###########################################################
####### Change the path! ##################################
outputPath$ = "/home/agricolamz/Desktop/ex/formants.csv"
###########################################################
writeInfoLine: "Extracting formants..."
# Extract the names of the Praat objects
thisSound$ = selected$("Sound")
thisTextGrid$ = selected$("TextGrid")
# Extract the number of intervals in the phoneme tier
select TextGrid 'thisTextGrid$'
numberOfPhonemes = Get number of intervals: 3
appendInfoLine: "There are ", numberOfPhonemes, " intervals."
# Create the Formant Object
select Sound 'thisSound$'
To Formant (burg)... 0 5 5000 0.025 50
# Create the output file and write the first line.
writeFileLine: "'outputPath$'", "time,phoneme,duration,F1,F2,F3"
# Loop through each interval on the phoneme tier.
for thisInterval from 1 to numberOfPhonemes
#appendInfoLine: thisInterval
# Get the label of the interval
select TextGrid 'thisTextGrid$'
thisPhoneme$ = Get label of interval: 3, thisInterval
#appendInfoLine: thisPhoneme$
# Find the midpoint.
thisPhonemeStartTime = Get start point: 3, thisInterval
thisPhonemeEndTime = Get end point: 3, thisInterval
duration = thisPhonemeEndTime - thisPhonemeStartTime
midpoint = thisPhonemeStartTime + duration/2
# Extract formant measurements
select Formant 'thisSound$'
f1 = Get value at time... 1 midpoint Hertz Linear
f2 = Get value at time... 2 midpoint Hertz Linear
f3 = Get value at time... 3 midpoint Hertz Linear
# Save to a spreadsheet
appendFileLine: "'outputPath$'",
...midpoint, ",",
...thisPhoneme$, ",",
...duration, ",",
...f1, ",",
...f2, ",",
...f3
endfor
appendInfoLine: newline$, newline$, "Whoo-hoo! It didn't crash!"
Converts character vectors between phonetic representations. Supports IPA (International Phonetic Alphabet), X-SAMPA (Extended Speech Assessment Methods Phonetic Alphabet), and ARPABET (used by the CMU Pronouncing Dictionary).
library(ipa)convert_phonetics('%hE"loU', from ="xsampa", to ="ipa")
[1] "ˌhɛˈloʊ"
If you will use the package it make sense to cite it:
citation("ipa")
To cite ipa in publications use:
Alexander Rossell Hayes (2020). ipa: convert between phonetic
alphabets. R package version 0.1.0.
https://github.com/rossellhayes/ipa
A BibTeX entry for LaTeX users is
@Manual{,
title = {ipa: convert between phonetic alphabets},
author = {Rossell Hayes and {Alexander}},
year = {2020},
note = {R package version 0.1.0},
url = {https://github.com/rossellhayes/ipa},
}
8.2phonTools
This package contains tools for the organization, display, and analysis of the sorts of data frequently encountered in phonetics research and experimentation, including the easy creation of IPA vowel plots, and the creation and manipulation of WAVE audio files.
