library(tidyverse)8 Байесовский регрессионный анализ
В основном, мы до этого момента пытались оценить параметры распределения некоторой переменной, однако чаще всего в научной литературе мы пытаемся оценить связь нескольких переменных. Регрессионный анализ как раз такой метод, который позволяет оценить связь некоторой переменной от некоторого набора зависимых переменных.
8.1 Основы регрессионного анализа
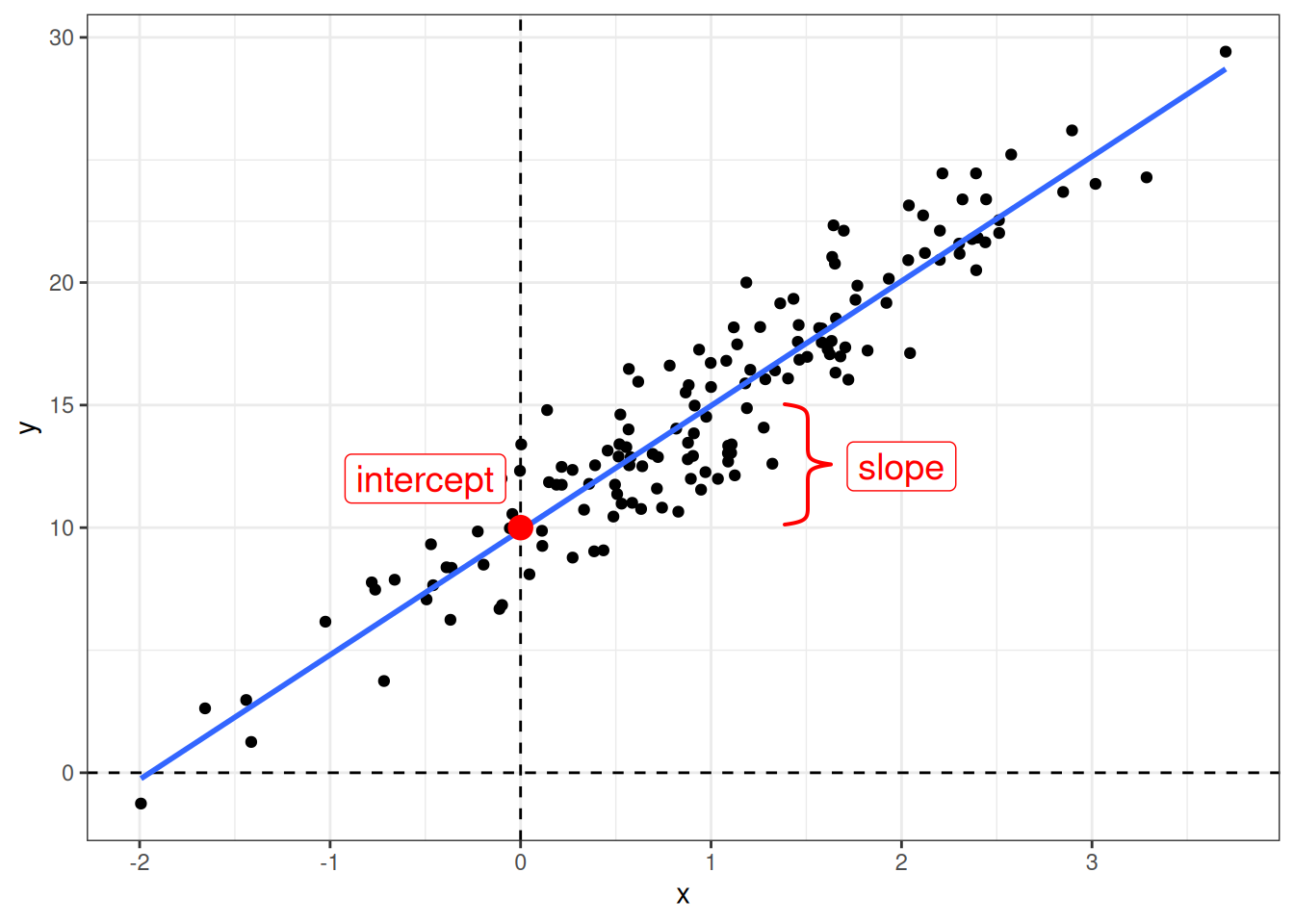
Когда мы используем регрессионный анализ, мы пытаемся оценить два параметра:
- свободный член (intercept) — значение \(y\) при \(x = 0\);
- угловой коэффициент (slope) — изменение \(y\) при изменении \(x\) на одну единицу.
\[y_i = \hat{\beta_0} + \hat{\beta_1}\times x_i + \epsilon_i\]
Причем, иногда мы можем один или другой параметр считать равным нулю.
При этом, вне зависимости от статистической школы, у регрессии есть свои ограничения на применение:
- линейность связи между \(x\) и \(y\);
- нормальность распределение остатков \(\epsilon_i\);
- гомоскидастичность — равномерность распределения остатков на всем протяжении \(x\);
- независимость переменных;
- независимость наблюдений друг от друга.
Припомнив предыдущий раздел, мы можем представить связь и в другой нотации:
\[y_{n} \sim Normal(\mu = \hat{\beta_0} + \hat{\beta_1}\times x_{n}, \sigma = \epsilon)\]
8.2 Регрессионная модель в brms
library(brms)
n_cores <- 15 # parallel::detectCores() - 1
read_csv("https://raw.githubusercontent.com/agricolamz/2026_HSE_b_da4l/master/data/speech_tempo_zvenigorod.csv") |>
filter(speaker == "ea1976") ->
df
get_prior(speech_tempo ~ n_vowels,
family = gaussian(),
data = df) Исходя из формулы выше, нам нужно определить априорное распределение для
- свободного члена;
- углового коэффециента;
- распределения остатков.
fit1 <- brm(speech_tempo ~ n_vowels,
data = df,
family = gaussian(),
cores = n_cores,
silent = TRUE,
prior = c(prior(normal(5.31, 1.93), class = "Intercept", lb = 0),
prior(normal(0, 1), class = "sigma", lb = 0),
prior(normal(0, 10), class = "b", lb = 0)))После того, как функция отработала, мы можем проанализировать то, что мы получили в результате ее работы. Мы оценили три параметра:
plot(fit1)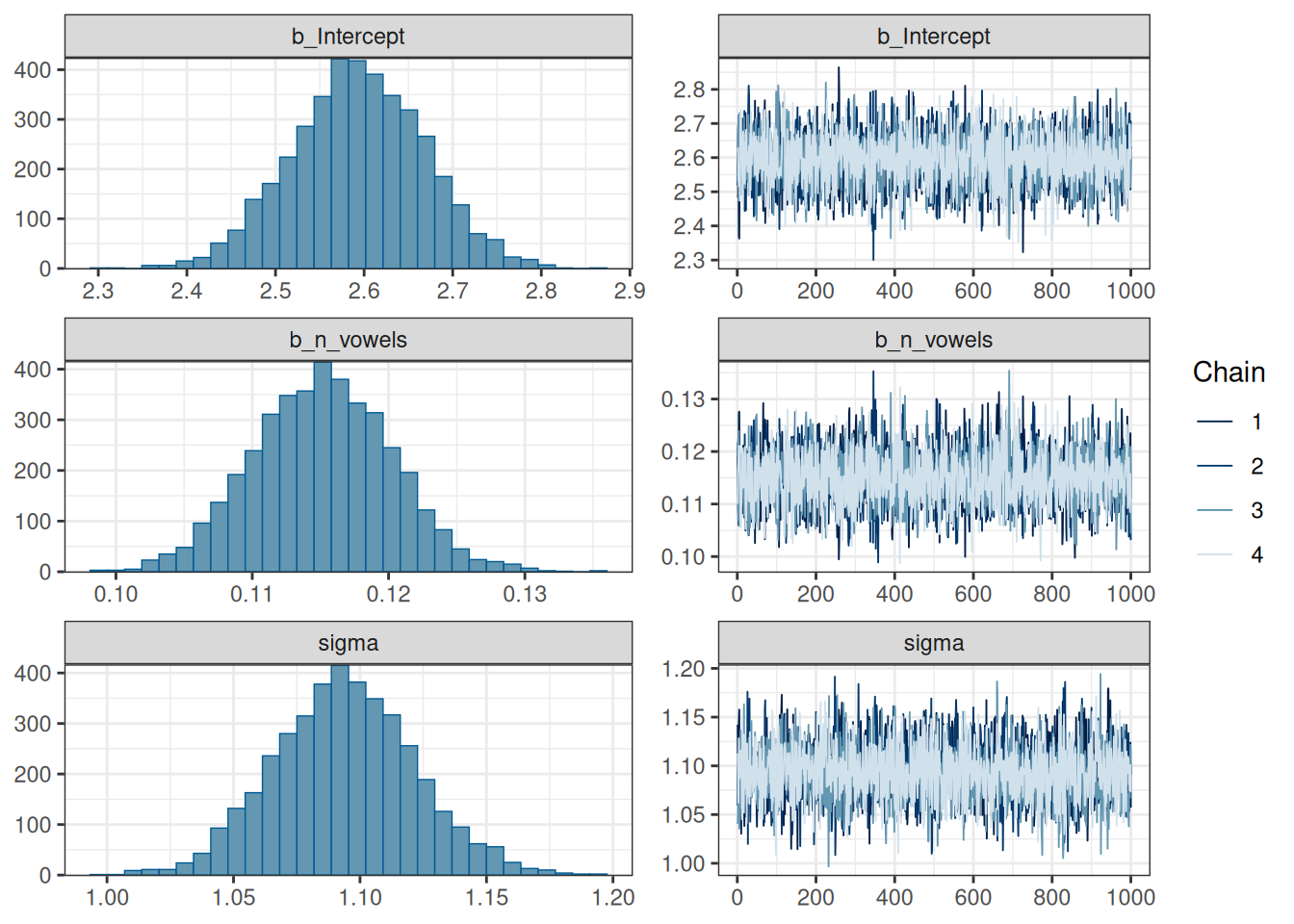
Стоит обратить внимание на сходимость цепей. Если все цепи накладываются друг на друга и выглядят как волосатые гусеницы — все в порядке. Вот пример плохой сходимости цепей:
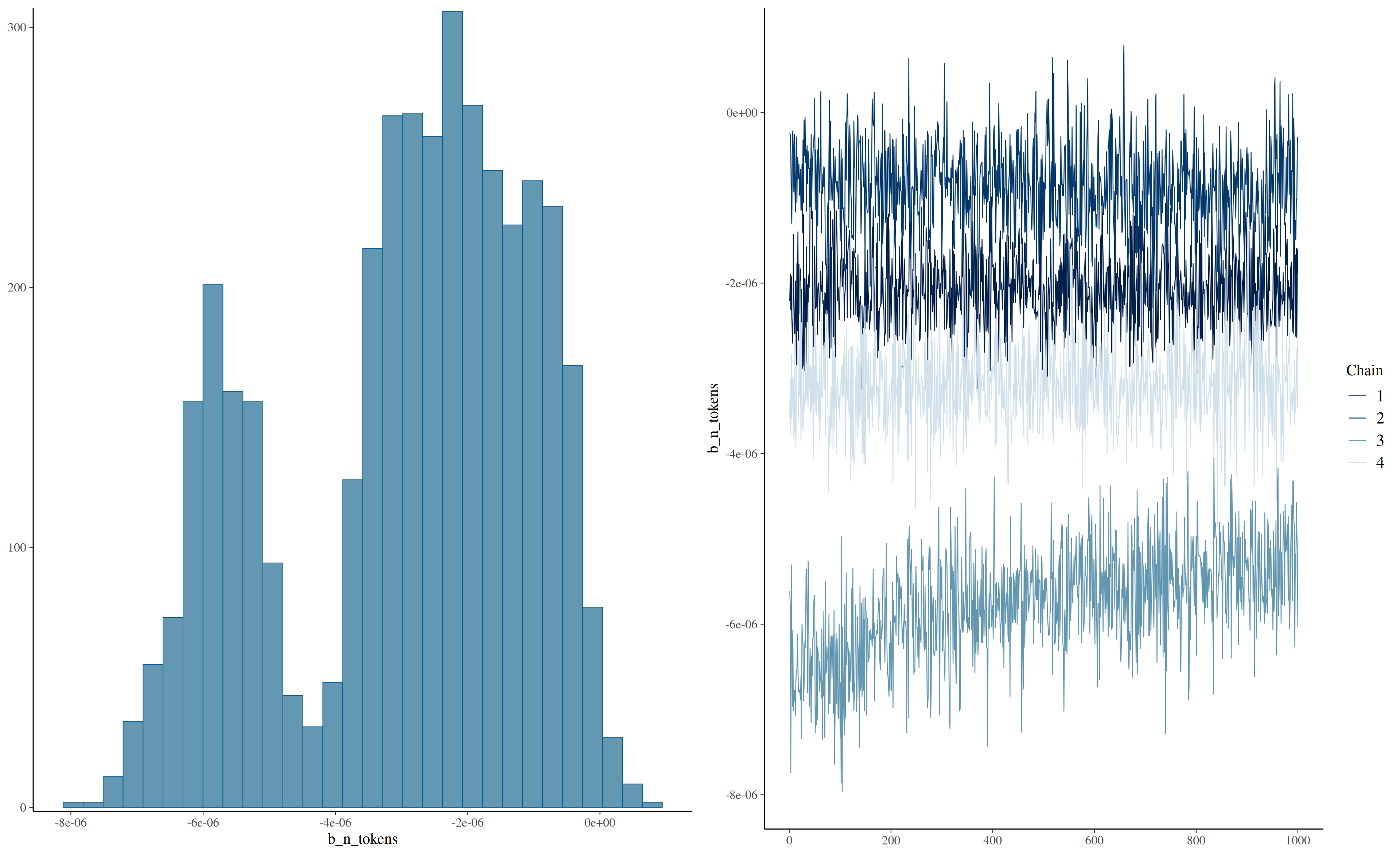
Видно, что цепи исследуют разное пространство и “устаканились” каждая на своем уровне. Кроме того, может быть такое, что цепи в принципе на одном уровне, но где-нибудь по середине делает скачок в сторону, а потом возвращается.
Метрики модели можно посмотреть, просто вызвав переменную с моделью.
fit1 Family: gaussian
Links: mu = identity
Formula: speech_tempo ~ n_vowels
Data: df (Number of observations: 786)
Draws: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
total post-warmup draws = 4000
Regression Coefficients:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
Intercept 2.59 0.07 2.45 2.74 1.00 3771 3220
n_vowels 0.12 0.01 0.11 0.13 1.00 3497 2752
Further Distributional Parameters:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
sigma 1.09 0.03 1.04 1.15 1.00 4006 2744
Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).Метрики качества модели: R-hat, Bulk_ESS и Tail_ESS
R-hat – это диагностика сходимости, которая сравнивает оценку модели, которая получается внутри цепи и между цепями (введена в (Gelman and Rubin 1992)). Если цепи не перемешались (например, если нет согласия внутри цепи и между цепями) R-hat будет иметь значение больше 1. Собственно для этого рекоммендуется запускать по-крайней мере 4 цепи. Stan возвращает что-то более сложное, что называется maximum of rank normalized split-R-hat и rank normalized folded-split-R-hat, однако мы не будем в этом разбиратсья, отсылаю к статье или к посту в блоге одного из авторов с объяснением.
Самое главное: \(\hat{R} \leq 1.05\) – значит проблем со сходмиостью цепей не обнаружено.
Bulk ESS (Effective sample size) — это оценка качества сэмплирования в середине апостериорного распределения, а Tail ESS — в краях апостериорного распределения. Чем выше ESS – тем лучше.
