class: center, middle, inverse, title-slide # Daghestanian stops ## temporal structure of Daghestanian stops ### S. Grawunder, G. Moroz, V. Zhigulskaya, M. Daniel ### 2017/11/28 --- class: inverse, center, middle # Motivation --- ## A note on Ejectives: - Ejectives thought to be one of the few pan-Caucasian distinct features (e.g. Chirikba 2008) - although not particularly rare in the Worlds languages, underrepresented in phonetic research embedding in obstruent systems even less understood - ... the more in areal perspective ---  .pull-left[ Zilo speaker: **sit'a** ‘straw’ <audio controls> <source src="https://raw.githubusercontent.com/agricolamz/VOT_talk/master/docs/a_zilo_sit'a_soloma.WAV" type="audio/wav"> </audio> ] .pull-right[ Rutul speaker: **sit'aʔ** ‘bind’ <audio controls> <source src="https://raw.githubusercontent.com/agricolamz/VOT_talk/master/docs/a_kina_sit'a'_zavyazhi.WAV" type="audio/wav"> </audio> ] --- ## CD and VOT values for **sit'a** ‘straw’ and **sit'aʔ** ‘bind’ <!-- --> --- # VOT In 1964, Lisker and Abramson: "the timing of glottal pulsing relative to supraglottal articulation would account for the great majority of homorganic consonantal distinctions traditionally said to depend on voicing, aspiration, "tensity", and the like" (Abramson and Whalen 2017).  --- .pull-left[  ] .pull-right[  .pull-left[Lisker and Abramson (1964)] .pull-right[from Wikipedia] ] --- Abramson & Whalen (2017) argue that VOT is a cross-linguistically useful (and simple) measure, even if not a universal discriminator. - aspirated voiced in Hindi: pʰ, p, b and bʰ. -- both latter sound types show negative VOT, bH showing breathy voice filling before the onset of modal voice) - pre-aspirated in Swedish, Icelandic, Scots Gaelic and Tarascan -- period of aspiration preceding a silent CD - Korean: unaspirated, slightly aspirated and strongly aspirated (degree of VOT) - ejectives: see next slide --- .pull-left[Considering a sample of languages, (Ladefoged & Cho 1999) show that VOT measurements do not directly depend on sound types and oppositions. Below is the sub-sample that has ejectives:] .pull-right[  ] --- .pull-left[Considering a sample of languages, (Ladefoged & Cho 1999) show that VOT measurements do not directly depend on sound types and oppositions. Below is the sub-sample that has ejectives:] .pull-right[ <!-- --> ] --- .pull-left[ In our study, we want to consider how East Caucasian languages perform in terms of temporal structuring (VOT etc.), comparing voiceless and ejective stops.] .pull-right[ <!-- --> ] --- class: inverse, center, middle # Data --- # Villages <div id="htmlwidget-a2513d605a4c3a8e2f01" style="width:748.8px;height:504px;" class="leaflet html-widget"></div> <script type="application/json" data-for="htmlwidget-a2513d605a4c3a8e2f01">{"x":{"options":{"crs":{"crsClass":"L.CRS.EPSG3857","code":null,"proj4def":null,"projectedBounds":null,"options":{}},"zoomControl":false},"calls":[{"method":"addTiles","args":["Stamen.TerrainBackground",null,null,{"minZoom":0,"maxZoom":18,"maxNativeZoom":null,"tileSize":256,"subdomains":"abc","errorTileUrl":"","tms":false,"continuousWorld":false,"noWrap":false,"zoomOffset":0,"zoomReverse":false,"opacity":1,"zIndex":null,"unloadInvisibleTiles":null,"updateWhenIdle":null,"detectRetina":false,"reuseTiles":false}]},{"method":"addProviderTiles","args":["Stamen.TerrainBackground",null,"Stamen.TerrainBackground",{"errorTileUrl":"","noWrap":false,"zIndex":