This package is usefull, since it provides some datasets:
pb52 — Peterson & Barney (1952) Vowel Data (1520 rows)
f73 — Fant (1973) Swedish Vowel Data (10 rows)
p73 — Pols et al. (1973) Dutch Vowel Data (12 rows)
b95 — Bradlow (1995) Spanish Vowel Data (5 rows)
h95 — Hillenbrand et al. (1995) Vowel Data (1668 rows)
a96 — Aronson et al. (1996) Hebrew Vowel Data (10 rows)
y96 — Yang (1996) Korean Vowel Data (20 rows)
f99 — Fourakis et al. (1999) Greek Vowel Data (5 rows)
t07 — Thomson (2007) Vowel Data (20 rows)
In order to load them you need to follow these steps:
library(phonTools)data(h95)h95
As you see vowel column is in X-SAMPA. In order to use it we need to recode it:
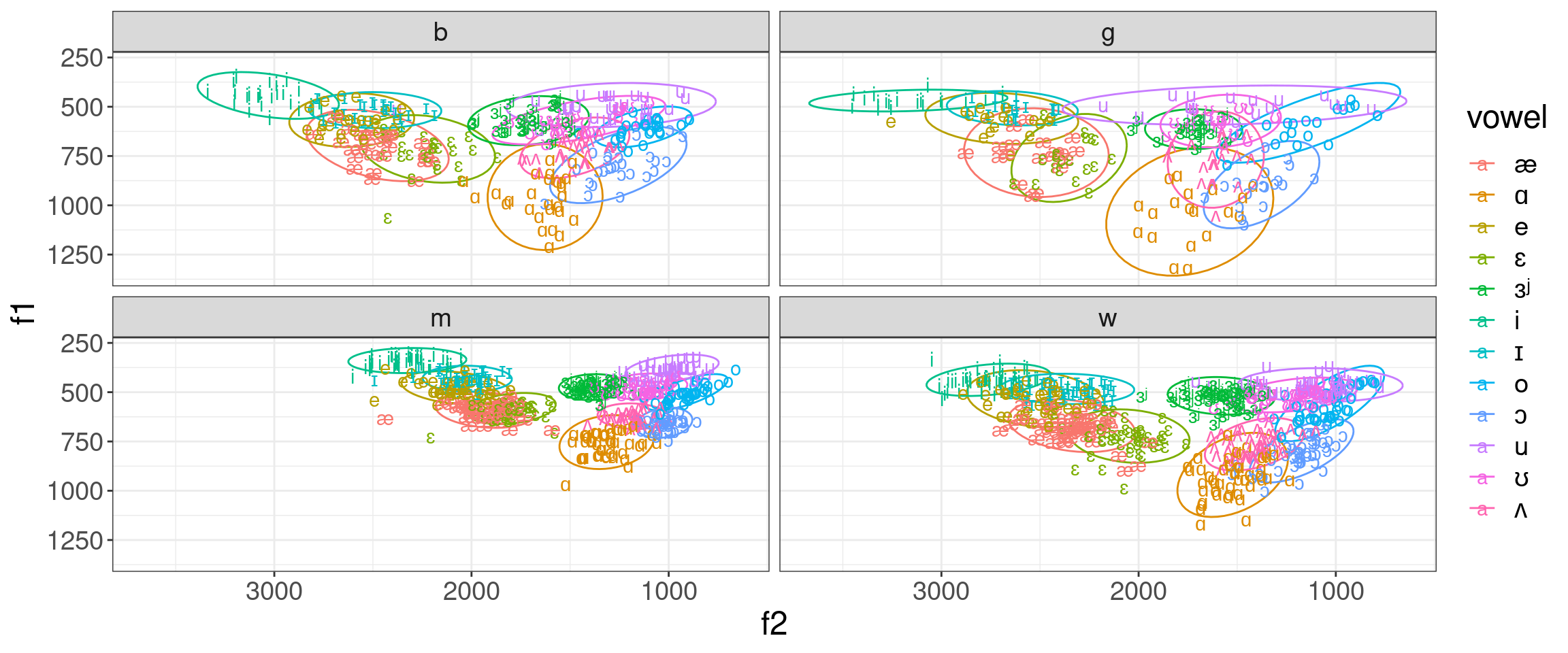
library(tidyverse)h95 |>mutate(vowel =convert_phonetics(vowel, from ="xsampa", to ="ipa")) |>ggplot(aes(f2, f1, label = vowel, color = vowel))+stat_ellipse()+geom_text()+scale_x_reverse()+scale_y_reverse()+coord_fixed()+facet_wrap(~type)
It also make sense to use normalization for vowels:
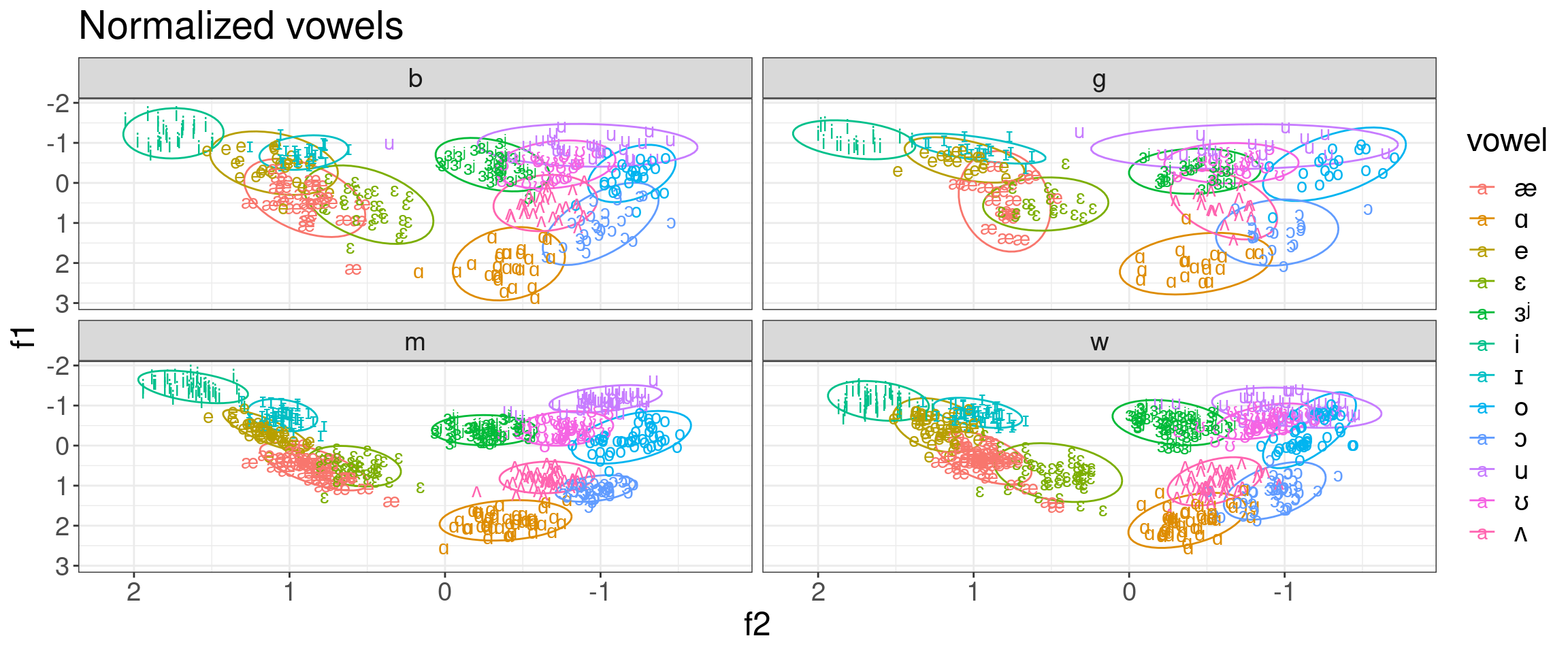