Мы можем визуализировать полученную регрессию:
fit1 |>
conditional_effects() |>
plot(points=TRUE)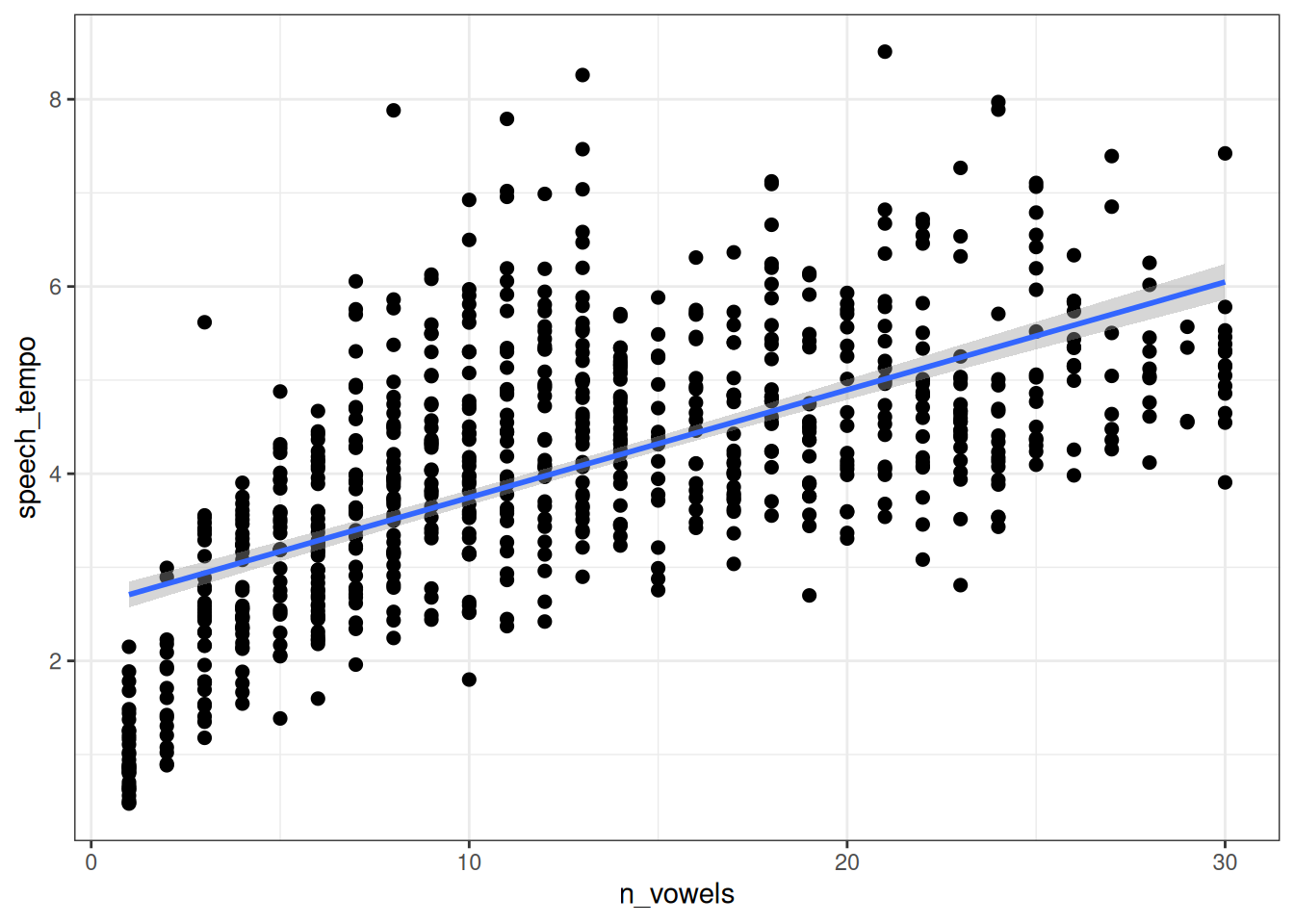
Мы можем визуализировать, насколько скорость речи в данных соотносится с полученным распределением апостериорного распределения:
fit1 |>
pp_check(type = "dens_overlay", ndraws = 50)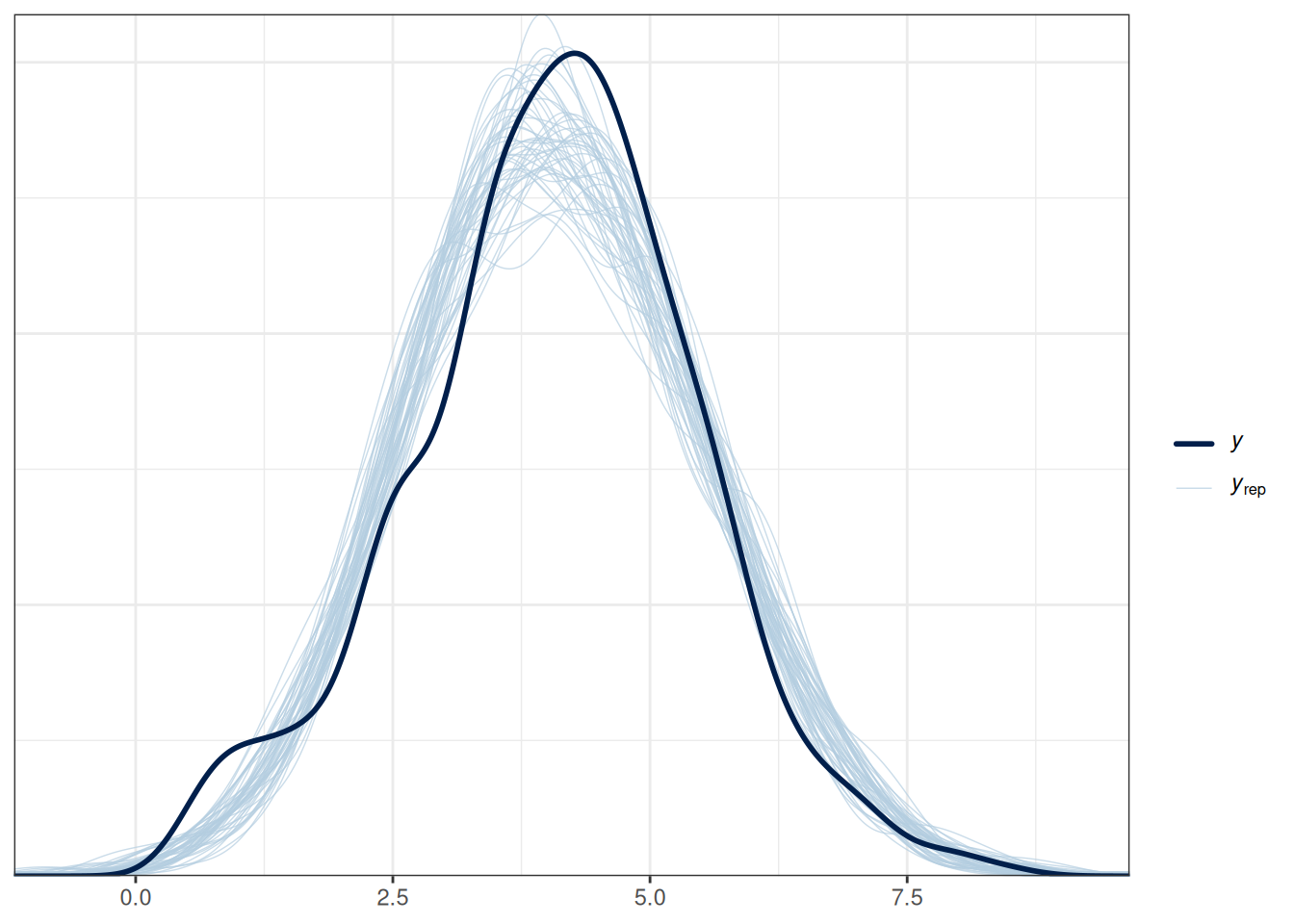
fit1 |>
pp_check(type = "stat")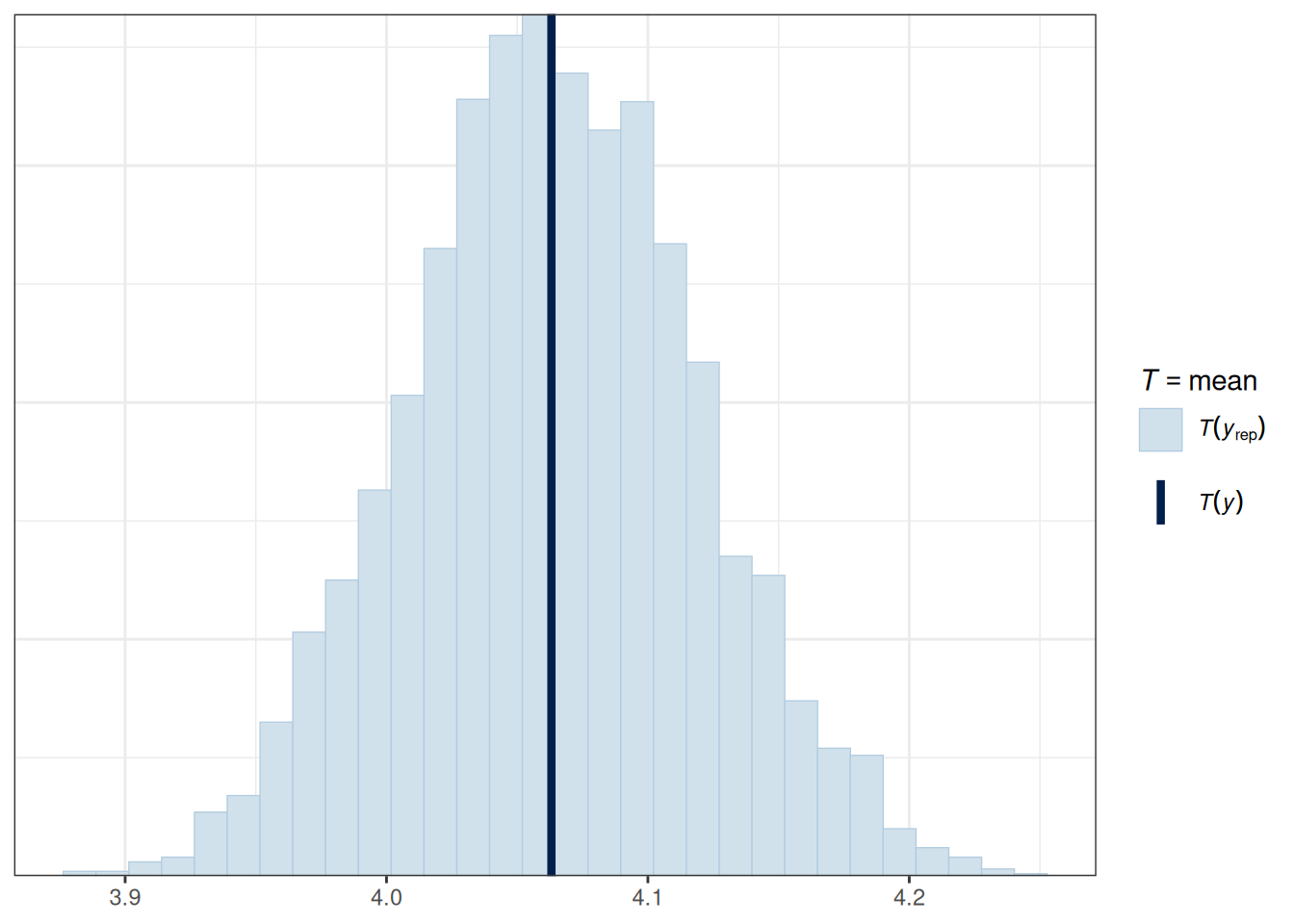
Если хочется предсказать какие-то значения, то можно использовать функцию predict(), которая возьмет выборки из апостериорного распределения:
predict(fit1, newdata = tibble(n_vowels = c(10, 20))) Estimate Est.Error Q2.5 Q97.5
[1,] 3.758548 1.107224 1.574869 5.879727
[2,] 4.871645 1.094450 2.695000 6.9653758.3 Альтернативная модель
Мы можем использовать тот же самый код, но попробовать в качестве переменной использовать логорифм количества гласных. Для того, чтобы использовать какие-то арифемтические операции внутри регрессионной формулы, нужно использовать функцию I() или сделать какие-то модификации переменных до того, как использовать в регрессии.
get_prior(speech_tempo ~ I(log(n_vowels)),
data = df,
family = gaussian())fit2 <- brm(speech_tempo ~ I(log(n_vowels)),
data = df,
family = gaussian(),
cores = n_cores,
silent = TRUE,
prior = c(prior(normal(5.31, 1.93), class = "Intercept", lb = 0),
prior(normal(0, 1), class = "sigma", lb = 0),
prior(normal(0, 10), class = "b", lb = 0)))plot(fit2)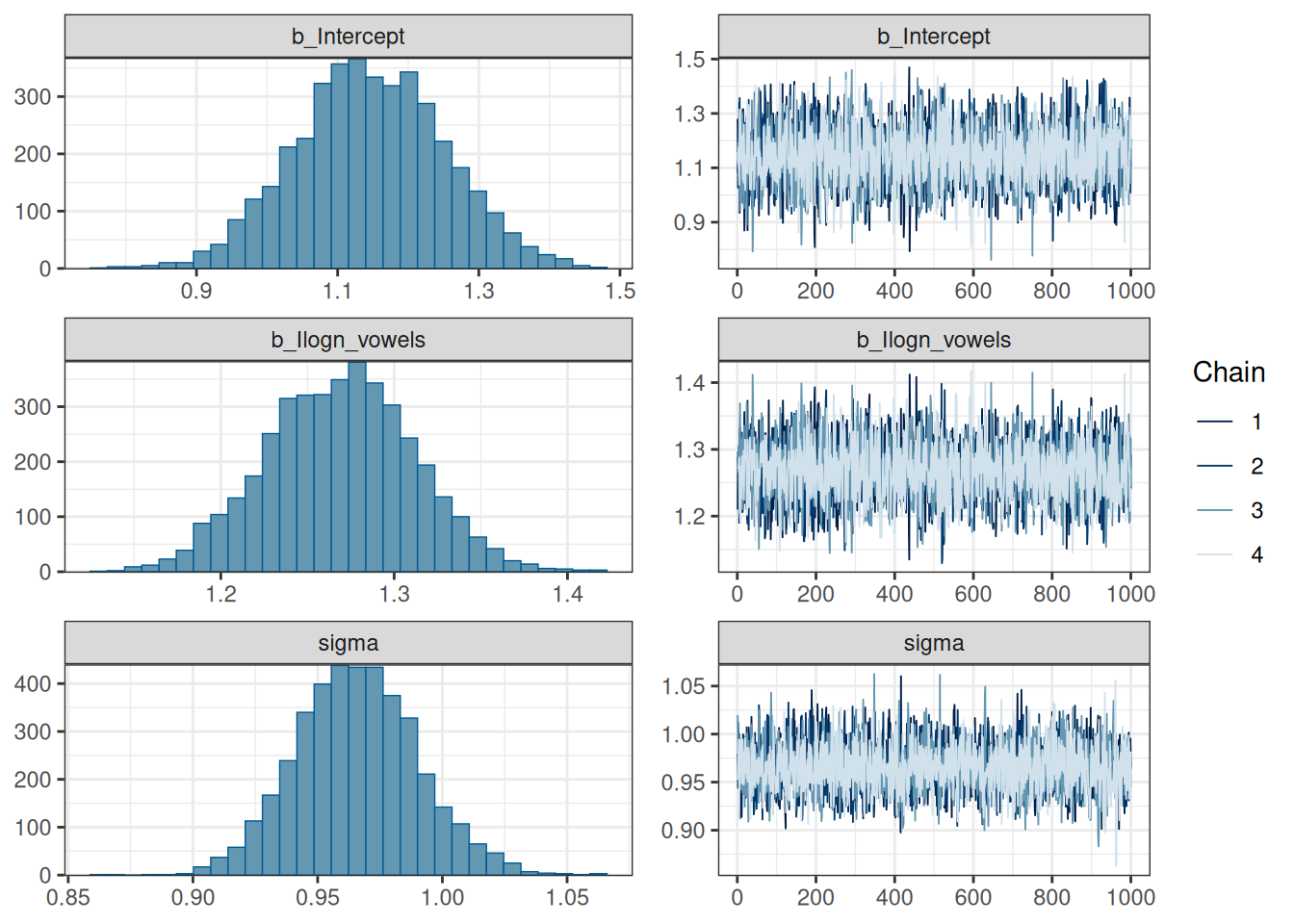
fit2 |>
conditional_effects() |>
plot(points=TRUE)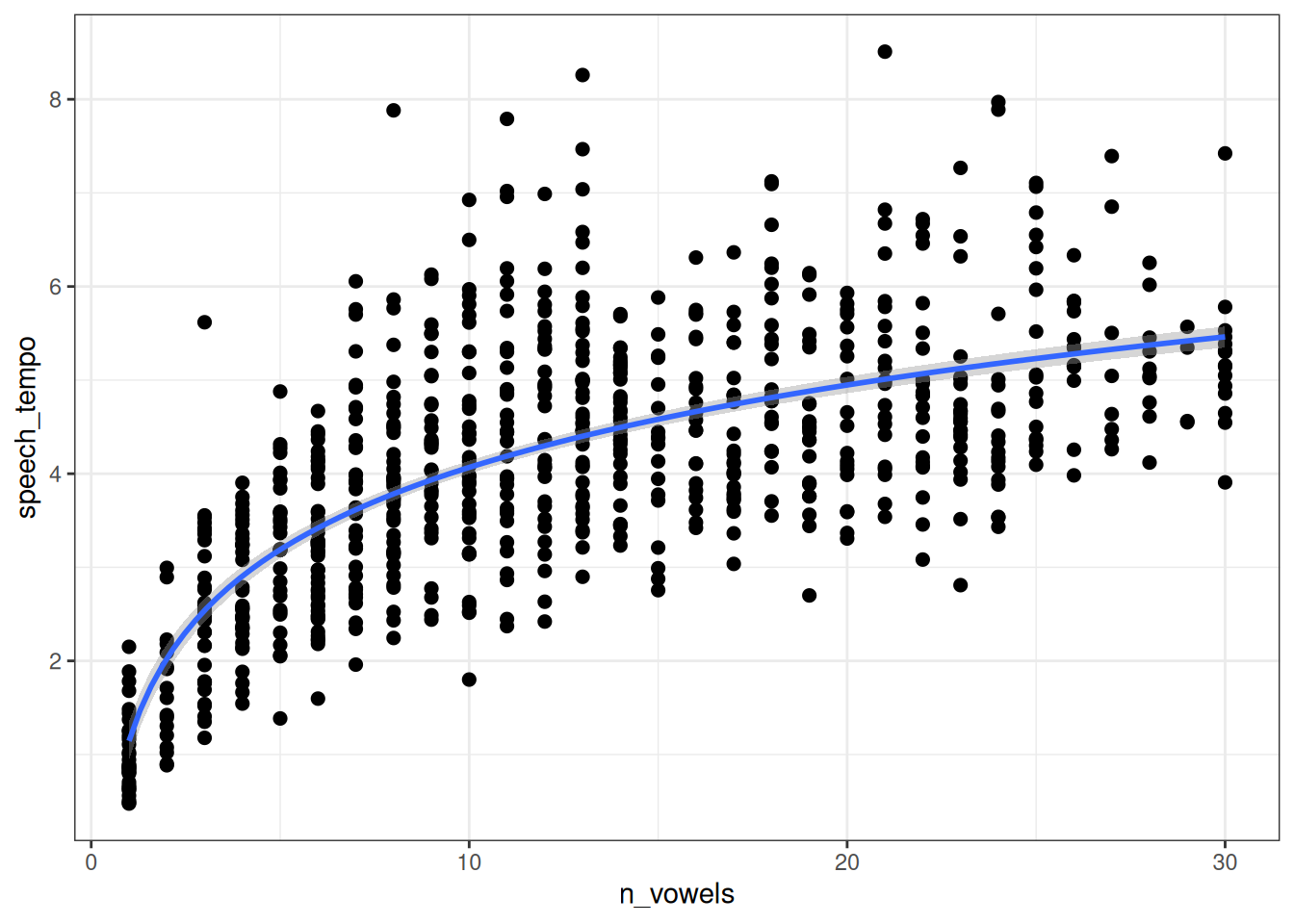
fit2 |>
pp_check(type = "dens_overlay", ndraws = 50)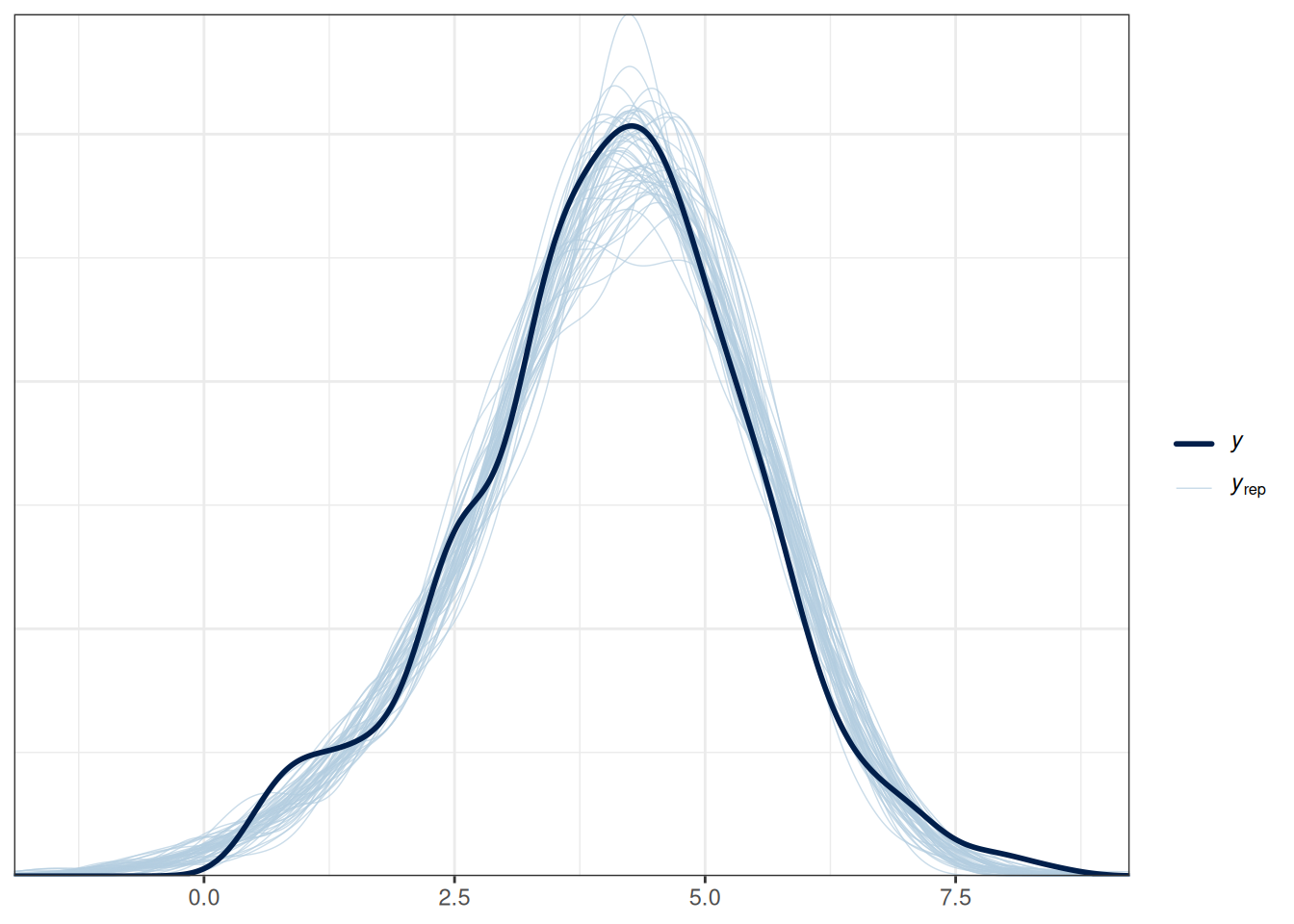
fit2 |>
pp_check(type = "stat")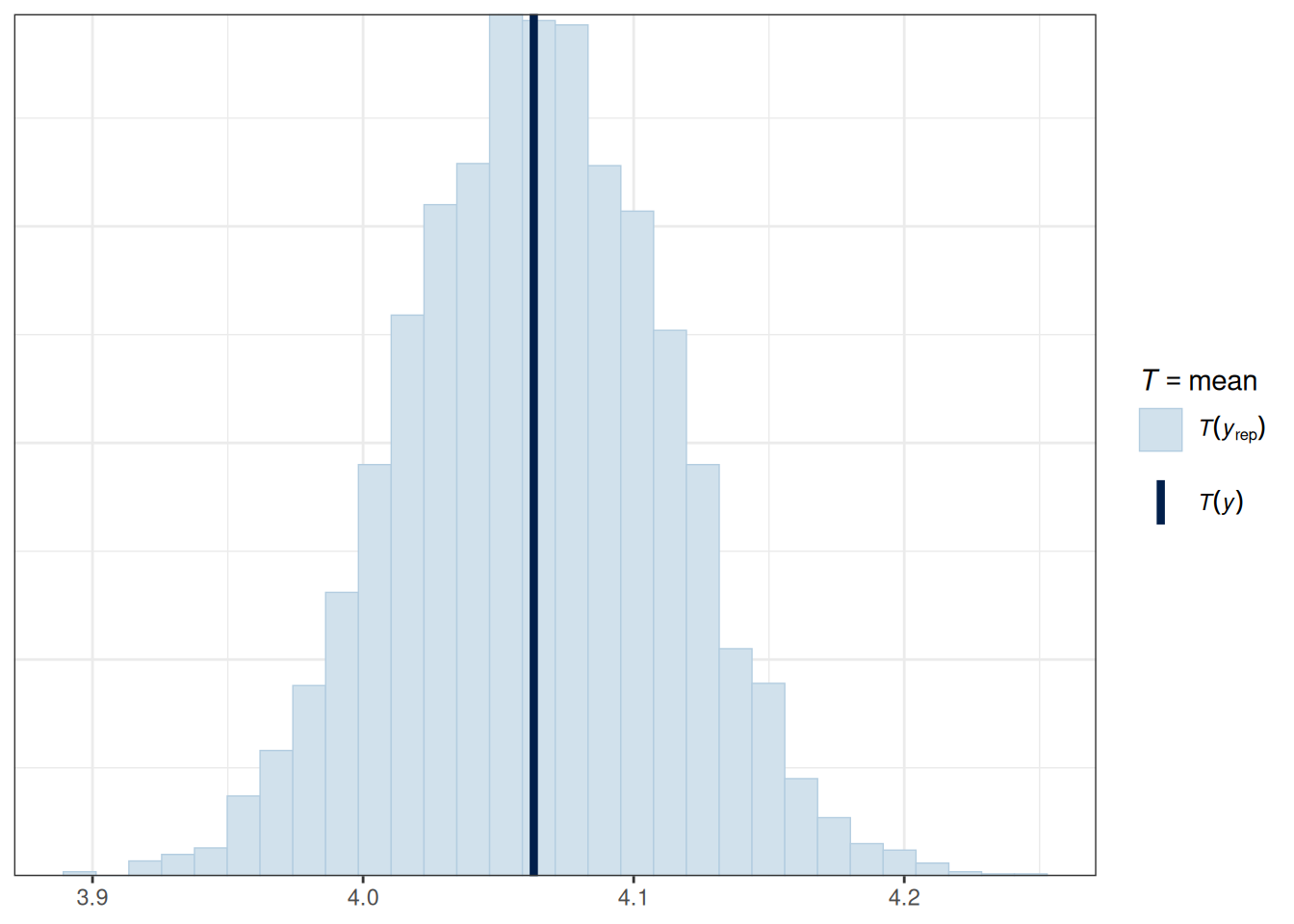
Как интерпретировать полученную регрессию с двумя отлогорифмированными значениями?
