- Работа со строками
Г. Мороз
25 июля 2017, АНДАН
1. Как получить строку?1
- следите за кавычками
"the quick brown fox jumps over the lazy dog"## [1] "the quick brown fox jumps over the lazy dog"'the quick brown fox jumps over the lazy dog'## [1] "the quick brown fox jumps over the lazy dog""the quick 'brown' fox jumps over the lazy dog"## [1] "the quick 'brown' fox jumps over the lazy dog"'the quick "brown" fox jumps over the lazy dog'## [1] "the quick \"brown\" fox jumps over the lazy dog"- пустая строка
""## [1] ""''## [1] ""character(3)## [1] "" "" ""- преобразование
typeof(4:7)## [1] "integer"as.character(4:7)## [1] "4" "5" "6" "7"- встроенные векторы
letters## [1] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l" "m" "n" "o" "p" "q"
## [18] "r" "s" "t" "u" "v" "w" "x" "y" "z"LETTERS## [1] "A" "B" "C" "D" "E" "F" "G" "H" "I" "J" "K" "L" "M" "N" "O" "P" "Q"
## [18] "R" "S" "T" "U" "V" "W" "X" "Y" "Z"month.name## [1] "January" "February" "March" "April" "May"
## [6] "June" "July" "August" "September" "October"
## [11] "November" "December"- пользовательские данные
str(data.frame(letters[6:10], LETTERS[4:8]))## 'data.frame': 5 obs. of 2 variables:
## $ letters.6.10.: Factor w/ 5 levels "f","g","h","i",..: 1 2 3 4 5
## $ LETTERS.4.8. : Factor w/ 5 levels "D","E","F","G",..: 1 2 3 4 5str(data.frame(letters[6:10], LETTERS[4:8], stringsAsFactors = FALSE))## 'data.frame': 5 obs. of 2 variables:
## $ letters.6.10.: chr "f" "g" "h" "i" ...
## $ LETTERS.4.8. : chr "D" "E" "F" "G" ...stringi
set.seed(42)
stringi::stri_rand_strings(n = 10, length = 5:14)## [1] "uwHpd" "Wj8ehS" "ivFSwy7" "TYu8zw5V"
## [5] "OuRpjoOg0" "p0CubNR2yQ" "xtdycKLOm2k" "fAGVfylZqBGp"
## [9] "gE28DTCi0NV0a" "9MemYE55If0Cvv"stringi::stri_rand_shuffle("любя, съешь щипцы, — вздохнёт мэр, — кайф жгуч")## [1] "вцд тэшс,г яло, х ми—паюызф ркнжьеу б—ъйёщ, ч"stringi::stri_rand_shuffle(month.name[1:8]) # на больших векторах глючит## [1] "Jaurnay" "byFarrue" "chMar" "iAlrp" "rMy" "pJue"
## [7] "rJuy" "uAugut"stringi::stri_rand_lipsum(nparagraphs = 2)## [1] "Lorem ipsum dolor sit amet, pellentesque sit in vitae ligula nec pellentesque sed hac curabitur. Ut semper lectus justo ut suspendisse ut, at faucibus dolor nec non. Neque senectus donec sit nunc urna sed. Ultricies ac pharetra orci luctus iaculis ac tincidunt cum neque. Eu semper at sociosqu hendrerit eu aliquet lacus eu, hendrerit, donec aliquam. Eros risus, nibh quam in. Sit facilisi ipsum amet sem. Sed donec sed molestie scelerisque. Tincidunt nisl donec et. Facilisis interdum non sed dolor purus in ipsum."
