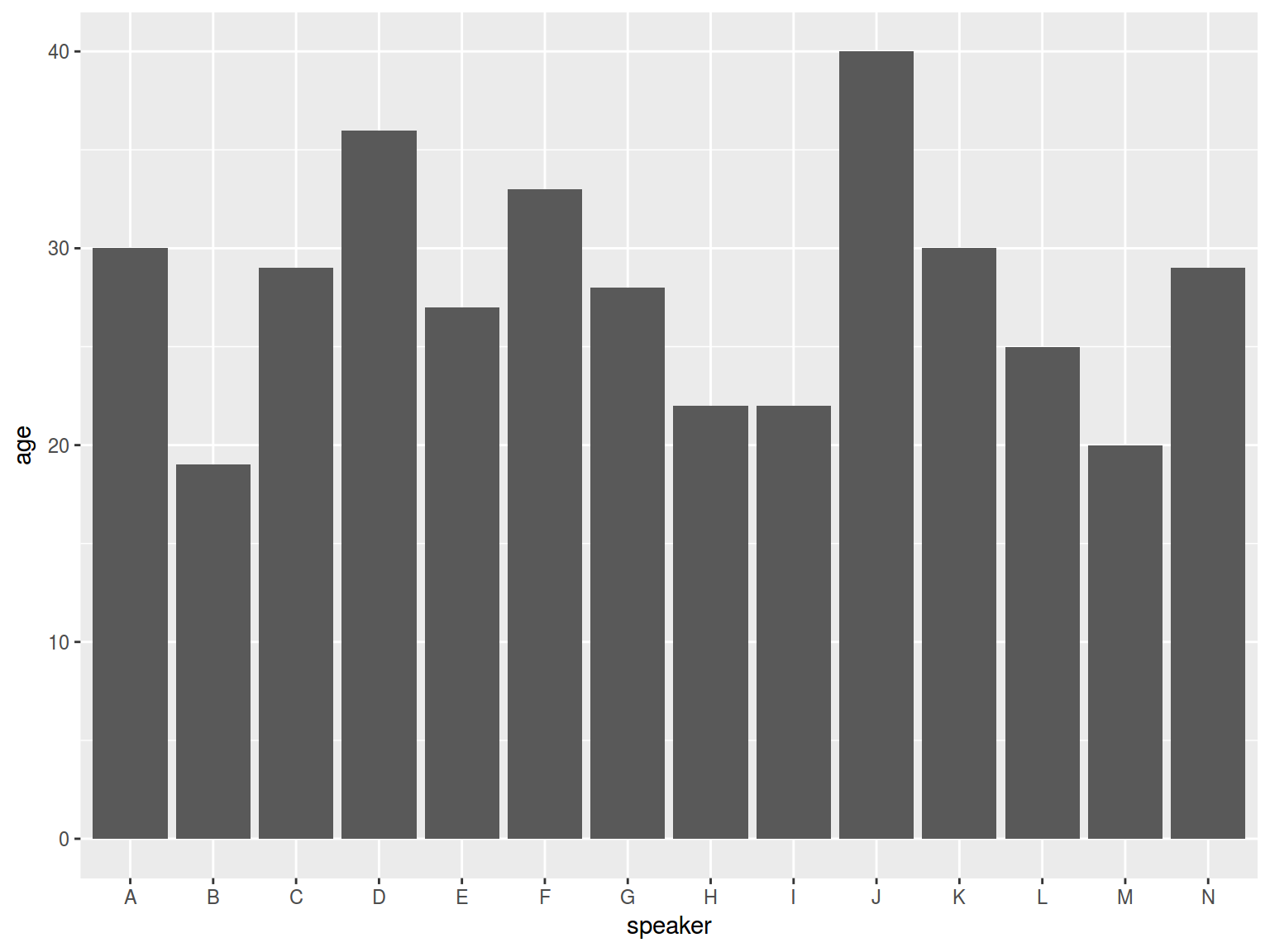
homo %>%
ggplot(aes(speaker, age)) +
geom_bar(stat = "identity")
6.2.2 Barplots: color
barplot(homo$age, names.arg = homo$speaker,
col = homo$orientation)
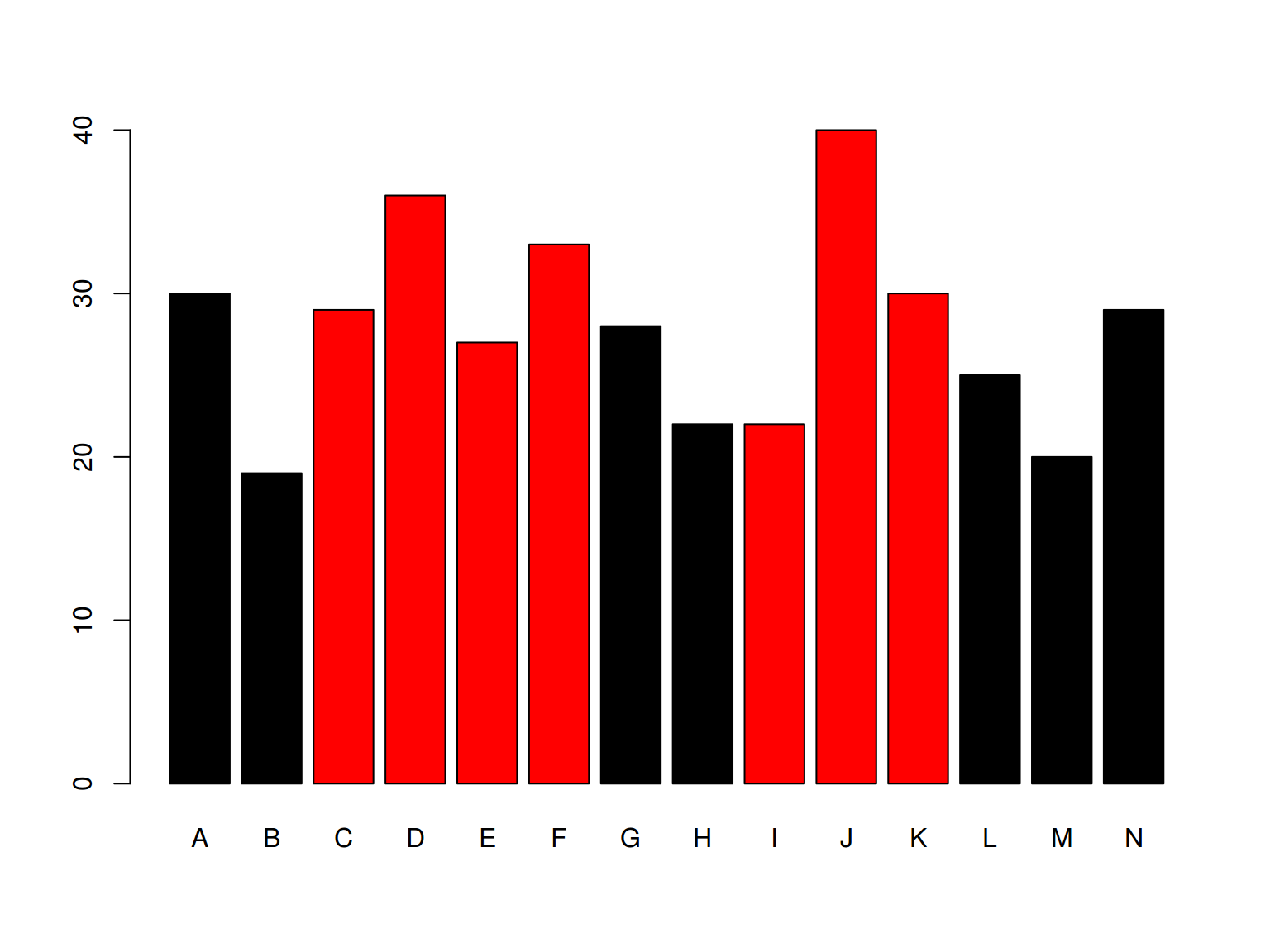 * dplyr, ggplot2
* dplyr, ggplot2
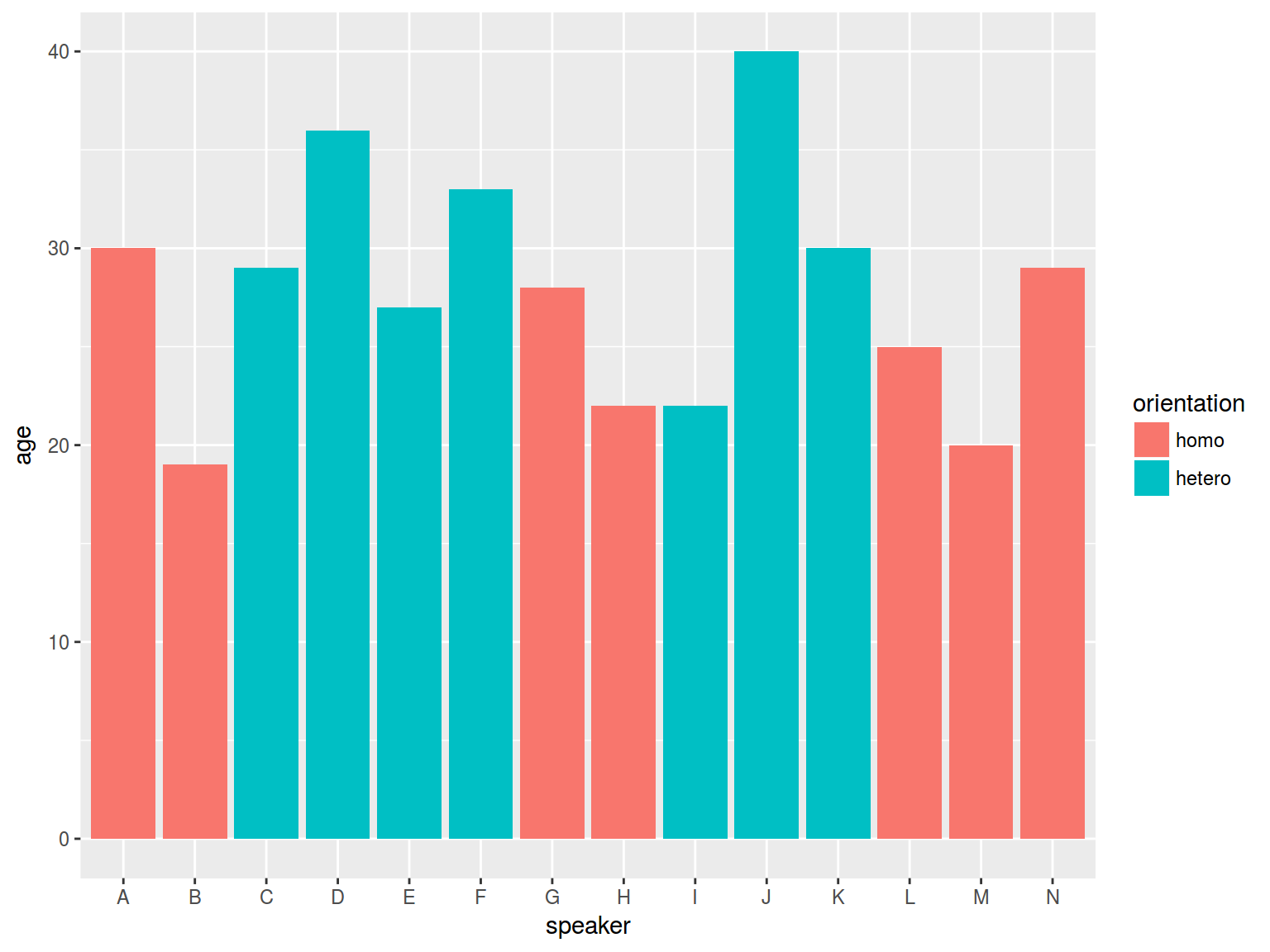
homo %>%
ggplot(aes(speaker, age, fill = orientation)) +
geom_bar(stat = "identity")
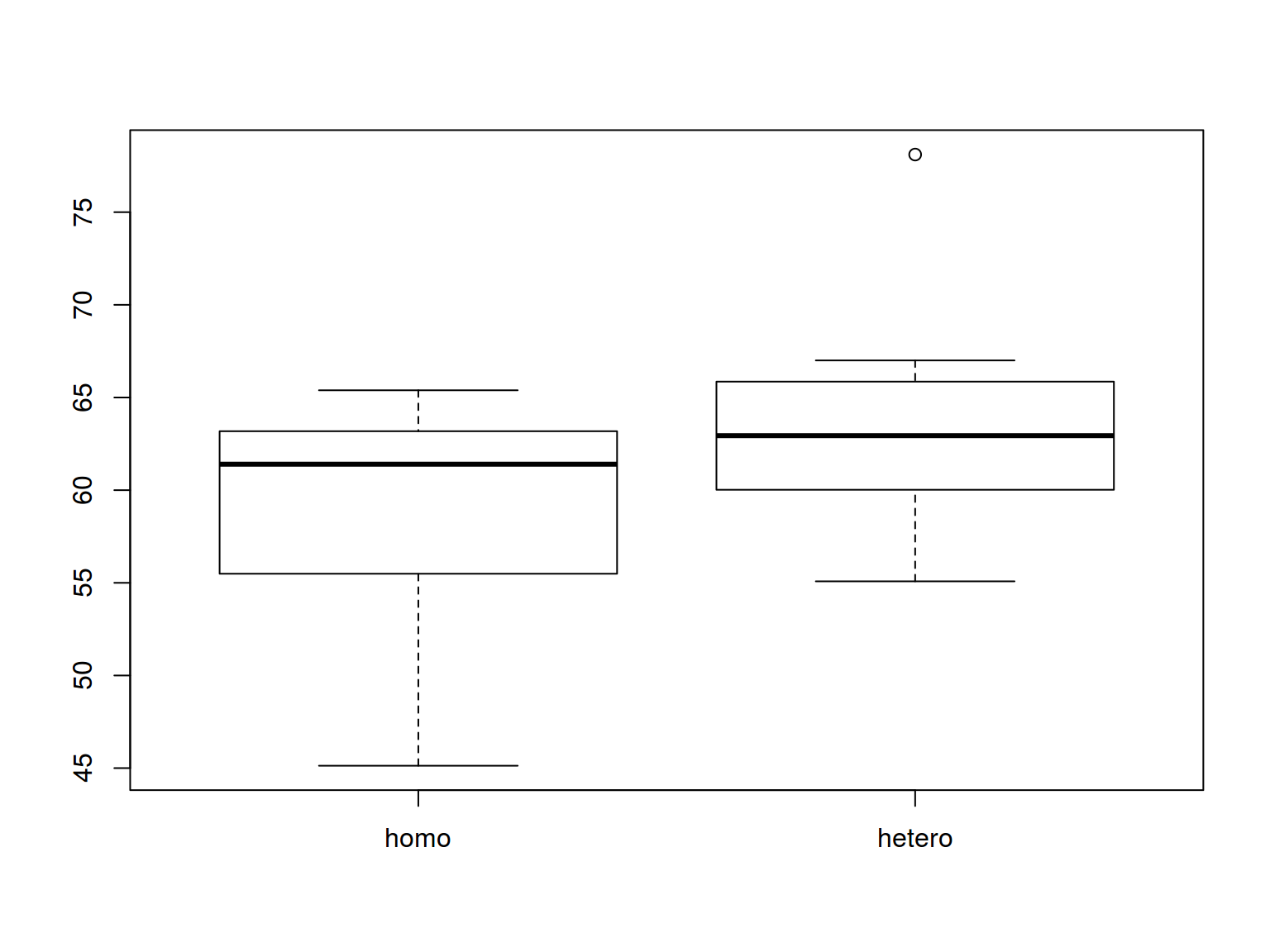
6.3.1 Boxplots: basics
boxplot(homo$s.duration.ms~homo$orientation)
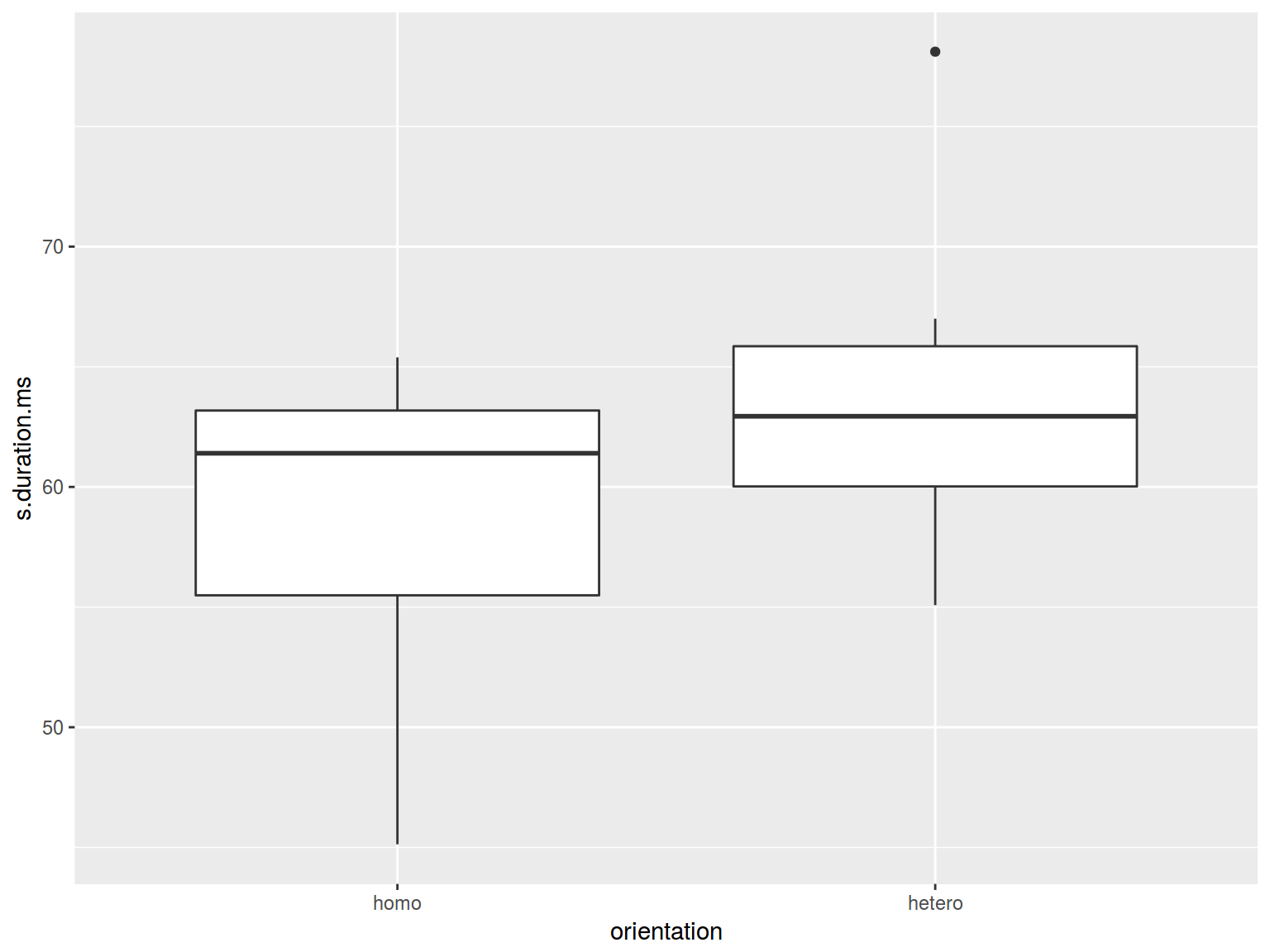
 * dplyr, ggplot2
* dplyr, ggplot2