h95 |>mutate(vowel =convert_phonetics(vowel, from ="xsampa", to ="ipa")) |>group_by(speaker) |>mutate(f1 =scale(f1),f2 =scale(f2)) |>ggplot(aes(f2, f1, label = vowel, color = vowel))+stat_ellipse()+geom_text()+scale_x_reverse()+scale_y_reverse()+facet_wrap(~type)+labs(title ="Normalized vowels")
If you will use the package it make sense to cite it:
citation("phonTools")
To cite package 'phonTools' in publications use:
Barreda S (2023). "phonTools: Functions for phonetics in R." R
package version 0.2-2.2.
A BibTeX entry for LaTeX users is
@Misc{phonTools,
author = {Santiago Barreda},
title = {phonTools: Functions for phonetics in R},
note = {R package version 0.2-2.2},
year = {2023},
}
8.3vowels
Procedures for the manipulation, normalization, and plotting of phonetic and sociophonetic vowel formant data. vowels is the backend for the NORM website.
If you will use the package it make sense to cite it:
citation("vowels")
To cite package 'vowels' in publications use:
Kendall T, Thomas ER (2018). _vowels: Vowel Manipulation,
Normalization, and Plotting_. R package version 1.2-2,
<https://CRAN.R-project.org/package=vowels>.
