Первый день
Г. Мороз
Presentation link: https://tinyurl.com/yaa5v4s3
1 Данные
- 1 носитль абазинского языка произносил
- односложные слова
- с открытым слогом,
- содержащие гласные a или ə
- в контексте после зубных (t, d, s, z, ts, dz)
- 4 произнесения (3 повторения и carrier phrase)
- все данные записаны в июле 2018 г. в ходе экспедиции НИУ ВШЭ
Данные доступны здесь.
1.1 Исследовательские вопросы
- Правда ли, что a в среднем длиннее ə?
- Верно ли это для всех произнесений (первое, второе, третье, carrier phrase)?
2 Praat
2.1 Работа с файлами
1. Чтение файлов в Praat.
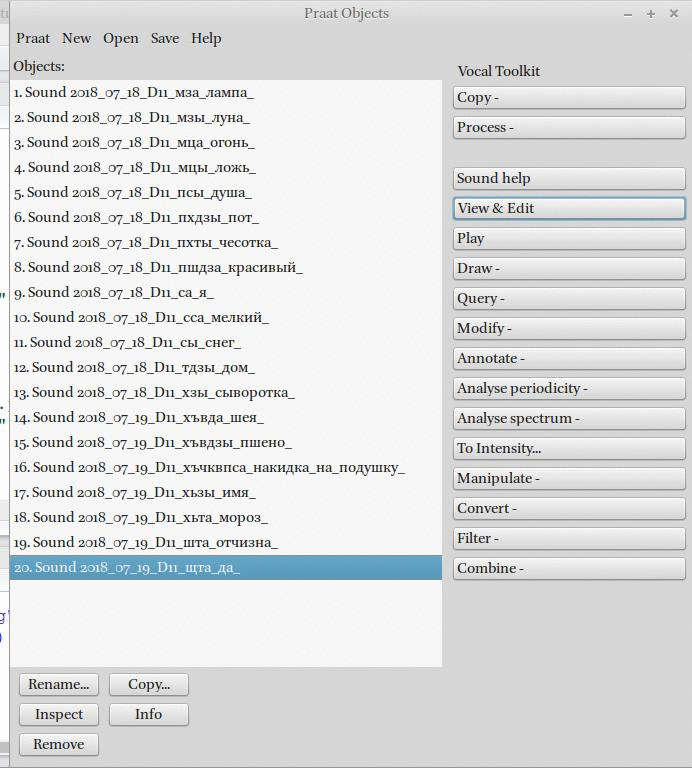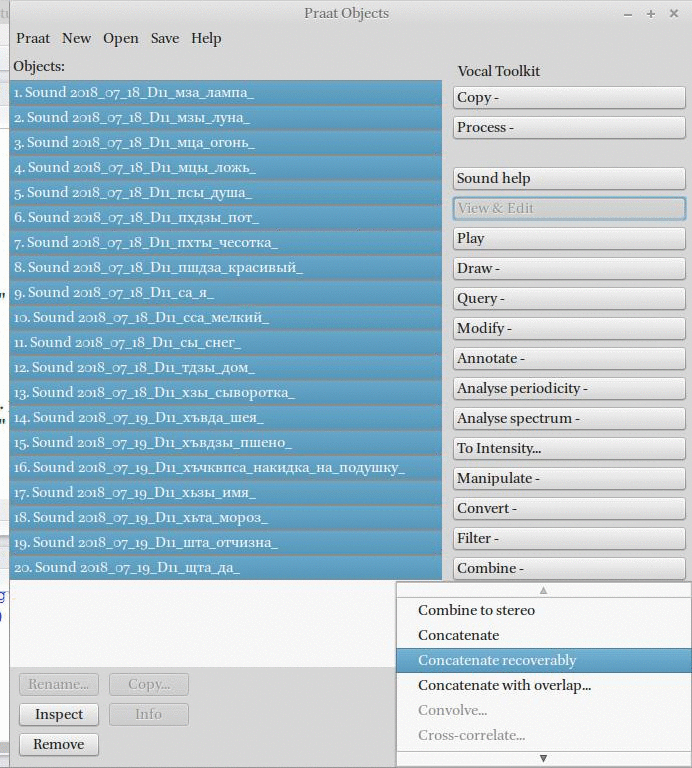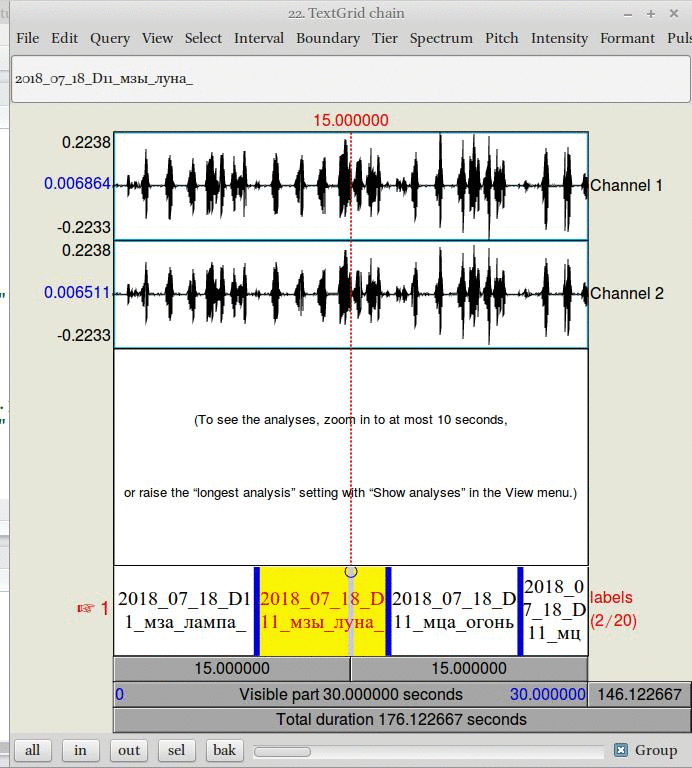