homo %>%
ggplot(aes(orientation, s.duration.ms)) +
geom_boxplot()
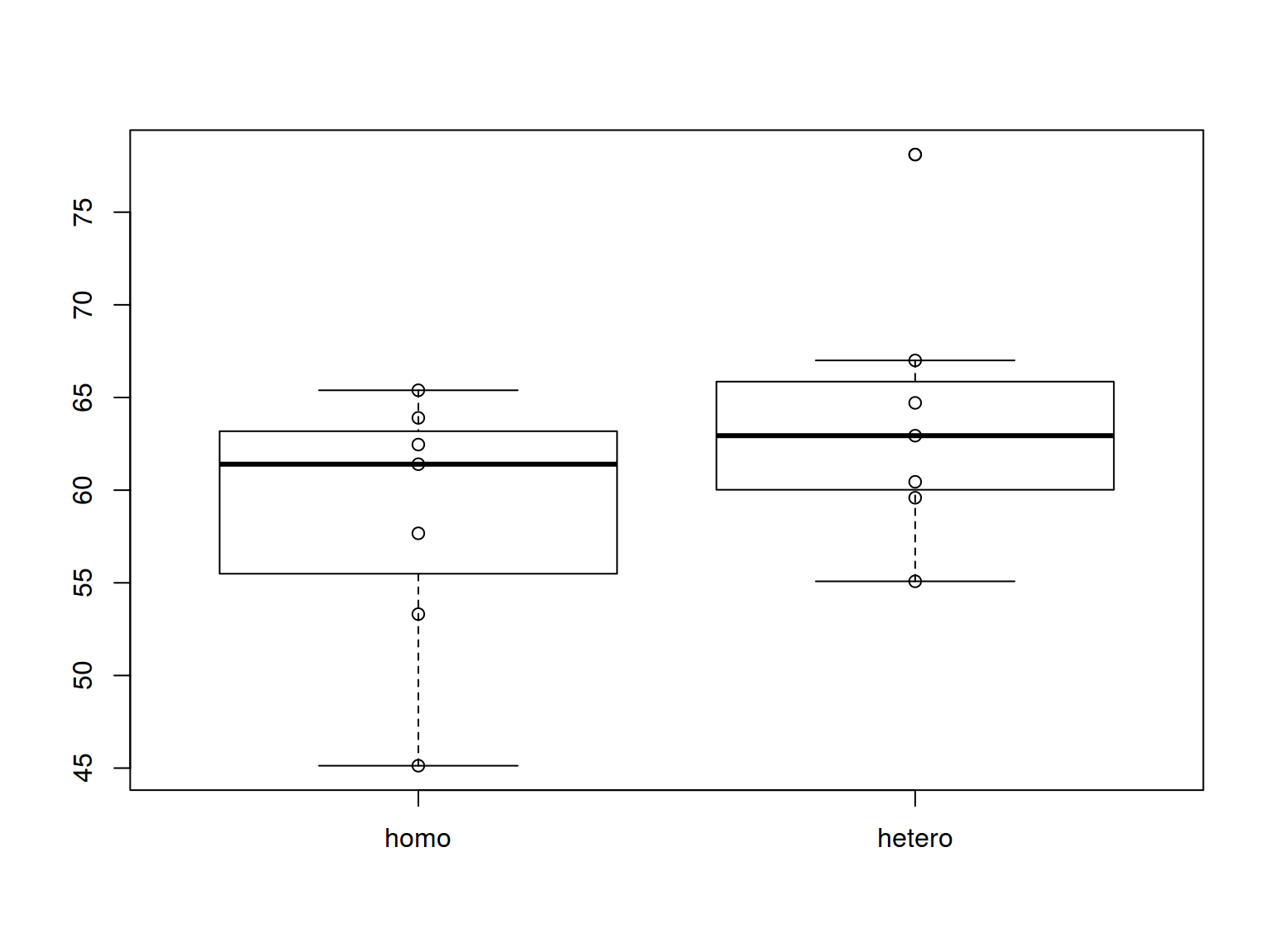
6.3.2 Boxplots: points
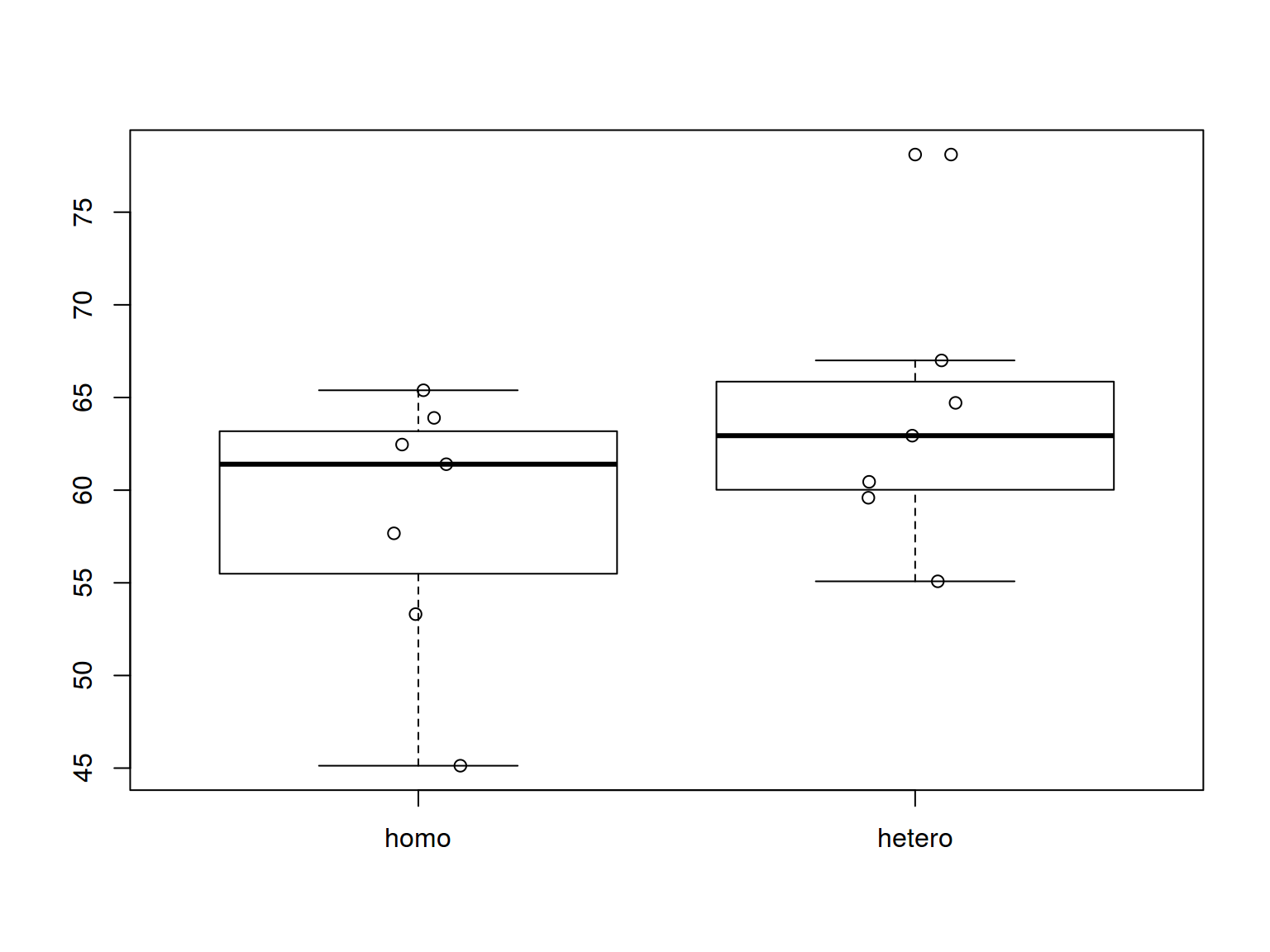
boxplot(homo$s.duration.ms~homo$orientation)
stripchart(homo$s.duration.ms ~ homo$orientation,
pch = 1, vertical = T, add = T)
 * dplyr, ggplot2
* dplyr, ggplot2
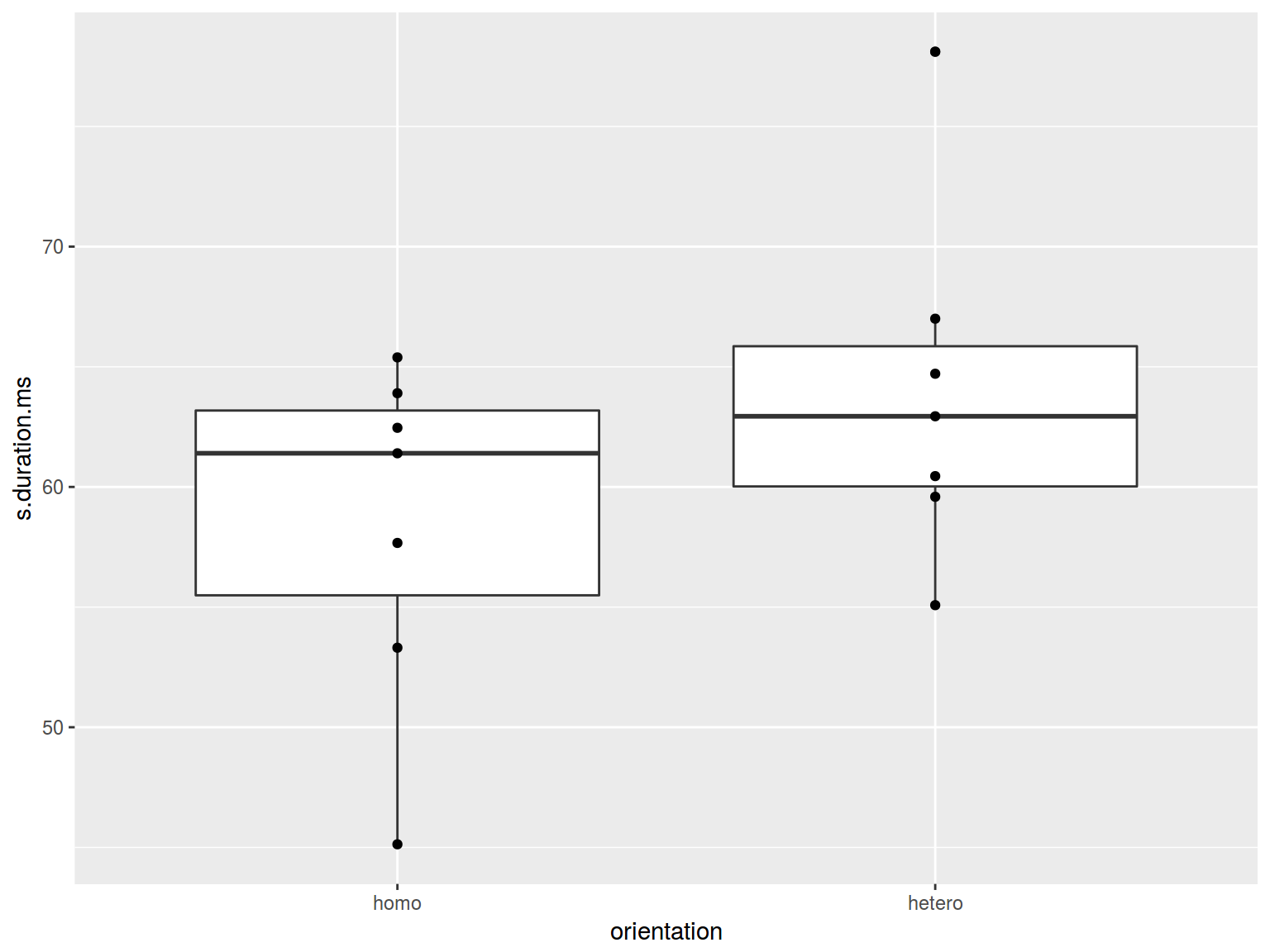
homo %>%
ggplot(aes(orientation, s.duration.ms)) +
geom_boxplot()+
geom_point()
6.3.3 Boxplots: jitter
boxplot(homo$s.duration.ms~homo$orientation)
stripchart(homo$s.duration.ms~homo$orientation,
