- Определение языка. Расстояния. Регулярки
Г. Мороз
25 июля 2017, АНДАН
“Что общего между вороном и письменным столом?”(Л. Кэрролл)
1. Определение языка1
Для определения языка существует два пакета cld2 (вероятностный) и cld3 (нейросеть).
udhr_24 <- read.csv("https://goo.gl/cHviY5", stringsAsFactors = FALSE, sep = "\t")
udhr_24cld2::detect_language(udhr_24$article_text)## [1] "ru" "en" "fr" "es" "ar" "zh"cld2::detect_language(udhr_24$article_text, lang_code = FALSE)## [1] "RUSSIAN" "ENGLISH" "FRENCH" "SPANISH" "ARABIC" "CHINESE"cld3::detect_language(udhr_24$article_text)## [1] "ru" "en" "fr" "es" "ar" "zh"cld2::detect_language("Ты женат? Говорите ли по-английски?")## [1] "bg"cld3::detect_language("Ты женат? Говорите ли по-английски?")## [1] NAcld2::detect_language("Варкалось. Хливкие шорьки пырялись по наве, и хрюкотали зелюки, как мюмзики в мове.")## [1] "ru"cld3::detect_language("Варкалось. Хливкие шорьки пырялись по наве, и хрюкотали зелюки, как мюмзики в мове.")## [1] "ru"cld2::detect_language("Варчилось… Хлив'язкі тхурки викрули, свербчись навкрузі, жасумновілі худоки гривіли зехряки в чузі.")## [1] "uk"cld3::detect_language("Варчилось… Хлив'язкі тхурки викрули, свербчись навкрузі, жасумновілі худоки гривіли зехряки в чузі.")## [1] "uk"cld2::detect_language_mixed("Многие в нашей команде OpenDataScience занимаются state-of-the-art технологиями машинного обучения: DL-фреймворками, байесовскими методами машинного обучения, вероятностным программированием и не только.")## $classificaton
## language code latin proportion
## 1 RUSSIAN ru FALSE 0.87
## 2 ENGLISH en TRUE 0.11
## 3 UNKNOWN un TRUE 0.00
##
## $bytes
## [1] 353
##
## $reliabale
## [1] TRUEcld3::detect_language_mixed("Многие в нашей команде OpenDataScience занимаются state-of-the-art технологиями машинного обучения: DL-фреймворками, байесовскими методами машинного обучения, вероятностным программированием и не только.")2. Расстояния между строками
Существует много разных метрик для измерения расстояния между строками (см. ?`stringdist-metrics`), в примерах используется расстояние Дамерау — Левенштейна. Данное расстояние получается при подсчете количества операций, которые нужно сделать, чтобы перевести одну строку в другую.
- вставка ab → aNb
- удаление aOb → ab
- замена символа aOb → aNb
- перестановка символов ab → ba
stringdist::stringdist("корова","корова")## [1] 0stringdist::stringdist("коровы", c("курица", "бык", "утка", "корова", "осел"))## [1] 4 6 6 1 5stringdist::stringdistmatrix(c("быки", "коровы"), c("курица", "бык", "утка", "корова", "осел"))## [,1] [,2] [,3] [,4] [,5]
## [1,] 5 1 3 6 4
## [2,] 4 6 6 1 5stringdist::stringsim("коровы", c("курица", "бык", "утка", "корова", "осел"))## [1] 0.3333333 0.0000000 0.0000000 0.8333333 0.1666667stringdist::amatch(c("быки", "коровы"), c("курица", "бык", "утка", "корова", "осел"), maxDist = 2)## [1] 2 4stringdist::ain(c("осы", "коровы"), c("курица", "бык", "утка", "корова", "осел"), maxDist = 2)## [1] FALSE TRUE3. Регулярные выражения
Большинство функций из раздела об операциях над векторами имеют следующую структуру:
- строка с которой работает функция
- образец (pattern)
3.1 Экранирование метасимволов
a <- "Всем известно, что 4$\\2 + 3$ * 5 = 17$? Да? Ну хорошо (а то я не был уверен). [|}^{|]"
stringr::str_view_all(a, "$")stringr::str_view_all(a, "\\$")stringr::str_view_all(a, "\\.")stringr::str_view_all(a, "\\*")stringr::str_view_all(a, "\\+")stringr::str_view_all(a, "\\?")stringr::str_view_all(a, "\\(")stringr::str_view_all(a, "\\)")stringr::str_view_all(a, "\\|")stringr::str_view_all(a, "\\^")stringr::str_view_all(a, "\\[")stringr::str_view_all(a, "\\]")stringr::str_view_all(a, "\\{")stringr::str_view_all(a, "\\}")stringr::str_view_all(a, "\\\\")3.2 Классы знаков
\\d– цифры.\\D– не цифры.
