5 Работа с текстами: gutenbergr, tidytext, stopwords, udpipe
Привет, дорогие пацаны и пацанессы!
День второй, вы, предположительно, поразвлекались с регулярками, жизнь продолжается, давайте же анализировать тексты!
В этом эпизоде сериала АйсДан мы выясним, как обычно выглядят текстовые данные (и откуда их, кстати, брать!), как мы хотим, чтобы текстовые данные выглядели, и как перевести одно в другое. Бонус: смешные графики!
Для начала давайте установим нужные библиотеки:
5.1 Загрузка текста в R
В пакете readr, который входит в tidyverse, есть функция read_lines(). Такая же по сути функция есть в base R, она называется readLines(), но она работает гораздо медленнее, так что мы ей пользоваться не будем.
read_lines() принимает на вход путь к файлу с текстом на вашем компьютере или ссылку на файл в Интернете. Например, у Гарика на гитхабе есть документ с текстом книги Теда Чана “История твоей жизни” (судя по Википедии, это научно-фантастическая повесть о лингвистке, изучающей язык пришельцев. Звучит прикольно). Давайте считаем этот файл.
t <- read_lines("https://raw.githubusercontent.com/agricolamz/2020_HSE_DPO/master/data/Chang.txt")
head(t)[1] "Тед Чан"
[2] "История твоей жизни"
[3] "Твой отец собирается задать мне вопрос. Это самый важный момент в нашей жизни, и я хочу"
[4] "запомнить все до малейшей детали. Уже за полночь, но мы только что вернулись домой после"
[5] "ужина в ресторане и веселого шоу и сразу выходим в патио полюбоваться полной луной. Хочу"
[6] "танцевать! — объявляю я, и твой отец подтрунивает надо мной, но мы начинаем скользить в" read_lines() создал вектор строк:
class(t)[1] "character"В каждом элементе вектора у нас содержится одна строчка (в смысле, line) из книги. Чтобы превратить текст в единое целое, воспользуемся уже известной нам функцией str_c() из библиотеки stringr, и склеим, используя пробел как разделитель.
t2 <- stringr::str_c(t, collapse = " ")
length(t2)[1] 1str_length(t2)[1] 117398При таком слиянии стоит проверить, не было ли в анализируемом тексте знаков переноса, иначе они сольются неправильно:
str_c(c("... она запо-", "лучила ..."), collapse = " ")[1] "... она запо- лучила ..."5.2 gutenbergr
Библиотека gutenbergr это API для проекта Gutenberg - онлайн-библиотеки электронных книг, которую создал Майкл Харт, изобретатель, собственно, формата электронных книг. Там хранится куча документов, которые по каким-то причинам не защищены авторским правом, так что мы можем совершенно легально их скачивать и анализировать (ну, или читать).
В этой библиотеке нас интересуют две вещи: объект gutenberg_metadata, в котором хранится информация о всех книгах, которые есть в библиотеке, и функция gutenberg_download(), которая позволяет их скачивать. Начнём с первого.
str(gutenberg_metadata)tibble [51,997 × 8] (S3: tbl_df/tbl/data.frame)
$ gutenberg_id : int [1:51997] 0 1 2 3 4 5 6 7 8 9 ...
$ title : chr [1:51997] NA "The Declaration of Independence of the United States of America" "The United States Bill of Rights\r\nThe Ten Original Amendments to the Constitution of the United States" "John F. Kennedy's Inaugural Address" ...
$ author : chr [1:51997] NA "Jefferson, Thomas" "United States" "Kennedy, John F. (John Fitzgerald)" ...
$ gutenberg_author_id: int [1:51997] NA 1638 1 1666 3 1 4 NA 3 3 ...
$ language : chr [1:51997] "en" "en" "en" "en" ...
$ gutenberg_bookshelf: chr [1:51997] NA "United States Law/American Revolutionary War/Politics" "American Revolutionary War/Politics/United States Law" NA ...
$ rights : chr [1:51997] "Public domain in the USA." "Public domain in the USA." "Public domain in the USA." "Public domain in the USA." ...
$ has_text : logi [1:51997] TRUE TRUE TRUE TRUE TRUE TRUE ...
- attr(*, "date_updated")= Date[1:1], format: "2016-05-05"У каждого документа указан автор (если он есть) и название, author и title. Например, мы можем узнать, книг какого автора в библиотеке больше всего:
gutenberg_metadata %>%
count(author, sort = TRUE)Сколько произведений Джейн Остин (не перепутайте с другими Остин) есть в датасете?
gutenberg_metadata %>%
filter(author == "Austen, Jane") %>%
distinct(gutenberg_id, title)Ещё у каждой книги есть свой уникальный ID, который хранится в колонке gutenberg_id. По этому ID книгу можно скачать, используя функцию gutenberg_download(). Давайте скачаем “Эмму”:
emma <- gutenberg_download(158, mirror = "http://mirrors.xmission.com/gutenberg/")
emmaМожно скачивать сразу несколько книг. Давайте добавим еще “Леди Сьюзен”:
books <- gutenberg_download(c(158, 946), meta_fields = "title", mirror = "http://mirrors.xmission.com/gutenberg/")
booksbooks %>%
count(title)Сколько уникальных заголовков из базы данных содержит “Sherlock Holmes?”