null,"unloadInvisibleTiles":null,"updateWhenIdle":null,"detectRetina":false,"reuseTiles":false}]},{"method":"addCircleMarkers","args":[[42.78139,42.72,42.0647,41.78278,42.13361,42.34333,42.03333,42.23,42.2775,41.69611,41.61667,41.53333,42.19306],[46.31528,46.31861,46.868,46.94475,46.12194,47.32972,47.91667,47.04833,47.23056,47.21444,47.26722,47.41667,45.95833],5.5,null,["Andi","Andi","Archi","Avar","Bezhta","North-Dargwa","Kajtak","Mehweb","Lak","Rutul","Rutul","Rutul","Tsez"],{"lineCap":null,"lineJoin":null,"clickable":true,"pointerEvents":null,"className":"","stroke":false,"color":"black","weight":5,"opacity":0.5,"fill":true,"fillColor":"black","fillOpacity":1,"dashArray":null},null,null,["<a href='http://glottolog.org/resource/languoid/iso/ani' target='_blank'>Andi<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/ani' target='_blank'>Andi<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/aqc' target='_blank'>Archi<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/ava' target='_blank'>Avar<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/kap' target='_blank'>Bezhta<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/dar' target='_blank'>North-Dargwa<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/dar' target='_blank'>Kajtak<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/dar' target='_blank'>Mehweb<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/lbe' target='_blank'>Lak<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/rut' target='_blank'>Rutul<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/rut' target='_blank'>Rutul<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/rut' target='_blank'>Rutul<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/ddo' target='_blank'>Tsez<\/a><br>"],null,null,null,null]},{"method":"addCircleMarkers","args":[[42.78139,42.72,42.0647,41.78278,42.13361,42.34333,42.03333,42.23,42.2775,41.69611,41.61667,41.53333,42.19306],[46.31528,46.31861,46.868,46.94475,46.12194,47.32972,47.91667,47.04833,47.23056,47.21444,47.26722,47.41667,45.95833],5,null,["Andi","Andi","Archi","Avar","Bezhta","North-Dargwa","Kajtak","Mehweb","Lak","Rutul","Rutul","Rutul","Tsez"],{"lineCap":null,"lineJoin":null,"clickable":true,"pointerEvents":null,"className":"","stroke":false,"color":["#CD8500","#CD8500","#32CD32","#FFFF00","#DB7093","#0000CD","#0000FF","#ADD8E6","#D02090","#ADFF2F","#ADFF2F","#ADFF2F","#FF4040"],"weight":5,"opacity":0.5,"fill":true,"fillColor":["#CD8500","#CD8500","#32CD32","#FFFF00","#DB7093","#0000CD","#0000FF","#ADD8E6","#D02090","#ADFF2F","#ADFF2F","#ADFF2F","#FF4040"],"fillOpacity":1,"dashArray":null},null,null,["<a href='http://glottolog.org/resource/languoid/iso/ani' target='_blank'>Andi<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/ani' target='_blank'>Andi<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/aqc' target='_blank'>Archi<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/ava' target='_blank'>Avar<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/kap' target='_blank'>Bezhta<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/dar' target='_blank'>North-Dargwa<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/dar' target='_blank'>Kajtak<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/dar' target='_blank'>Mehweb<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/lbe' target='_blank'>Lak<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/rut' target='_blank'>Rutul<