В обычной линейной регресии мы узнаем отношения между \(x\) и \(y\): \[y_i = \beta_0+\beta_1\times x_i\]
Как изменится \(y_j\), если мы увеличем \(x_i + 1 = x_j\)? \[y_j = \beta_0+\beta_1\times x_j\]
\[y_j - y_i = \beta_0+\beta_1\times x_j - (\beta_0+\beta_1\times x_i) = \beta_1(x_j - x_i)\]
Т. е. \(y\) увеличится на \(\beta_1\) , если \(x\) увеличится на 1. Что же будет с логарифмированными переменными? Как изменится \(y_j\), если мы увеличем \(x_i + 1 = x_j\)?
\[\log(y_j) - \log(y_i) = \beta_1\times (\log(x_j) - \log(x_i))\]
\[\log\left(\frac{y_j}{y_i}\right) = \beta_1\times \log\left(\frac{x_j}{x_i}\right) = \log\left(\left(\frac{x_j}{x_i}\right) ^ {\beta_1}\right)\]
\[\frac{y_j}{y_i}= \left(\frac{x_j}{x_i}\right) ^ {\beta_1}\]
Т. е. \(y\) увеличится на \(\beta_1\) процентов, если \(x\) увеличится на 1 процент. Эта процентная логика будет работать при любой комбинации. Например, если \(y\) не логорифмирован, а \(x\) логорифмирован интерпретировать это стоит в той же логике: \(y\) увеличится на \(\beta_1\), если \(x\) увеличится на 1 процент.
8.3.1 Сравнение моделей
В работах (Vehtari et al. 2017, 2024) описан метод loo, который оценивает leave-one-out кроссвалидацию, которую можно использовать для сравнения байесовских моделей.
fit1 <- add_criterion(fit1, "loo")
fit1$criteria$loo
Computed from 4000 by 786 log-likelihood matrix.
Estimate SE
elpd_loo -1187.3 22.0
p_loo 3.3 0.3
looic 2374.5 44.0
------
MCSE of elpd_loo is 0.0.
MCSE and ESS estimates assume MCMC draws (r_eff in [0.8, 1.1]).
All Pareto k estimates are good (k < 0.7).
See help('pareto-k-diagnostic') for details.fit2 <- add_criterion(fit2, "loo")
fit2$criteria$loo
Computed from 4000 by 786 log-likelihood matrix.
Estimate SE
elpd_loo -1089.2 24.1
p_loo 3.1 0.4
looic 2178.5 48.3
------
MCSE of elpd_loo is 0.0.
MCSE and ESS estimates assume MCMC draws (r_eff in [0.8, 1.1]).
All Pareto k estimates are good (k < 0.7).
See help('pareto-k-diagnostic') for details.loo_compare(fit1, fit2, criterion = "loo") elpd_diff se_diff
fit2 0.0 0.0
fit1 -98.0 10.4 Большее значение ELPD стоит интепретировать как лучшую предсказательную способность модели. Подробнее про эту метрику можно прочитать, запустив help('pareto-k-diagnostic'). Еще больше на странице пакета loo.
8.4 Категориальные переменные
8.4.1 Default contrast coding: Treatment contrasts
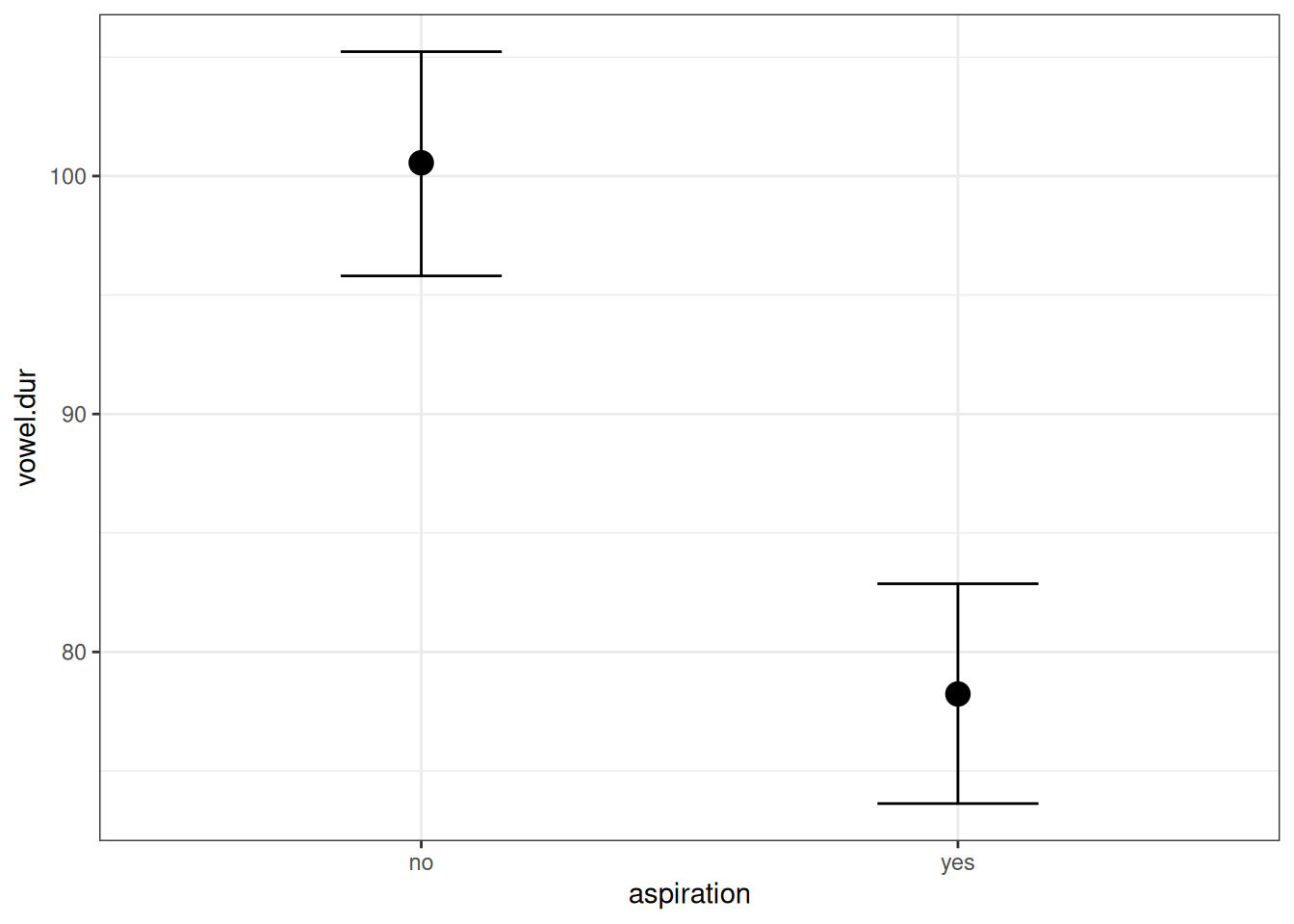
Чтобы добавить категориальную переменную в регрессионный анализ, она должна подвергнуться некоторому преобразованию. Существует несколько методов, которые позволяют это сделать, байесовский подход лишь заставляет нас помнить, что к чему, чтобы можно было адаптировать априорные распределения. Выше мы уже рассматривали задачу, где была построена модель, предсказывающая длительность гласного на основе придыхания предыдущего согласного.
Как этот график соотносится с оценками параметров модели?
Мы видим, что свободный член (b_Intercept) соотносится с отсутствием придыхания, а переменная b_aspirationyes с разницей средних между случаев с придыханием и без. Дело в том, что когда запускается регрессию с категориальной переменной, данная переменная автоматически разбивается на группу бинарных dummy-переменных:
| aspiration | dummy_aspiration_no | dummy_aspiration_yes |
|---|---|---|
| без придыхания | 1 | 0 |
| с придыханием | 0 | 1 |
Дальше для регрессионного анализа выкидывают одну из переменных, так как иначе модель не сойдется (dummy-переменных всегда n-1, где n — количество категорий в переменной).
| aspiration | dummy_aspiration_yes |
|---|---|
| без придыхания | 0 |
| с придыханием | 1 |
Если переменная dummy_aspiration_yes принимает значение 1, значит речь о случаях, где согласный придыхательный, а если принимает значение 0, то о случаях, где согласный непридыхательный. Если вставить нашу переменную в регрессионную формулу получится следующее:
\[y_i = \hat\beta_0 + \hat\beta_1 \times \text{dummy-aspiration-yes} + \epsilon_i,\]
Так как dummy_aspiration_yes принимает либо значение 1, либо значение 0, то получается, что модель предсказывает лишь два значения:
\[y_i = \left\{\begin{array}{ll}\hat\beta_0 + \hat\beta_1 \times 1 + \epsilon_i = \hat\beta_0 + \hat\beta_1 + \epsilon_i\text{, если предыдущий согласный придыхательный}\\ \hat\beta_0 + \hat\beta_1 \times 0 + \epsilon_i = \hat\beta_0 + \epsilon_i\text{, если предыдущий согласный непридыхательный} \end{array}\right.\]
Таким образом, получается, что свободный член \(\beta_0\) и угловой коэффициент \(\beta_1\) в регрессии с категориальной переменной получает другую интерпретацию. Одно из значений переменной кодируется при помощи \(\beta_0\), а сумма коэффициентов \(\beta_0+\beta_1\) дают другое значение переменной. Так что \(\beta_1\) — это разница между оценками средних двух значений переменной.
В случаях, когда значений больше — логика будет та же: будет создаваться n-1 dummy переменных, каждый коэффициент при таких переменных будет говорить о разнице средних переменной и некоторого, выделенного в интерсепт значения, которое становится таким эталоном сравнения. Автоматическая процедура отправляет в эталон сравнения уровень, название которого раньше по алфавиту. Если хочется выбрать другой эталон сравнения, то можно использовать функцию factor() и эксплицитно задать уровни или же использовать функцию fct_relevel(your_variable, "make me the baseline") из пакета forcats (часть tidyverse).
8.4.2 Sum contrasts
Существует и другая стратегия моделирования с категориальной переменной, которая позволяет вернуть логику числовых предикторов, согласно которой свободный член моделирует среднее значение переменной, а коэффициент при категориальной переменной говорит об изменении в предсказываемой переменной, при изменении категориальной переменной.
read_csv("https://raw.githubusercontent.com/agricolamz/2024_HSE_b_da4l/master/data/Coretta_2017_icelandic.csv") |>
filter(speaker == "tt01") |>
mutate(aspiration = factor(aspiration)) ->
vowels
contrasts(vowels$aspiration) yes
no 0
yes 1contrasts(vowels$aspiration) <- c(-1, 1)
get_prior(vowel.dur ~ aspiration,
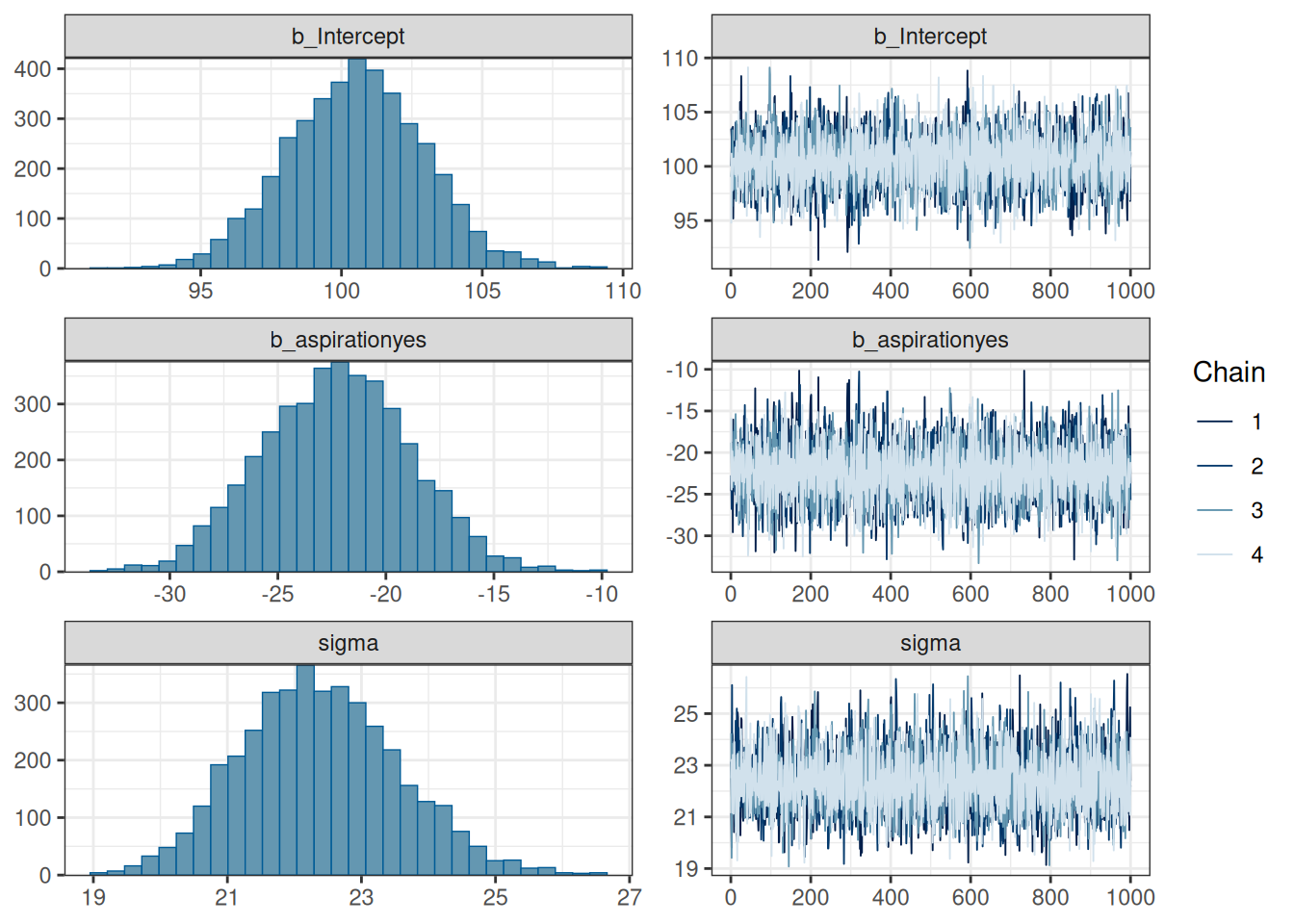
data = vowels)vowels_fit2 <- brm(vowel.dur ~ aspiration,
data = vowels,
cores = n_cores,
silent = TRUE)Running /usr/lib/R/bin/R CMD SHLIB foo.c
using C compiler: ‘gcc (Ubuntu 13.3.0-6ubuntu2~24.04.1) 13.3.0’
gcc -I"/usr/share/R/include" -DNDEBUG -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/Rcpp/include/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/unsupported" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/BH/include" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/StanHeaders/include/src/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/StanHeaders/include/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppParallel/include/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/rstan/include" -DEIGEN_NO_DEBUG -DBOOST_DISABLE_ASSERTS -DBOOST_PENDING_INTEGER_LOG2_HPP -DSTAN_THREADS -DUSE_STANC3 -DSTRICT_R_HEADERS -DBOOST_PHOENIX_NO_VARIADIC_EXPRESSION -D_HAS_AUTO_PTR_ETC=0 -include '/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/StanHeaders/include/stan/math/prim/fun/Eigen.hpp' -D_REENTRANT -DRCPP_PARALLEL_USE_TBB=1 -fpic -g -O2 -fno-omit-frame-pointer -mno-omit-leaf-frame-pointer -ffile-prefix-map=/build/r-base-FPSnzf/r-base-4.3.3=. -fstack-protector-strong -fstack-clash-protection -Wformat -Werror=format-security -fcf-protection -fdebug-prefix-map=/build/r-base-FPSnzf/r-base-4.3.3=/usr/src/r-base-4.3.3-2build2 -Wdate-time -D_FORTIFY_SOURCE=3 -c foo.c -o foo.o
In file included from /home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/Eigen/Core:19,
from /home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/Eigen/Dense:1,
from /home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/StanHeaders/include/stan/math/prim/fun/Eigen.hpp:22,
from <command-line>:
/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/Eigen/src/Core/util/Macros.h:679:10: fatal error: cmath: No such file or directory
679 | #include <cmath>
| ^~~~~~~
compilation terminated.
