2 Введение в R
2.1 Основы
2.1.1 Типы данных
В R есть несколько типов данных, которые нам будут важны на наших занятиях:
- числа
5## [1] 58.23## [1] 8.23- строки
"hi"## [1] "hi""тро-ло-ло"## [1] "тро-ло-ло""שלום"## [1] "שלום"Важно отметить, что числа также могут быть строкой: "5".
- логические операторы
TRUE## [1] TRUEFALSE## [1] FALSE- пропущенные значения
NA## [1] NAНабор значений можно при помощи функции c() объединить в единицу, которая называется вектор:
c(4, 9)## [1] 4 9c("first name", "фамилия")## [1] "first name" "фамилия"2.1.2 Переменные
Любое значение можно записать в переменную. Для этого используется оператор присваивания =1:
x = 2021
x## [1] 2021y = c("имя", "last name")Переменные можно спользовать в манипуляциях:
x + 3## [1] 2024Однако она останется не изменной, пока мы не сделаем новое присваивание:
x## [1] 2021x = x + 3
x## [1] 20242.1.3 Функции
Любые действия в R происходят при помощи функций:
x = c(1, 3, 5, 7)
mean(x)## [1] 4cumsum(x)## [1] 1 4 9 16
Используя функцию sqrt() найдите квадратный корень числа 152399025.
2.1.4 Пакеты
Большая часть преимуществ R находится в его пакетах — наборах функций. Сегодня мы будем использовать пакет tidyverse, а завтра пакеты leaflet и leaflet.minicharts. Первое что имеет смысл сделать, это научиться устанавливать пакеты:
install.packages(c("tidyverse", "leaflet", "leaflet.minicharts"))R может попросить при первой установке выбрать зеркало – это не особенно важно, можете выбрать любое. Перед использованием пакета его нужно включить:
library(tidyverse)## ── Attaching packages ─────────────────────────────────────── tidyverse 1.3.1 ──## ✓ ggplot2 3.3.5 ✓ purrr 0.3.4
## ✓ tibble 3.1.5 ✓ dplyr 1.0.7
## ✓ tidyr 1.1.4 ✓ stringr 1.4.0
## ✓ readr 2.0.2 ✓ forcats 0.5.1## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()Пакет выдал какое-то сообщение: такое бывает. Главное чтобы не выдал ошибки.
Если Вы еще не скачали пакет, запустите его скачивание и включите библиотеку tidyverse.
2.1.5 Как получить помощь?
Во первых легко получить помощь в интернете. Но и в самом R, каждая функция задокументирована, так что можно просто набрать в консоли вопросительный знак и название функции:
?sqrt()2.2 Введение в tidyverse
В R существуют свои поддиалекты: есть базовый R, есть tidyverse, есть data.table. В этих материалах мы будем работать с tidyverse.
2.2.1 Чтение файлов
Люди придумали достаточно много способов хранить табличные данные (мы будем смотреть только на такие данные). Всем известны таблицы из Excel/LibreOffice/Numbers и самые распространенные форматы .xls и .xlsx, c которыми можно работать в R при помощи пакетов readxl и writexl. На наших занятиях мы рассмотрим более простой формат, с которым предпочитают работать при анализе данных — .csv. Этот формат предполагает использование как машинно-, так и человеко-читаемый формат, в котором значения разделяются некоторым разделителем. Чаще всего в качестве разделителя используют запятую (поэтому .csv расшифровывается как comma separated values). Важным условием для работы является, чтобы значения в одном столбце были одного типа. Первой строчкой в таком формате данных обычно идет название столбцов. Этот формат можно открыть и редактировать в привычном редакторе однако для пользователей Excel это, к сожалению, требует дополнительных операций, а для пользователей Windows еще и нужно непрырывно следить, чтобы была верная кодировка.