## [2] "Dignissim torquent velit nec aliquam pellentesque, ac adipiscing neque et. At torquent vestibulum ullamcorper ad dictumst enim velit non, nulla felis habitant. Egestas placerat consectetur, dictum nostra sed nec erat phasellus dolor libero. Aliquam viverra vestibulum leo et. Suscipit, egestas in in montes sapien gravida conubia purus varius, ut nec feugiat risus. Eleifend magnis, neque diam suspendisse ullamcorper. Nulla adipiscing malesuada massa nisi sociosqu velit id. Et aliquam facilisis et, aenean parturient vel. Ac in convallis massa diam nibh, nulla interdum. Cursus et natoque, amet, ut praesent tortor ultrices a. Consectetur, augue natoque class faucibus ut sed arcu. Elementum magna dignissim ac facilisi quis ut nisl. Eu massa vitae consectetur non non quis, mollis. Justo in ac dolor adipiscing mattis tempus."2. Операции со строками
- изменение регистра
- подсчет количества символов в строке
- сортировка строк
- соединение строк
- поиск вектора по подстроке
- разделение вектора по подстроке
- выделение подстроки по номеру
stringr, stringi…
2.1 Изменение регистра
latin <- "tHe QuIcK BrOwN fOx JuMpS OvEr ThE lAzY dOg"
tolower(latin)## [1] "the quick brown fox jumps over the lazy dog"toupper(latin)## [1] "THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG"cyrillic <- "лЮбЯ, сЪеШь ЩиПцЫ, — вЗдОхНёТ мЭр, — кАйФ жГуЧ"
tolower(cyrillic)## [1] "любя, съешь щипцы, — вздохнёт мэр, — кайф жгуч"toupper(cyrillic)## [1] "ЛЮБЯ, СЪЕШЬ ЩИПЦЫ, — ВЗДОХНЁТ МЭР, — КАЙФ ЖГУЧ"stringr::str_to_upper(latin)## [1] "THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG"stringr::str_to_lower(cyrillic)## [1] "любя, съешь щипцы, — вздохнёт мэр, — кайф жгуч"stringr::str_to_title(latin)## [1] "The Quick Brown Fox Jumps Over The Lazy Dog"2.2 Подсчет количества символов
nchar(latin)## [1] 43nchar(month.name)## [1] 7 8 5 5 3 4 4 6 9 7 8 8nchar(c(NULL, NA, ""))## [1] NA 0stringr::str_length(latin)## [1] 43stringr::str_length(month.name)## [1] 7 8 5 5 3 4 4 6 9 7 8 8stringr::str_length(c(NULL, NA, ""))## [1] NA 02.3 Сортировка
unsorted_latin <- c("I", "♥", "N", "Y")
sort(unsorted_latin)## [1] "♥" "I" "N" "Y"stringr::str_sort(unsorted_latin)## [1] "♥" "I" "N" "Y"stringr::str_sort(unsorted_latin, locale = "lt")## [1] "♥" "I" "Y" "N"unsorted_cyrillic <- c("я", "i", "ж")
stringr::str_sort(unsorted_cyrillic)## [1] "i" "ж" "я"stringr::str_sort(unsorted_cyrillic, locale = "ru_UA")## [1] "ж" "я" "i"sort(c(NULL, NA, ""))## [1] ""stringr::str_sort(c(NULL, NA, ""))## [1] "" NAСписок локалей можно посмотреть командой stringi::stri_locale_list(). Еще полезные команды: stringi::stri_locale_info и stringi::stri_locale_set.
Не углубляясь в разнообразие алгоритмов сортировки, отмечу, что алгоритм по-умолчанию хуже работает с большими данными:
set.seed(42)
huge <- sample(letters, 1e7, replace = TRUE)
head(huge)## [1] "x" "y" "h" "v" "q" "n"system.time(
sort(huge)
)## user system elapsed
## 5.349 0.017 5.367system.time(
sort(huge, method = "radix")
)## user system elapsed
## 0.507 0.033 0.541system.time(
stringr::str_sort(huge)
)## user system elapsed
## 10.016 0.034 10.059huge_df <- data.frame(huge)
system.time(
dplyr::arrange(.data = huge_df, huge)
)## user system elapsed
## 5.652 0.010 5.665huge_tbl <- tibble::data_frame(huge)
system.time(
dplyr::arrange(.data = huge_tbl, huge)