5.3 tidytext и stopwords
Сейчас наши книги хранятся в тиббле, в котором есть три колонки:
class(books)[1] "tbl_df" "tbl" "data.frame"colnames(books)[1] "gutenberg_id" "text" "title" Причём для каждой из книг у нас куча строк:
books %>% count(title)Это потому что одна строка в тиббле это одна строка книги. Мы можем снова воспользоваться функцией str_c() и слить весь текст в одну гигантскую строку, но вместо этого мы токенизируем наши тексты, используя в качестве токенов (=смысловых единиц) слова. Если вы посмотрели видео в начале, то уже знаете, что такое токенизация, а если не посмотрели, то идите и посмотрите :)
Для токенизации мы будем использовать функцию unnest_tokens() из библиотеки tidytext (про эту библиотеку есть книга, которую можно прочитать здесь). В аргумент output функции unnest_tokens() подается вектор с именем будущей переменной, а аргумент input принимает имя переменной, в которой в нашем тиббле хранится текст. По умолчанию unnest_tokens() делит текст на слова, хотя есть и другие опции, которые можно указать в аргументе token. Но пока давайте поисследуем слова.
library(tidytext)
books %>%
unnest_tokens(output = "word", input = text)Теперь можно посчитать самые частотные слова в обоих произведениях:
books %>%
unnest_tokens(output = "word", input = text) %>%
count(title, word, sort = TRUE)Ну… Это было ожидаемо. Нужно убрать стоп-слова. Английские стоп-слова встроены в пакет tidytext (переменная stop_words):