pch = 1, vertical = T, add = T, method = "jitter")
 * dplyr, ggplot2
* dplyr, ggplot2
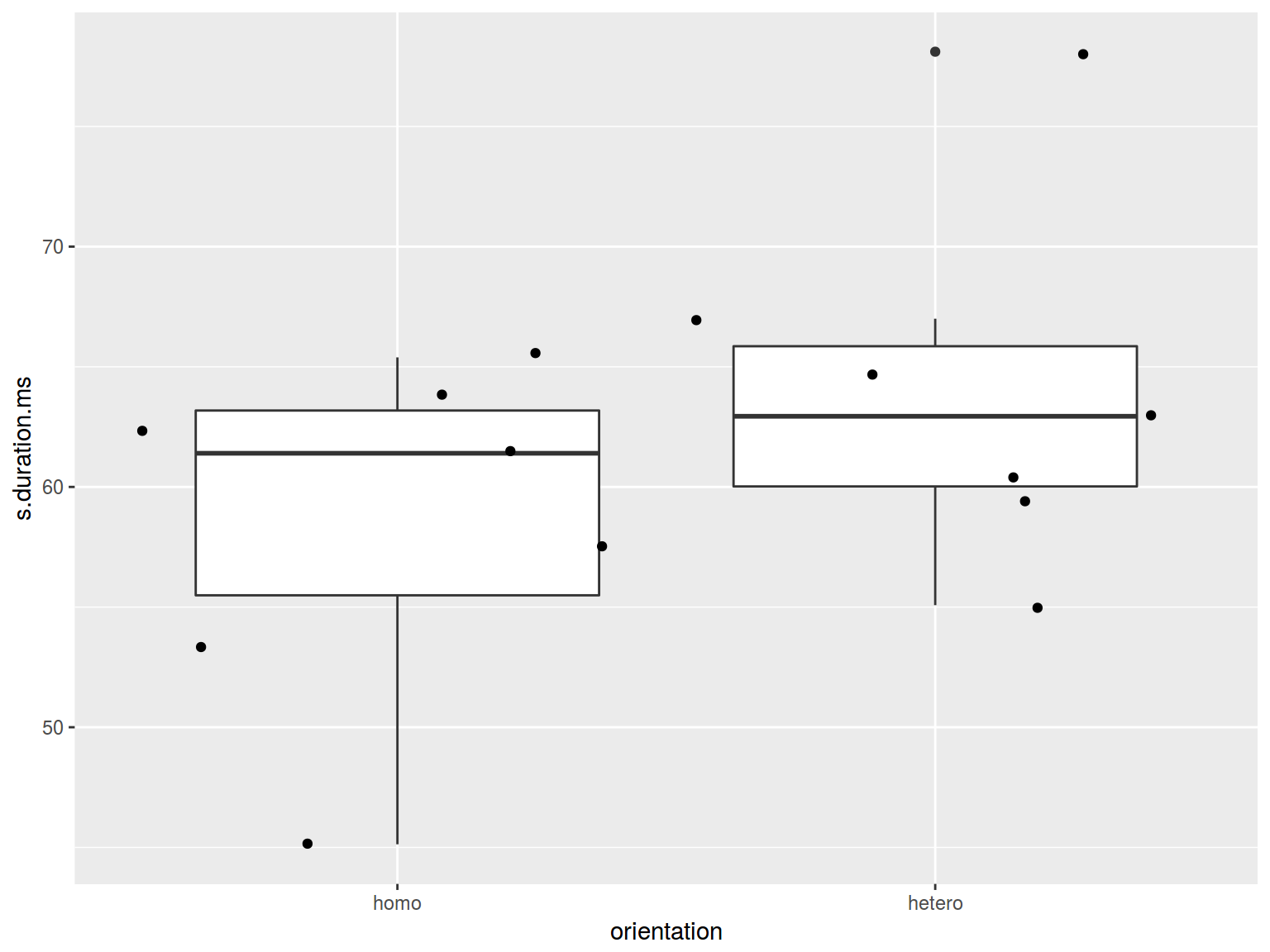
homo %>%
ggplot(aes(orientation, s.duration.ms)) +
geom_boxplot() +
geom_jitter(width = 0.5)
6.3.3 Boxplots: jitter
- base R There is a horrible package vioplot
- dplyr, ggplot2
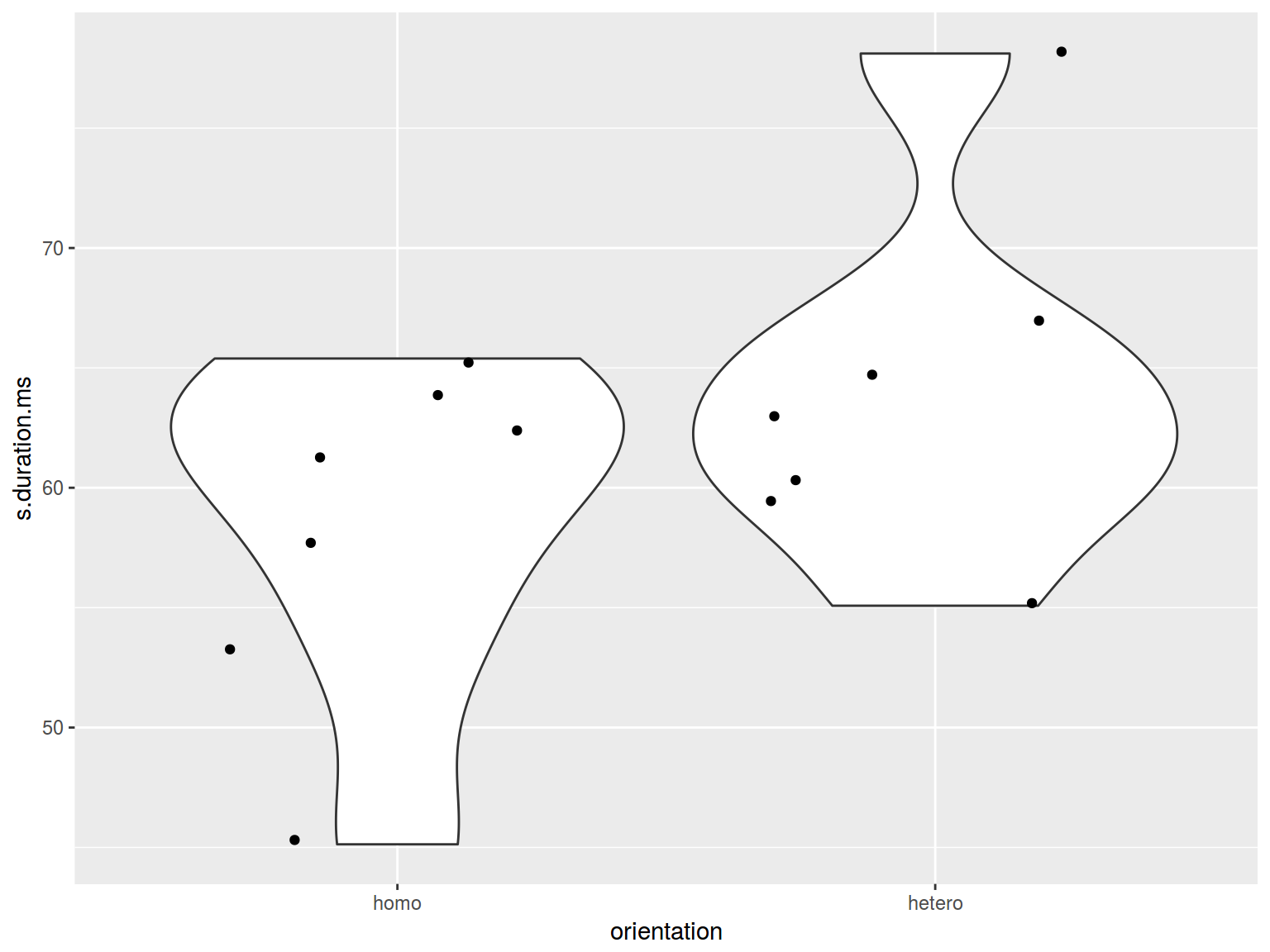
homo %>%
ggplot(aes(orientation, s.duration.ms)) +
geom_violin() +
geom_jitter()
6. Preliminary summary: two variables
- scaterplot: two quantitative varibles
- barplot: nominal varible and one number
- boxplot: nominal varible and quantitative varibles