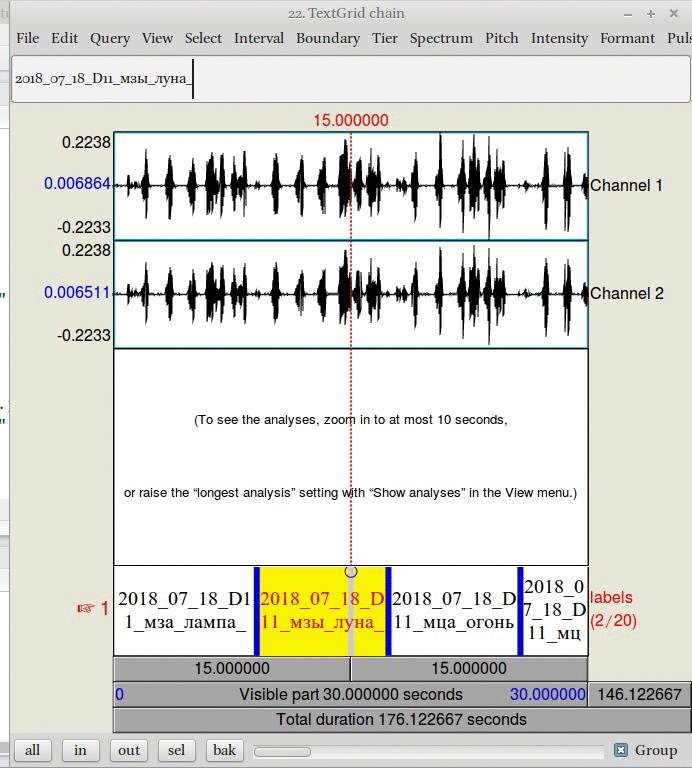
2. Полученные файлы можно соединить в один, сохраняя названия.
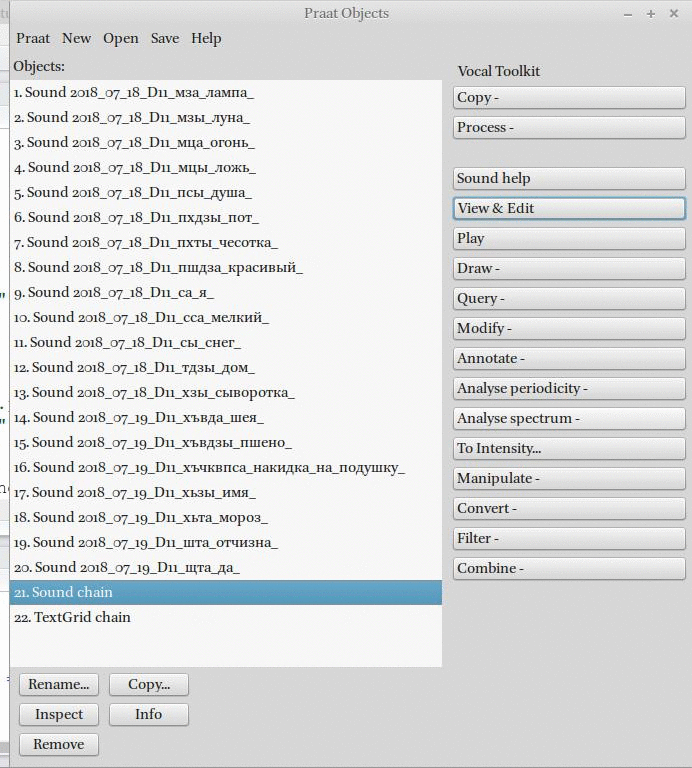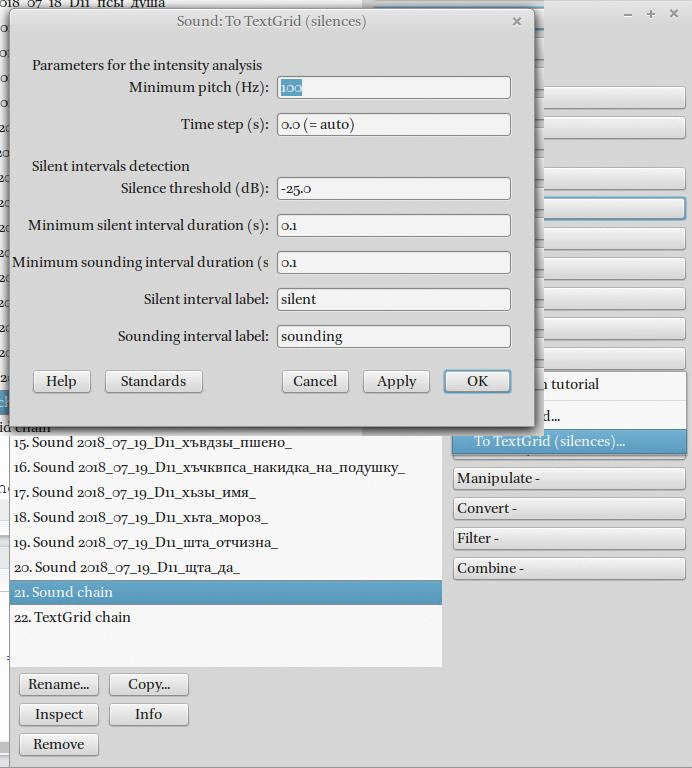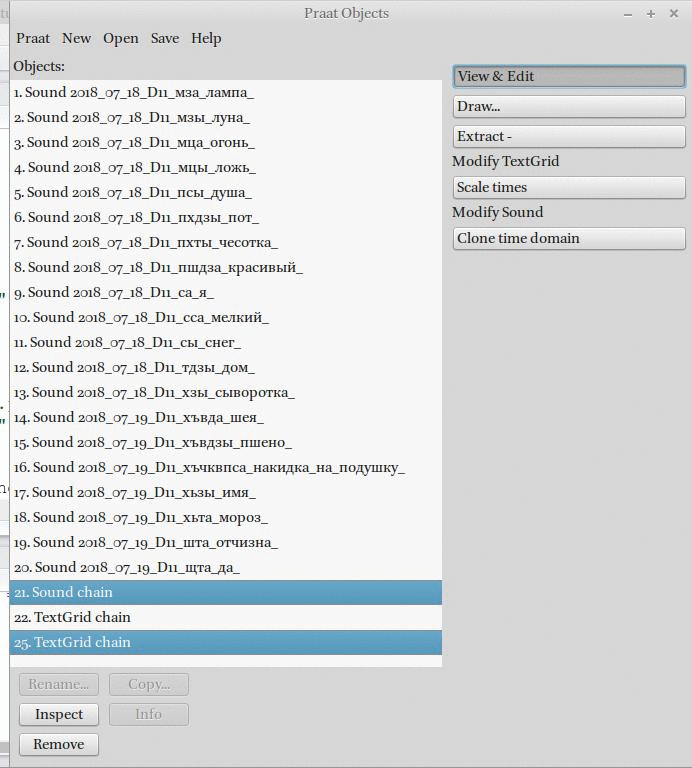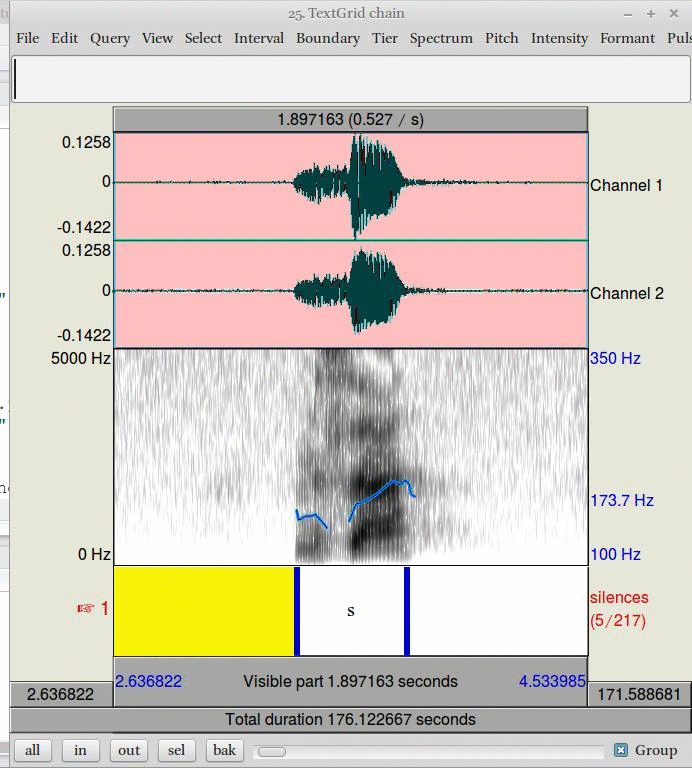
3. Полученный звук можно автоматически разделит по паузам.