A BibTeX entry for LaTeX users is
@Manual{,
title = {vowels: Vowel Manipulation, Normalization, and Plotting},
author = {Tyler Kendall and Erik R. Thomas},
year = {2018},
note = {R package version 1.2-2},
url = {https://CRAN.R-project.org/package=vowels},
}
ATTENTION: This citation information has been auto-generated from the
package DESCRIPTION file and may need manual editing, see
'help("citation")'.
8.4rPraat
This is a package for reading, writing and manipulating Praat objects like TextGrid, PitchTier, Pitch, IntensityTier, Formant, Sound, and Collection files. You can find the demo for rPraathere.
If you will use the package it make sense to cite it:
citation("rPraat")
To cite rPraat in publications use:
Bořil, T., & Skarnitzl, R. (2016). Tools rPraat and mPraat. In P.
Sojka, A. Horák, I. Kopeček, & K. Pala (Eds.), Text, Speech, and
Dialogue (pp. 367-374). Springer International Publishing.
A BibTeX entry for LaTeX users is
@InProceedings{,
author = {Tomáš Bořil and Radek Skarnitzl},
editor = {Petr Sojka and Aleš Horák and Ivan Kopeček and Karel Pala},
booktitle = {Text, Speech, and Dialogue: 19th International Conference, TSD 2016, Brno, Czech Republic, September 12-16, 2016, Proceedings},
publisher = {Springer International Publishing},
address = {Cham},
year = {2016},
title = {Tools rPraat and mPraat},
pages = {367--374},
isbn = {978-3-319-45510-5},
doi = {10.1007/978-3-319-45510-5_42},
url = {http://dx.doi.org/10.1007/978-3-319-45510-5_42},
}
8.5speakr
This package allows running Praat scripts from R and it provides some wrappers for basic plotting.
On macOS, Linux and Windows, the path to Praat is set automatically to the default installation path. If you have installed Praat in a different location, or if your operating system is not supported, you can set the path to Praat with options(speakr.praat.path).
For example:
options(speakr.praat.path = "./custom/praat.exe")
If you use rstudio.cloud you need to upload the unziped file of Linux version of Praat and provide path to it within the options():
sound = Read from file: "s1_all.wav"
formant = To Formant (burg): 0, 5, 5000, 0.05, 50