- jittered points or sized points: two nominal varibles
mtcars %>%
mutate(newvar = mpg > 22,
newvr = mpg < 17) %>%
ggplot(aes(newvr, newvar, color = newvar))+
geom_jitter(width = 0.2)
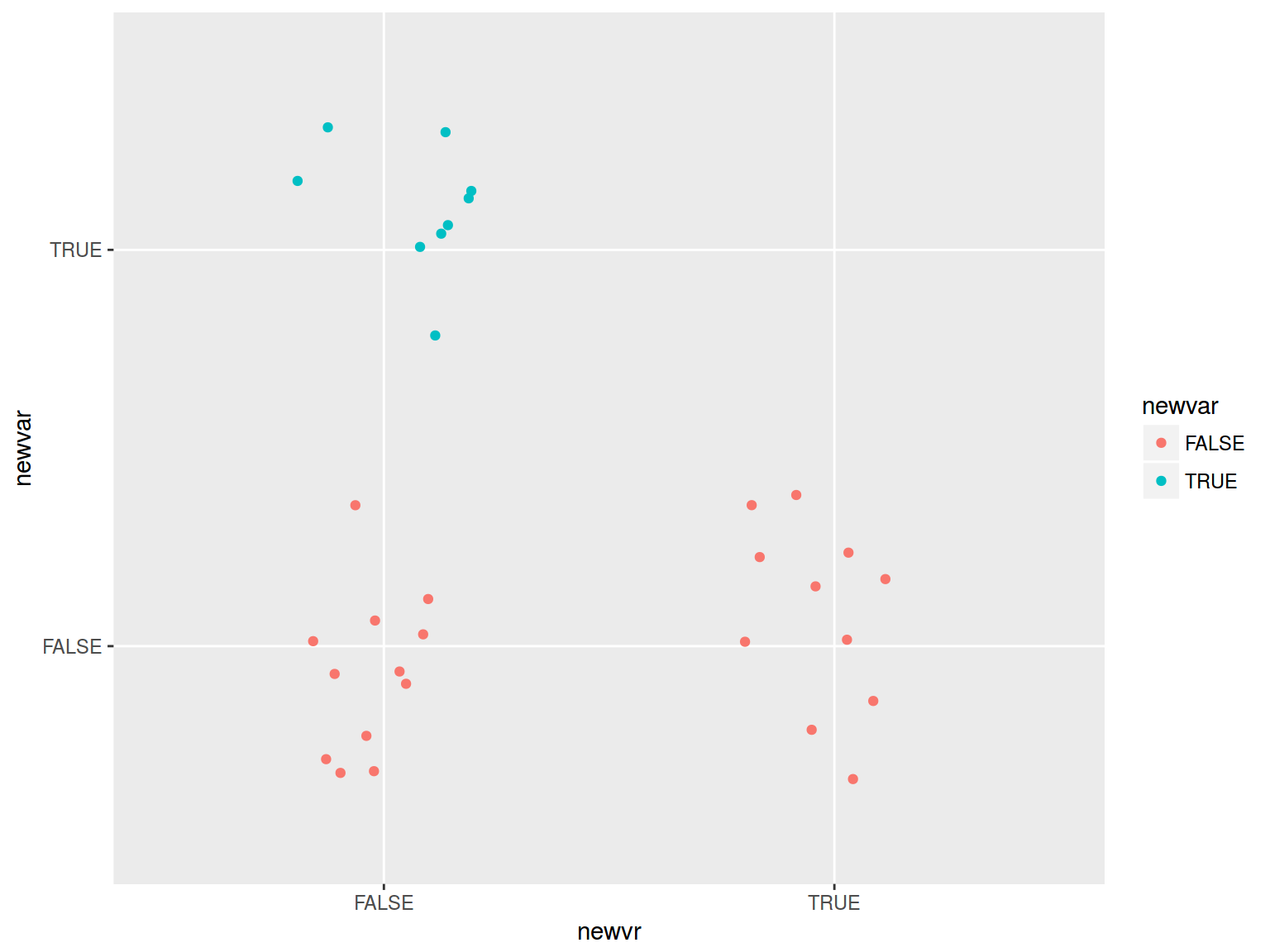
mtcars %>%
mutate(newvar = mpg > 22,
newvr = mpg < 17) %>%
group_by(newvar, newvr) %>%
summarise(number = n()) %>%
ggplot(aes(newvr, newvar, label = number))+
geom_point(aes(size = number, color = newvar))+
geom_text()+
scale_size(range = c(10, 30))+
guides(size = F)
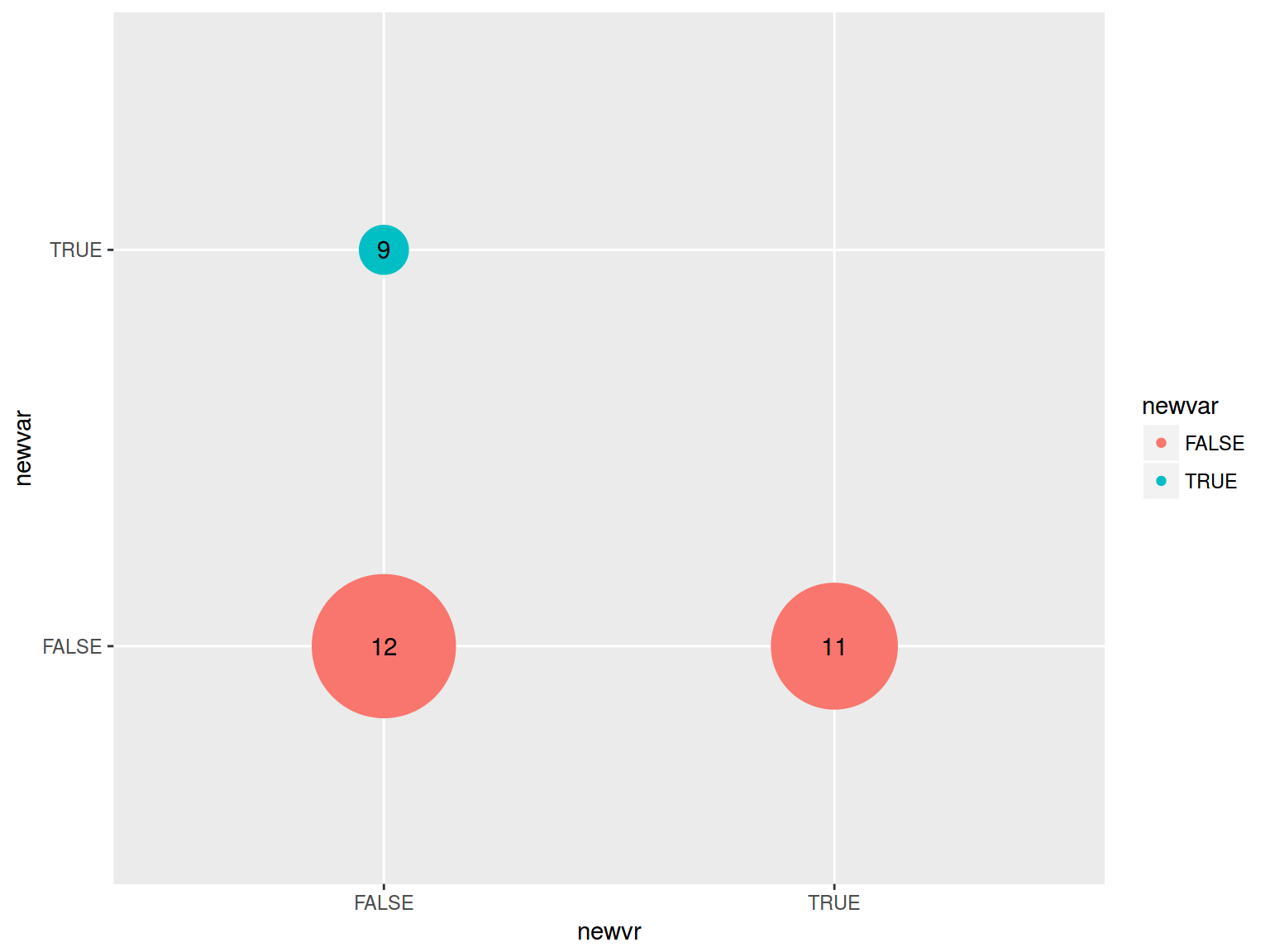
6.6.1 Histogram: basics