stringr::str_view_all("два 15 42. 42 15. 37 08 5. 20 20 20!", "\\d")stringr::str_view_all("два 15 42. 42 15. 37 08 5. 20 20 20!", "\\D")\\s– пробелы.\\S– не пробелы.
stringr::str_view_all("два 15 42. 42 15. 37 08 5. 20 20 20!", "\\s")stringr::str_view_all("два 15 42. 42 15. 37 08 5. 20 20 20!", "\\S")\\w– не пробелы и не знаки препинания.\\W– пробелы и знаки препинания.
stringr::str_view_all("два 15 42. 42 15. 37 08 5. 20 20 20!", "\\w")stringr::str_view_all("два 15 42. 42 15. 37 08 5. 20 20 20!", "\\W")- произвольная группа символов и обратная к ней
stringr::str_view_all("Умей мечтать, не став рабом мечтанья", "[оауиыэёеяю]")stringr::str_view_all("И мыслить, мысли не обожествив", "[^оауиыэёеяю]")- встроенные группы символов
stringr::str_view_all("два 15 42. 42 15. 37 08 5. 20 20 20!", "[0-9]")stringr::str_view_all("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "[а-я]")stringr::str_view_all("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "[А-Я]")stringr::str_view_all("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "[А-я]")stringr::str_view_all("The quick brown Fox jumps over the lazy Dog", "[a-z]")stringr::str_view_all("два 15 42. 42 15. 37 08 5. 20 20 20!", "[^0-9]")- выбор из нескольких групп
stringr::str_view_all("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "лар|рал|арл")- произвольный символ
stringr::str_view_all("Везет Сенька Саньку с Сонькой на санках. Санки скок, Сеньку с ног, Соньку в лоб, все — в сугроб", "[Сс].н")- знак начала и конца строки
stringr::str_view_all("от топота копыт пыль по полю летит.", "^о")stringr::str_view_all("У ежа — ежата, у ужа — ужата", "жата$")- есть еще другие группы и другие обозначения уже приведенных групп, см.
?regex
3.3 Квантификация
?– ноль или один раз
stringr::str_view_all("хорошее длинношеее животное", "еее?")*– ноль и более раз
stringr::str_view_all("хорошее длинношеее животное", "ее*")+– один и более раз
stringr::str_view_all("хорошее длинношеее животное", "е+"){n}–nраз
stringr::str_view_all("хорошее длинношеее животное", "е{2}"){n,}–nраз и более
stringr::str_view_all("хорошее длинношеее животное", "е{1,}"){n,m}– отnдоm. Отсутствие пробела важно:{1,2}– правильно,{1,␣2}– неправильно.
stringr::str_view_all("хорошее длинношеее животное", "е{2,3}")- группировка символов
stringr::str_view_all("Пушкиновед, Лермонтовед, Лермонтововед", "(ов)+")stringr::str_view_all("беловатый, розоватый, розововатый", "(ов)+")- жадный vs. нежадный алоритмы
stringr::str_view_all("Пушкиновед, Лермонтовед, Лермонтововед", "в.*ед")stringr::str_view_all("Пушкиновед, Лермонтовед, Лермонтововед", "в.*?ед")4. Задачи
4.1 Чистка html тегов
В мире достаточно много готовых решений по чистке html и xml тегов, так что настало время изобрести велосипед. Напишите функцию tagless(), которая убирает из строки теги.
tagless("<greeting>Hello, world!</greeting>")## [1] "Hello, world!"4.2 Лишние пробелы
Напишите функцию spaceless(), которая убирает лишние пробелы.
spaceless(c("two spaces", "five spaces"))## [1] "two spaces" "five spaces"4.3 Функция для проверки полиндромности
Улучшите функцию is.palindrome(), чтобы она могла учесть знаки препинания, пробелы и т. п.
is.palindrome("Замучен он, но не чумаз")## [1] TRUEis.palindrome("Замучена она, но не чумаза")## [1] FALSEСкачайте произведение Жоржа Перека, посчитайте количество символов в нем и проверьте на полиндромность. Мой вариант несколько препарирован, оригинал можно найти здесь.