make: *** [/usr/lib/R/etc/Makeconf:191: foo.o] Error 1plot(vowels_fit2)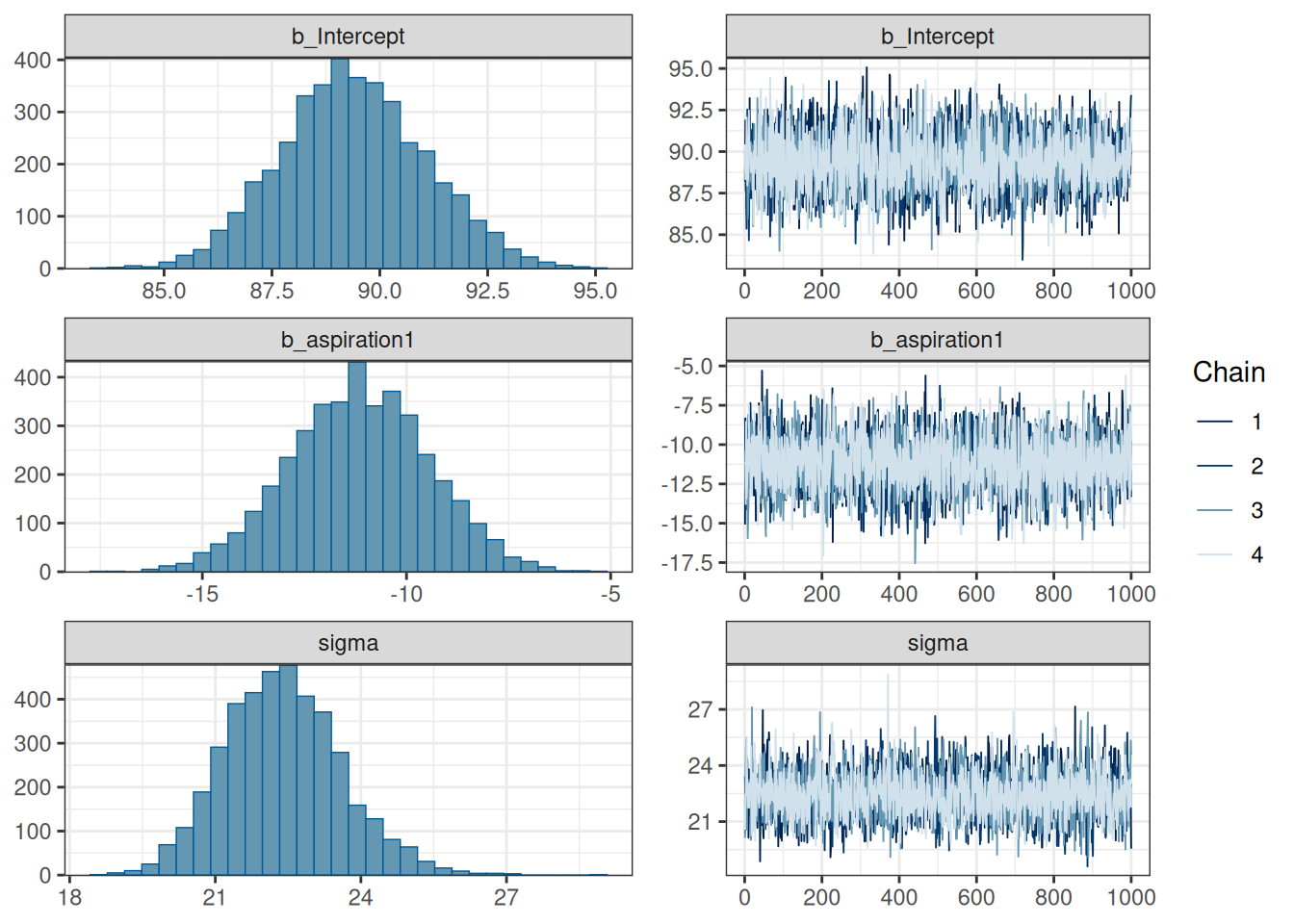
vowels_fit2 |>
conditional_effects() |>
plot()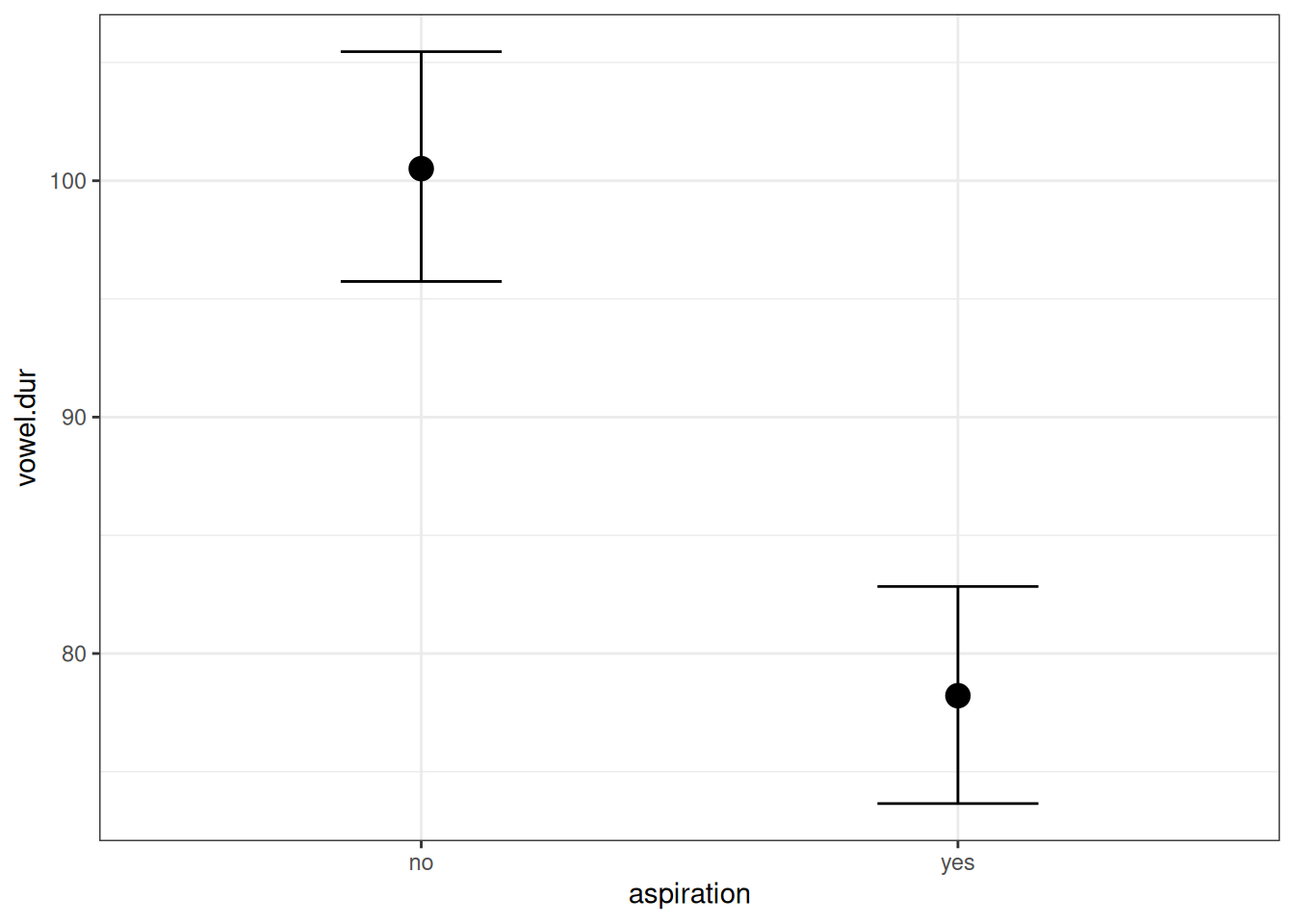
Мы видим, что графики эффектов идентичны, однако графики коэффециентов разные, потому что эффекты теперь закодированы не друг относительно друга, а как некоторое средние между группами \(\pm\) некоторое значение, отраженное в коэффициенте \(\hat\beta_1\) (в нашем случае, если выразить все при помощи средних — 89.38 \(\pm\) 11.18)
vowels_fit2 Family: gaussian
Links: mu = identity
Formula: vowel.dur ~ aspiration
Data: vowels (Number of observations: 175)
Draws: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
total post-warmup draws = 4000
Regression Coefficients:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
Intercept 89.39 1.68 86.20 92.70 1.00 3641 2984
aspiration1 -11.15 1.71 -14.59 -7.87 1.00 4067 2936
Further Distributional Parameters:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
sigma 22.40 1.21 20.15 24.93 1.00 3880 2184
Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).8.4.3 One-hot encoding
Существует еще одна стратегия: оставить все dummy-переменные и убрать случайный член, тогда регрессия будет оценивать каждый уровень переменной, создавая для него отдельный коэффициент.
vowels_fit3 <- brm(vowel.dur ~ -1 + aspiration,
data = vowels,
cores = n_cores,
silent = TRUE)Running /usr/lib/R/bin/R CMD SHLIB foo.c
using C compiler: ‘gcc (Ubuntu 13.3.0-6ubuntu2~24.04.1) 13.3.0’
gcc -I"/usr/share/R/include" -DNDEBUG -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/Rcpp/include/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/unsupported" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/BH/include" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/StanHeaders/include/src/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/StanHeaders/include/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppParallel/include/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/rstan/include" -DEIGEN_NO_DEBUG -DBOOST_DISABLE_ASSERTS -DBOOST_PENDING_INTEGER_LOG2_HPP -DSTAN_THREADS -DUSE_STANC3 -DSTRICT_R_HEADERS -DBOOST_PHOENIX_NO_VARIADIC_EXPRESSION -D_HAS_AUTO_PTR_ETC=0 -include '/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/StanHeaders/include/stan/math/prim/fun/Eigen.hpp' -D_REENTRANT -DRCPP_PARALLEL_USE_TBB=1 -fpic -g -O2 -fno-omit-frame-pointer -mno-omit-leaf-frame-pointer -ffile-prefix-map=/build/r-base-FPSnzf/r-base-4.3.3=. -fstack-protector-strong -fstack-clash-protection -Wformat -Werror=format-security -fcf-protection -fdebug-prefix-map=/build/r-base-FPSnzf/r-base-4.3.3=/usr/src/r-base-4.3.3-2build2 -Wdate-time -D_FORTIFY_SOURCE=3 -c foo.c -o foo.o
In file included from /home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/Eigen/Core:19,
from /home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/Eigen/Dense:1,
from /home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/StanHeaders/include/stan/math/prim/fun/Eigen.hpp:22,
from <command-line>:
/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/Eigen/src/Core/util/Macros.h:679:10: fatal error: cmath: No such file or directory
679 | #include <cmath>
| ^~~~~~~
compilation terminated.
make: *** [/usr/lib/R/etc/Makeconf:191: foo.o] Error 1plot(vowels_fit3)
vowels_fit3 |>
conditional_effects() |>
plot()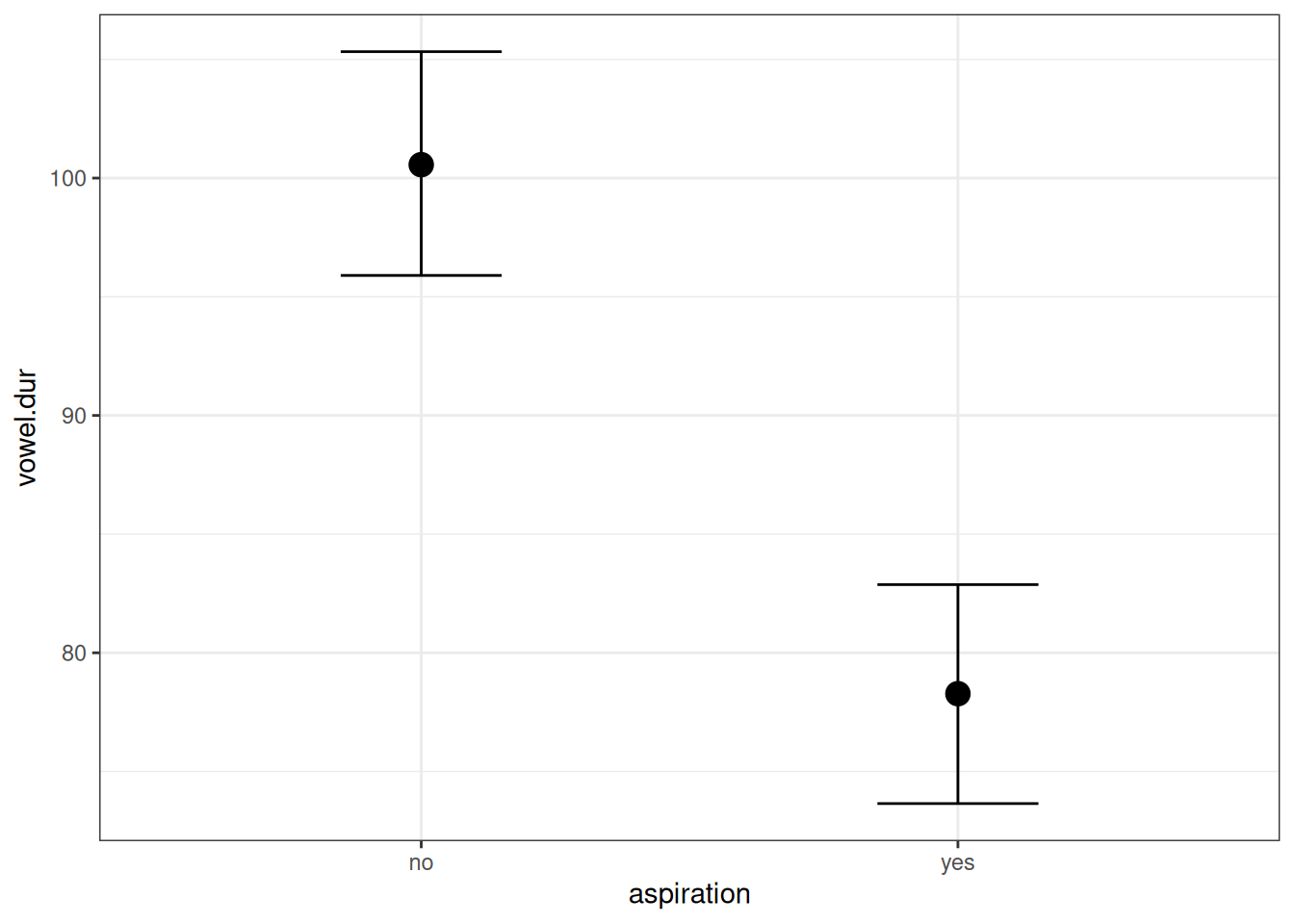
vowels_fit3 Family: gaussian
Links: mu = identity
Formula: vowel.dur ~ -1 + aspiration
Data: vowels (Number of observations: 175)
Draws: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
total post-warmup draws = 4000
Regression Coefficients:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
aspirationno 100.56 2.43 95.90 105.33 1.00 3646 2454
aspirationyes 78.26 2.36 73.65 82.87 1.00 3734 3118
Further Distributional Parameters:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
sigma 22.38 1.21 20.15 24.84 1.00 3563 2752
Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).Использование данной стратегии имеет свой недостаток: у нас исчезают переменные, сравнивающие группы, так что мы не можем проанализировав коэффициенты что-то понять про наличие разницы между ними.
8.4.4 Другие контрасты
- Repeated contrasts: контрасты для анализа упорядоченных переменных (например, образование, возраст и т. п.)
- Helmert contrasts: первый контрсат сравнивает между уровнями L1 и L2, следующий сравнивает уровне L3 и средние между (L1 и L2), следующий сравнивает L4 и среднее между (L1, L2 и L3) и т. д.
- и другие
Вообще есть семейство функций, позволяющее задать контрасты:
contr.treatment()contr.sum()contr.helmert()contr.poly()
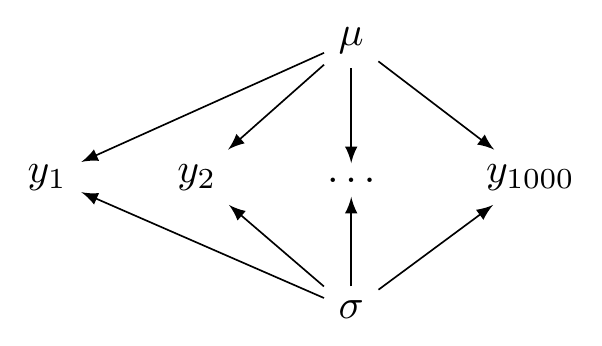
8.5 Иерархические модели
Одним из важных предположений регрессионного анализа является независимость наблюдений друг от друга. Однако часто в данных можно встретить различные группировки наблюдений, которые следует учитывать. В статистическом моделировании принято различать разные методы для борьбы с независимостью наблюдений. Во-первых, группировку можно разметить и добавить в основные эффекты регрессии. Если эта группировка как-то важна для исследования, то оценка параметров такого варьирования будет иметь смысл. Однако бывают такого рода группировки, которые нам неинтересно вставлять в основные эффекты регрессии: нам хочется сделать обобщение внутри группировки, а потом построить обобщение над обобщениями. Использование такого рода модель позволяет
- признать, что в данных есть нарушение независимости наблюдений друг от друга;
- учесть эффект группировок;
- и абстрагироваться от группировок, делая предсказания в том числе для таких уровней группы, которых мы еще не наблюдаем в наших данных.
Такого рода модели называют моделями со смешанными эффектами. При моделировании при помощи моделей со случайными эффектами различают:
- основные эффекты – это те связи, которые нас интересуют, независимые переменные (скорость речи, наличие придыхания…);
- случайные эффекты – это те переменные, которые создают группировку в данных (корпус, носитель, стимул и т. п.).
В результате моделирования появляется обобщенная модель, которая игнорирует группировку, а потом для каждого значения случайного эффекта генерируется своя регрессия, отсчитывая от обобщенной модели как от базового уровня.
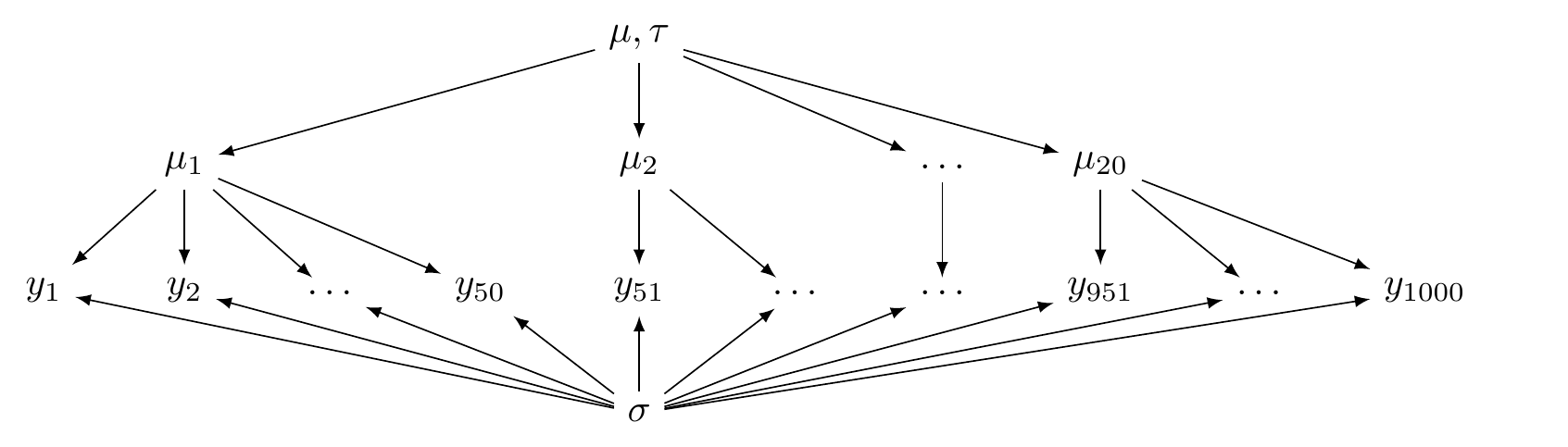
В заданиях выше, когда мы предсказывали скорость речи, мы все время отфильтровывали одного конкретного носителя и делали модель для него. Это связано с тем, что носитель — это образцовый пример случайного эффекта. Давайте теперь попробуем смоделировать скорость речи для всех носителей из звинигородского корпуса
df <- read_csv("https://raw.githubusercontent.com/agricolamz/2026_HSE_b_da4l/master/data/speech_tempo_zvenigorod.csv")Случайные эффекты записываются в круглых скобках. Почему перед ним тоже нужно писать 1 (что означает интерсепт) станет ясно из примеров ниже. Давайте сравним априорные распределения по-умолчанию, которые предлагает brms для моделей со смешанными эффектами и для моделей без них:
get_prior(speech_tempo ~ 1,
data = df,
family = gaussian())get_prior(speech_tempo ~ (1|speaker),
data = df,
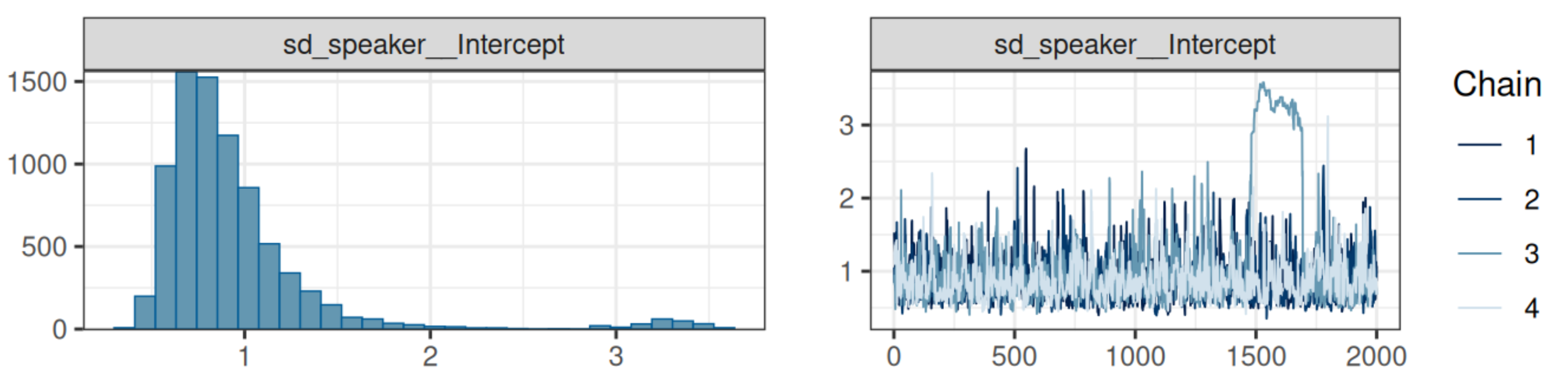
family = gaussian())Как видно добавились много параметров sd, которыми принято обозначать параметры вариативности модели внутри групп, в то время как sigma продолжает быть параметром, определяющим вариативность между группами.