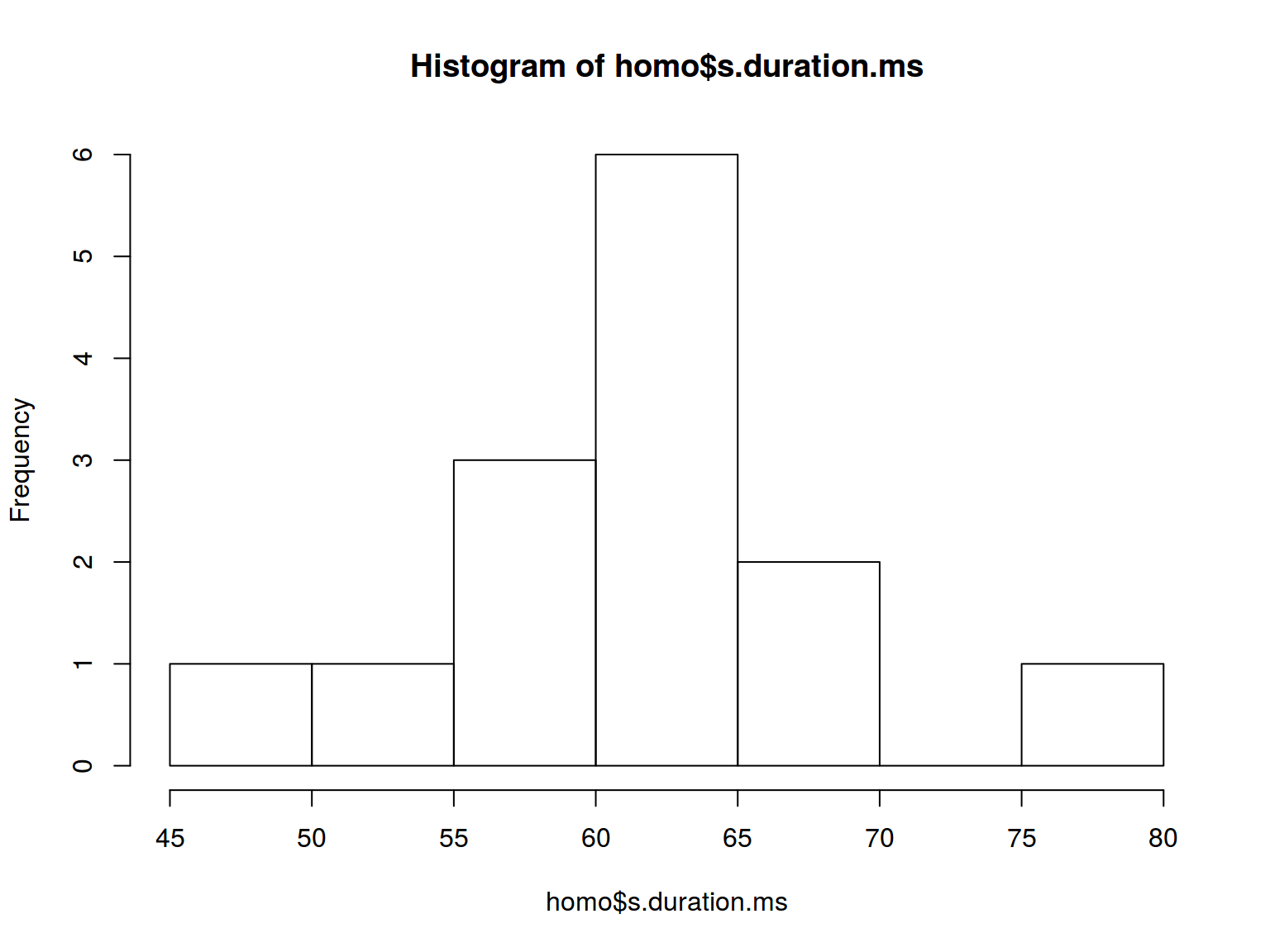 * dplyr, ggplot2
* dplyr, ggplot2
homo %>%
ggplot(aes(s.duration.ms)) +
geom_histogram()
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
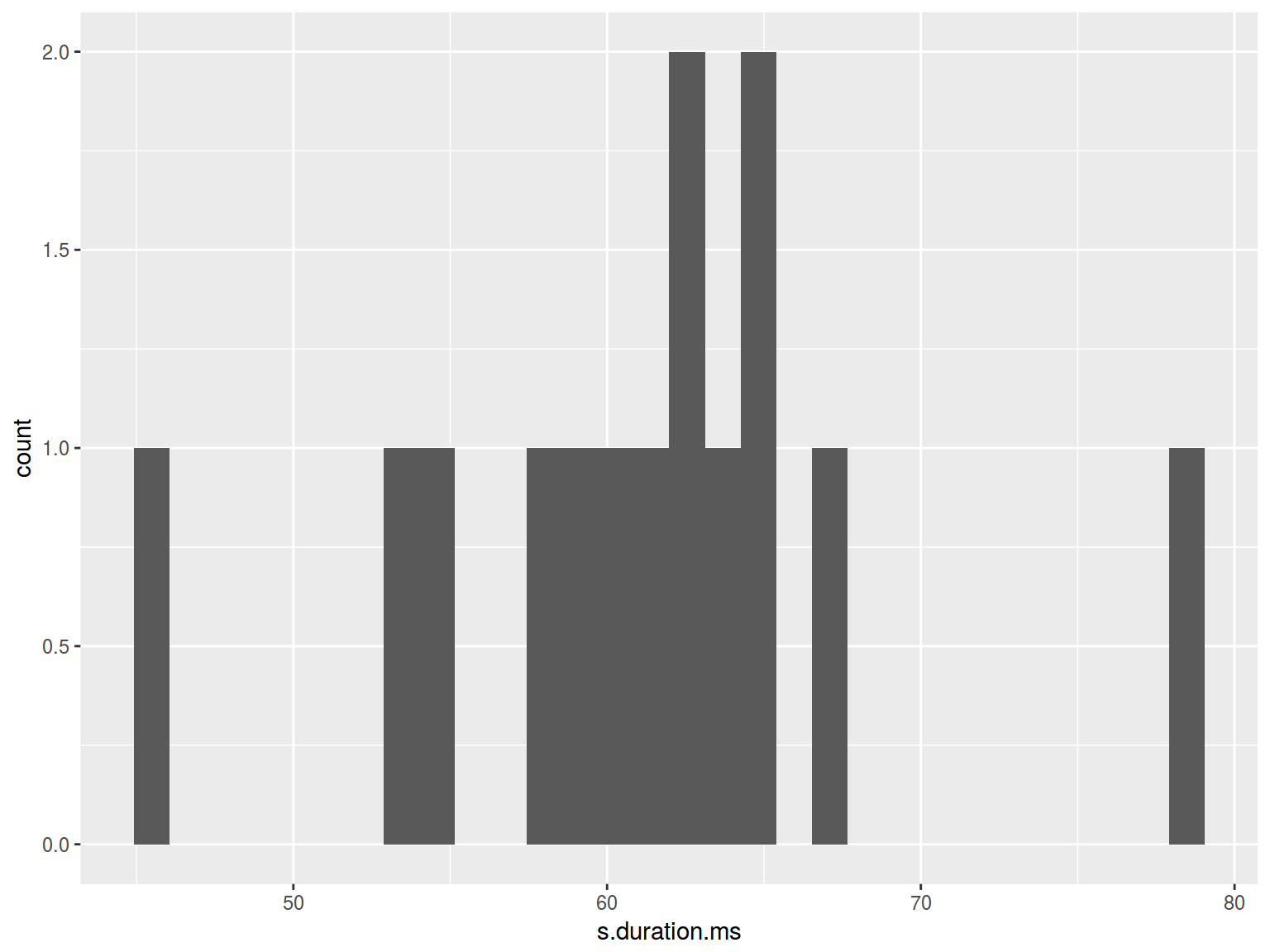 How many histogram bins do we need?
How many histogram bins do we need?
hist(homo$s.duration.ms,
breaks = nclass.FD(homo$s.duration.ms))
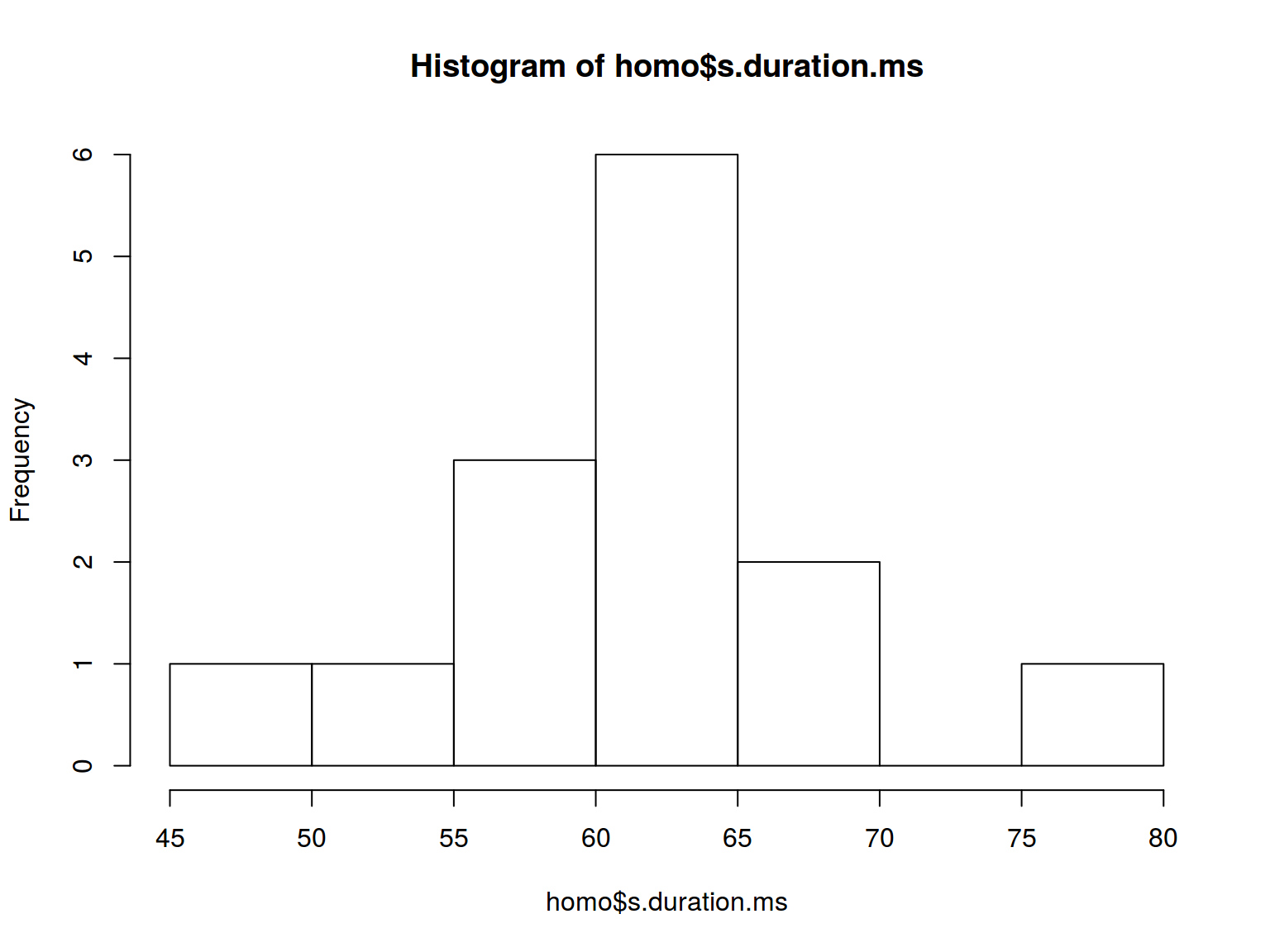 * dplyr, ggplot2
* dplyr, ggplot2
homo %>%
ggplot(aes(s.duration.ms)) +
geom_histogram(bins = nclass.FD(homo$s.duration.ms))
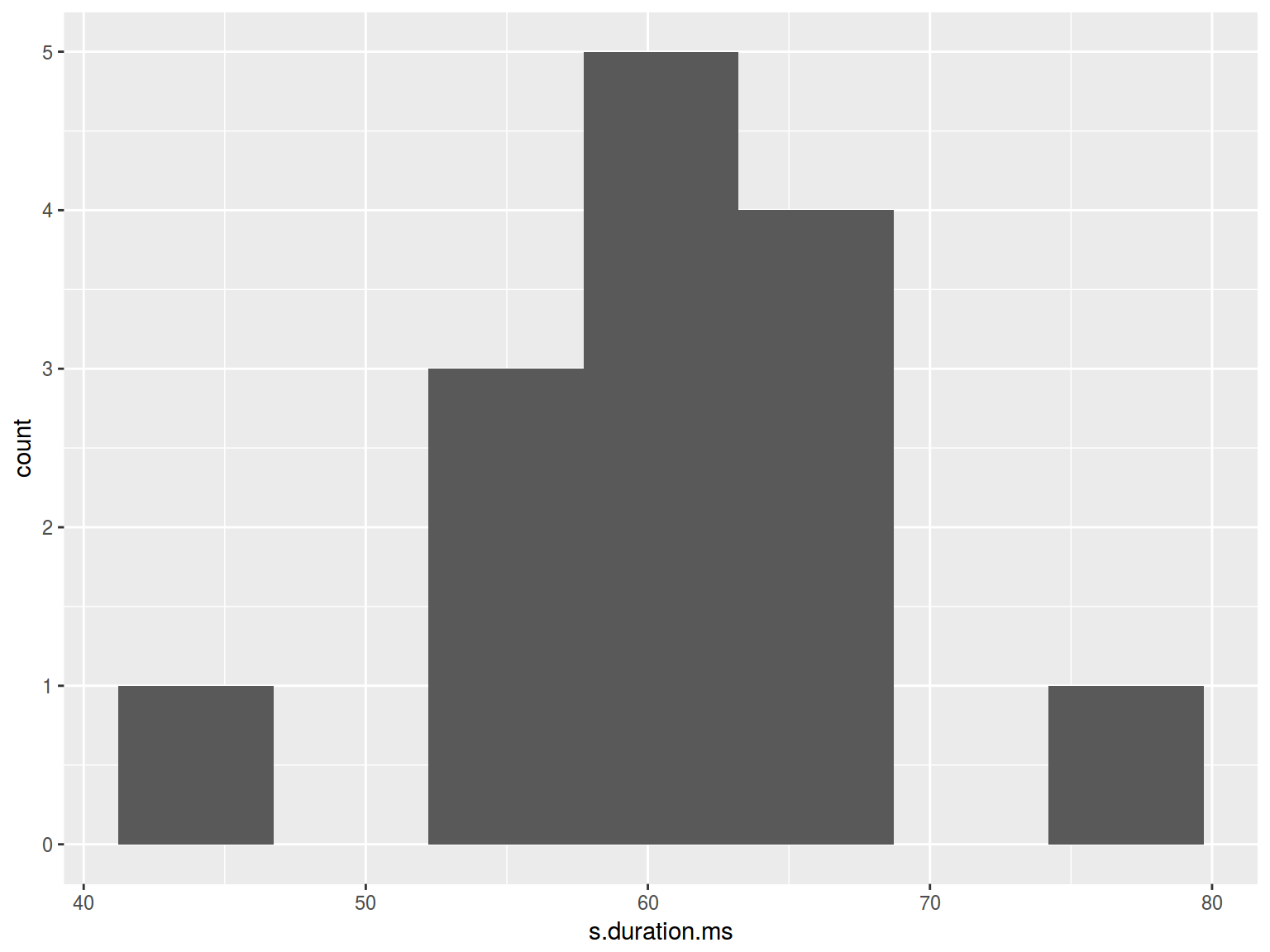