4.4 Спеллчекер? Легко!
Скачайте словарь форм русского языка (осторожно, большой файл) на основе словаря А. А. Залязняка и сделайте функцию spellcheck(), которая
- возвращает слова из строки, которых нет в словаре;
- если аргумент
suggestions = TRUE, то возвращает слово с минимальным расстояние Дамерау — Левенштейна.
4.5 Анализ данных небрежно собраннных анкет
В ходе анализа данных чаще всего бороться со строками и регулярными выражениями приходится в процессе обработки неаккуратно собранных анкет. Предлагаю поразвлекаться с подобными данными и построить следующие графики:
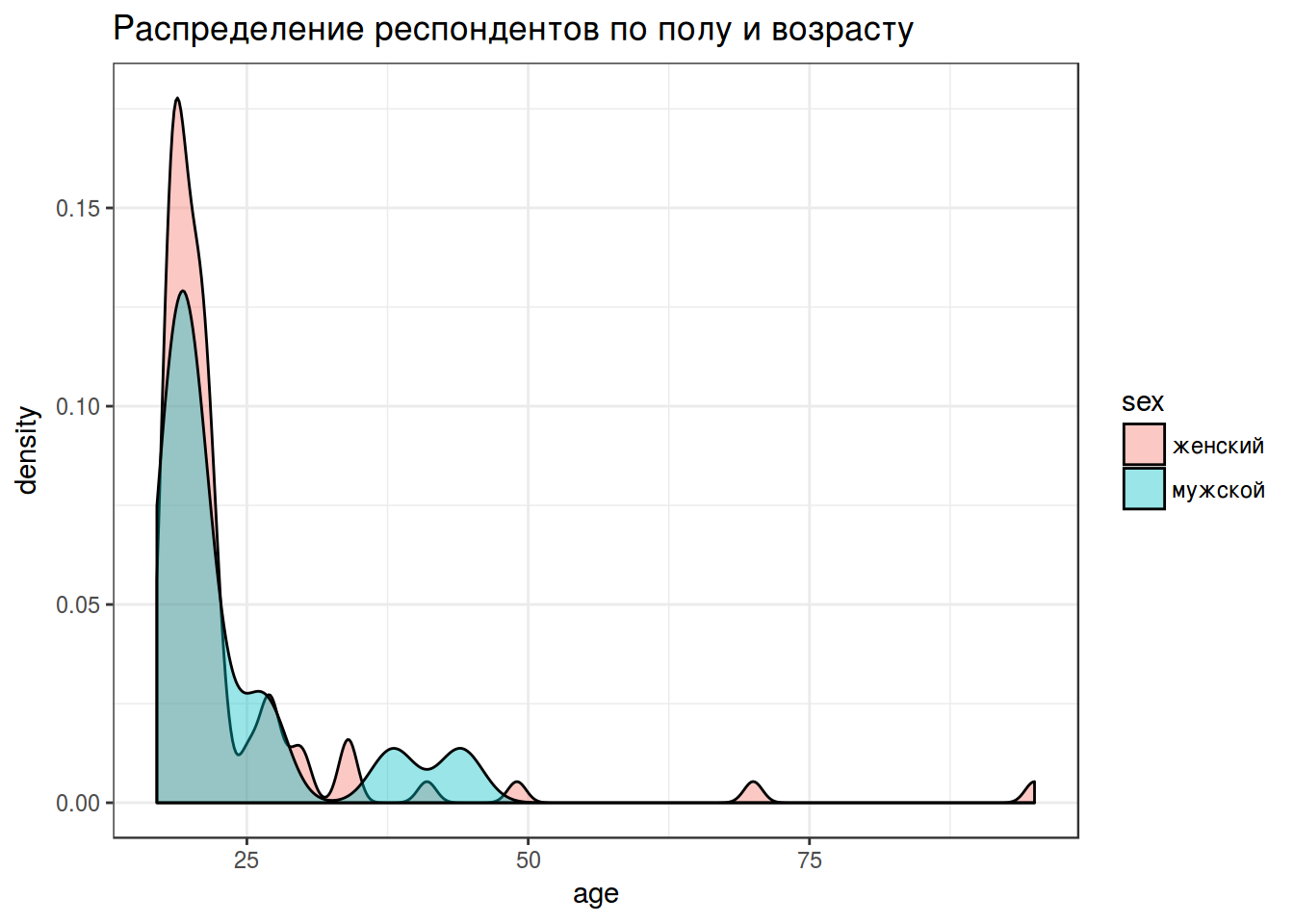