)## user system elapsed
## 5.821 0.043 5.871Предварительный вывод: для больших данных – sort(..., method = "radix").
2.4 Соединение
- одинаковое количество строк
greek_abc <- c("Α", "Β", "Γ", "Δ")
latin_abc <- c("A", "B", "C", "D")
paste(greek_abc, latin_abc)## [1] "Α A" "Β B" "Γ C" "Δ D"paste0(greek_abc, latin_abc)## [1] "ΑA" "ΒB" "ΓC" "ΔD"paste(greek_abc, latin_abc, sep = "-")## [1] "Α-A" "Β-B" "Γ-C" "Δ-D"paste(greek_abc, "Ы") # если векторы разной длины## [1] "Α Ы" "Β Ы" "Γ Ы" "Δ Ы"- … → одна строка
paste(greek_abc, collapse = "_")## [1] "Α_Β_Γ_Δ"paste(greek_abc, latin_abc, collapse = "_")## [1] "Α A_Β B_Γ C_Δ D"paste(greek_abc, latin_abc, sep = "-", collapse = "_")## [1] "Α-A_Β-B_Γ-C_Δ-D"stringr
stringr::str_c(greek_abc, latin_abc)## [1] "ΑA" "ΒB" "ΓC" "ΔD"stringr::str_c(greek_abc, latin_abc, sep = " ")## [1] "Α A" "Β B" "Γ C" "Δ D"stringr::str_c(greek_abc, latin_abc, sep = "-")## [1] "Α-A" "Β-B" "Γ-C" "Δ-D"stringr::str_c(greek_abc, collapse = "_")## [1] "Α_Β_Γ_Δ"stringr::str_c(greek_abc, latin_abc, collapse = "_")## [1] "ΑA_ΒB_ΓC_ΔD"stringr::str_c(greek_abc, latin_abc, sep = "-", collapse = "_")## [1] "Α-A_Β-B_Γ-C_Δ-D"- К сожалению, аргументы
sepиcollapseне векторизованы, так что если хочется использовать разные разделители, нужно использовать аргументseparators:
stringr::str_c(greek_abc, separaters = c("-", "_"))## [1] "Α-" "Β_" "Γ-" "Δ_"stringr::str_c(greek_abc, separaters = c("-", "_"), collapse = "")## [1] "Α-Β_Γ-Δ_"stringr::str_c(greek_abc, latin_abc, separaters = c("-", "_"))## [1] "ΑA-" "ΒB_" "ΓC-" "ΔD_"stringr::str_c(greek_abc, latin_abc, separaters = c("-", "_"), sep = "^")## [1] "Α^A^-" "Β^B^_" "Γ^C^-" "Δ^D^_"stringr::str_c(greek_abc, latin_abc, separaters = c("-", "_"), collapse = "")## [1] "ΑA-ΒB_ΓC-ΔD_"stringr::str_c(greek_abc, latin_abc, sep = "^", separaters = c("-", "_"), collapse = "")## [1] "Α^A^-Β^B^_Γ^C^-Δ^D^_"- глюки
paste(c(NULL, NA, ""))## [1] "NA" ""stringr::str_c(c(NULL, NA, ""))## [1] NA ""2.5 Поиск строки по подстроке
a <- c("the quick", "brown fox", "jumps", "over the lazy dog")
grep("the", a)## [1] 1 4grep("the", a, value = TRUE)## [1] "the quick" "over the lazy dog"grep("the", a, invert = TRUE)## [1] 2 3grep("the", a, invert = TRUE, value = TRUE)## [1] "brown fox" "jumps"grepl("the", a)## [1] TRUE FALSE FALSE TRUEregexpr("o", a)## [1] -1 3 -1 1
## attr(,"match.length")
## [1] -1 1 -1 1
## attr(,"useBytes")
## [1] TRUEgregexpr("o", a)## [[1]]
## [1] -1
## attr(,"match.length")
## [1] -1
## attr(,"useBytes")
## [1] TRUE
##
## [[2]]
## [1] 3 8
## attr(,"match.length")
## [1] 1 1
## attr(,"useBytes")
## [1] TRUE
##
## [[3]]
## [1] -1
## attr(,"match.length")
## [1] -1
## attr(,"useBytes")
## [1] TRUE
##
## [[4]]
## [1] 1 16
## attr(,"match.length")
## [1] 1 1
## attr(,"useBytes")
## [1] TRUEregmatches("Мама увидела маму", regexec("[Мм]ам", "Мама увидела маму"))## [[1]]
## [1] "Мам"stringr::str_which(a, "the")## [1] 1 4stringr::str_subset(a, "the")## [1] "the quick" "over the lazy dog"stringr::str_detect(a, "the")## [1] TRUE FALSE FALSE TRUEstringr::str_view(a, "o")stringr::str_view_all(a, "o")stringr::str_locate(a, "o")## start end
## [1,] NA NA
## [2,] 3 3
## [3,] NA NA
## [4,] 1 12.6 Замена подстроки в строке
b <- c("the quick brown fox", "jumps over the lazy dog")