df = read_csv("https://tinyurl.com/yzfgony9")
dfВ нашем датасете следующие переменные:
- tombstone_code — код надгробия (
BSH0141) - place — место (
Бешенковичи) - tombstone_id — уникальный номер надгробия (
141) - latitude — широта (
55.0455800198435) - longitude — долгота (
29.4838749171489) - last_name — фамилия (
Фридман) - name — имя (
Ицхак Менаше) - fathers_name — имя отца (
Зув Вольф) - gender — гендерная принадлежность (
m) - year — год смерти (1919)
- tags — тэги, проставленные разметчиками (
юноша) - epitaph_language — язык эпитафии (
HE) - decor_type — тип декора (
O— архитектурно-орнаментальный;F— растительный;Z— зооморфный;S— традиционная символика) - tombstone_type — тип памятника (
M— стела,L— стела с саркофагом,P— саркофаг/плита,O— охель,S— индивидуальной или сложной формы;N— не определен) - tombstone_material_code — материал надгробия (
S- камень:SS-песчаник,SC- известняк,SG- гранит,SB- габбро-диорит,SL- лабрадорит,SM- мрамор,AS- искусственный камень,M- металл,W- дерево,O- другое)
Считайте даные к себе в RStudio. Сколько строчек из датасета напечатались в консоле при вызове переменной с данными?
2.2.2 Манипуляция с данными
При анализе данных часто нужно сделать несколько операций. Рассмотрим пример:
x = c(5, 7, 3)
cumsum(x)## [1] 5 12 15cumsum(sort(x))## [1] 3 8 15sort(cumsum(x))## [1] 5 12 15Как видно из примера в зависимости от порядка применения функций получается разный результат. Читать длинные цепочки функций не очень удобно, например, при подготовке к нашим занятиям я написал цепочку из 91 операций над датасетом, который мне прислали. В tidyverse очень распространено использование так называемого конвеера (pipe), который передает результат работы одной функции в другую:
x %>%
cumsum() %>%
sort()## [1] 5 12 15x %>%
sort() %>%
cumsum() ## [1] 3 8 15Для знака конвеера есть своя горячая клавиша: Ctrl/Cmd+Shift+M. Конечно, результат можно при желании записать в переменную:
x2 =
x %>%
sort() %>%
cumsum()
x2## [1] 3 8 152.2.2.1 select()
Теперь мы можем приступить к анализу данных. Начнем с функции select(), которая позволяет создать подтаблицу с нужными столбцами, например:
df %>%
select(tombstone_code, year, gender)2.2.2.2 arrange()
Теперь рассмотрим функцию arrange(), которая позволяет сортировать один или более столбцов. Например, давайте узнаем гендерную принадлежность усопшего, которого в нашем датасете похоронили раньше всего:
df %>%
select(tombstone_code, year, gender) %>%
arrange(year)Измените предыдущий код, чтобы узнать, где захоронен этот самый ранний усопший?
В функции arrange() можно использовать сразу несколько переменных.
2.2.2.3 count()
Функция count() позволяет считать количество наблюдений. Если в скобках не указывать переменных, то функция вернет количество строчек в датасете:
df %>%
count()Но можно также выбрать какую-то переменную или даже комбинацию переменных:
df %>%
count(gender)df %>%
count(place, gender)
Узнайте в каком из кладбищ больше стел с саркофагом (переменная tombstone_type значение L).
2.2.2.4 filter()
Функция filter() позволяет отсортировать какие-то значения в переменной:
df %>%
count(place, gender) %>%
filter(gender == "f")Несколько условий можно писать через запятую:
df %>%
count(place, gender) %>%
filter(gender == "f",
place == "Бешенковичи")Если все условия выше предполагают равенство ==, то бывает, что нужно отфильтровать ненужное !=:
df %>%
count(place, gender) %>%
filter(gender != "n",
place == "Бешенковичи")2.2.2.5 mutate()
Иногда переменных в датасете недостаточно, или имеющиеся нужно изменить, для этого используют функцию mutate(). Давайте например, создадим переменную, которая будет содержать возраст надгробий:
df %>%
mutate(tombstone_age = 2021 - year) %>%
select(tombstone_code, year, tombstone_age)В одной функции можно создать и несколько переменных.