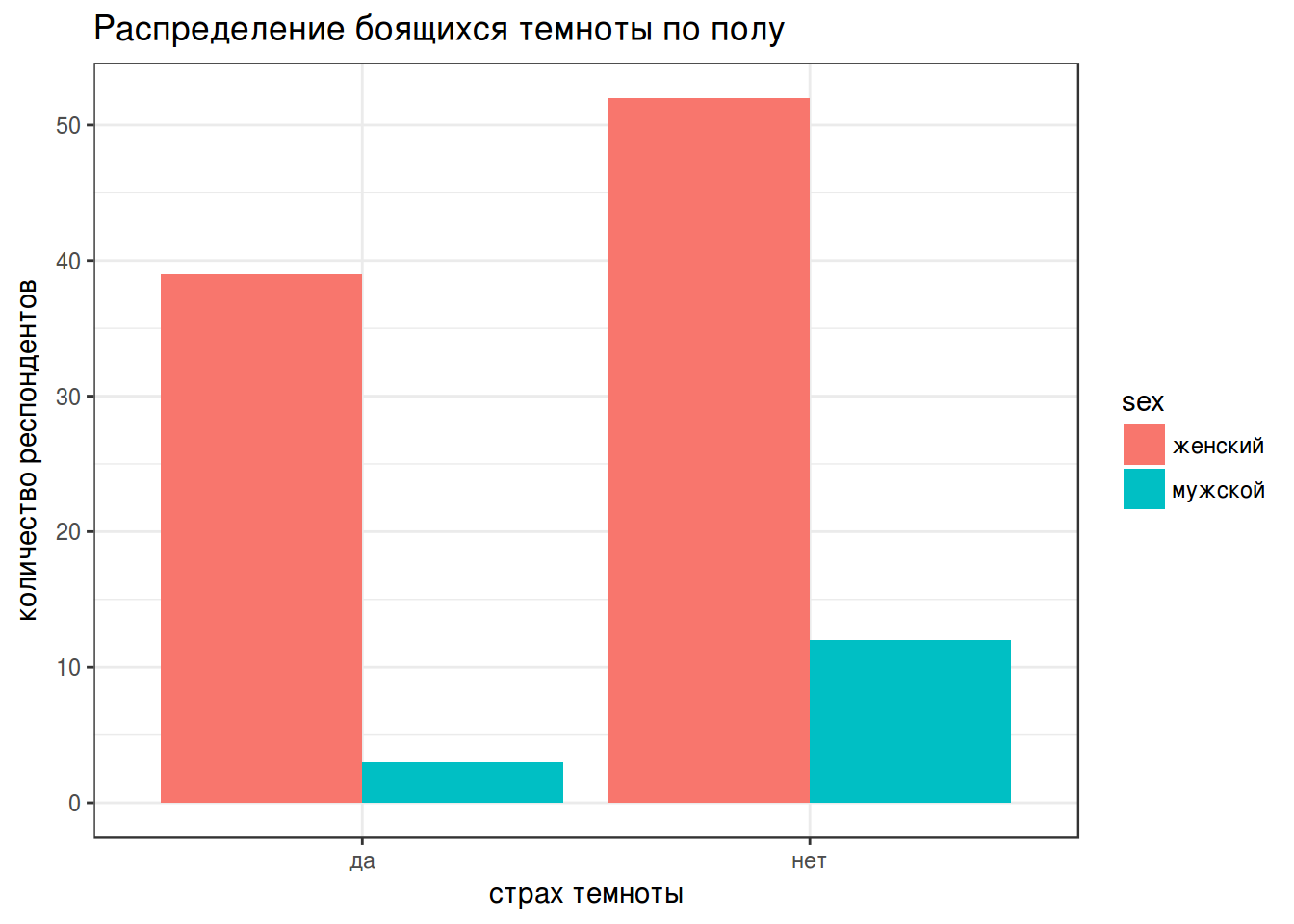
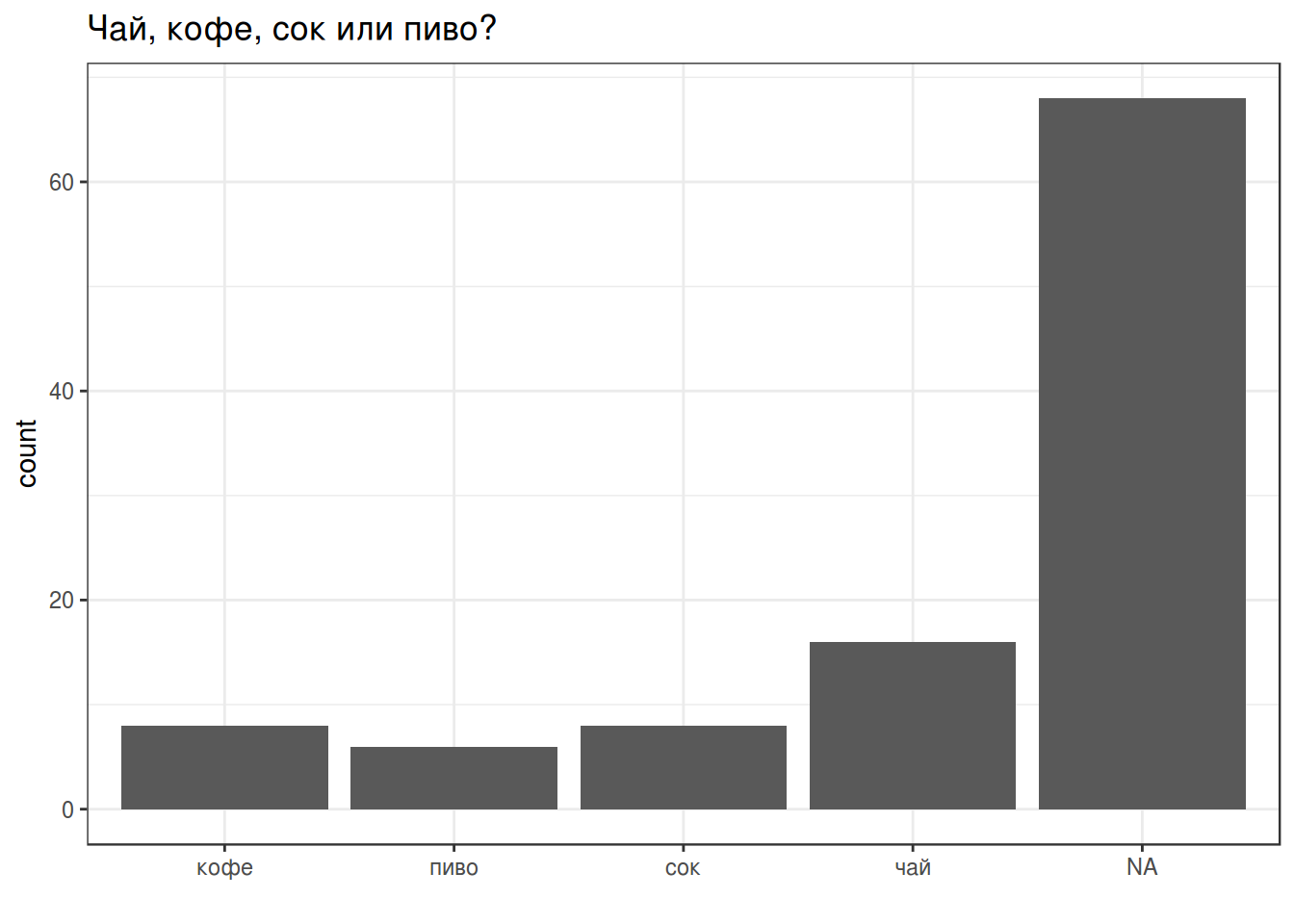
А когда все получится, напишите функцию, которая приведет все телефоны к единому формату: 89143302299.
Данная картинка – рисунок Бориса Аркадьевича Диодорова из книжки Яна Экхольма “Тутта Карлссон, первая и единственная, Людвиг Четырнадцатый и другие”↩