books %>%
unnest_tokens(word, text) %>%
count(title, word, sort = TRUE) %>%
anti_join(stop_words)Постройте следующий график, на котором представлены самые частотные 20 слов каждого из произведений.
Как видно, на графике всё не упорядочено, давайте начнем с такого примера:
books %>%
unnest_tokens(word, text) %>%
count(word, sort = TRUE) %>%
anti_join(stop_words) %>%
slice(1:20) %>%
ggplot(aes(n, word))+
geom_col()
Если мы работаем с одним фасетом, то все проблемы может решить функция fct_reorder(), которая упорядочивает на основании некоторой переменной:
books %>%
unnest_tokens(word, text) %>%
count(word, sort = TRUE) %>%
anti_join(stop_words) %>%
slice(1:20) %>%
mutate(word = fct_reorder(word, n)) %>%
ggplot(aes(n, word))+
geom_col()
Однако, если мы применим это к нашим данным, то получится неупорядочено, потому что fct_reorder()упорядочивает, не учитывая, где какой текст:
books %>%
unnest_tokens(word, text) %>%
count(title, word, sort = TRUE) %>%
anti_join(stop_words) %>%
group_by(title) %>%
slice(1:20) %>%
ungroup() %>%
mutate(word = fct_reorder(word, n)) %>%
ggplot(aes(n, word))+
geom_col()+
facet_wrap(~title, scales = "free")
В пакете tidytext есть функция reorder_within(), которая позволяет упорядочить нужным образом:
books %>%
unnest_tokens(word, text) %>%
count(title, word, sort = TRUE) %>%
anti_join(stop_words) %>%
group_by(title) %>%
slice(1:20) %>%
ungroup() %>%
mutate(word = reorder_within(x = word, by = n, within = title)) %>%