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/rut' target='_blank'>Rutul<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/rut' target='_blank'>Rutul<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/ddo' target='_blank'>Tsez<\/a><br>"],null,null,null,null]},{"method":"addCircleMarkers","args":[[42.78139,42.72,42.0647,41.78278,42.13361,42.34333,42.03333,42.23,42.2775,41.69611,41.61667,41.53333,42.19306],[46.31528,46.31861,46.868,46.94475,46.12194,47.32972,47.91667,47.04833,47.23056,47.21444,47.26722,47.41667,45.95833],15,null,["Andi","Andi","Archi","Avar","Bezhta","North-Dargwa","Kajtak","Mehweb","Lak","Rutul","Rutul","Rutul","Tsez"],{"lineCap":null,"lineJoin":null,"clickable":true,"pointerEvents":null,"className":"","stroke":false,"color":"blue","weight":5,"opacity":0.5,"fill":true,"fillColor":"blue","fillOpacity":0,"dashArray":null},null,null,["<a href='http://glottolog.org/resource/languoid/iso/ani' target='_blank'>Andi<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/ani' target='_blank'>Andi<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/aqc' target='_blank'>Archi<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/ava' target='_blank'>Avar<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/kap' target='_blank'>Bezhta<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/dar' target='_blank'>North-Dargwa<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/dar' target='_blank'>Kajtak<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/dar' target='_blank'>Mehweb<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/lbe' target='_blank'>Lak<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/rut' target='_blank'>Rutul<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/rut' target='_blank'>Rutul<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/rut' target='_blank'>Rutul<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/ddo' target='_blank'>Tsez<\/a><br>"],null,["Rikvani","Zilo","Archi","Kusur","Bezhta","Cuxta","Javgat","Mehweb","Balkhar","Ikhrek","Kina","Rutul","Kidero"],{"clickable":false,"noHide":true,"direction":"right","opacity":1,"offset":[12,-15],"textsize":"10px","textOnly":true,"style":{"font-size":"19px"},"zoomAnimation":true,"className":""},null]},{"method":"addScaleBar","args":[{"maxWidth":100,"metric":true,"imperial":true,"updateWhenIdle":true,"position":"bottomleft"}]},{"method":"addLegend","args":[{"colors":["#CD8500","#32CD32","#FFFF00","#DB7093","#0000FF","#D02090","#ADD8E6","#0000CD","#ADFF2F","#FF4040"],"labels":["Andi","Archi","Avar","Bezhta","Kajtak","Lak","Mehweb","North-Dargwa","Rutul","Tsez"],"na_color":null,"na_label":"NA","opacity":1,"position":"topright","type":"factor","title":null,"extra":null,"layerId":null,"className":"info legend"}]},{"method":"addMiniMap","args":[null,null,"topleft",150,150,19,19,-5,false,false,false,true,false,false,{"color":"#ff7800","weight":1,"clickable":false},{"color":"#000000","weight":1,"clickable":false,"opacity":0,"fillOpacity":0},{"hideText":"Hide MiniMap","showText":"Show MiniMap"},[]]}],"limits":{"lat":[41.53333,42.78139],"lng":[45.95833,47.91667]}},"evals":[],"jsHooks":[]}</script> --- # Speakers by village <!-- --> --- # Speakers by language <!