6.6.2 Histogram: color
hist(homo$s.duration.ms, col = "lightblue")
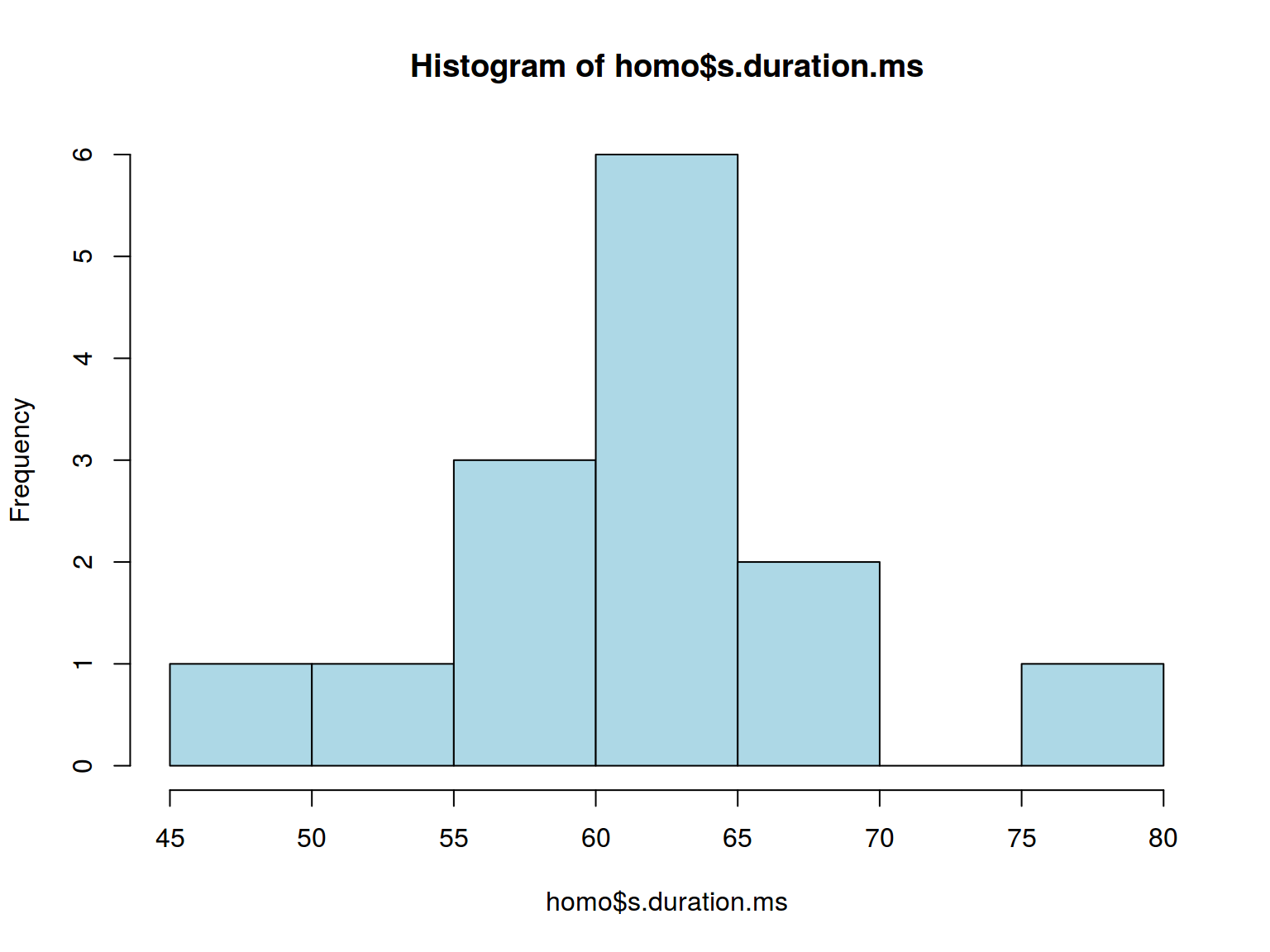 * dplyr, ggplot2
* dplyr, ggplot2
homo %>%
ggplot(aes(s.duration.ms)) +
geom_histogram(fill = "lightblue")
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
6.7 Facets
Facetization is the most powerful ggplot2 tool that allow to split up your data by one or more variables and plot the subsets of data together.
facet_wrap()
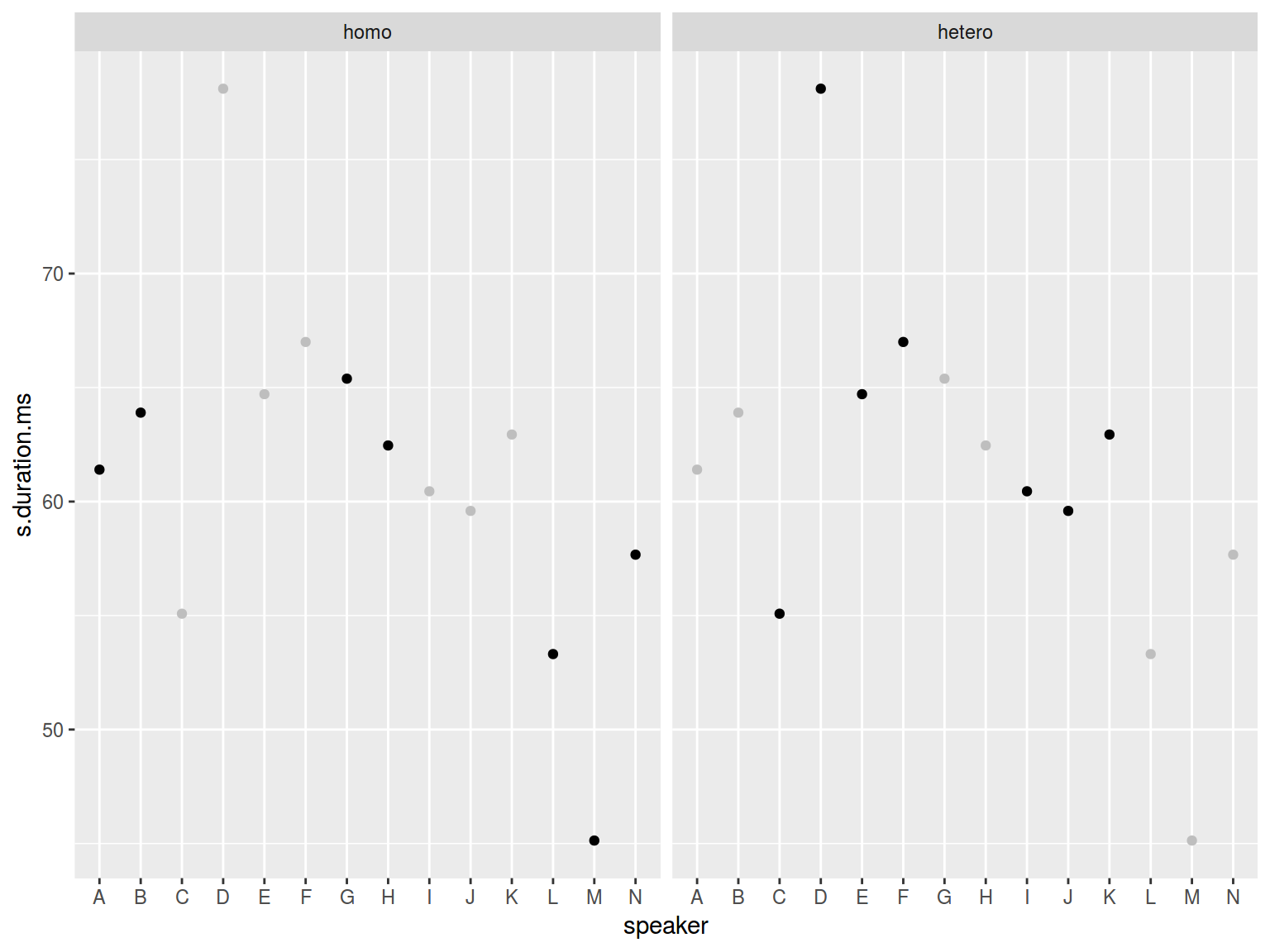
homo %>%
ggplot(aes(speaker, s.duration.ms))+
geom_point() +
facet_wrap(~orientation)