4. Полученные аннотации можно соединить.
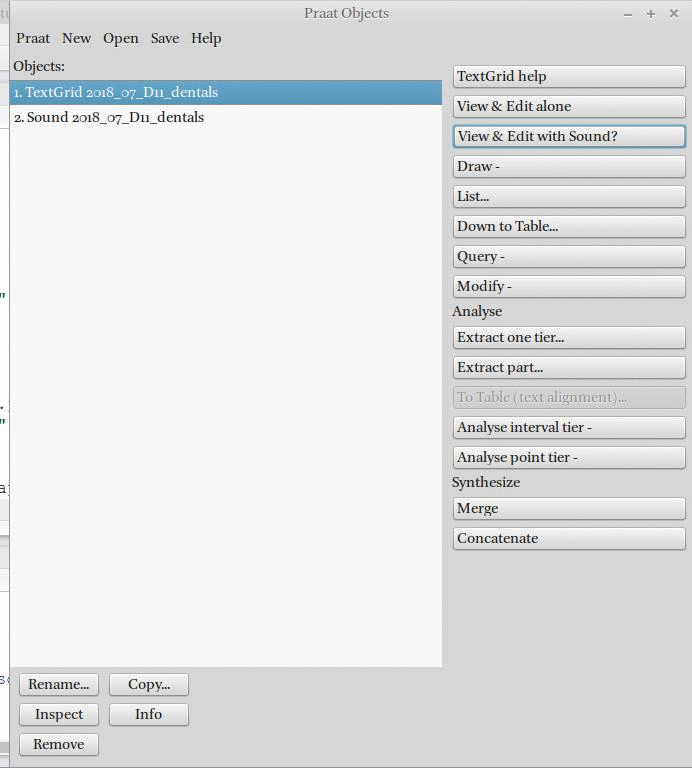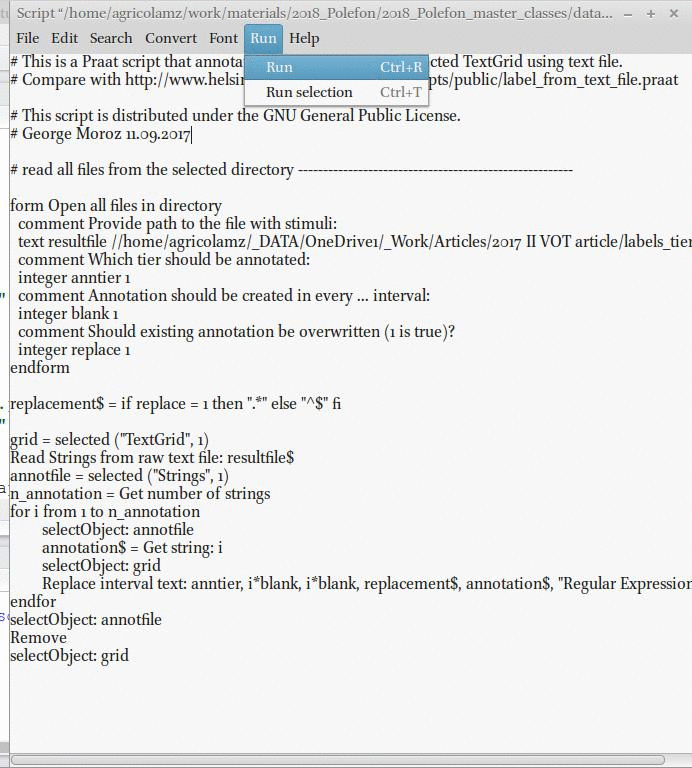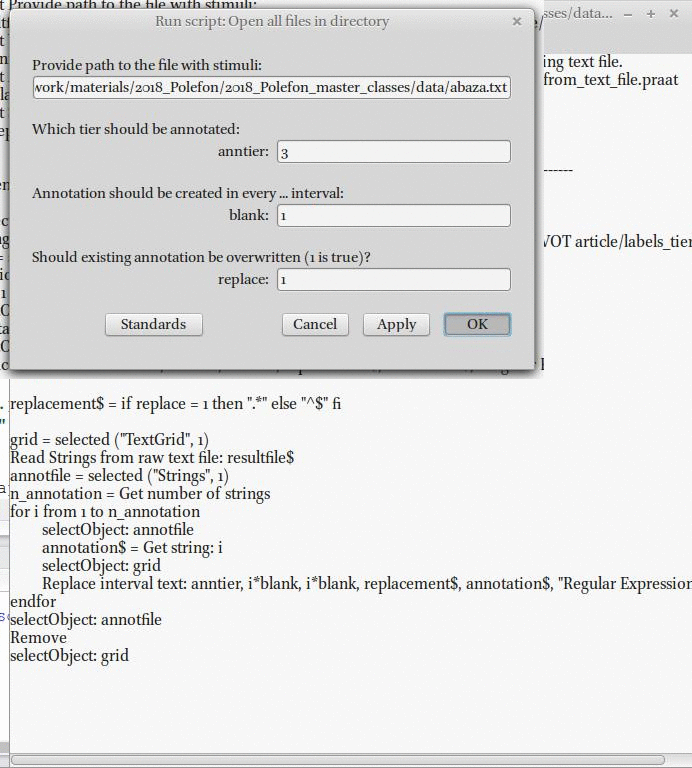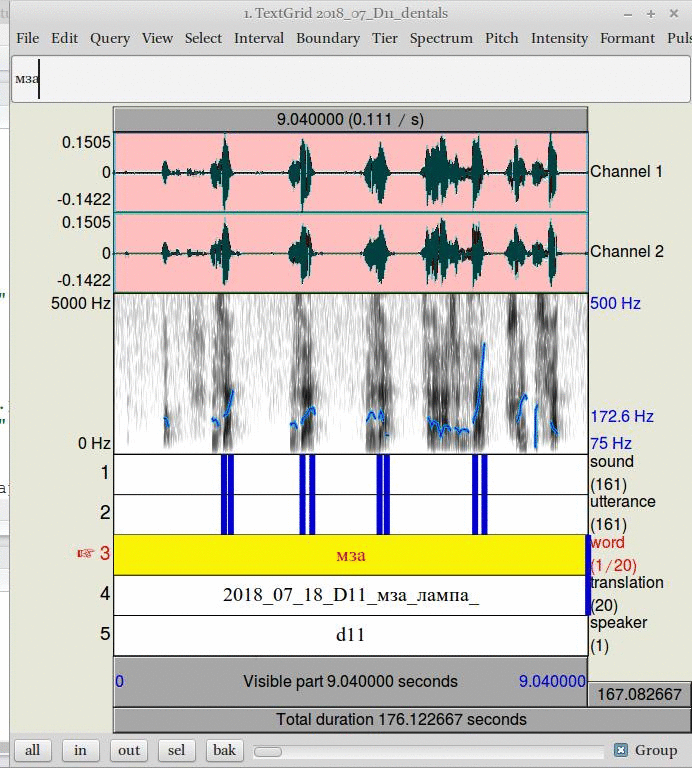
На этом этапе, данные надо почистить и подкорректировать: нужно в полученной автоматически разметке удалить лишнюю разметку и добавить нехватающую. Этим НЕ НАДО заниматься на семинаре. Скачайте уже корректные файлы: звук и текстгрид. Потом, используя команды из