sub("o", "_", b)## [1] "the quick br_wn fox" "jumps _ver the lazy dog"gsub("o", "_", b)## [1] "the quick br_wn f_x" "jumps _ver the lazy d_g"stringr::str_replace(b, "o", "_")## [1] "the quick br_wn fox" "jumps _ver the lazy dog"stringr::str_replace_all(b, "o", "_")## [1] "the quick br_wn f_x" "jumps _ver the lazy d_g"2.7 Разделение вектора по подстроке
b## [1] "the quick brown fox" "jumps over the lazy dog"strsplit(b, " ")## [[1]]
## [1] "the" "quick" "brown" "fox"
##
## [[2]]
## [1] "jumps" "over" "the" "lazy" "dog"stringr::str_split(b, " ")## [[1]]
## [1] "the" "quick" "brown" "fox"
##
## [[2]]
## [1] "jumps" "over" "the" "lazy" "dog"stringr::str_split(b, " ", simplify = TRUE)## [,1] [,2] [,3] [,4] [,5]
## [1,] "the" "quick" "brown" "fox" ""
## [2,] "jumps" "over" "the" "lazy" "dog"2.8 Выделение подстроки по номеру
b## [1] "the quick brown fox" "jumps over the lazy dog"substring(b, 11, 15)## [1] "brown" " the "# с 5 по 9 и с 16 по 19
substring(b, c(5, 16), c(9, 19))## [1] "quick" "lazy"substring("а роза упала на лапу Азора", 1:26, 1:26)## [1] "а" " " "р" "о" "з" "а" " " "у" "п" "а" "л" "а" " " "н" "а" " " "л"
## [18] "а" "п" "у" " " "А" "з" "о" "р" "а"substring("мат и тут и там", 1:15, 15:1)## [1] "мат и тут и там" "ат и тут и та" "т и тут и т"
## [4] " и тут и " "и тут и" " тут "
## [7] "тут" "у" ""
## [10] "" "" ""
## [13] "" "" ""stringr::str_sub(b, 11, 15)## [1] "brown" " the "stringr::str_sub(b, c(5, 16), c(9, 19))## [1] "quick" "lazy"stringr::str_sub("а роза упала на лапу Азора", 1:26, 1:26)## [1] "а" " " "р" "о" "з" "а" " " "у" "п" "а" "л" "а" " " "н" "а" " " "л"
## [18] "а" "п" "у" " " "А" "з" "о" "р" "а"stringr::str_sub("мат и тут и там", 1:15, 15:1)## [1] "мат и тут и там" "ат и тут и та" "т и тут и т"
## [4] " и тут и " "и тут и" " тут "
## [7] "тут" "у" ""
## [10] "" "" ""
## [13] "" "" ""stringr::str_sub(b, -3, -1) # обратите внимание: нестандартное использование "-"## [1] "fox" "dog"2.9 Транслитерация строк
В пакете stringi сууществует достаточно много методов транслитераций строк, которые можно вывести командой stri_trans_list(). Вот пример использования некоторых из них:
stringi::stri_trans_general("stringi", "latin-cyrillic")## [1] "стринги"stringi::stri_trans_general("сырники", "cyrillic-latin")## [1] "syrniki"stringi::stri_trans_general("stringi", "latin-greek")## [1] "στριγγι"stringi::stri_trans_general("stringi", "latin-armenian")## [1] "ստրինգի"2.10 Подгонка количества символов
Для удобства представления, иногда удобно обрезать строки до фиксированного количества символов в строке:
s <- "Это слишком длинная строка"
stringr::str_trunc(s, 20, "right")## [1] "Это слишком длинн..."stringr::str_trunc(s, 20, "left")## [1] "...ом длинная строка"stringr::str_trunc(s, 20, "center")## [1] "Это слишк...я строка"Или наоборот подогнать к какому-то фиксированному количеству символов:
w <- "коротковато"
stringr::str_pad(w, 20, "right")## [1] "коротковато "stringr::str_pad(w, 20, "left")## [1] " коротковато"stringr::str_pad(w, 20, "both")## [1] " коротковато "3. Операции над векторами
Векторы не мноежества, но операции на них действуют те же:
- Объединение
- Пересечение
- Разность
- Сравнение
- Подмножество?