fit_hierarchical <- brm(speech_tempo ~ (1|speaker),
data = df,
family = gaussian(),
cores = n_cores,
silent = TRUE,
prior = c(prior(normal(5.31, 1.93), class = "Intercept", lb = 0),
prior(normal(2, 5), class = "sigma", lb = 0),
prior(normal(2, 10), class = "sd")),
iter = 4000,
control = list(adapt_delta = .85))Running /usr/lib/R/bin/R CMD SHLIB foo.c
using C compiler: ‘gcc (Ubuntu 13.3.0-6ubuntu2~24.04.1) 13.3.0’
gcc -I"/usr/share/R/include" -DNDEBUG -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/Rcpp/include/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/unsupported" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/BH/include" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/StanHeaders/include/src/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/StanHeaders/include/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppParallel/include/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/rstan/include" -DEIGEN_NO_DEBUG -DBOOST_DISABLE_ASSERTS -DBOOST_PENDING_INTEGER_LOG2_HPP -DSTAN_THREADS -DUSE_STANC3 -DSTRICT_R_HEADERS -DBOOST_PHOENIX_NO_VARIADIC_EXPRESSION -D_HAS_AUTO_PTR_ETC=0 -include '/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/StanHeaders/include/stan/math/prim/fun/Eigen.hpp' -D_REENTRANT -DRCPP_PARALLEL_USE_TBB=1 -fpic -g -O2 -fno-omit-frame-pointer -mno-omit-leaf-frame-pointer -ffile-prefix-map=/build/r-base-FPSnzf/r-base-4.3.3=. -fstack-protector-strong -fstack-clash-protection -Wformat -Werror=format-security -fcf-protection -fdebug-prefix-map=/build/r-base-FPSnzf/r-base-4.3.3=/usr/src/r-base-4.3.3-2build2 -Wdate-time -D_FORTIFY_SOURCE=3 -c foo.c -o foo.o
In file included from /home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/Eigen/Core:19,
from /home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/Eigen/Dense:1,
from /home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/StanHeaders/include/stan/math/prim/fun/Eigen.hpp:22,
from <command-line>:
/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/Eigen/src/Core/util/Macros.h:679:10: fatal error: cmath: No such file or directory
679 | #include <cmath>
| ^~~~~~~
compilation terminated.
make: *** [/usr/lib/R/etc/Makeconf:191: foo.o] Error 1Warning: There were 100 divergent transitions after warmup. See
https://mc-stan.org/misc/warnings.html#divergent-transitions-after-warmup
to find out why this is a problem and how to eliminate them.Warning: Examine the pairs() plot to diagnose sampling problemsWarning: Bulk Effective Samples Size (ESS) is too low, indicating posterior means and medians may be unreliable.
Running the chains for more iterations may help. See
https://mc-stan.org/misc/warnings.html#bulk-essWarning: Tail Effective Samples Size (ESS) is too low, indicating posterior variances and tail quantiles may be unreliable.
Running the chains for more iterations may help. See
https://mc-stan.org/misc/warnings.html#tail-essfit_hierarchicalWarning: There were 100 divergent transitions after warmup. Increasing
adapt_delta above 0.85 may help. See
http://mc-stan.org/misc/warnings.html#divergent-transitions-after-warmup Family: gaussian
Links: mu = identity
Formula: speech_tempo ~ (1 | speaker)
Data: df (Number of observations: 5623)
Draws: 4 chains, each with iter = 4000; warmup = 2000; thin = 1;
total post-warmup draws = 8000
Multilevel Hyperparameters:
~speaker (Number of levels: 9)
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
sd(Intercept) 0.95 0.47 0.52 2.92 1.02 235 68
Regression Coefficients:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
Intercept 4.59 0.31 4.01 5.21 1.01 672 954
Further Distributional Parameters:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
sigma 1.38 0.01 1.35 1.40 1.01 3752 3590
Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).plot(fit_hierarchical)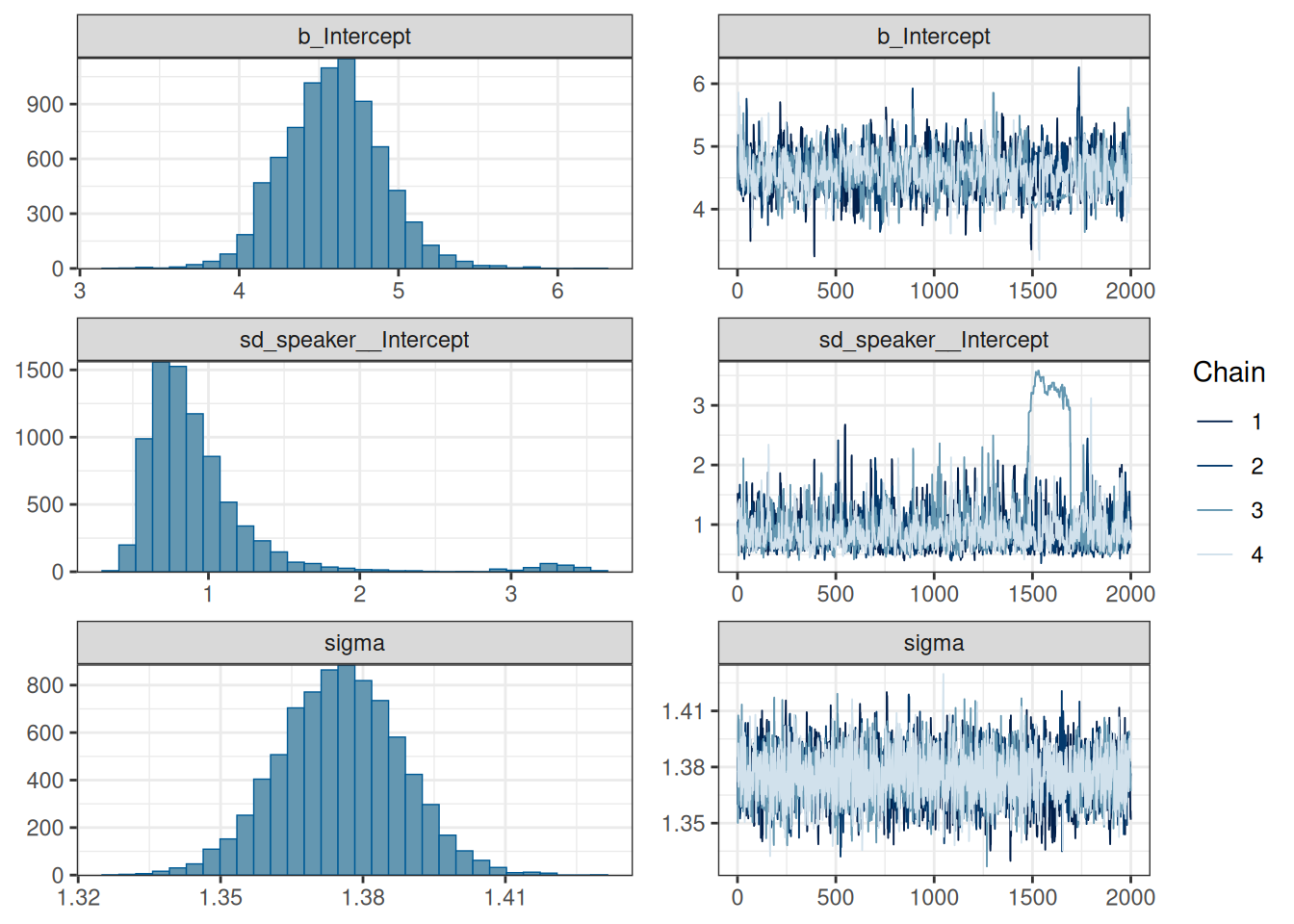
В случаях, когда у нас нет предикторов, визуализация параметров иллюстрирует необходимые распределения.
8.6 Другие варианты моделей с группировками
8.6.1 Complete pooling model
fit_complete_pooling <- brm(speech_tempo ~ 1,
data = df,
family = gaussian(),
cores = n_cores,
silent = TRUE)fit_complete_pooling Family: gaussian
Links: mu = identity
Formula: speech_tempo ~ 1
Data: df (Number of observations: 5623)
Draws: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
total post-warmup draws = 4000
Regression Coefficients:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
Intercept 4.64 0.02 4.60 4.68 1.00 3001 2571
Further Distributional Parameters:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
sigma 1.59 0.02 1.56 1.62 1.00 3905 2678
Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).plot(fit_complete_pooling)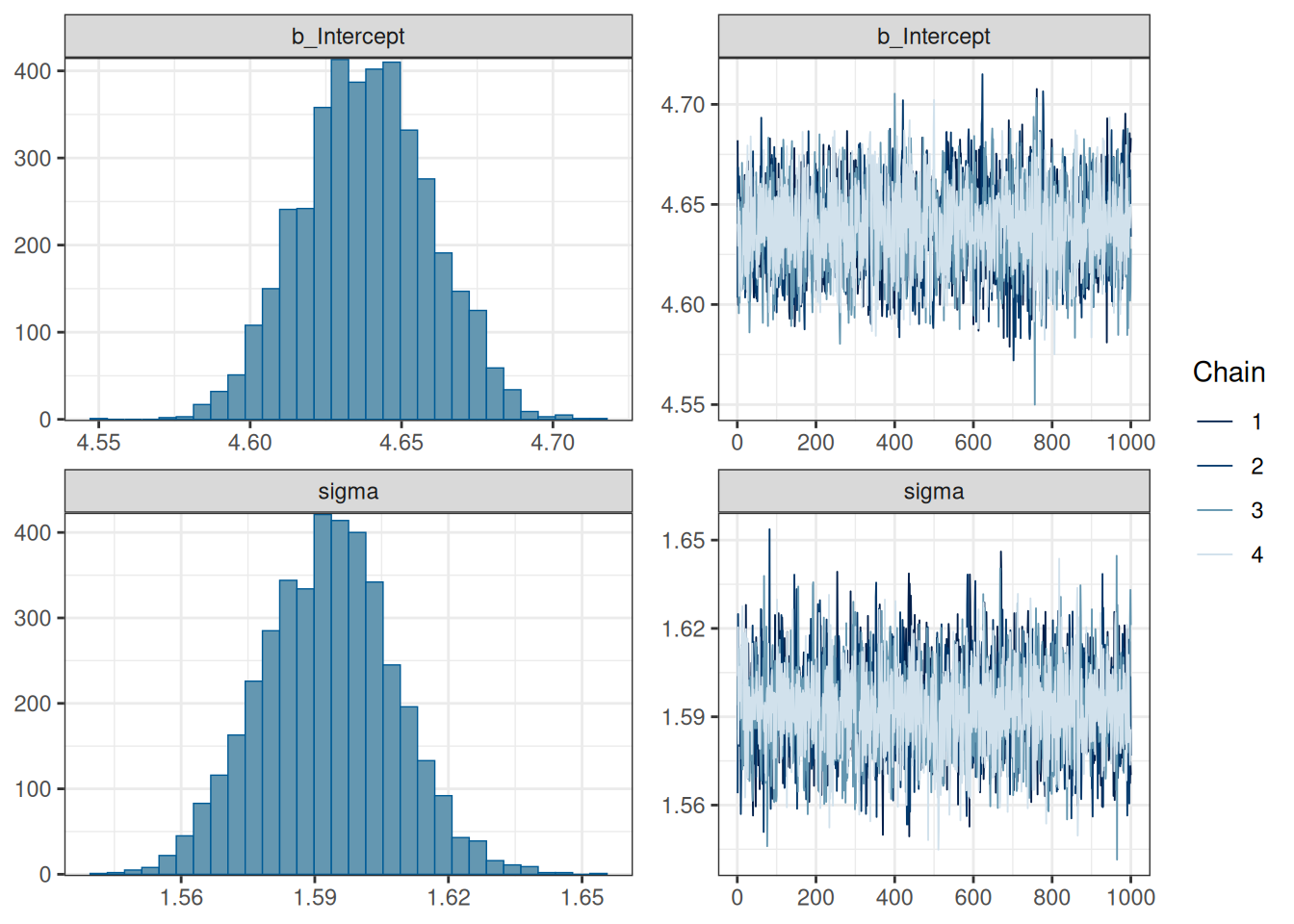
8.6.2 No pooling model
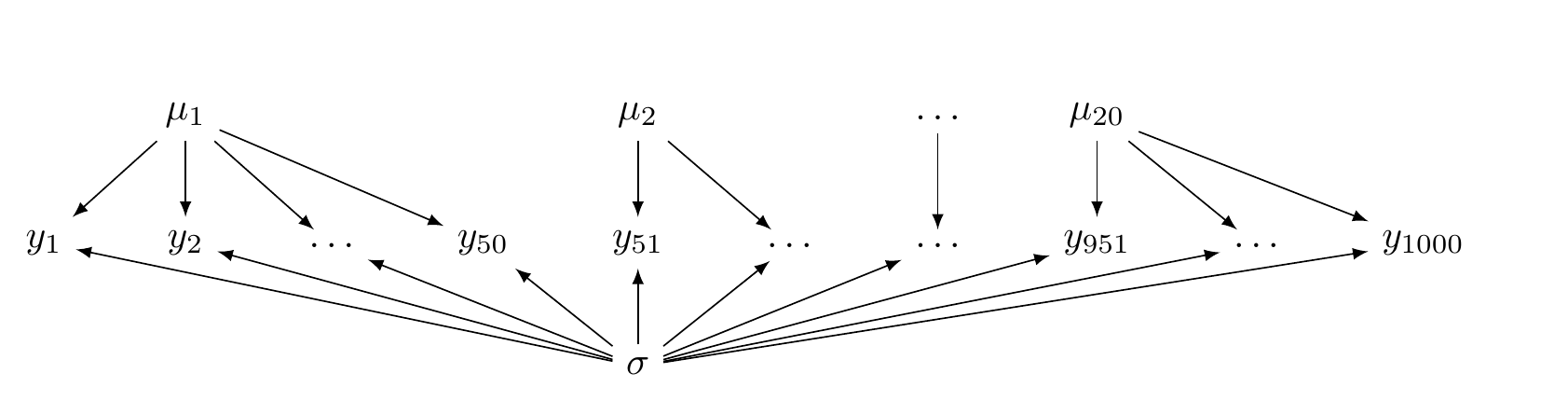
fit_no_pooling <- brm(speech_tempo ~ 0 + speaker,
data = df,
family = gaussian(),
cores = n_cores,
silent = TRUE,
prior = c(prior(normal(2, 5), class = "sigma", lb = 0),
prior(normal(0, 10), class = "b", lb = 0)))fit_no_pooling Family: gaussian
Links: mu = identity
Formula: speech_tempo ~ 0 + speaker
Data: df (Number of observations: 5623)
Draws: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
total post-warmup draws = 4000
Regression Coefficients:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
speakerea1976 4.06 0.05 3.97 4.16 1.00 8928 2896
speakerli1950 4.32 0.07 4.19 4.45 1.00 8650 3275
speakeroa1975 4.73 0.06 4.61 4.85 1.00 8049 3281
speakerom1973 4.24 0.04 4.15 4.32 1.00 7198 2790
speakertk1949 4.91 0.07 4.78 5.04 1.00 8520 2679
speakerva1940 3.50 0.06 3.39 3.61 1.00 7850 3158
speakervg1945 4.74 0.08 4.57 4.90 1.00 9845 3190
speakervi1972 6.14 0.04 6.06 6.22 1.00 7777 2662
speakerya1968 4.46 0.06 4.35 4.57 1.00 7966 2509
Further Distributional Parameters:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
sigma 1.38 0.01 1.35 1.40 1.00 8270 3328
Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).plot(fit_no_pooling)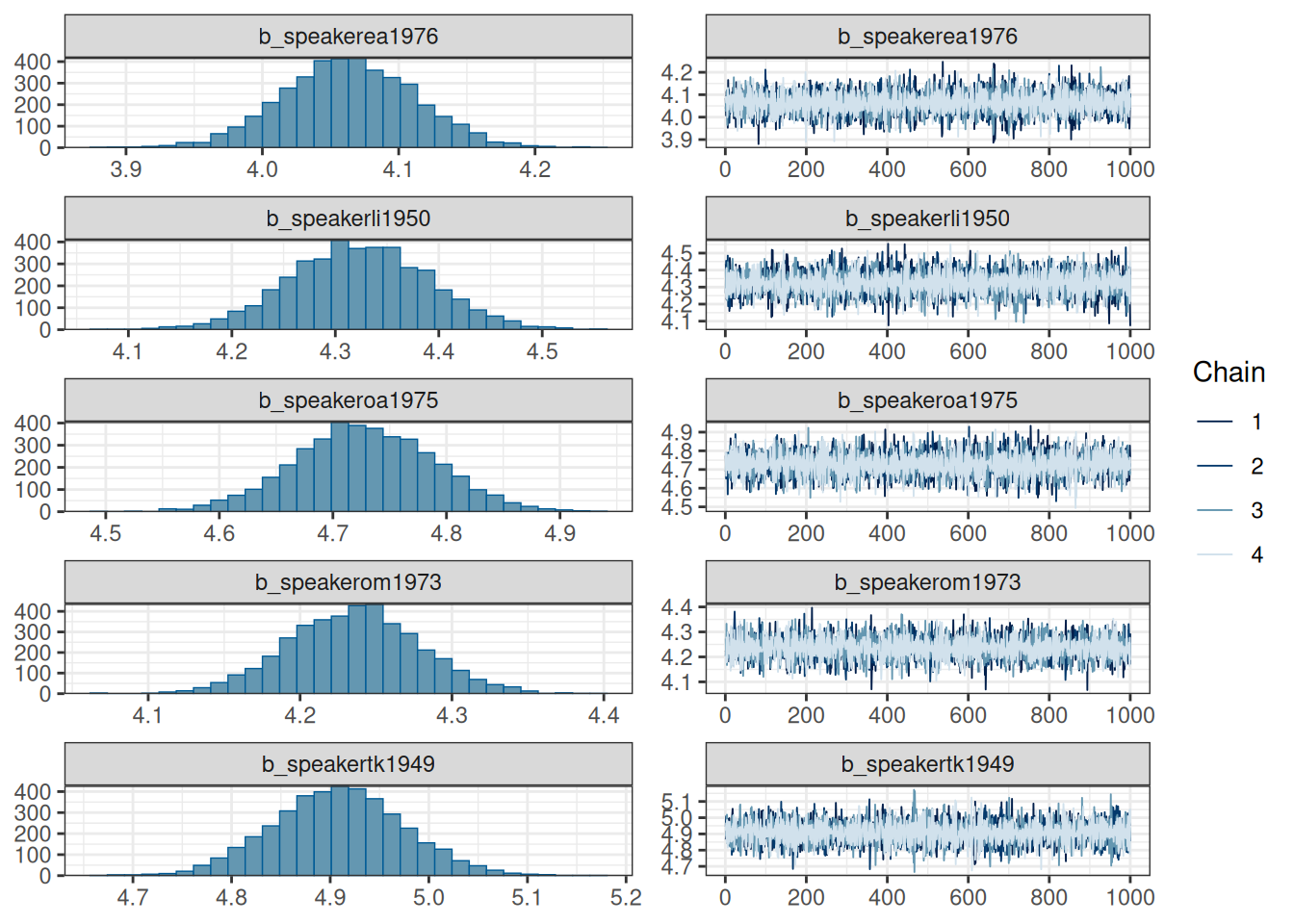
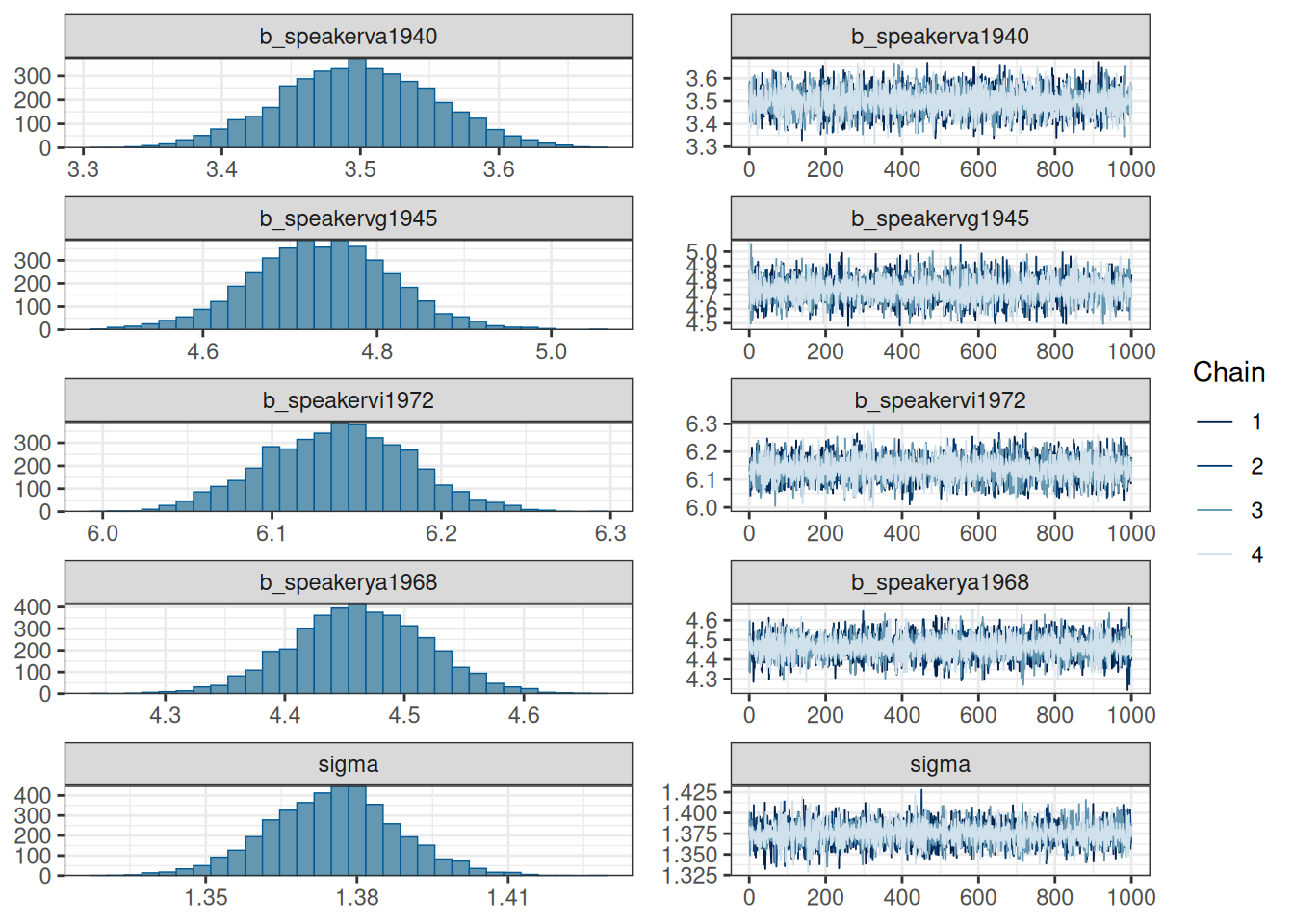
8.7 Модель со случайным эффектом: добавляем предикторы
fit_hierarchical_intercept <- brm(speech_tempo ~ I(log(n_vowels)) + (1|speaker),
data = df,
family = gaussian(),
cores = n_cores,
silent = TRUE,
prior = c(prior(normal(5.31, 1.93), class = "Intercept", lb = 0),
prior(normal(2, 5), class = "sigma", lb = 0),
prior(normal(2, 10), class = "sd")),
iter = 4000,
control = list(adapt_delta = .85))Running /usr/lib/R/bin/R CMD SHLIB foo.c
using C compiler: ‘gcc (Ubuntu 13.3.0-6ubuntu2~24.04.1) 13.3.0’
gcc -I"/usr/share/R/include" -DNDEBUG -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/Rcpp/include/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/unsupported" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/BH/include" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/StanHeaders/include/src/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/StanHeaders/include/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppParallel/include/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/rstan/include" -DEIGEN_NO_DEBUG -DBOOST_DISABLE_ASSERTS -DBOOST_PENDING_INTEGER_LOG2_HPP -DSTAN_THREADS -DUSE_STANC3 -DSTRICT_R_HEADERS -DBOOST_PHOENIX_NO_VARIADIC_EXPRESSION -D_HAS_AUTO_PTR_ETC=0 -include '/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/StanHeaders/include/stan/math/prim/fun/Eigen.hpp' -D_REENTRANT -DRCPP_PARALLEL_USE_TBB=1 -fpic -g -O2 -fno-omit-frame-pointer -mno-omit-leaf-frame-pointer -ffile-prefix-map=/build/r-base-FPSnzf/r-base-4.3.3=. -fstack-protector-strong -fstack-clash-protection -Wformat -Werror=format-security -fcf-protection -fdebug-prefix-map=/build/r-base-FPSnzf/r-base-4.3.3=/usr/src/r-base-4.3.3-2build2 -Wdate-time -D_FORTIFY_SOURCE=3 -c foo.c -o foo.o
In file included from /home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/Eigen/Core:19,
from /home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/Eigen/Dense:1,
from /home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/StanHeaders/include/stan/math/prim/fun/Eigen.hpp:22,
from <command-line>:
/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/Eigen/src/Core/util/Macros.h:679:10: fatal error: cmath: No such file or directory
679 | #include <cmath>
| ^~~~~~~
compilation terminated.