вкладки Tier можно поменять структуру разметки на ту, которая хороша для документации языка. Я считаю, что необходимы следующие слои:
- дополнительная разметка
- звуки
- номер произнесения
- слово
- перевод
- код спикера
Эта структура представлена на рисунке ниже:
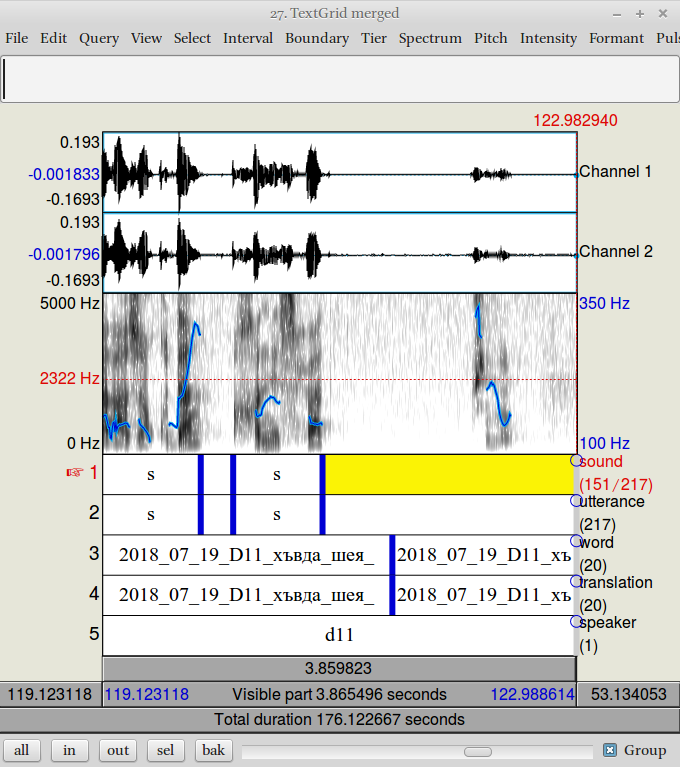
- Структура слоёв.
К сожалению, запись и чтение файлов в Praat нужно настраивать: для сегодняшнего семинара необходимо поменять кодировку чтения и записи файлов.