3.1 Объединение
a; b## [1] "the quick" "brown fox" "jumps"
## [4] "over the lazy dog"## [1] "the quick brown fox" "jumps over the lazy dog"c(a, b)## [1] "the quick" "brown fox"
## [3] "jumps" "over the lazy dog"
## [5] "the quick brown fox" "jumps over the lazy dog"unique(c(a, b))## [1] "the quick" "brown fox"
## [3] "jumps" "over the lazy dog"
## [5] "the quick brown fox" "jumps over the lazy dog"union(a, b)## [1] "the quick" "brown fox"
## [3] "jumps" "over the lazy dog"
## [5] "the quick brown fox" "jumps over the lazy dog"3.2 Пересечение
a; b## [1] "the quick" "brown fox" "jumps"
## [4] "over the lazy dog"## [1] "the quick brown fox" "jumps over the lazy dog"intersect(a, b)## character(0)3.3 Разность
a; b## [1] "the quick" "brown fox" "jumps"
## [4] "over the lazy dog"## [1] "the quick brown fox" "jumps over the lazy dog"setdiff(a, b)## [1] "the quick" "brown fox" "jumps"
## [4] "over the lazy dog"3.4 Сравнение
c <- c("brown", "fox", "jumps", "over", "the quick")
a; c## [1] "the quick" "brown fox" "jumps"
## [4] "over the lazy dog"## [1] "brown" "fox" "jumps" "over" "the quick"setequal(c, a)## [1] FALSEidentical(c, a)## [1] FALSE3.5 Подмножество?
a## [1] "the quick" "brown fox" "jumps"
## [4] "over the lazy dog"is.element("over", a)## [1] FALSEis.element("the dog", a)## [1] FALSEis.element(c("over", "the dog"), a)## [1] FALSE FALSEc("over", "the dog") %in% a## [1] FALSE FALSE4. Задачи
4.1 Чет-нечет