ggplot(aes(n, word))+
geom_col()+
facet_wrap(~title, scales = "free")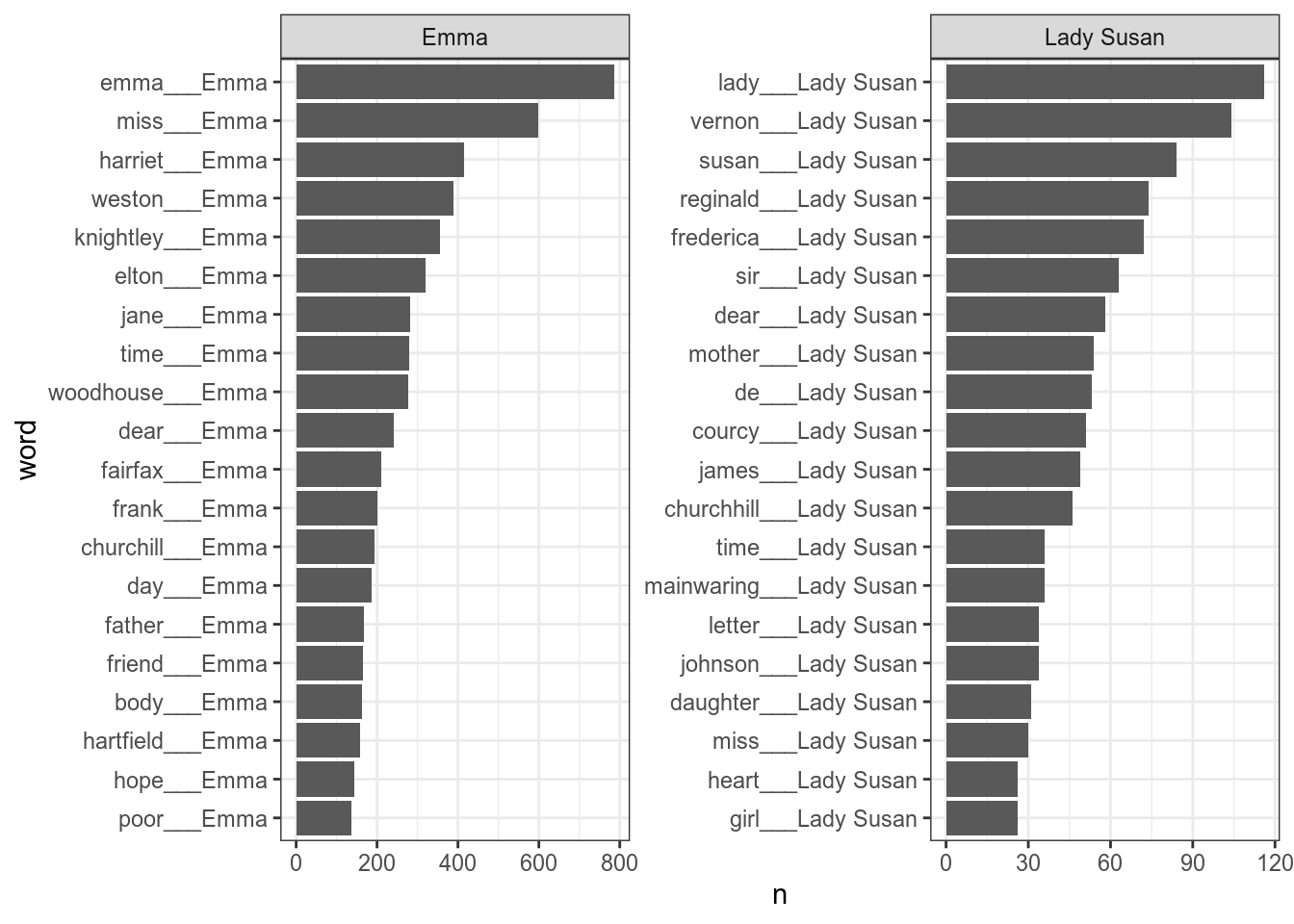
Чтобы избавиться от дополнительной подписи, нужно использовать scale_y_reordered() или scale_x_reordered():
books %>%
unnest_tokens(word, text) %>%
count(title, word, sort = TRUE) %>%
anti_join(stop_words) %>%
group_by(title) %>%
slice(1:20) %>%
ungroup() %>%
mutate(word = reorder_within(x = word, by = n, within = title)) %>%
ggplot(aes(n, word))+
geom_col()+
facet_wrap(~title, scales = "free")+
scale_y_reordered()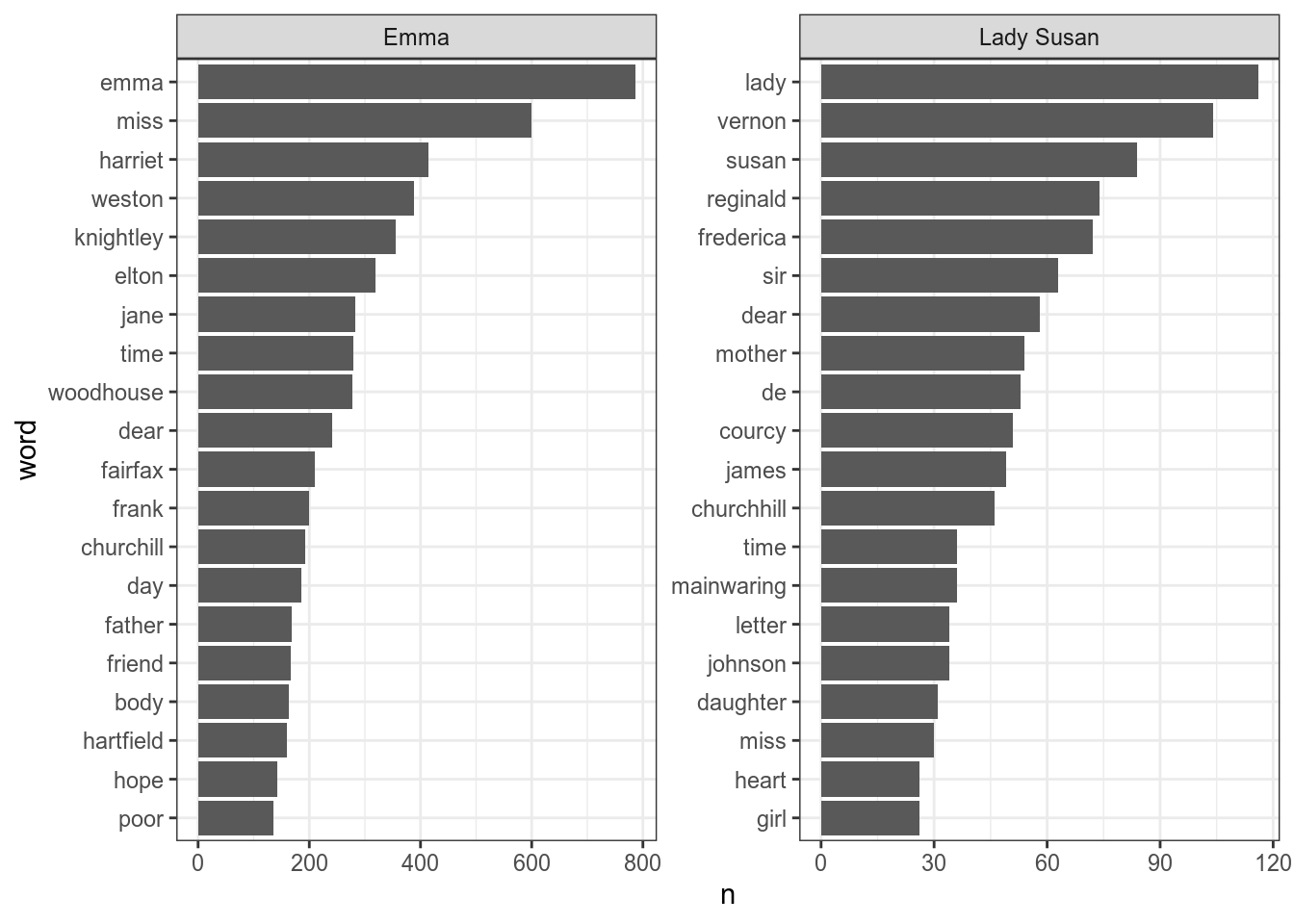
Ещё один способ графически представить самые частотные слова это сделать облако слов. Есть библиотека wordclouds с функцией wordcloud.
Давайте построим облако слов для романа Lady Susan. Для раскрашивания слов в разные цвета я использую палитру из великой библиотеки wesanderson с цветами разных фильмов, собственно, Уэса Андерсона.
pal <- wes_palette("Royal2")
books %>% filter(title == 'Lady Susan') %>%
unnest_tokens(input = 'text', output = 'word') %>%
count(title, word, sort = TRUE) %>% anti_join(stop_words) %>%
with(wordcloud(word, n, random.order = FALSE, max.words = 50, colors=pal))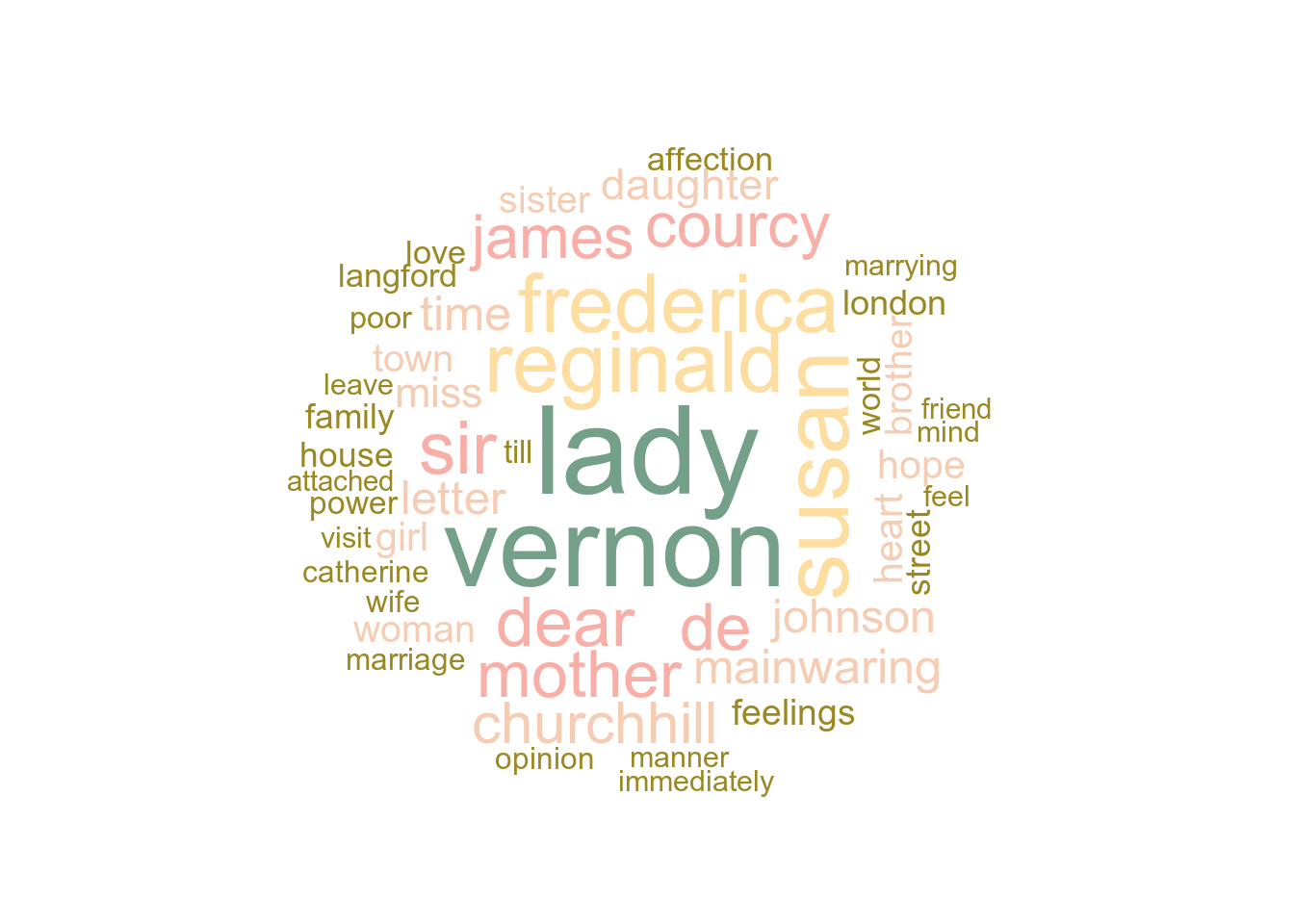
wordcloud, к сожалению, не совместим с ggplot2 без которого, например, гораздо сложнее сделать фасетизацию и не задолбаться. Зато есть библиотека ggwordcloud, в которой есть geom_text_wordcloud. Воспользуемся же им!