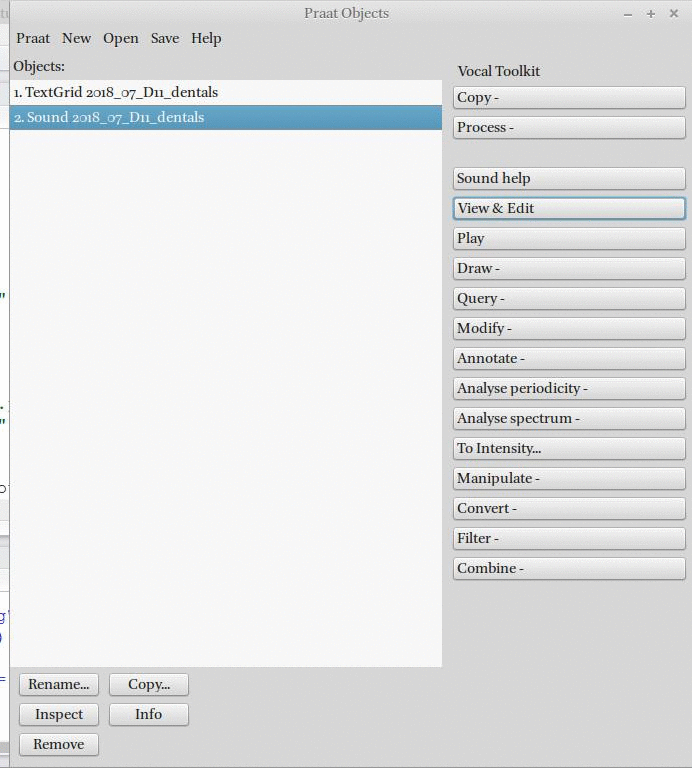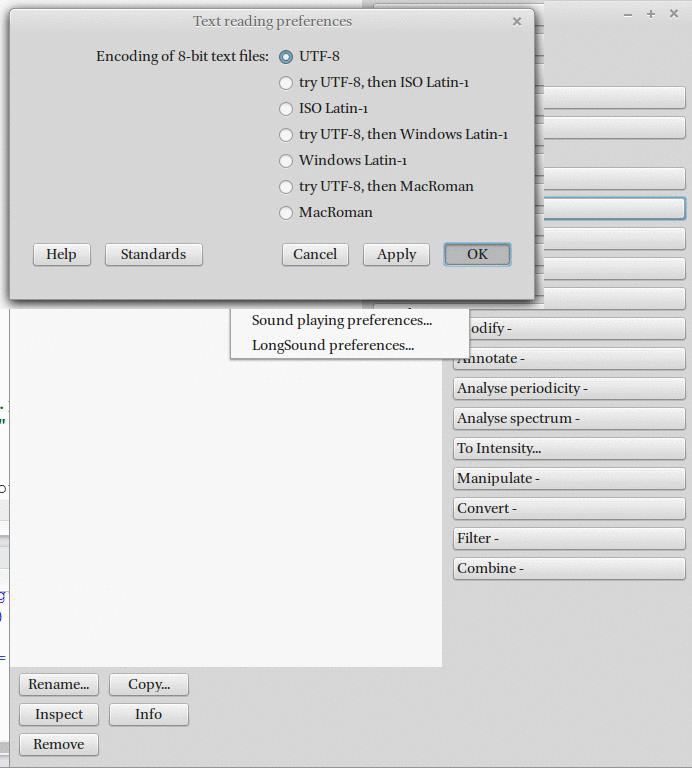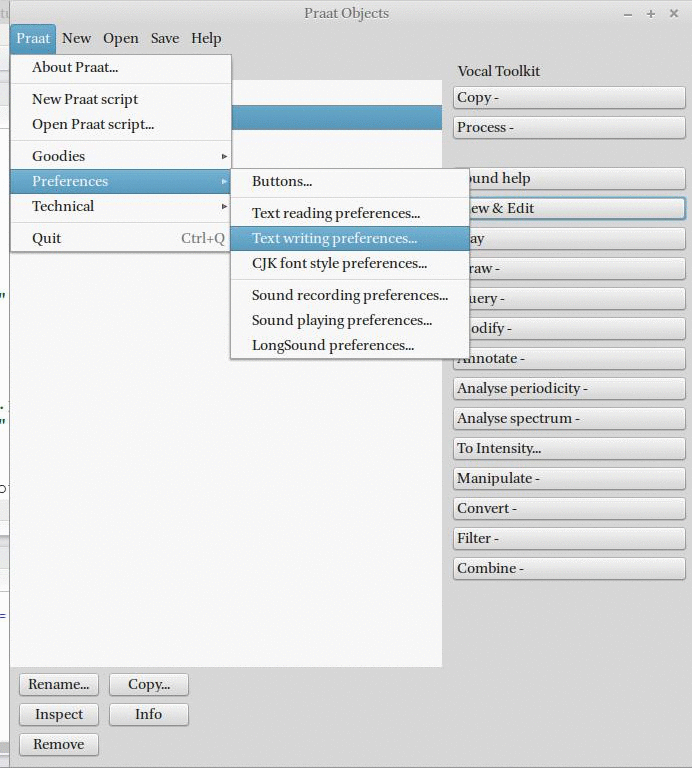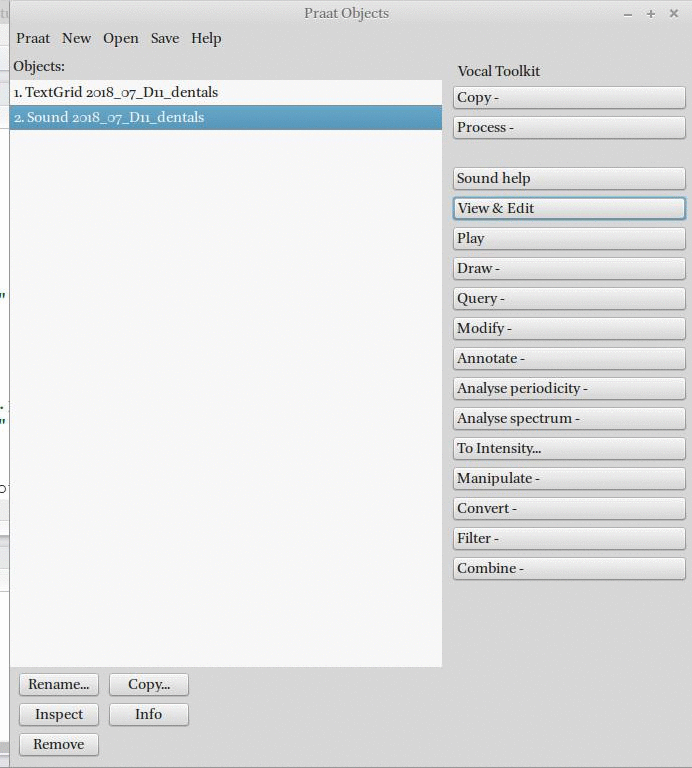
6. Настройка параметров чтения и записи файлов.
2.2 Praat скрипты
Я предлагаю автоматически заполнить полученные файлы, используя следующие файлы:
- Praat скрипт (annotate from text file.praat)