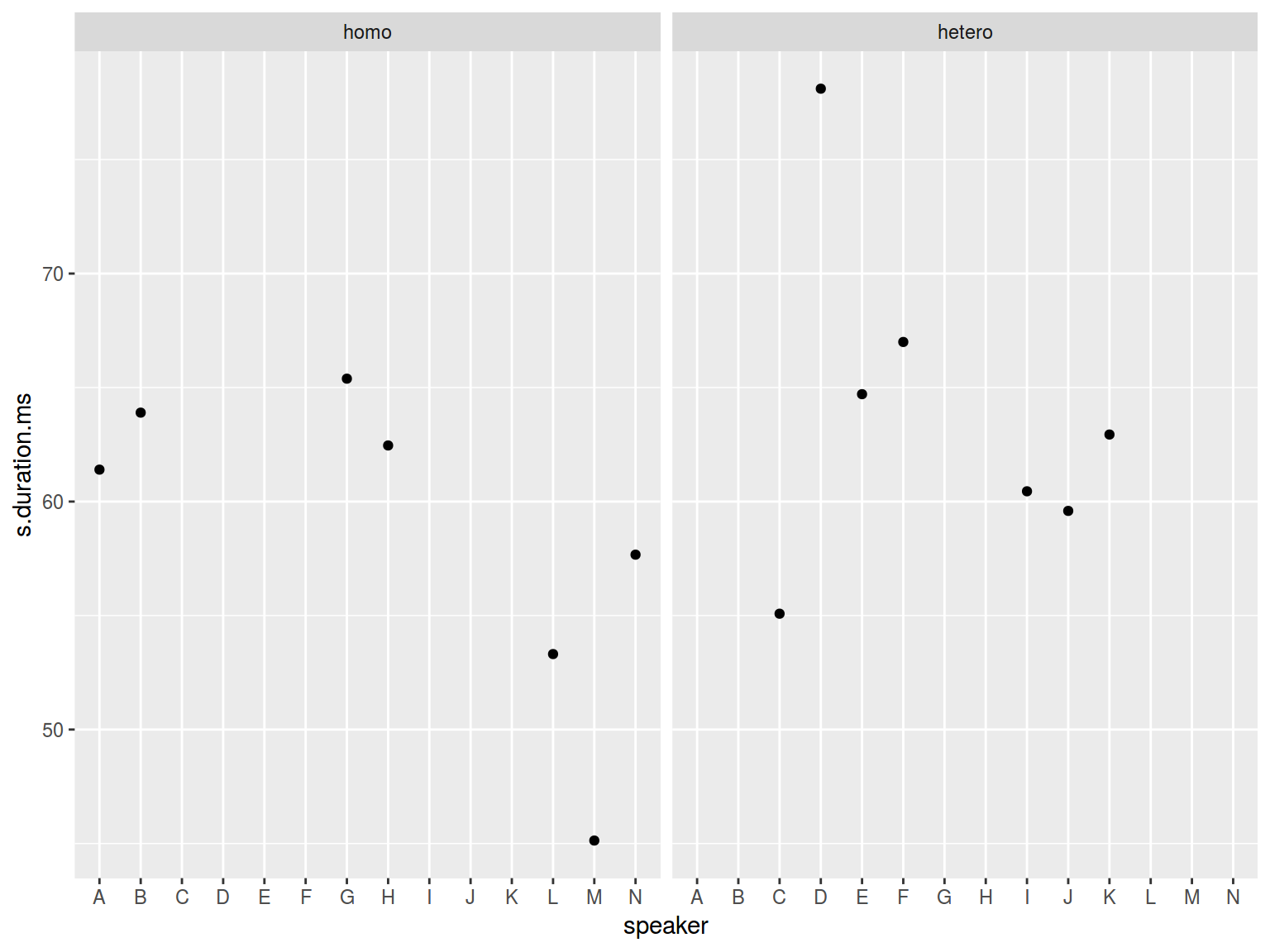
You can see that there are all speakers on both graph, but only certain speakers have dot value. It is because by default scales of facets are equal.
homo %>%
ggplot(aes(speaker, s.duration.ms))+
geom_point() +
facet_wrap(~orientation, scales = "free")
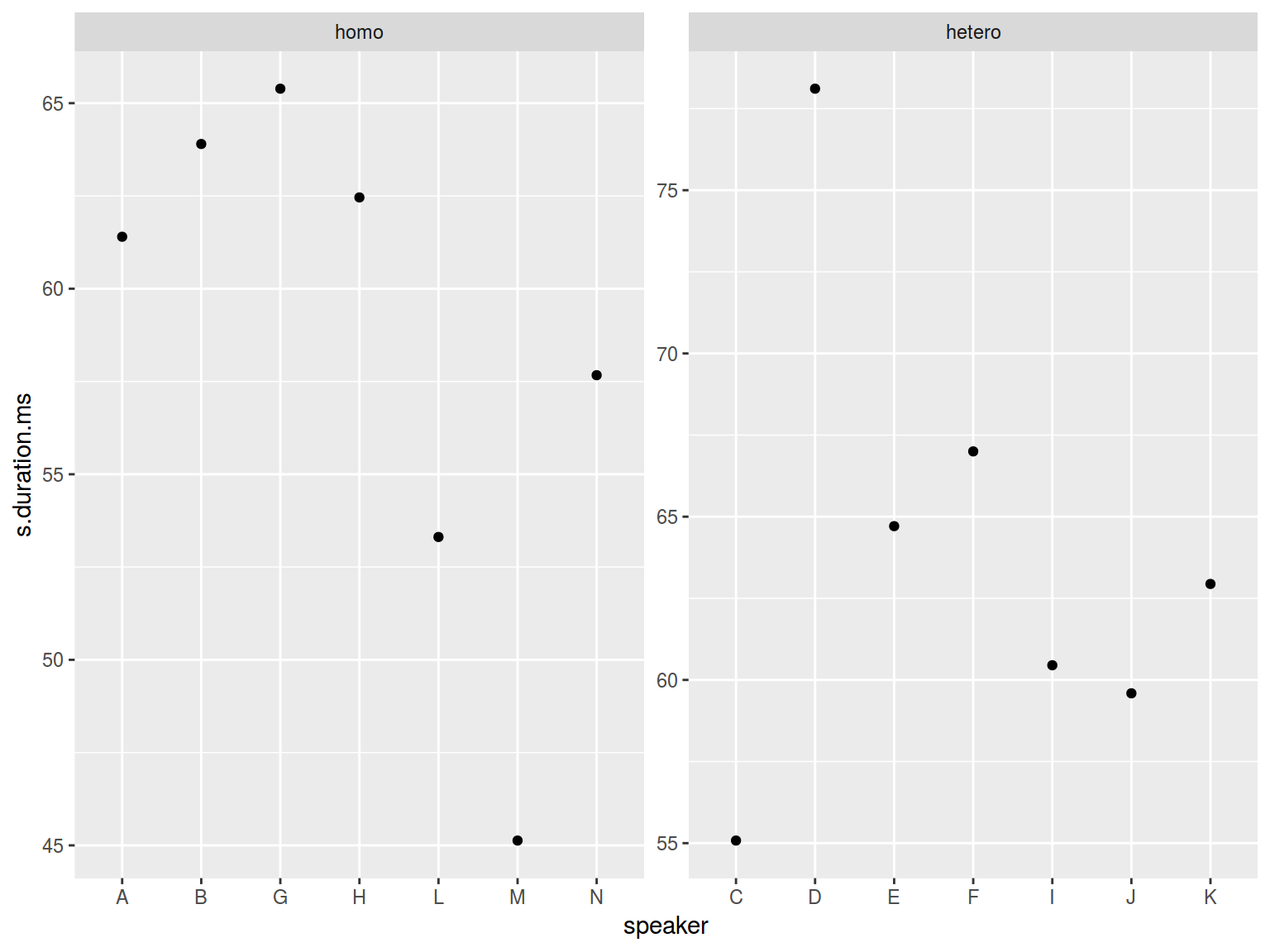
It is possible to make only one scale “free”:
homo %>%
ggplot(aes(speaker, s.duration.ms))+
geom_point() +
facet_wrap(~orientation, scales = "free_x")
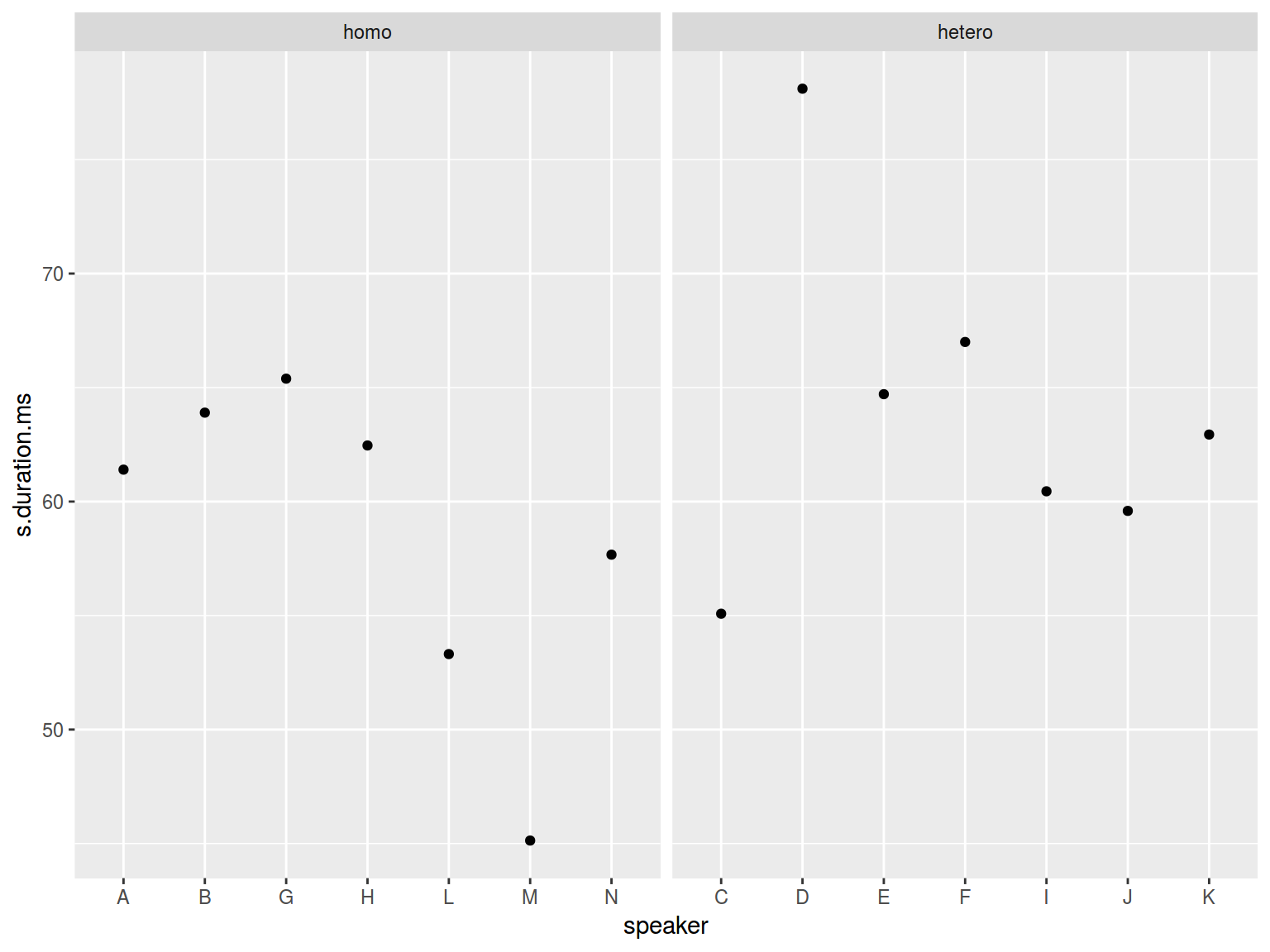
facet_grid()
It is possible to facet using more then one variable.