2.2.2.6 group_by() %>% summarise()
Данная комбинация позволяет создать аналог сводных таблиц в Excel/LibreOffice. Давайте посчитаем средний возраст надгробий в каждом из населенных пунктов:
df %>%
mutate(tombstone_age = 2021 - year) %>%
group_by(place) %>%
summarise(mean_age = mean(tombstone_age, na.rm = TRUE))Аргумент na.rm = TRUE отвечает за удаление пропущенных значений. Мы могли бы их отфильтровать используя в самом начале команду filter(is.na(year)). Сгруппировать можно и по нескольким переменным:
df %>%
mutate(tombstone_age = 2021 - year) %>%
group_by(place, gender) %>%
summarise(mean_age = mean(tombstone_age, na.rm = TRUE))## `summarise()` has grouped output by 'place'. You can override using the `.groups` argument.Схематично операции, которые происходят в ходе комбинации команд group_by() %>% summarise() можно изобразить так:
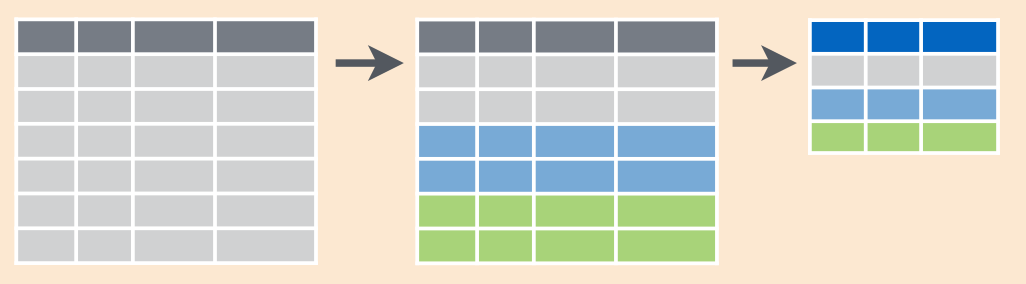
2.2.2.7 group_by() %>% mutate()
Если group_by() %>% summarise() создает новую сокращенную табличку, то сочетание команд group_by() %>% mutate() позволяет оставлять структуру таблицы нетронутой, что может быть важно, если какие-то из переменных будут потом использоваться.
df %>%
mutate(tombstone_age = 2021 - year) %>%
group_by(place, gender) %>%
mutate(mean_age = mean(tombstone_age, na.rm = TRUE)) %>%
select(tombstone_code, place, gender, tombstone_age, mean_age)Схематично операции, которые происходят в ходе комбинации команд group_by() %>% mutate() можно изобразить так:
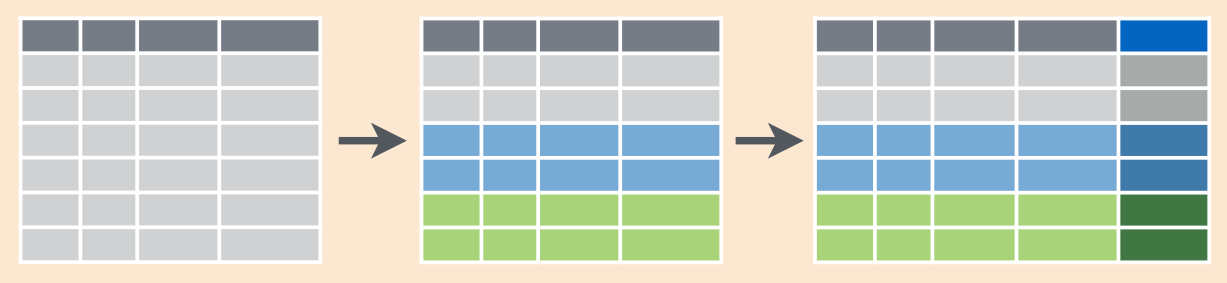
Надо сказать, что в R обычно настаивают на использований операторов
<-и->, однако при нашем беглом знакомстве интуитивнее использовать знак равно.↩︎