make: *** [/usr/lib/R/etc/Makeconf:191: foo.o] Error 1Warning: There were 14 divergent transitions after warmup. See
https://mc-stan.org/misc/warnings.html#divergent-transitions-after-warmup
to find out why this is a problem and how to eliminate them.Warning: Examine the pairs() plot to diagnose sampling problemsfit_hierarchical_interceptWarning: There were 14 divergent transitions after warmup. Increasing
adapt_delta above 0.85 may help. See
http://mc-stan.org/misc/warnings.html#divergent-transitions-after-warmup Family: gaussian
Links: mu = identity
Formula: speech_tempo ~ I(log(n_vowels)) + (1 | speaker)
Data: df (Number of observations: 5623)
Draws: 4 chains, each with iter = 4000; warmup = 2000; thin = 1;
total post-warmup draws = 8000
Multilevel Hyperparameters:
~speaker (Number of levels: 9)
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
sd(Intercept) 0.82 0.27 0.47 1.50 1.00 1228 1499
Regression Coefficients:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
Intercept 1.90 0.29 1.32 2.49 1.00 1176 1535
Ilogn_vowels 1.14 0.02 1.10 1.18 1.00 4224 1914
Further Distributional Parameters:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
sigma 1.09 0.01 1.07 1.11 1.00 4605 3492
Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).plot(fit_hierarchical_intercept)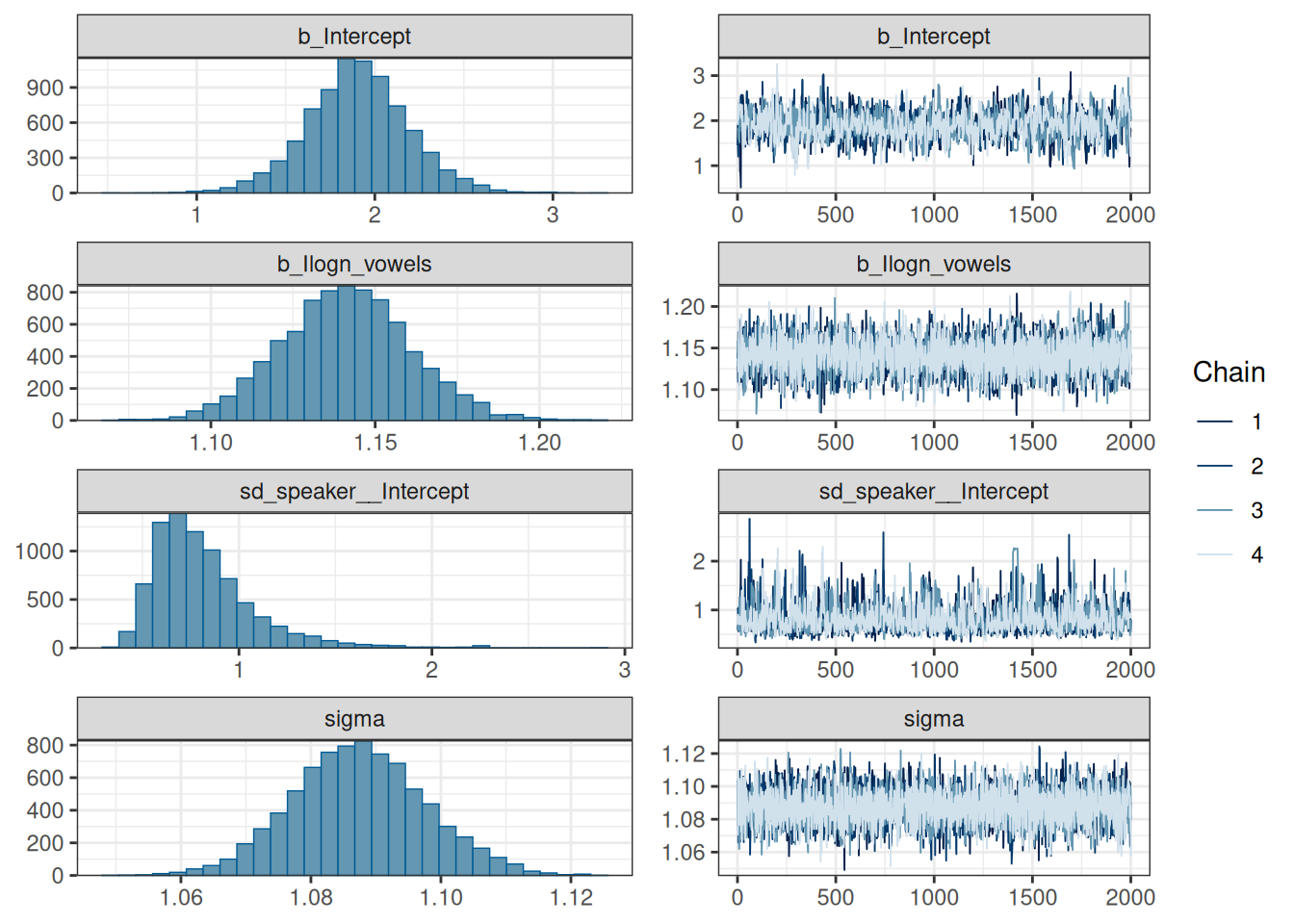
fit_hierarchical_intercept |>
conditional_effects() |>
plot(points = TRUE)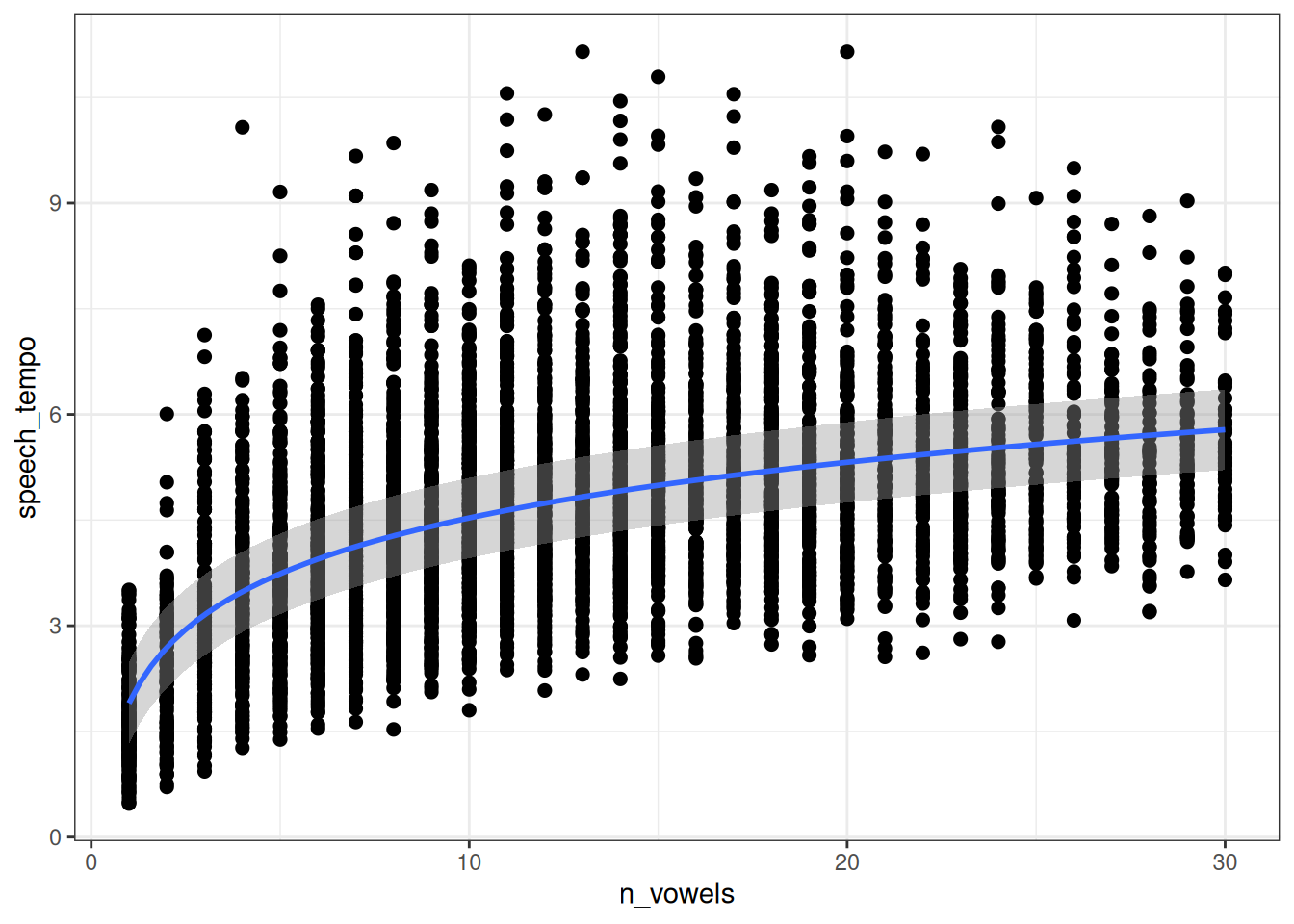
Cлучайные члены для каждого носителя
ranef(fit_hierarchical_intercept)$speaker[,,"Intercept"] |>
as.data.frame() |>
rownames_to_column("speaker") |>
ggplot(aes(y = speaker, x = Estimate)) +
geom_errorbar(aes(xmin = `Q2.5`, xmax = `Q97.5`))+
geom_vline(xintercept = 0, linetype = 2) +
geom_point()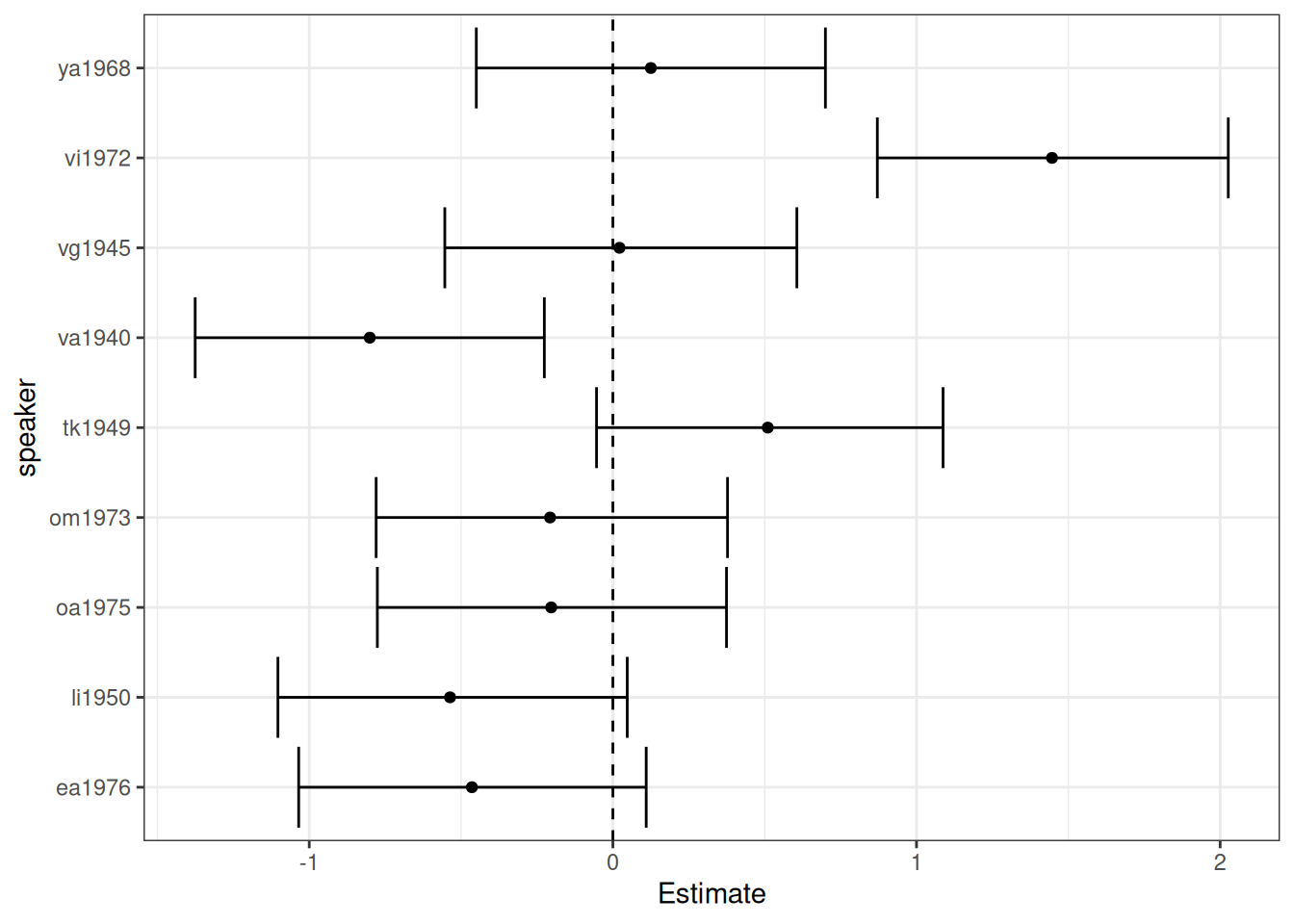
fit_hierarchical_intercept_slope <- brm(speech_tempo ~ I(log(n_vowels)) + (I(log(n_vowels)) + 1|speaker),
data = df,
family = gaussian(),
cores = n_cores,
silent = TRUE,
prior = c(prior(normal(5.31, 1.93), class = "Intercept", lb = 0),
prior(normal(2, 5), class = "sigma", lb = 0),
prior(normal(2, 10), class = "sd")),
iter = 4000,
control = list(adapt_delta = .85))Running /usr/lib/R/bin/R CMD SHLIB foo.c
using C compiler: ‘gcc (Ubuntu 13.3.0-6ubuntu2~24.04.1) 13.3.0’
gcc -I"/usr/share/R/include" -DNDEBUG -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/Rcpp/include/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/unsupported" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/BH/include" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/StanHeaders/include/src/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/StanHeaders/include/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppParallel/include/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/rstan/include" -DEIGEN_NO_DEBUG -DBOOST_DISABLE_ASSERTS -DBOOST_PENDING_INTEGER_LOG2_HPP -DSTAN_THREADS -DUSE_STANC3 -DSTRICT_R_HEADERS -DBOOST_PHOENIX_NO_VARIADIC_EXPRESSION -D_HAS_AUTO_PTR_ETC=0 -include '/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/StanHeaders/include/stan/math/prim/fun/Eigen.hpp' -D_REENTRANT -DRCPP_PARALLEL_USE_TBB=1 -fpic -g -O2 -fno-omit-frame-pointer -mno-omit-leaf-frame-pointer -ffile-prefix-map=/build/r-base-FPSnzf/r-base-4.3.3=. -fstack-protector-strong -fstack-clash-protection -Wformat -Werror=format-security -fcf-protection -fdebug-prefix-map=/build/r-base-FPSnzf/r-base-4.3.3=/usr/src/r-base-4.3.3-2build2 -Wdate-time -D_FORTIFY_SOURCE=3 -c foo.c -o foo.o
In file included from /home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/Eigen/Core:19,
from /home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/Eigen/Dense:1,
from /home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/StanHeaders/include/stan/math/prim/fun/Eigen.hpp:22,
from <command-line>:
/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/Eigen/src/Core/util/Macros.h:679:10: fatal error: cmath: No such file or directory
679 | #include <cmath>
| ^~~~~~~
compilation terminated.