homo %>%
mutate(older_then_28 = ifelse(age > 28, "older", "younger")) %>%
ggplot(aes(speaker, s.duration.ms))+
geom_point() +
facet_wrap(older_then_28~orientation, scales = "free_x")
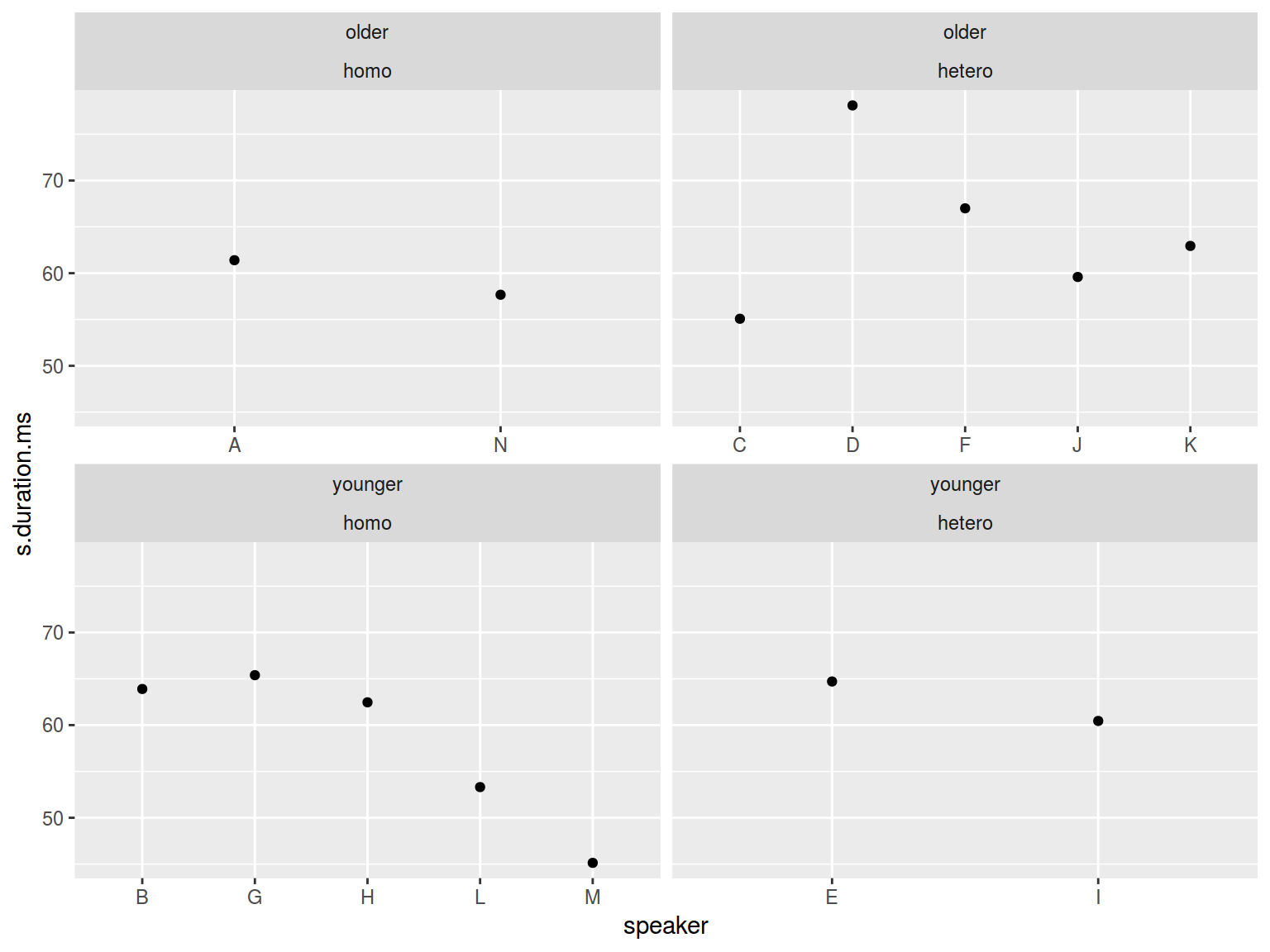
homo %>%
mutate(older_then_28 = ifelse(age > 28, "older", "younger")) %>%
ggplot(aes(speaker, s.duration.ms))+
geom_point() +
facet_grid(older_then_28~orientation, scales = "free_x")
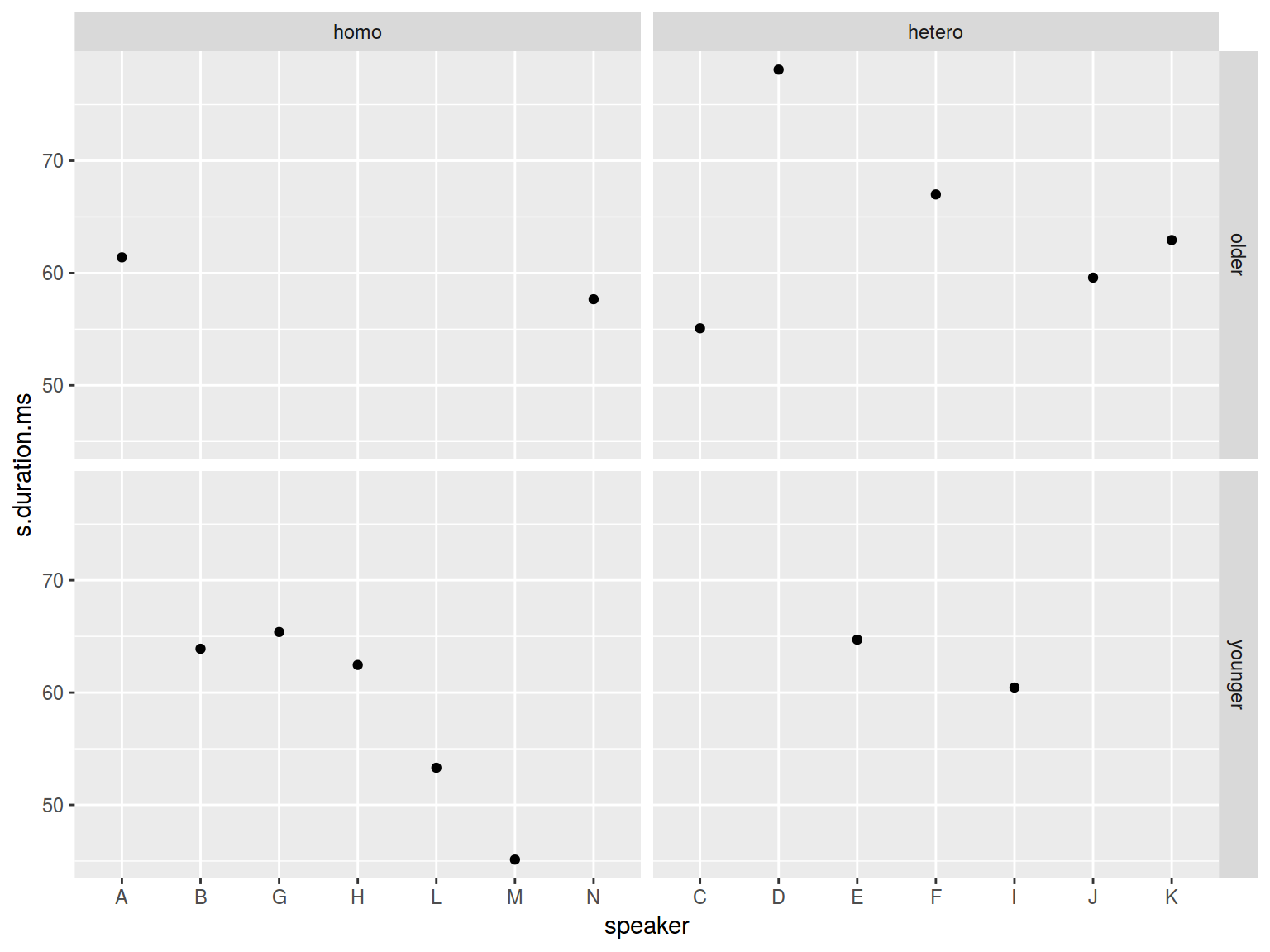
There is a nice argument margins.
homo %>%
mutate(older_then_28 = ifelse(age > 28, "older", "younger")) %>%
ggplot(aes(speaker, s.duration.ms))+
geom_point() +
facet_grid(older_then_28~orientation, scales = "free_x", margins = TRUE)
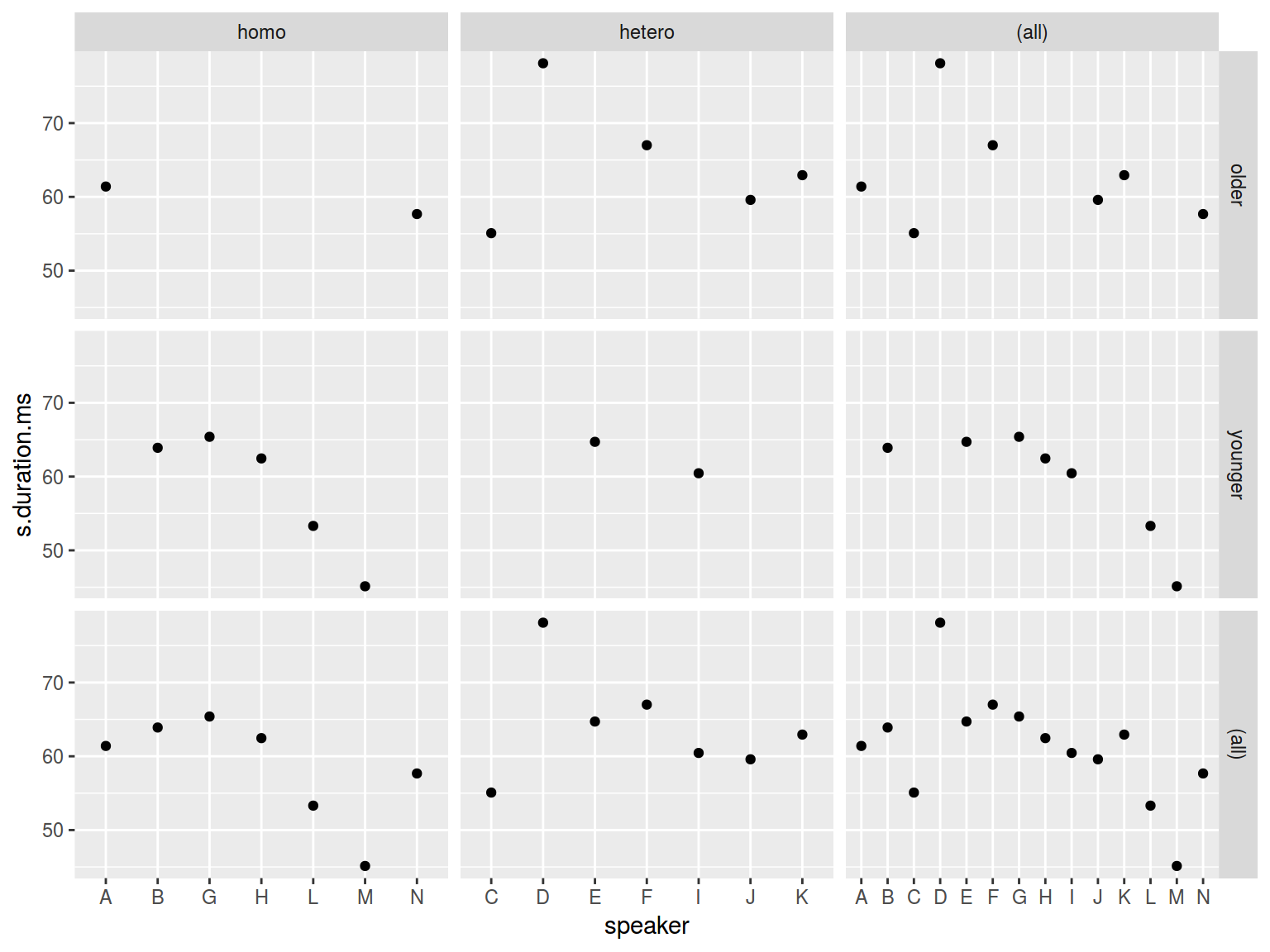
Sometimes it is nice to put your data in all facets:
homo %>%
ggplot(aes(speaker, s.duration.ms))+
# Add an additional geom without facetization variable!
geom_point(data = homo[,-9], aes(speaker, s.duration.ms), color = "grey") +
geom_point() +
facet_wrap(~orientation)