Предварительное предупреждение: если слов в облако надо вместить много, то `ggwordcloud указывает для редко встречающихся очень маленький размер шрифта. ggplot от этого волнуется и выдаёт ворнинги, по одному на каждое слово. Это я к чему: график в чанке снизу выдаёт миллион ворнингов. В этом мануале они спрятаны, а когда столкнётесь с ними при выполнении заданий, можете их игнорировать. И, конечно, совершенно не обязательно включать слова, которые встречаются всего пару раз в очень длинном тексте.
books %>%
unnest_tokens(input = 'text', output = 'word') %>%
count(title, word, sort = TRUE) %>% anti_join(stop_words) %>%
filter(n > 20) %>%
ggplot(aes(label = word, size = n, color = n)) + geom_text_wordcloud(rm_outside = TRUE) + facet_wrap(~title, scale = 'free') + scale_size_area(max_size = 10)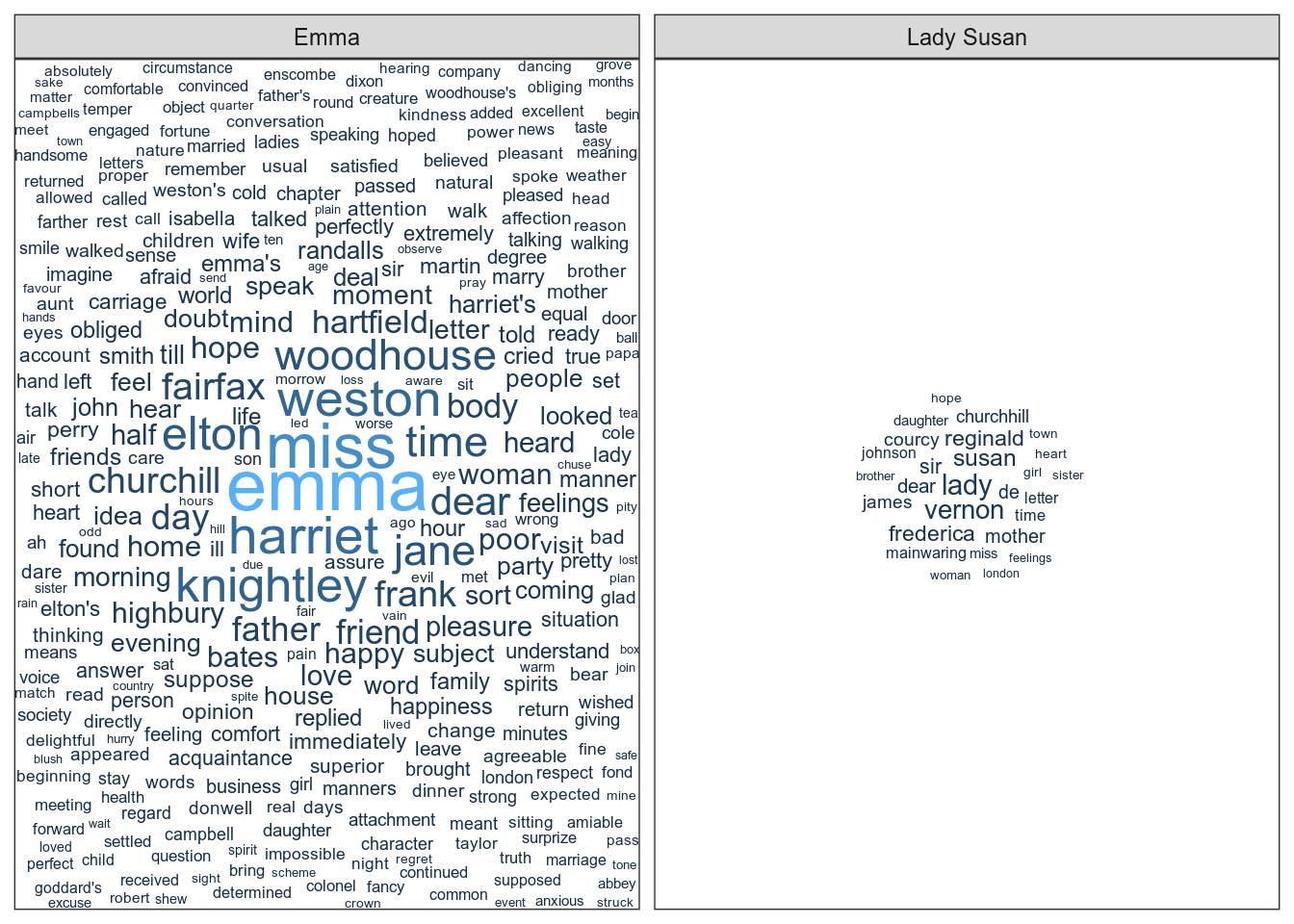
Поиск самых частотных слов — не единственная задача, которую можно решать при работе с текстом. Иногда имеет смысл узнать распределение слов в произведении. Давайте посмотрим как распределены в романе “Эмма” фамилии главных героев:
books %>%
filter(title == "Emma") %>%
unnest_tokens(word, text) %>%
mutate(narrative_time = 1:n()) %>%
filter(str_detect(word, "knightley$|woodhouse$|churchill$|fairfax$")) %>%
ggplot()+
geom_vline(aes(xintercept = narrative_time))+
facet_wrap(~word, ncol = 1)
Функция unnest_tokens() позволяет работать не только со словами, но и, напрмиер, с n-граммами, то есть сочетаниями из n слов. Важно понимать, что n-граммы образуются “внахлёст”:
txt <- tibble(text = "I'm a Barbie girl in a Barbie world")
txt %>% unnest_tokens(bigram, text, token = "ngrams", n = 2)Чтобы преобразовать текст в биграммы, надо уточнить, что token = "ngrams", а n=2.
books %>%
unnest_tokens(bigram, text, token = "ngrams", n = 2)Если мы посмотрим на самые частотные биграммы, то увидим кучу несодержательных вещей.
books %>%
unnest_tokens(bigram, text, token = "ngrams", n = 2) %>%
count(bigram, sort = TRUE)Почему? Снова стоп-слова-злодеи! Чтобы их убрать, надо разделить биграммы, отфильтровать так, чтобы остались только биграммы без стоп-слов, и снова склеить. Для этого мы воспользуемся функциями separate и unite, вот так (и заодно избавимся от NA’ев):
books %>%
unnest_tokens(bigram, text, token = "ngrams", n = 2) %>%
drop_na()%>%
separate(bigram, c('word1', 'word2'), sep = ' ') %>%
filter(!(word1 %in% stop_words$word)
& !(word2 %in% stop_words$word)) %>%
count(word1, word2, sort = TRUE) %>%