make: *** [/usr/lib/R/etc/Makeconf:191: foo.o] Error 1Warning: There were 3 divergent transitions after warmup. See
https://mc-stan.org/misc/warnings.html#divergent-transitions-after-warmup
to find out why this is a problem and how to eliminate them.Warning: Examine the pairs() plot to diagnose sampling problemsfit_hierarchical_intercept_slopeWarning: There were 3 divergent transitions after warmup. Increasing
adapt_delta above 0.85 may help. See
http://mc-stan.org/misc/warnings.html#divergent-transitions-after-warmup Family: gaussian
Links: mu = identity
Formula: speech_tempo ~ I(log(n_vowels)) + (I(log(n_vowels)) + 1 | speaker)
Data: df (Number of observations: 5623)
Draws: 4 chains, each with iter = 4000; warmup = 2000; thin = 1;
total post-warmup draws = 8000
Multilevel Hyperparameters:
~speaker (Number of levels: 9)
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS
sd(Intercept) 0.97 0.33 0.54 1.81 1.00 2343
sd(Ilogn_vowels) 0.17 0.07 0.08 0.34 1.00 1839
cor(Intercept,Ilogn_vowels) -0.35 0.32 -0.84 0.37 1.00 3523
Tail_ESS
sd(Intercept) 3386
sd(Ilogn_vowels) 2851
cor(Intercept,Ilogn_vowels) 3858
Regression Coefficients:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
Intercept 1.84 0.33 1.18 2.50 1.00 2071 3003
Ilogn_vowels 1.17 0.07 1.04 1.30 1.00 2809 2754
Further Distributional Parameters:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
sigma 1.08 0.01 1.06 1.10 1.00 11159 5589
Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).plot(fit_hierarchical_intercept_slope)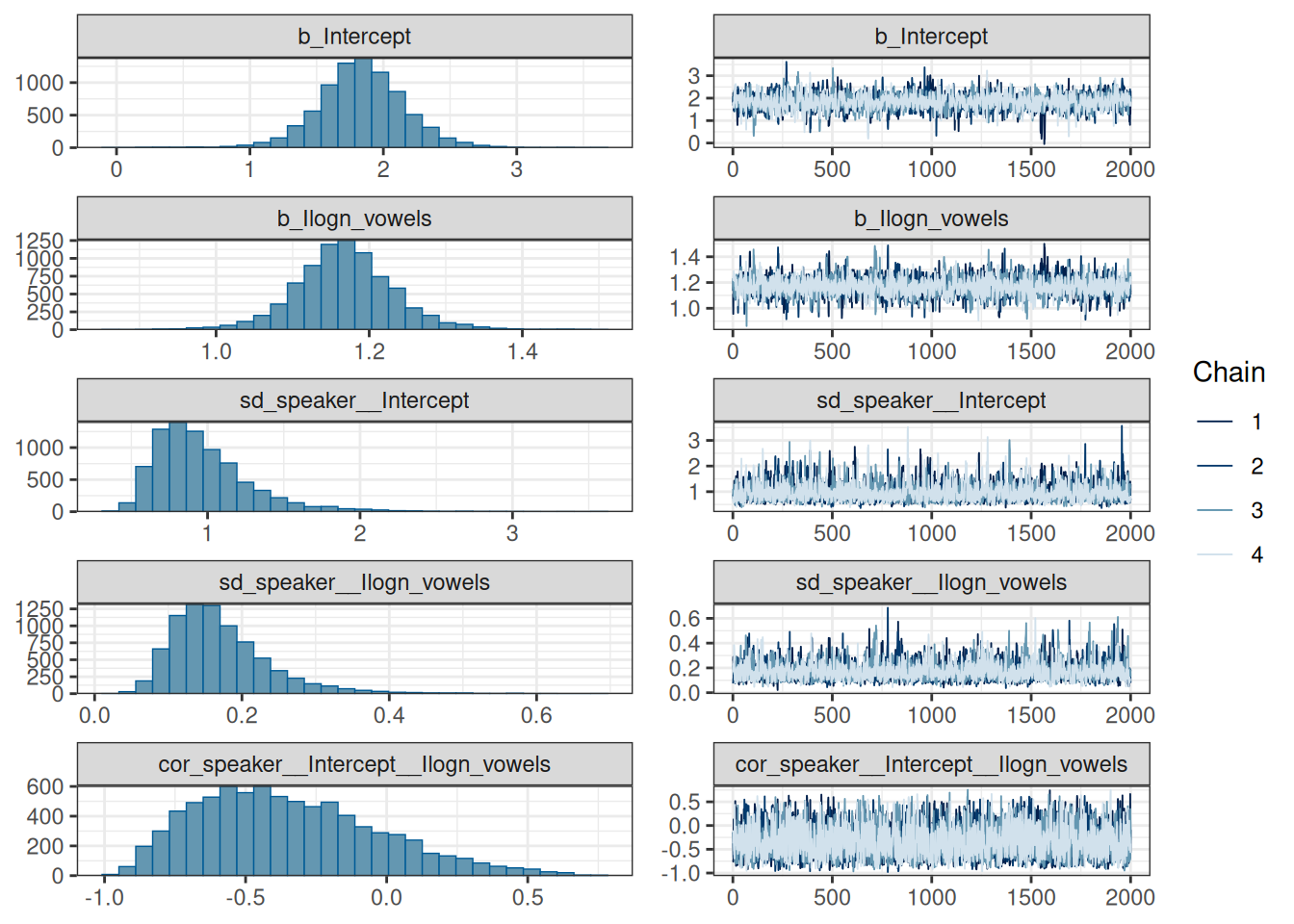
fit_hierarchical_intercept_slope |>
conditional_effects() |>
plot(points = TRUE)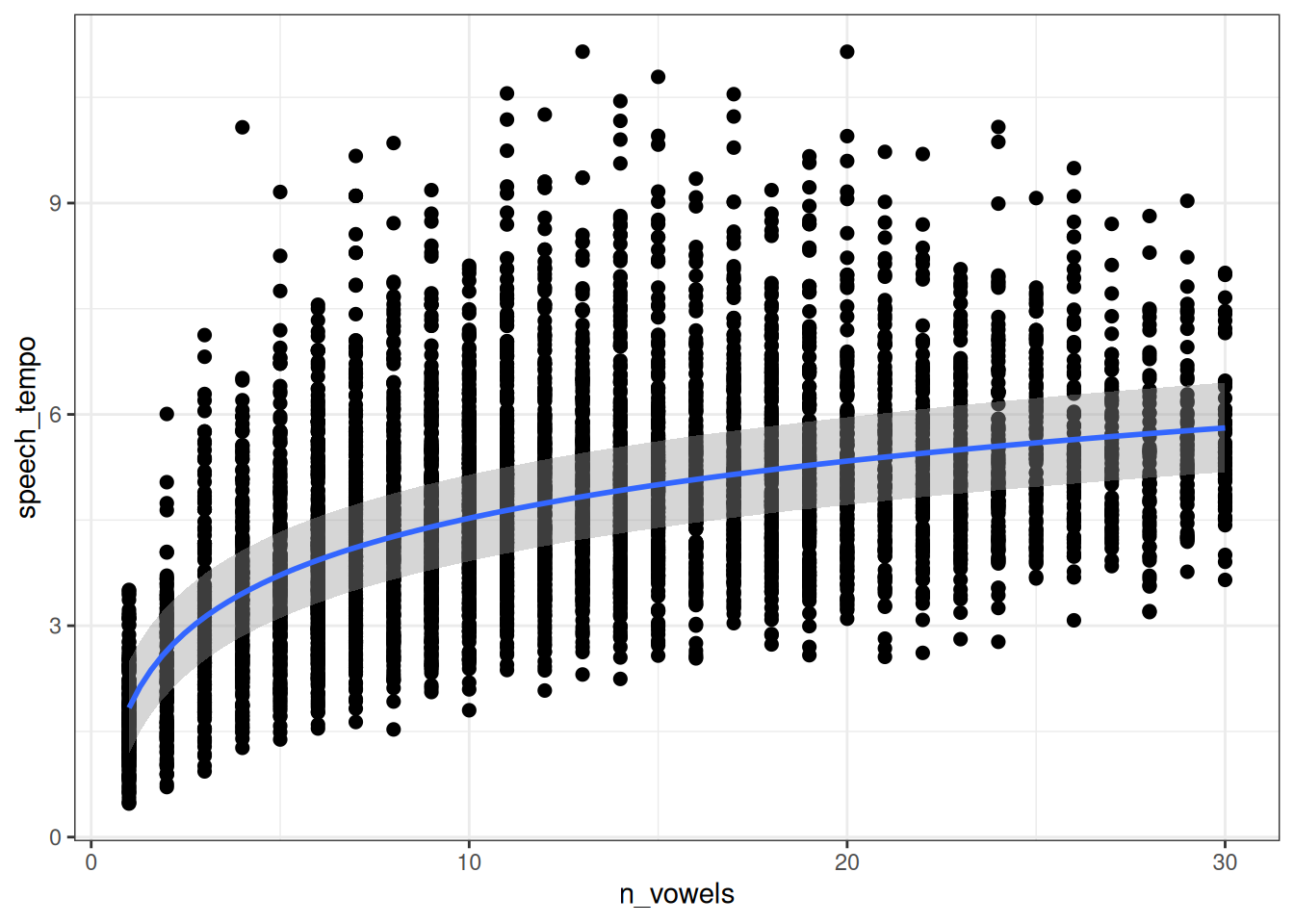
Cлучайные члены для каждого носителя
ranef(fit_hierarchical_intercept_slope)$speaker[,,"Intercept"] |>
as.data.frame() |>
rownames_to_column("speaker") |>
ggplot(aes(y = speaker, x = Estimate)) +
geom_errorbar(aes(xmin = `Q2.5`, xmax = `Q97.5`))+
geom_vline(xintercept = 0, linetype = 2) +
geom_point()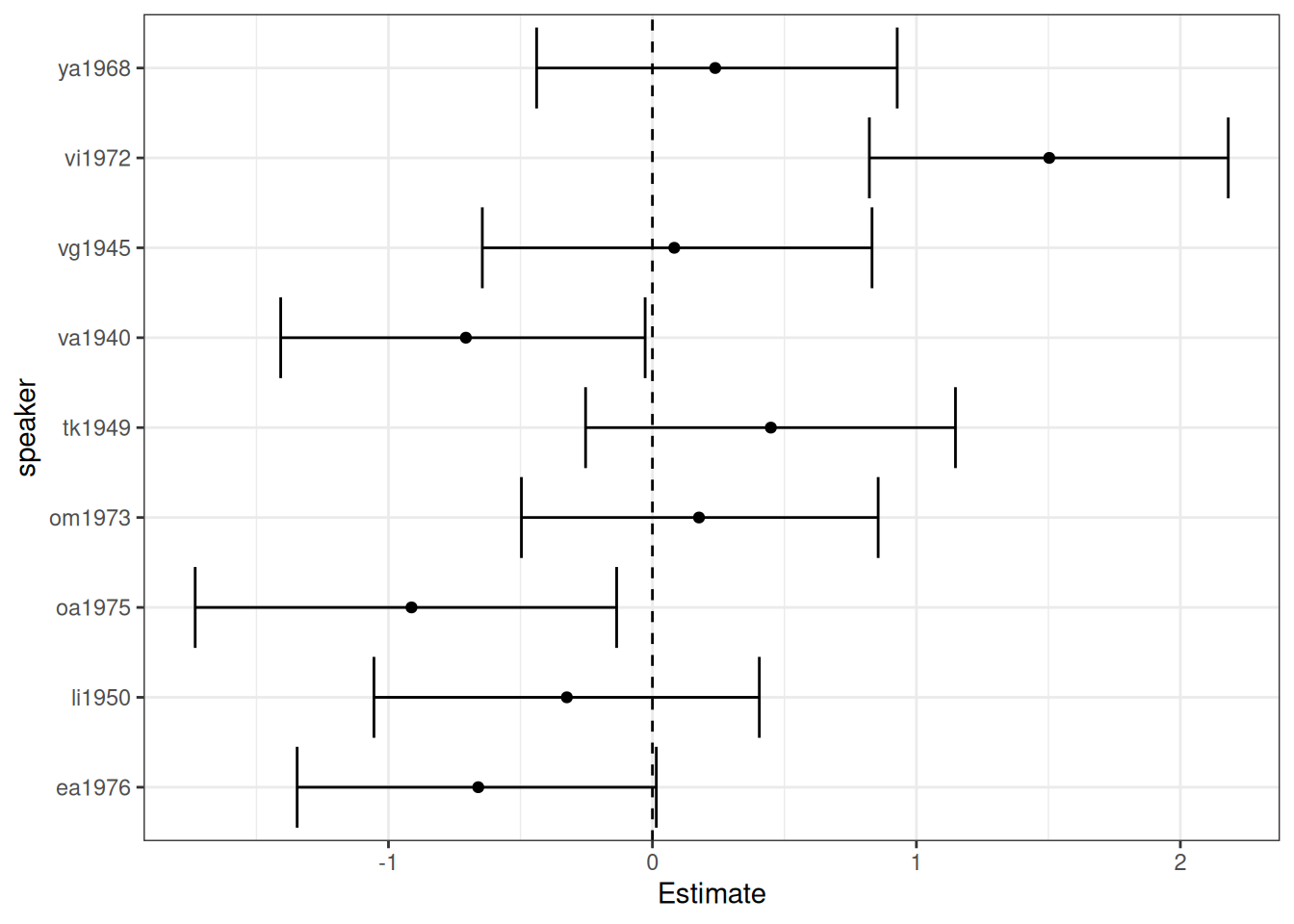
Угловой кэффициент для каждого носителя
ranef(fit_hierarchical_intercept_slope)$speaker[,,"Ilogn_vowels"] |>
as.data.frame() |>
rownames_to_column("speaker") |>
ggplot(aes(y = speaker, x = Estimate)) +
geom_errorbar(aes(xmin = `Q2.5`, xmax = `Q97.5`))+
geom_vline(xintercept = 0, linetype = 2) +
geom_point()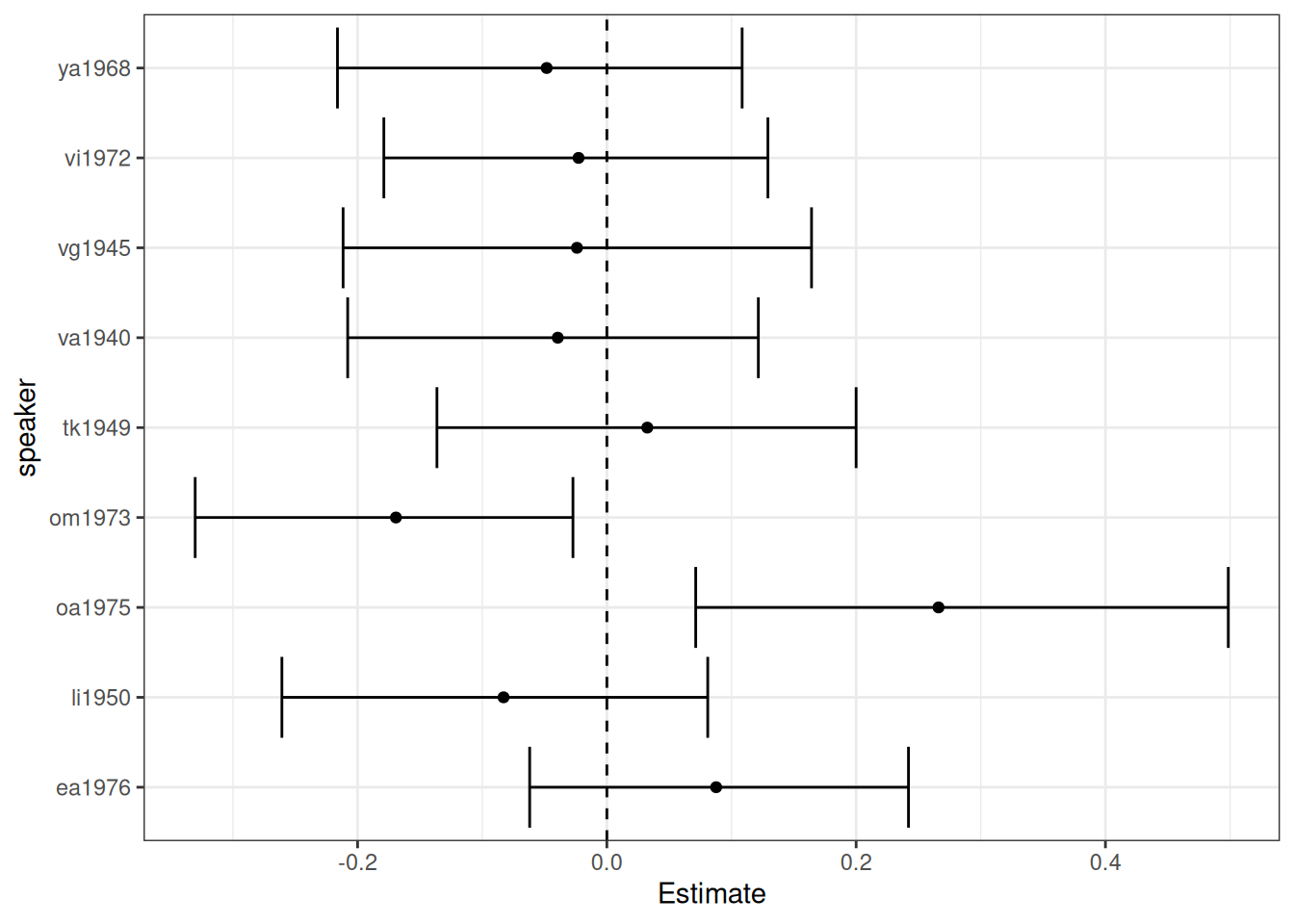
fit_hierarchical_slope <- brm(speech_tempo ~ I(log(n_vowels)) + (I(log(n_vowels)) + 0|speaker),
data = df,
family = gaussian(),
cores = n_cores,
silent = TRUE,
prior = c(prior(normal(5.31, 1.93), class = "Intercept", lb = 0),
prior(normal(2, 5), class = "sigma", lb = 0),
prior(normal(2, 10), class = "sd")),
iter = 4000,
control = list(adapt_delta = .85))Running /usr/lib/R/bin/R CMD SHLIB foo.c
using C compiler: ‘gcc (Ubuntu 13.3.0-6ubuntu2~24.04.1) 13.3.0’
gcc -I"/usr/share/R/include" -DNDEBUG -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/Rcpp/include/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/unsupported" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/BH/include" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/StanHeaders/include/src/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/StanHeaders/include/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppParallel/include/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/rstan/include" -DEIGEN_NO_DEBUG -DBOOST_DISABLE_ASSERTS -DBOOST_PENDING_INTEGER_LOG2_HPP -DSTAN_THREADS -DUSE_STANC3 -DSTRICT_R_HEADERS -DBOOST_PHOENIX_NO_VARIADIC_EXPRESSION -D_HAS_AUTO_PTR_ETC=0 -include '/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/StanHeaders/include/stan/math/prim/fun/Eigen.hpp' -D_REENTRANT -DRCPP_PARALLEL_USE_TBB=1 -fpic -g -O2 -fno-omit-frame-pointer -mno-omit-leaf-frame-pointer -ffile-prefix-map=/build/r-base-FPSnzf/r-base-4.3.3=. -fstack-protector-strong -fstack-clash-protection -Wformat -Werror=format-security -fcf-protection -fdebug-prefix-map=/build/r-base-FPSnzf/r-base-4.3.3=/usr/src/r-base-4.3.3-2build2 -Wdate-time -D_FORTIFY_SOURCE=3 -c foo.c -o foo.o
In file included from /home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/Eigen/Core:19,
from /home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/Eigen/Dense:1,
from /home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/StanHeaders/include/stan/math/prim/fun/Eigen.hpp:22,
from <command-line>:
/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/Eigen/src/Core/util/Macros.h:679:10: fatal error: cmath: No such file or directory
679 | #include <cmath>
| ^~~~~~~
compilation terminated.