-- --> --- # Features of stops and affricates - **POA**: labial; dentalv; lateral; velar; uvular - **manner**: stops; affricates - **phonation type**: voiced; voiceless; ejective - **geminates** ADDITIONALLY: - **labialization** - **pharyngealization** --- # Measurements - Closure Duration (cd) - Voice Onset Time (vot) - Friction part / burst (f) - Post-friction part (pf) - Following vowel duration - Creaky voice part of the vowel (cv) - Modal Voice part (m) - (Intensity contour) --- # Measurements The word **kʷatʃʼa** ‘paw’ by Zilo speaker m_11:  --- # Lists of words - only existing words (non-words were at first used in Mehweb and then discarded) - three repetitions followed by a carrier phrase - all places of articulation X phonation type → sound type - when possible, two or more lexical items recorded for each sound and in each position --- # Lists of words - keep the wordlist manageable (several dozens up to 40-60 words, 10-20 minutes recording session) - phonetic context preferences: aCa > VCa > VCi, VCe (but not in Andi) - stress position not controlled - eliciting words by a Russian translation, sometimes the target word hinted in a half voice or, ideally, distorted --- class: inverse, center, middle # Results so far --- # Analysis - 15 Kinas (Rutul), 16 Zilos (Andi) - Annotation in Praat by K. Filatov, V. Ivanova, A. Kopeckiy, G. Moroz, A. Safonova, M. Sheyanova, I. Sieber, A. Zakirova, V. Zhigulskaya - Data extraction with [**Praat Script by S. Grawunder**](https://raw.githubusercontent.com/agricolamz/VOT_talk/master/segment_durations_1f.praat) - Data analysis and visulization [**with R** by G. Moroz](https://raw.githubusercontent.com/agricolamz/VOT_talk/master/docs/index.Rmd) --- class: inverse, center, middle # Stops: exploratory visualisation --- # Absolute values of CD (medial) <!-- --> --- # Absolute values of VOT (medial) <!-- --> --- # Absolute values of CD ~ VOT (medial) <!-- --> --- class: inverse, center, middle # Relative values: measure / (CD + VOT) --- # Relative values: CD / (CD + VOT) <!-- --> --- # Relative values: VOT / (CD + VOT) 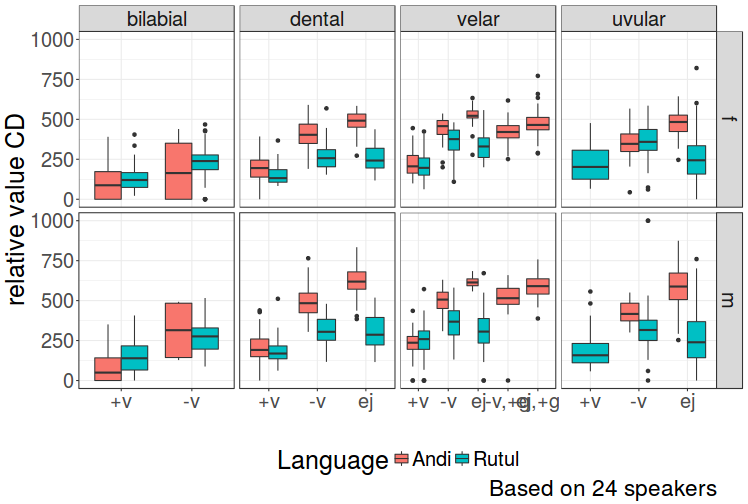<!-- --> --- class: inverse, center, middle # Relative values: measure / vowel duration --- # Relative values: CD / vowel duration 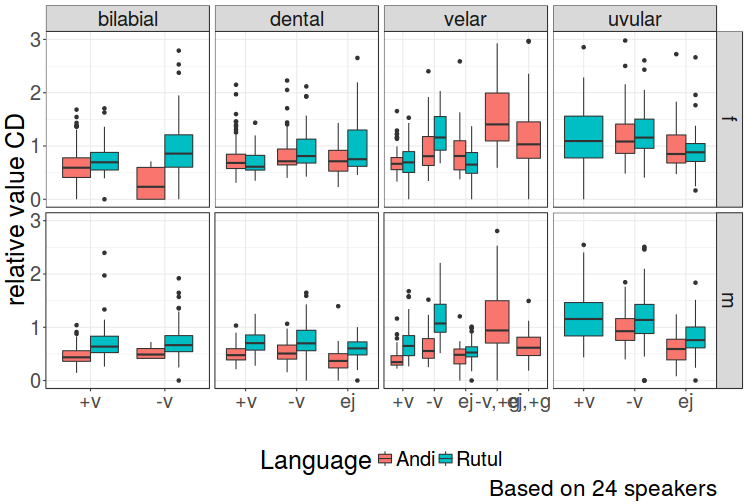<!-- --> --- # Relative values: VOT / vowel duration 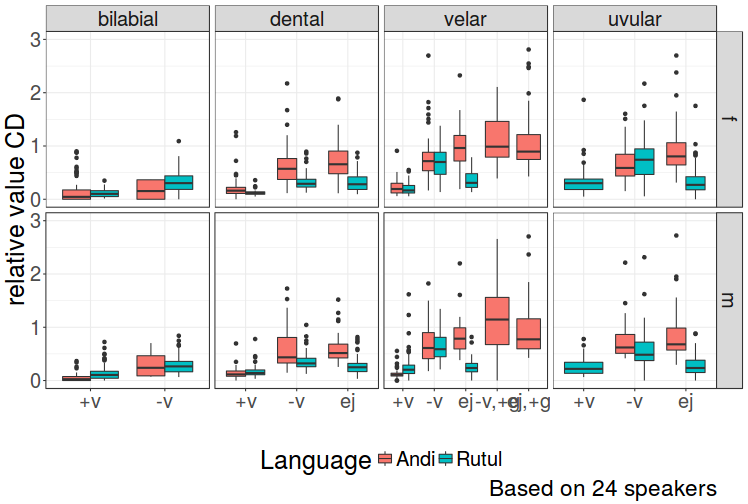<!-- --> --- # Methodological issues - reliability and comparability of annotations made by different annotators -- - we need selective re-annotation and to compare the annotations and calculate - agreement per each of the features that we annotated (e. g. **Cohen's or Fleiss’s kappa**); - agreement for time segmentation that we annotated (e. g. **St Dev**). -- - phonological interpretations -- : _q_ or _q͡χ_? --- # Methodological issues - different contexts -- : lists of words were compiled using different principles (no voiced in Mehweb, very few speakers in Archi, no control for the following vowel quality in Andi etc.). -- - possibility of loan phonetics? -- - speaker inconsistency: some speak casually and some dictate (normalization?) -- - different sound recordings conditions -- : headset microphone vs. pure recorder' microphones; different recorders; --- class: center, middle # Thanks! Misha Daniel (misha.daniel@gmail.com) Sven Grawunder (grawunder@eva.mpg.de ) Garik Moroz (agricolamz@gmail.com) Vasilisa Zhigulskaya (vasilek224@bk.ru) Slides created with the following R packages: [**ggjoy**](https://CRAN.R-project.org/package=ggjoy) [**ggplot2**](http://ggplot2.org) [**lingtypology**](https://ropensci.github.io/lingtypology/) [**xaringan**](https://github.com/yihui/xaringan)