unite(bigram, word1, word2, sep = " ")5.4 Визуализация биграмм с igraph и ggraph
Биграммы можно представить теми же способами, что и слова, а можно визуализировать сеть связей между словами в таком как бы графе. Для этого мы будем пользоваться двумя библиотеками: igraph и ggraph.
Из igraph нам понадобится функция graph_from_data_frame(), которой мы скормим тиббл с данными о частотности биграмм, а ggraph будем использовать, чтобы построить график.
Для графика нам нужно три переменных: - from, от какого “узла” (слова) начинается связь - to, в какой узел (слово) связь идёт - weight, вес этой связи. В нашем случае - насколько часто эта связь (то есть, конкретная биграмма) встречается в тексте.
graph_from_data_frame() берёт тиббл (или любой дата фрейм) с этой информацией и преобразует его в объект, из которого можно делать граф.
Давайте совершим все эти преобразования и заодно оставим только биграммы, которых больше 20:
bigrams_graph <- books %>%
unnest_tokens(bigram, text, token = "ngrams", n = 2) %>%
drop_na() %>%
separate(bigram, c("word1", "word2"), sep = " ") %>%
filter(!(word1 %in% stop_words$word)
& !(word2 %in% stop_words$word)) %>%
count(word1, word2, sort = TRUE) %>%
filter(n > 20) %>%
graph_from_data_frame()
bigrams_graphIGRAPH efeb300 DN-- 25 17 --
+ attr: name (v/c), n (e/n)
+ edges from efeb300 (vertex names):
[1] miss ->woodhouse frank ->churchill miss ->fairfax miss ->bates
[5] jane ->fairfax lady ->susan de ->courcy miss ->smith
[9] sir ->james john ->knightley miss ->taylor dear ->emma
[13] maple ->grove cried ->emma dear ->miss harriet->smith
[17] robert ->martin А теперь можно и график делать:
ggraph(bigrams_graph, layout = "fr") +
geom_edge_link() +
geom_node_point() +
geom_node_text(aes(label = name), vjust = 1, hjust = 1)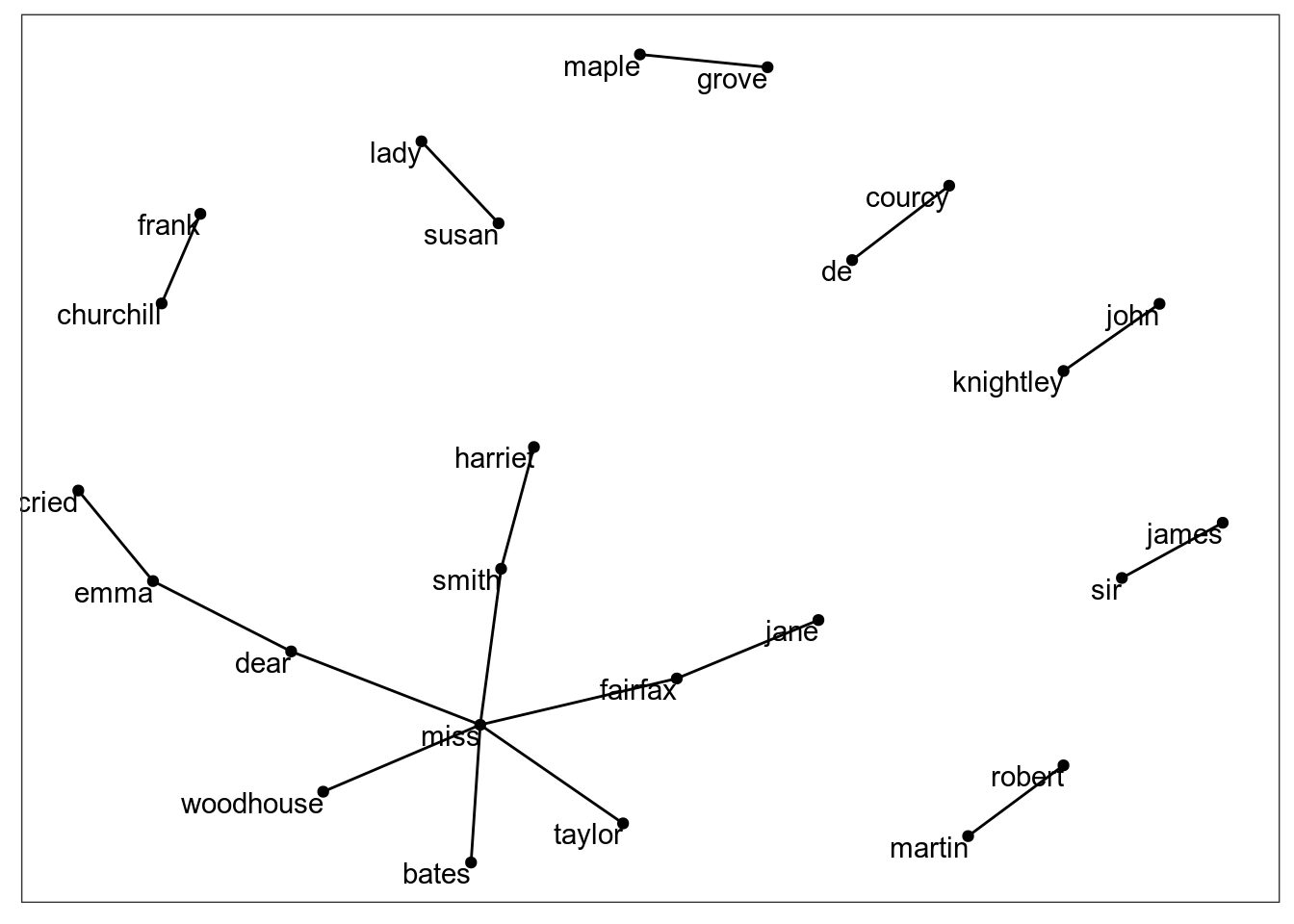
5.5 Пакет stopwords
Выше мы упомянули, что в пакет tidytext встроен список английских стоп-слов. Стоп-слова для других язков можно раздобыть, используя пакет stopwords. Вместо имени языка, функция принимает ISO-код языка:
library(stopwords)
stopwords("ru") [1] "и" "в" "во" "не" "что" "он" "на"
[8] "я" "с" "со" "как" "а" "то" "все"
[15] "она" "так" "его" "но" "да" "ты" "к"
[22] "у" "же" "вы" "за" "бы" "по" "только"
[29] "ее" "мне" "было" "вот" "от" "меня" "еще"
[36] "нет" "о" "из" "ему" "теперь" "когда" "даже"
[43] "ну" "вдруг" "ли" "если" "уже" "или" "ни"
[50] "быть" "был" "него" "до" "вас" "нибудь" "опять"
[57] "уж" "вам" "сказал" "ведь" "там" "потом" "себя"