textgrid = Read from file: "s1_all.TextGrid"
header$ = "vowel,F1,F2,F3"
writeInfoLine: header$
form Get formants
choice Measure 1
button Hertz
button Bark
real Window_(sec) 0.03
endform
if measure == 1
measure$ = "Hertz"
else
measure$ = "Bark"
endif
selectObject: textgrid
intervals = Get number of intervals: 3
for interval to intervals - 1
label$ = Get label of interval: 3, interval
if label$ != ""
start = Get start time of interval: 3, interval
start = start + window
end = Get end time of interval: 3, interval
end = end - window
vowel$ = Get label of interval: 3, interval
selectObject: formant
f1 = Get mean: 1, start, end, measure$
f2 = Get mean: 2, start, end, measure$
f3 = Get mean: 3, start, end, measure$
resultLine$ = "'vowel$','f1','f2','f3'"
appendInfoLine: resultLine$
selectObject: textgrid
endif
endfor
In order to use it you need to provide path to the script:
As you see the result is file in a .csv format. We can use the following code in order to visualise it:
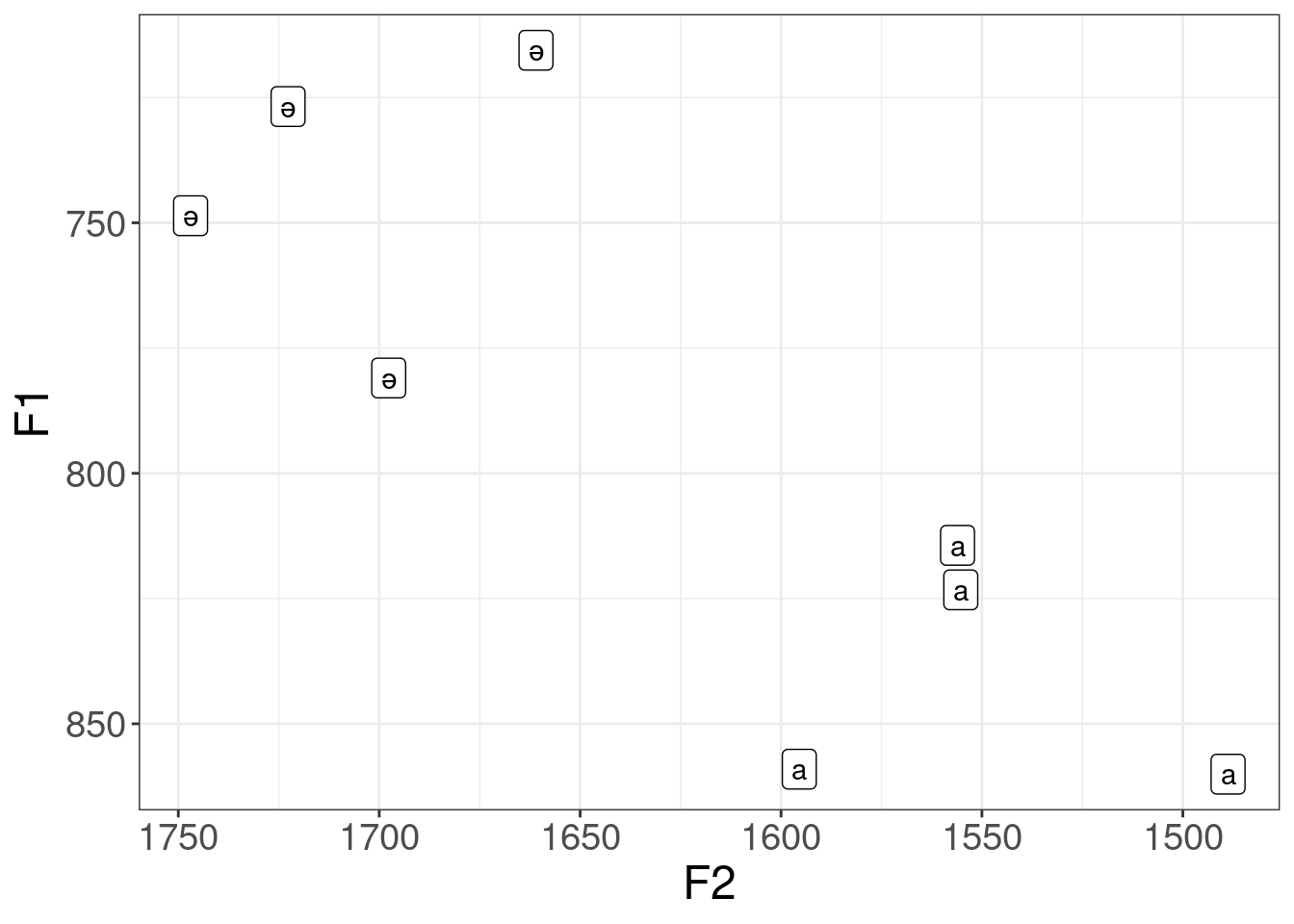
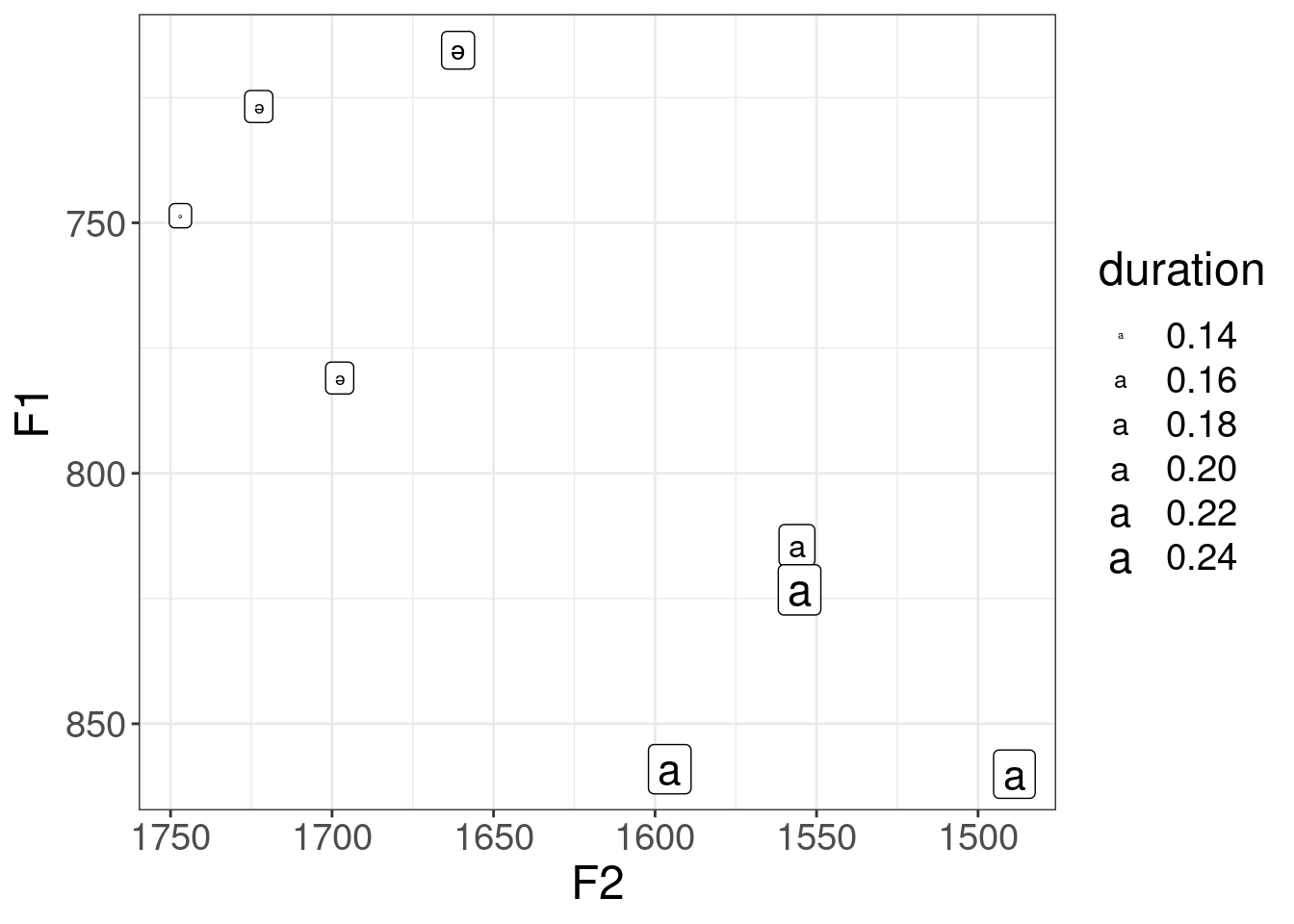
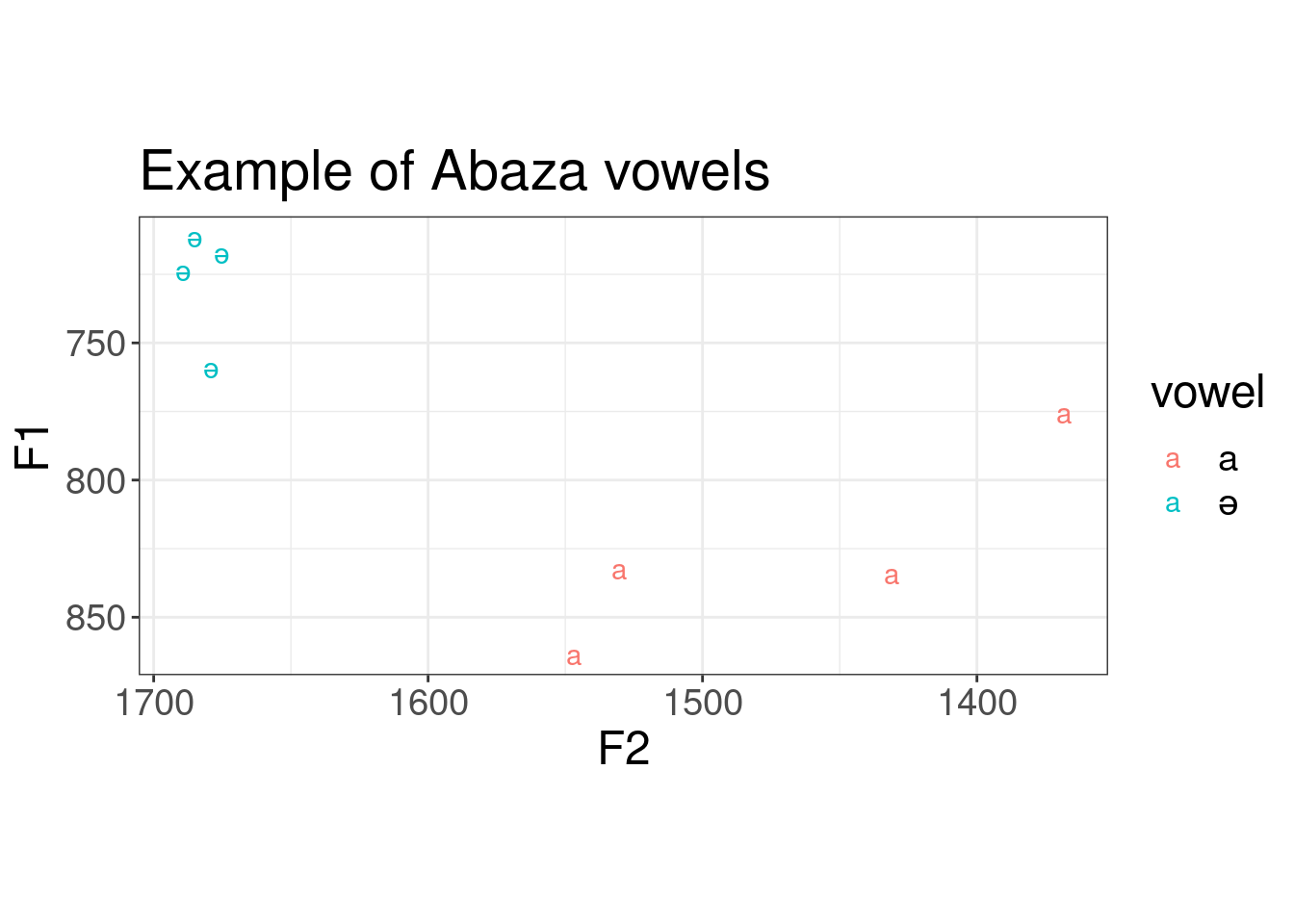
library(tidyverse)praat_run("sounds/speakr/get-formants-args.praat", "Hertz", 0.03, capture =TRUE) |>read_csv() -> abaza_formantsabaza_formants |>ggplot(aes(F2, F1, label = vowel, color = vowel))+geom_text()+scale_x_reverse()+scale_y_reverse()+coord_fixed()+labs(title ="Example of Abaza vowels")
If you will use the package it make sense to cite it:
citation("speakr")
To cite package 'speakr' in publications use:
Coretta S (2024). _speakr: A Wrapper for the Phonetic Software
'Praat'_. R package version 3.2.2,
<https://CRAN.R-project.org/package=speakr>.
A BibTeX entry for LaTeX users is
@Manual{,
title = {speakr: A Wrapper for the Phonetic Software 'Praat'},
author = {Stefano Coretta},
year = {2024},
note = {R package version 3.2.2},
url = {https://CRAN.R-project.org/package=speakr},
}
8.6wrassp
The wrassp package is a wrapper for R around Michel Scheffers’ libassp (Advanced Speech Signal Processor). Here is the manual.
Fletcher, N. 2007. “Animal Bioacoustics.” In Springer Handbook of Acoustics, edited by Thomas D. Rossing, 785–804. New York: Springer.