- Файл со звуками (vowels.txt), файл с номерами произнесения (utterances.txt), файл со словами (abaza.txt), файл с переводом (trans.txt)
7. Автоматическая разметка слов.
Для разметки звуков нужно создавать аннотацию в каждой второй разметке:
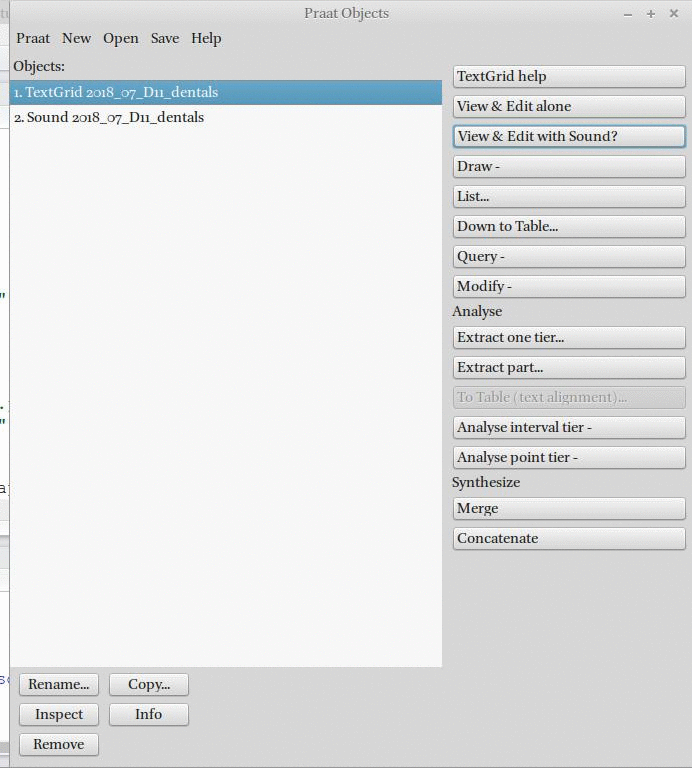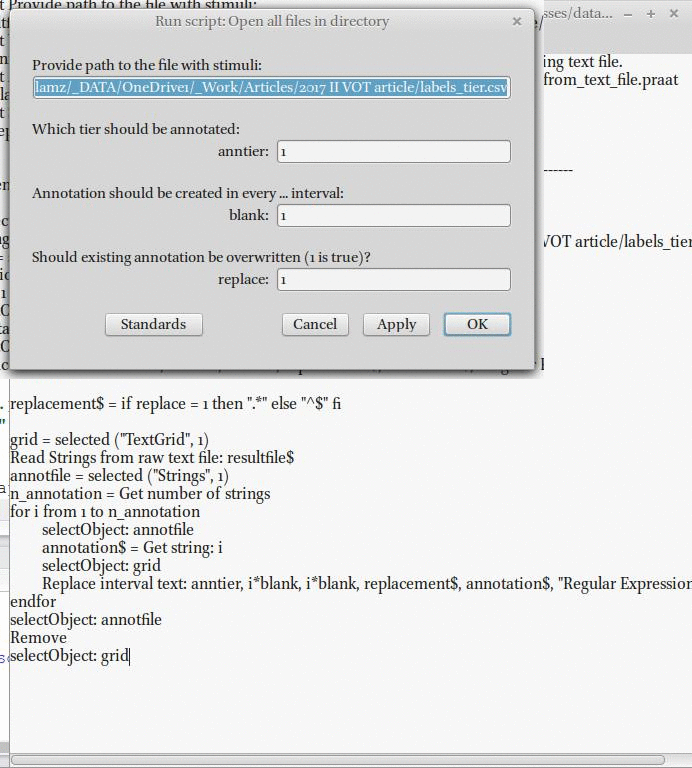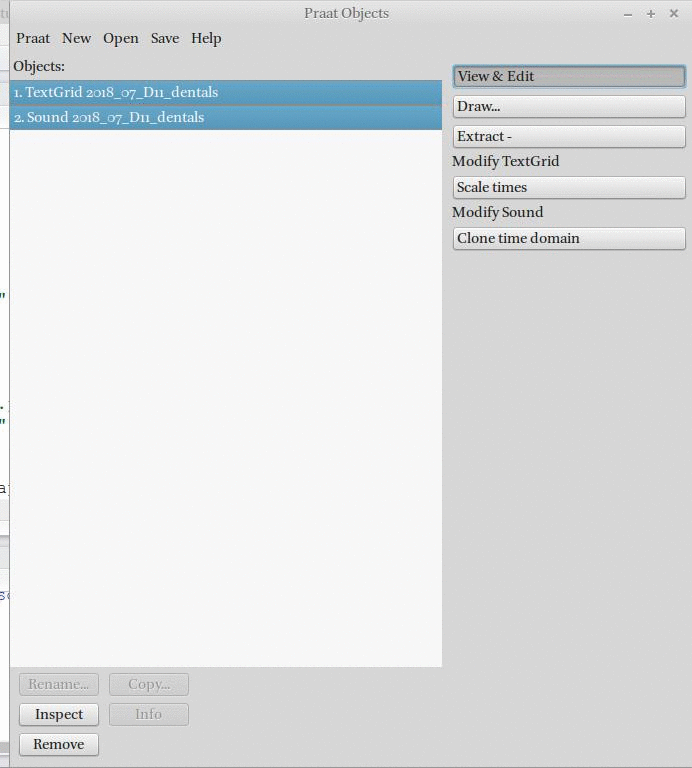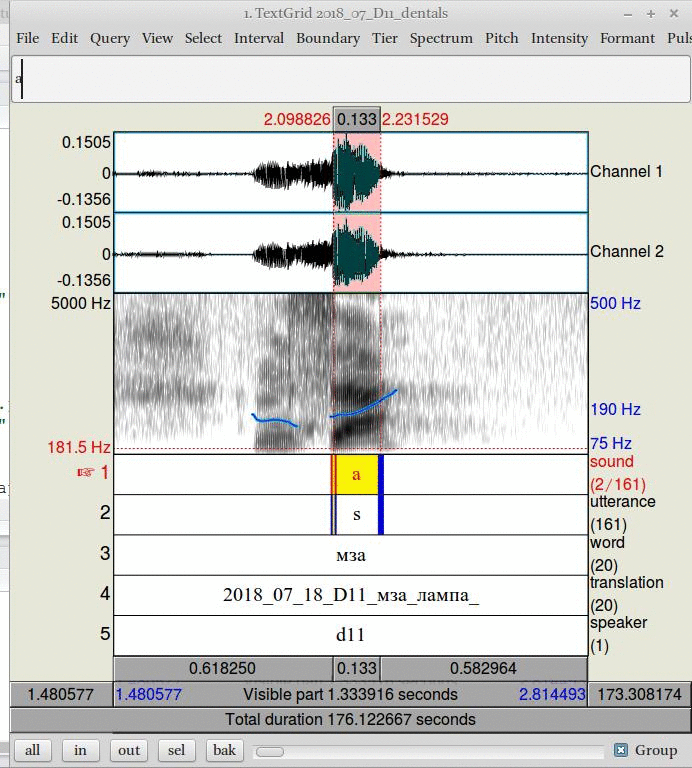
8. Автоматическая разметка звуков.
Аналогично можно разметить остальные слои. После этого можно воспользоваться вот этим скриптом и вынуть всю необходимую информацию. Нам понадобиться только длительность, хотя скрипт вынимает еще и ЧОТ, а также форманты гласных. Если у Вас что-то не получается, можно попробовать запустить скрипт на этом текстгриде. Если у Вас все равно не получилось, можно взять вот этот файл с результатами.