[64] "ничего" "ей" "может" "они" "тут" "где" "есть"
[71] "надо" "ней" "для" "мы" "тебя" "их" "чем"
[78] "была" "сам" "чтоб" "без" "будто" "человек" "чего"
[85] "раз" "тоже" "себе" "под" "жизнь" "будет" "ж"
[92] "тогда" "кто" "этот" "говорил" "того" "потому" "этого"
[99] "какой" "совсем" "ним" "здесь" "этом" "один" "почти"
[106] "мой" "тем" "чтобы" "нее" "кажется" "сейчас" "были"
[113] "куда" "зачем" "сказать" "всех" "никогда" "сегодня" "можно"
[120] "при" "наконец" "два" "об" "другой" "хоть" "после"
[127] "над" "больше" "тот" "через" "эти" "нас" "про"
[134] "всего" "них" "какая" "много" "разве" "сказала" "три"
[141] "эту" "моя" "впрочем" "хорошо" "свою" "этой" "перед"
[148] "иногда" "лучше" "чуть" "том" "нельзя" "такой" "им"
[155] "более" "всегда" "конечно" "всю" "между" Пакет предоставляет несколько источников списков:
stopwords_getsources()[1] "snowball" "stopwords-iso" "misc" "smart"
[5] "marimo" "ancient" "nltk" Давайте посмотрим, какие языки сейчас доступны:
map(stopwords_getsources(), stopwords_getlanguages)[[1]]
[1] "da" "de" "en" "es" "fi" "fr" "hu" "ir" "it" "nl" "no" "pt" "ro" "ru" "sv"
[[2]]
[1] "af" "ar" "hy" "eu" "bn" "br" "bg" "ca" "zh" "hr" "cs" "da" "nl" "en" "eo"
[16] "et" "fi" "fr" "gl" "de" "el" "ha" "he" "hi" "hu" "id" "ga" "it" "ja" "ko"
[31] "ku" "la" "lt" "lv" "ms" "mr" "no" "fa" "pl" "pt" "ro" "ru" "sk" "sl" "so"
[46] "st" "es" "sw" "sv" "th" "tl" "tr" "uk" "ur" "vi" "yo" "zu"
[[3]]
[1] "ar" "ca" "el" "gu" "zh"
[[4]]
[1] "en"
[[5]]
[1] "en" "ja" "ar" "he" "zh_tw" "zh_cn"
[[6]]
[1] "grc" "la"
[[7]]
[1] "ar" "az" "da" "nl" "en" "fi" "fr" "de" "el" "hu" "id" "it" "kk" "ne" "no"
[16] "pt" "ro" "ru" "sl" "es" "sv" "tg" "tr"Мы видим, что есть несколько источников для русского языка:
length(stopwords("ru", source = "snowball"))[1] 159length(stopwords("ru", source = "stopwords-iso"))[1] 559В зависимости от того, насколько консервативными вы хотите быть в плане стоп-слов (например, “сказал” это стоп-слово или нет?), можете выбирать тот или другой список. Ну и всегда можно попробовать оба и выбрать тот, который даёт более осмысленный результат.
5.6 Пакет udpipe
Пакет udpipe представляет лемматизацию, морфологический и синтаксический анализ разных языков. Туториал можно найти здесь, там же есть список доступных языков.
library(udpipe)Модели качаются очень долго.
enmodel <- udpipe_download_model(language = "english")Теперь можно распарсить какое-нибудь предложение:
udpipe("The want of Miss Taylor would be felt every hour of every day.", object = enmodel)Скачаем русскую модель:
rumodel <- udpipe_download_model(language = "russian-syntagrus")udpipe("Жила-была на свете крыса в морском порту Вальпараисо, на складе мяса и маиса, какао и вина.", object = rumodel)После того, как модель скачана, можно уже к ней обращаться просто по имени файла:
udpipe("Жила-была на свете крыса в морском порту Вальпараисо, на складе мяса и маиса, какао и вина.", object = rumodel)udpipe лемматизирует наш текст (то есть, теперь “мясо” и “мяса” распрознаются как одно и то же слово), а также помечает, к какой части речи это слово относится, по универсальной классификации. С таким текстом, например, можно посмотреть на то, как часто встречаются только определённые части речи.
И последний комментарий про udpipe: лемматизациz дело не быстрое, поэтому, скорее всего, лемматизировать все фанфики скопом у вас не получится. Вместо этого предлагается сделать сэмпл (то есть, рандомно выбрать, например, 300 фанфиков) и работать с ними. Если 300 вашему компьютеру тяжело - можно меньше. Соответственно, в заданиях, где нужна лемматизация, сэмплируйте датасет и работайте с сэмплом.
А теперь - собственно, задания!
5.7 Задания
Найдите три самыx популярных (по количеству лайков) фанфика и постройте барплоты для самых часто встречающихся слов в этих фанфиках.
Найдите самый длинный фанфик (не забывайте, что в нашем датасете одна строка это одна глава, а глав бывает несколько) и постройте для него граф биграмм (не всех, конечно, а тех, что встречаются чаще скольки-то раз).
Для того же самого длинного фанфика по самым частотным словам поймите, какие в нём есть персонажи и как их зовут. Постройте график, который показывает, как частота появления разных персонажей меняется на протяжении фанфика.
Какие прилагательные чаще всего используются в вашем фандоме со словом “глаз” (в любой форме)? Проиллюстрируйте облаком слов. Именно здесь вам понадобится лемматизация, так что используйте сэмпл.
Найдите самого плодовитого автора в вашем фандоме (то есть, такого, который написал больше всего фанфиков). Попробуйте найти клише, которые встречаются в его или её текстах. Тут можно посмотреть на биграммы, триграммы или и то, и другое - посмотрите, что интереснее, и покажите на графике (можно барплот, можно сделать облако слов, можете придумать свой вариант).
Если у вас появятся вопросы - смело задавайте их в канале #text-preprocessing-questions, а все странные и нелепые графики присылайте в #accidental-art. Удачи!