make: *** [/usr/lib/R/etc/Makeconf:191: foo.o] Error 1Warning: There were 2 divergent transitions after warmup. See
https://mc-stan.org/misc/warnings.html#divergent-transitions-after-warmup
to find out why this is a problem and how to eliminate them.Warning: Examine the pairs() plot to diagnose sampling problemsfit_hierarchical_slopeWarning: There were 2 divergent transitions after warmup. Increasing
adapt_delta above 0.85 may help. See
http://mc-stan.org/misc/warnings.html#divergent-transitions-after-warmup Family: gaussian
Links: mu = identity
Formula: speech_tempo ~ I(log(n_vowels)) + (I(log(n_vowels)) + 0 | speaker)
Data: df (Number of observations: 5623)
Draws: 4 chains, each with iter = 4000; warmup = 2000; thin = 1;
total post-warmup draws = 8000
Multilevel Hyperparameters:
~speaker (Number of levels: 9)
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
sd(Ilogn_vowels) 0.32 0.10 0.18 0.56 1.00 1240 1899
Regression Coefficients:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
Intercept 1.92 0.05 1.82 2.01 1.00 10017 6132
Ilogn_vowels 1.14 0.11 0.92 1.36 1.00 874 1165
Further Distributional Parameters:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
sigma 1.11 0.01 1.09 1.13 1.00 3238 2849
Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).plot(fit_hierarchical_slope)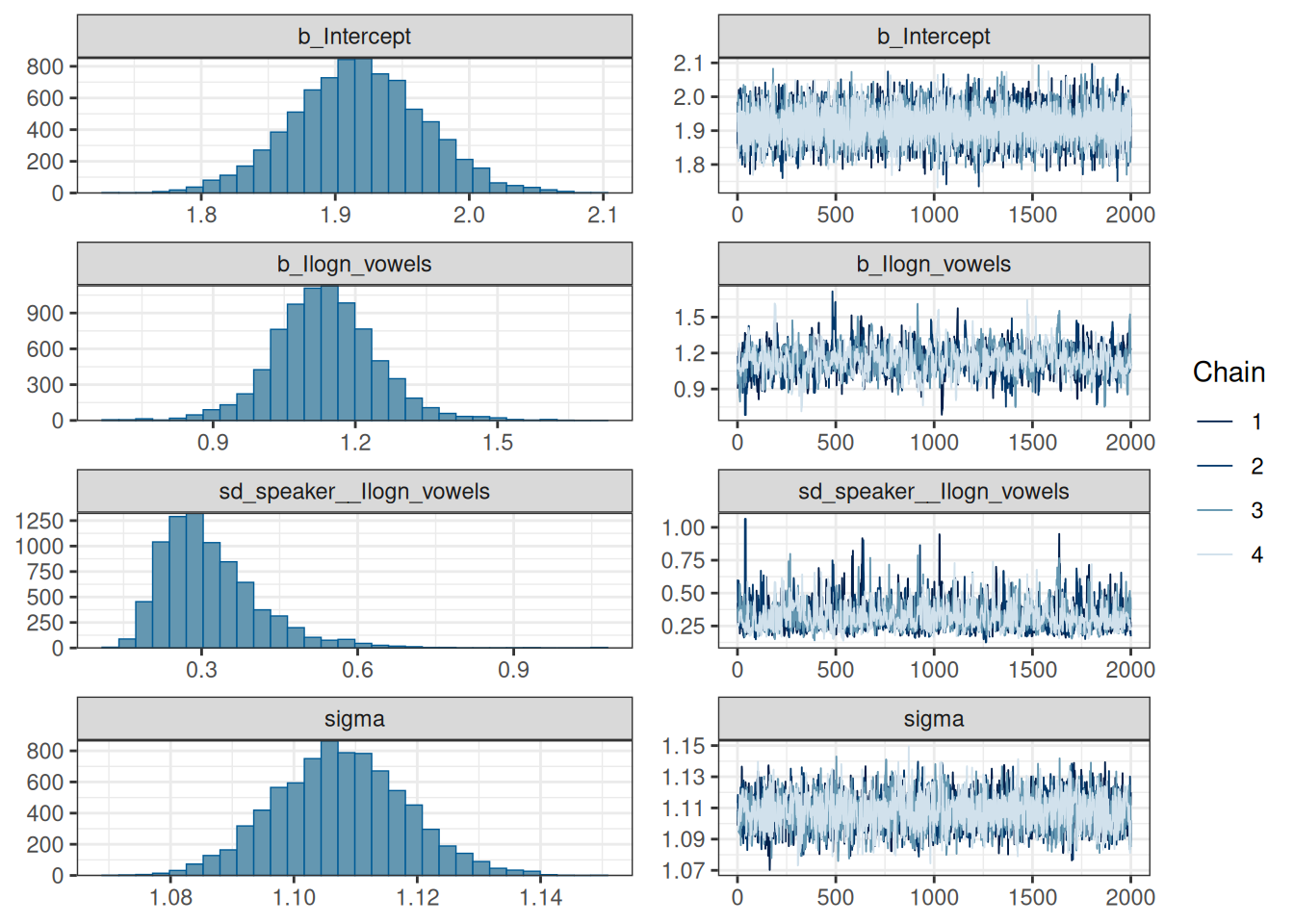
fit_hierarchical_slope |>
conditional_effects() |>
plot(points = TRUE)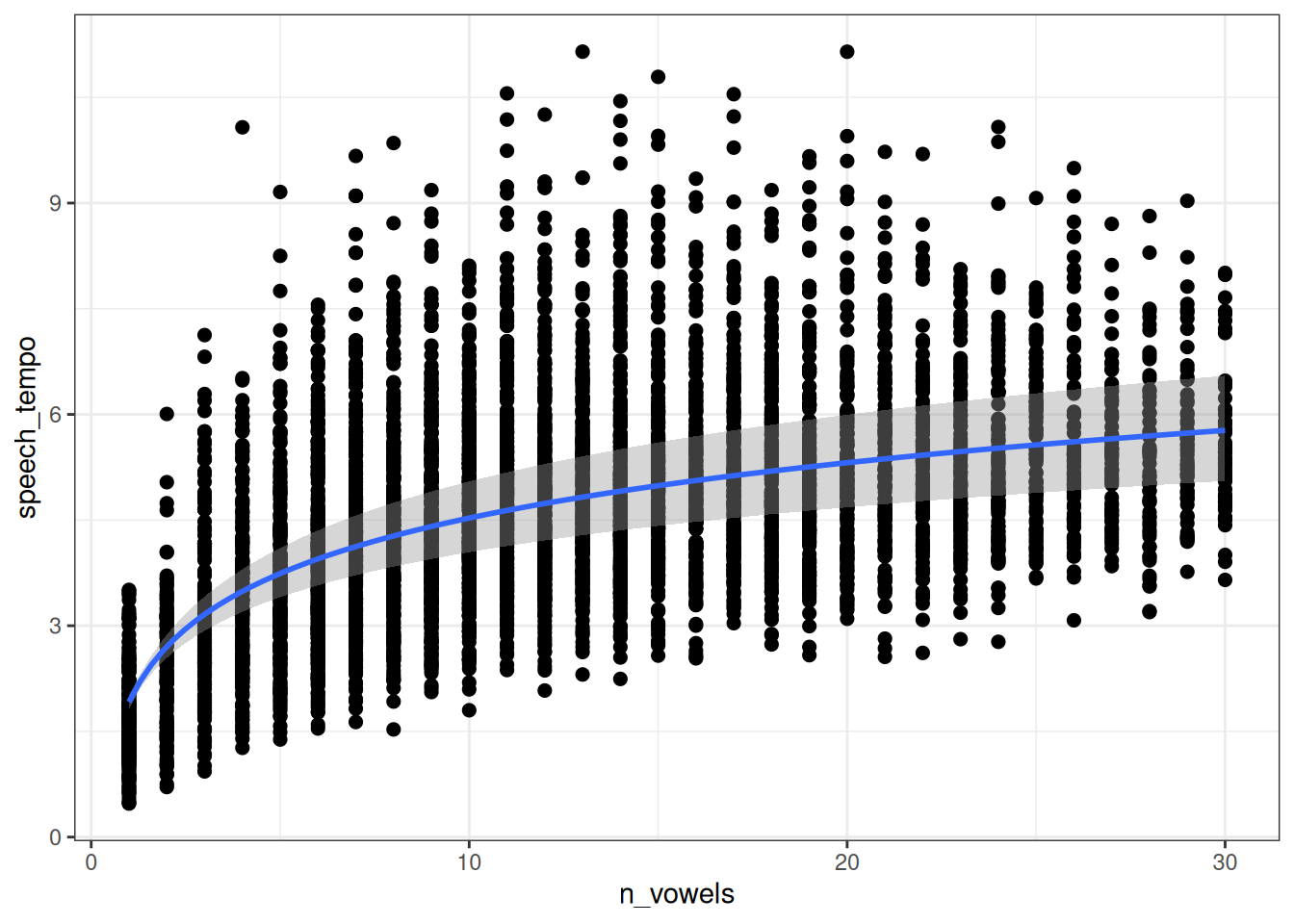
Угловой кэффициент для каждого носителя
ranef(fit_hierarchical_slope)$speaker[,,"Ilogn_vowels"] |>
as.data.frame() |>
rownames_to_column("speaker") |>
ggplot(aes(y = speaker, x = Estimate)) +
geom_errorbar(aes(xmin = `Q2.5`, xmax = `Q97.5`))+
geom_vline(xintercept = 0, linetype = 2) +
geom_point()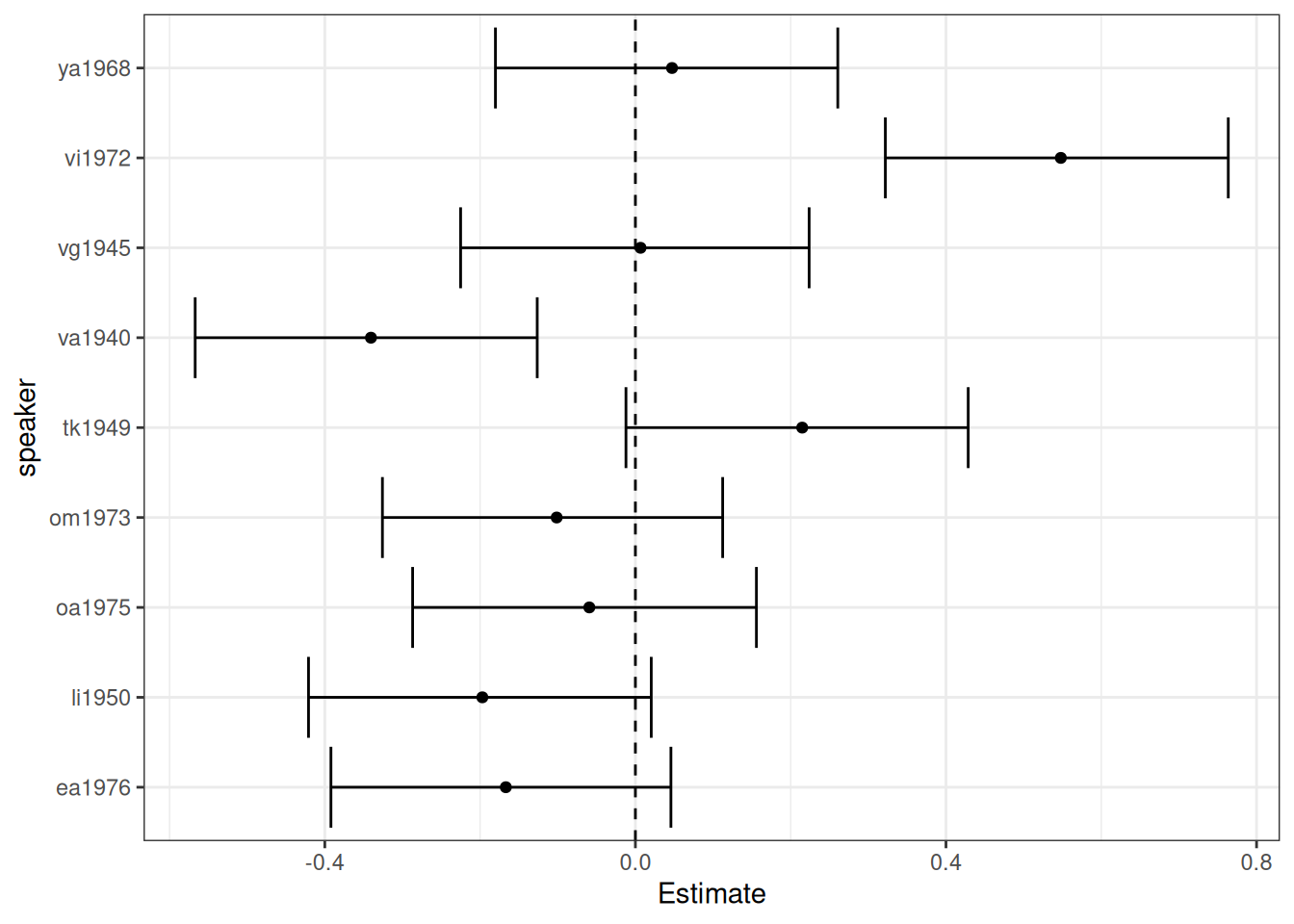
Running /usr/lib/R/bin/R CMD SHLIB foo.c
using C compiler: ‘gcc (Ubuntu 13.3.0-6ubuntu2~24.04.1) 13.3.0’
gcc -I"/usr/share/R/include" -DNDEBUG -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/Rcpp/include/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/unsupported" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/BH/include" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/StanHeaders/include/src/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/StanHeaders/include/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppParallel/include/" -I"/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/rstan/include" -DEIGEN_NO_DEBUG -DBOOST_DISABLE_ASSERTS -DBOOST_PENDING_INTEGER_LOG2_HPP -DSTAN_THREADS -DUSE_STANC3 -DSTRICT_R_HEADERS -DBOOST_PHOENIX_NO_VARIADIC_EXPRESSION -D_HAS_AUTO_PTR_ETC=0 -include '/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/StanHeaders/include/stan/math/prim/fun/Eigen.hpp' -D_REENTRANT -DRCPP_PARALLEL_USE_TBB=1 -fpic -g -O2 -fno-omit-frame-pointer -mno-omit-leaf-frame-pointer -ffile-prefix-map=/build/r-base-FPSnzf/r-base-4.3.3=. -fstack-protector-strong -fstack-clash-protection -Wformat -Werror=format-security -fcf-protection -fdebug-prefix-map=/build/r-base-FPSnzf/r-base-4.3.3=/usr/src/r-base-4.3.3-2build2 -Wdate-time -D_FORTIFY_SOURCE=3 -c foo.c -o foo.o
In file included from /home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/Eigen/Core:19,
from /home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/Eigen/Dense:1,
from /home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/StanHeaders/include/stan/math/prim/fun/Eigen.hpp:22,
from <command-line>:
/home/agricolamz/R/x86_64-pc-linux-gnu-library/4.3/RcppEigen/include/Eigen/src/Core/util/Macros.h:679:10: fatal error: cmath: No such file or directory
679 | #include <cmath>
| ^~~~~~~
compilation terminated.
make: *** [/usr/lib/R/etc/Makeconf:191: foo.o] Error 1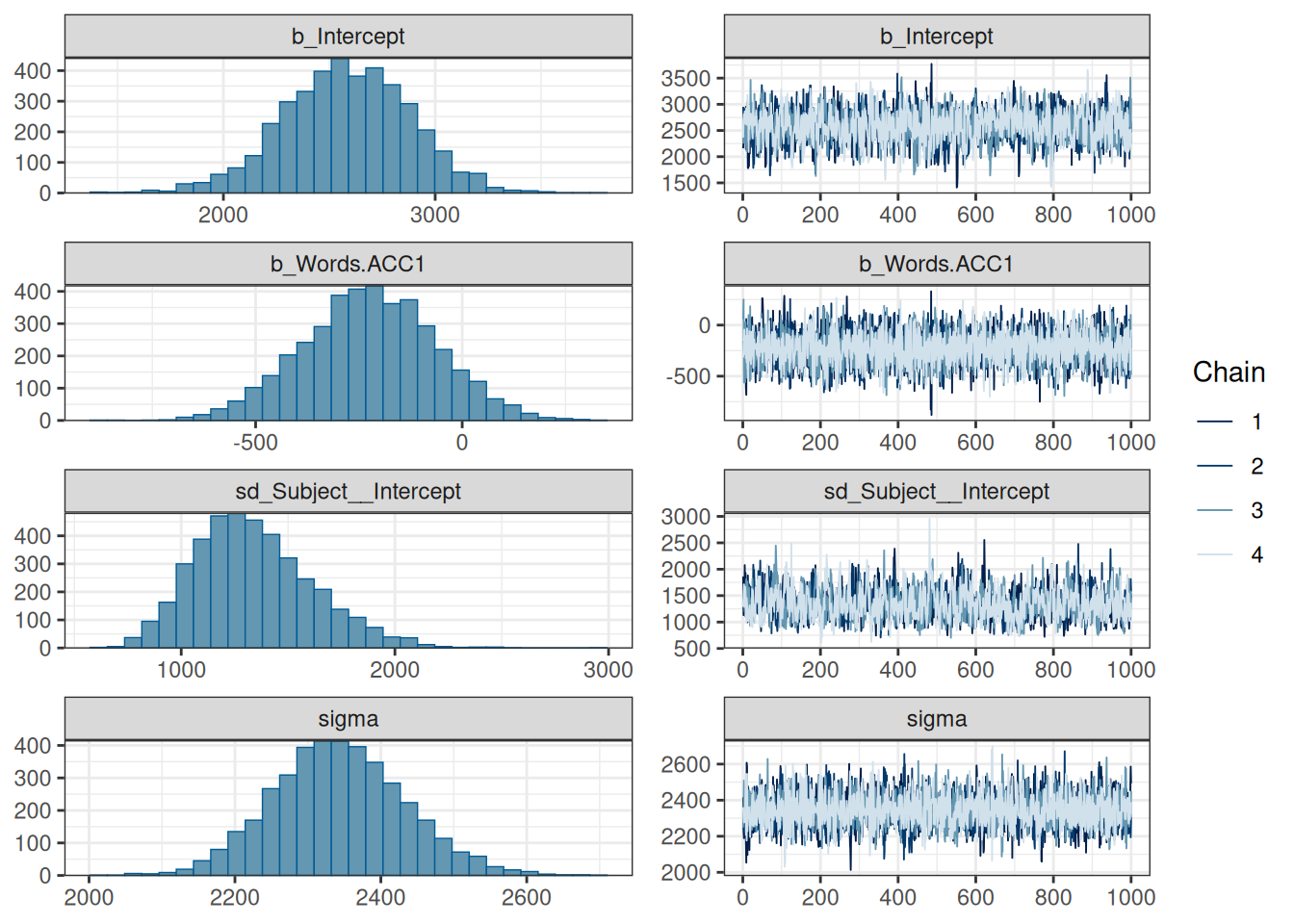
Coretta, Stefano. 2016. “Vowel Duration and Aspiration Effects in Icelandic.” University of York.
Gelman, A., and D. B. Rubin. 1992. “Inference from Iterative Simulation Using Multiple Sequences.” Statistical Science, 457–72.
Ota, Mitsuhiko, Robert J. Hartsuiker, and Sarah L. Haywood. 2009. “The KEY to the ROCK: Near-Homophony in Nonnative Visual Word Recognition.” Cognition 111 (2): 263–69. https://doi.org/https://doi.org/10.1016/j.cognition.2008.12.007.
Stepanova, S. 2011. “Russian Spontaneous Speech Rate-Based on the Speech Corpus of Russian Everyday Interaction.” ICPhS, 1902–5.
Vehtari, Aki, Andrew Gelman, and Jonah Gabry. 2017. “Practical Bayesian Model Evaluation Using Leave-One-Out Cross-Validation and WAIC.” Statistics and Computing 27 (5): 1413–32.
Vehtari, Aki, Daniel Simpson, Andrew Gelman, Yuling Yao, and Jonah Gabry. 2024. “Pareto Smoothed Importance Sampling.” Journal of Machine Learning Research 25 (72): 1–58.