Напишите функцию is.odd(), которая возвращает значение TRUE, если число символов в строке нечетно, FALSE, если число символов в строке четно.
is.odd(c("odd", "even", ""))## [1] TRUE FALSE FALSE4.2 Искусственные данные по средней продолжительности сна
В данных по продолжительности сна (1.1_sleep_hours.csv)2 две переменных: код испытуемого и среднее время сна. Попробуйте сделать следующий график:
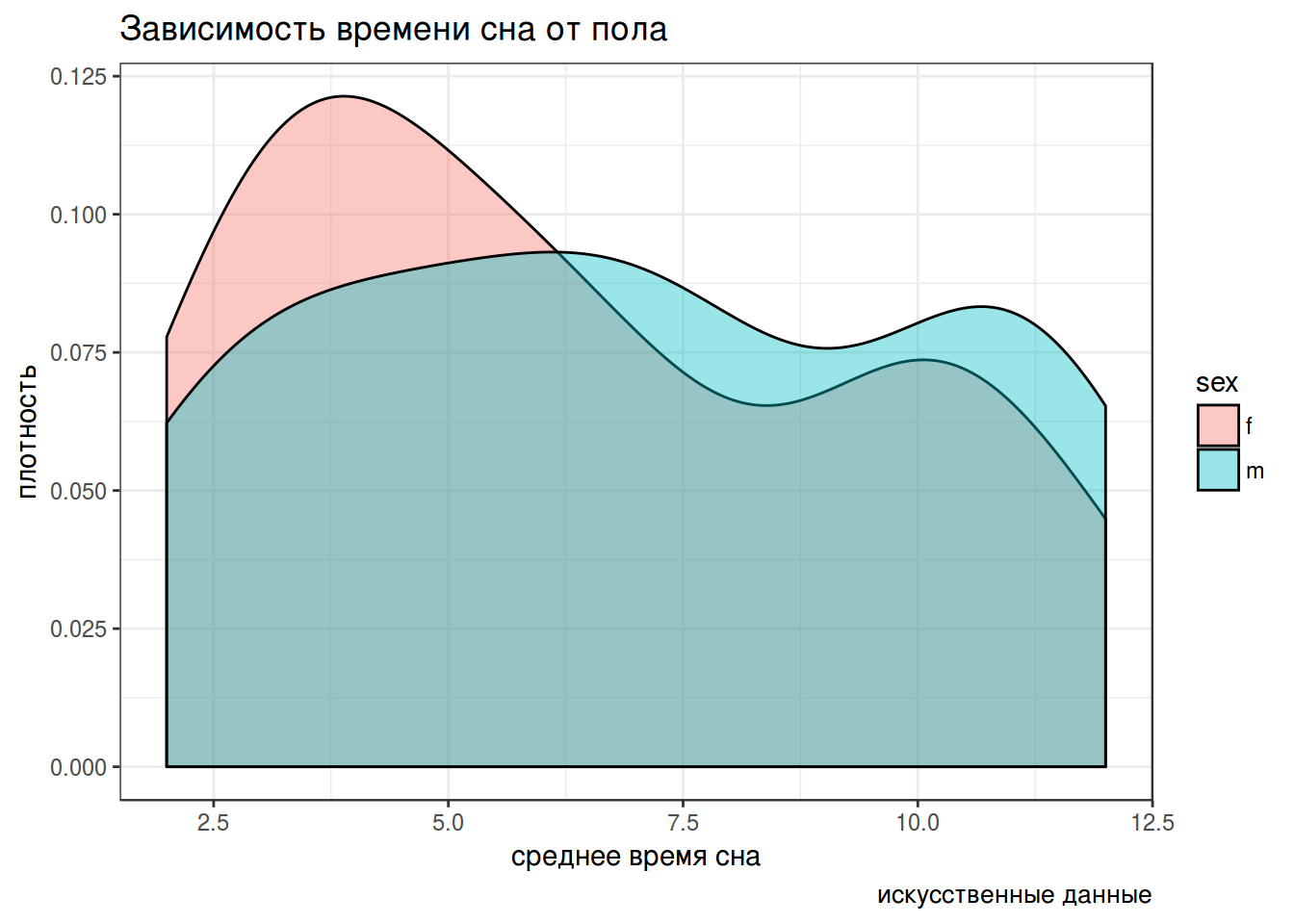
4.3 Алфавитный порядок
Как было сказано выше, “алфавитный” порядок разный в разных локалях. Напишите функцию ordering_in_locales, которая на вход принимает два символа, а возвращает таблицу с информацией о том, в скольких локалях порядок соответствует поданному в функцию, а в скольких порядок обратный:
ordering_in_locales("i", "и")##
## i_и и_i
## 425 2174.4 Функция для проверки полиндромности
Напишите функцию is.palindrome, которая будет проверять, является ли слово полиндромом.
is.palindrome("топот")## [1] TRUEis.palindrome("топор")## [1] FALSE4.5 Функция для зеркального отражения размера букв
Напишите функцию mirror_case(), которая в строке все большие буквы заменяет на маленькие, а все маленькие – на большие.
mirror_case("ЖиЛи БыЛи ТрИ мЕдВеДя")## [1] "жИлИ бЫлИ тРи МеДвЕдЯ"Данная картинка – рисунок Бориса Аркадьевича Диодорова из книжки Яна Экхольма “Тутта Карлссон, первая и единственная, Людвиг Четырнадцатый и другие”↩
Если у Вас не получается считать файл, попробуйте добавлять разные аргументы к
read.csv:encoding="UTF-8"илиfileEncoding = "UTF-8"… Я надеюсь, поможет…↩