3 Визуализация с ggplot2
Для начала включим библиотеку
library("tidyverse")и скачаем датасет:
df <- read_csv("https://tinyurl.com/yzfgony9")3.1 Построим первый график
Сначала сделаем данные для визуализации:
df %>%
count(place)Теперь сделаем наш первый график:
df %>%
count(place) %>%
ggplot()+
aes(x = place, y = n)+
geom_col()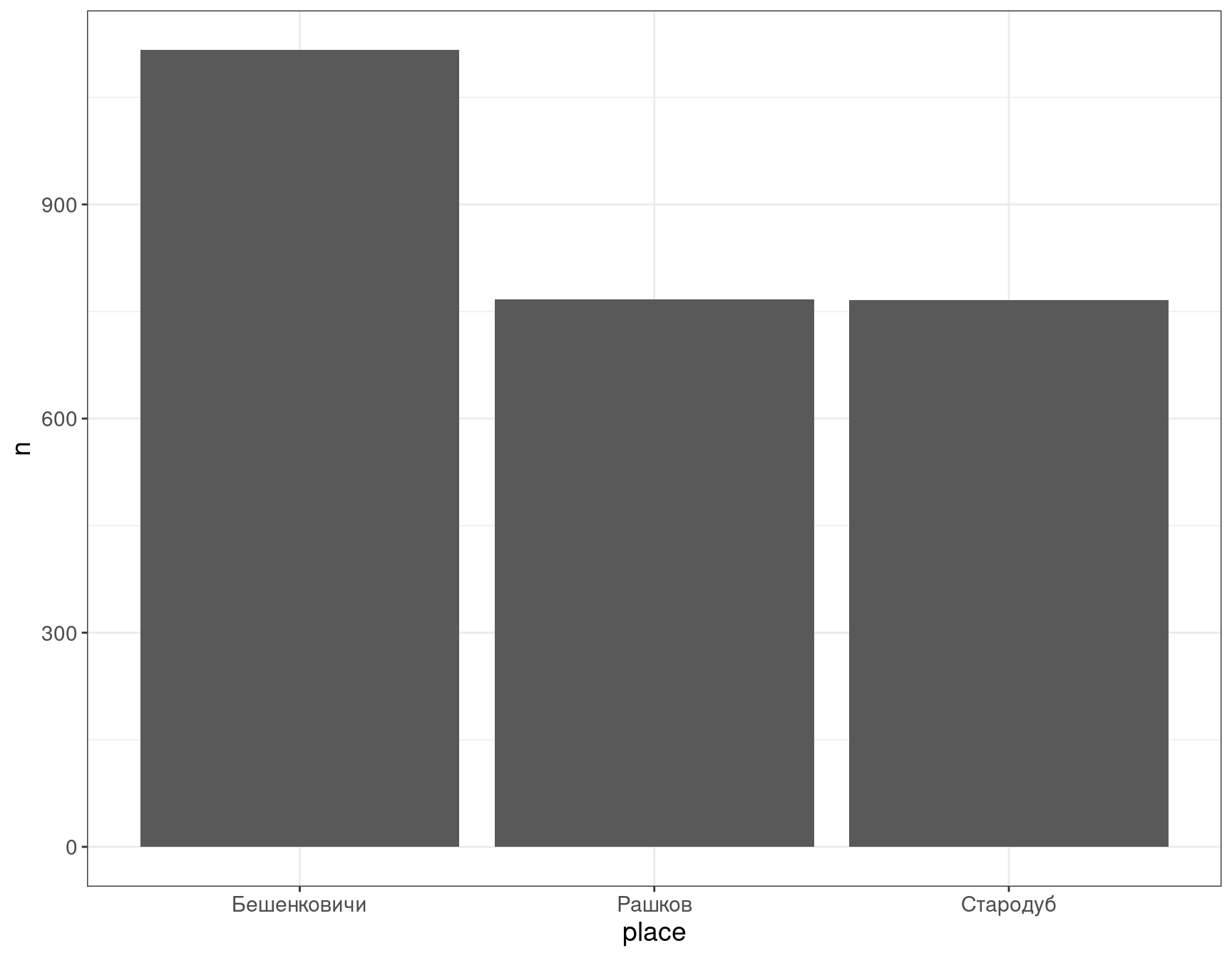
Мы можем поменять цвет получившегося:
df %>%
count(place) %>%
ggplot()+
aes(x = place, y = n)+
geom_col(fill = "darkgreen")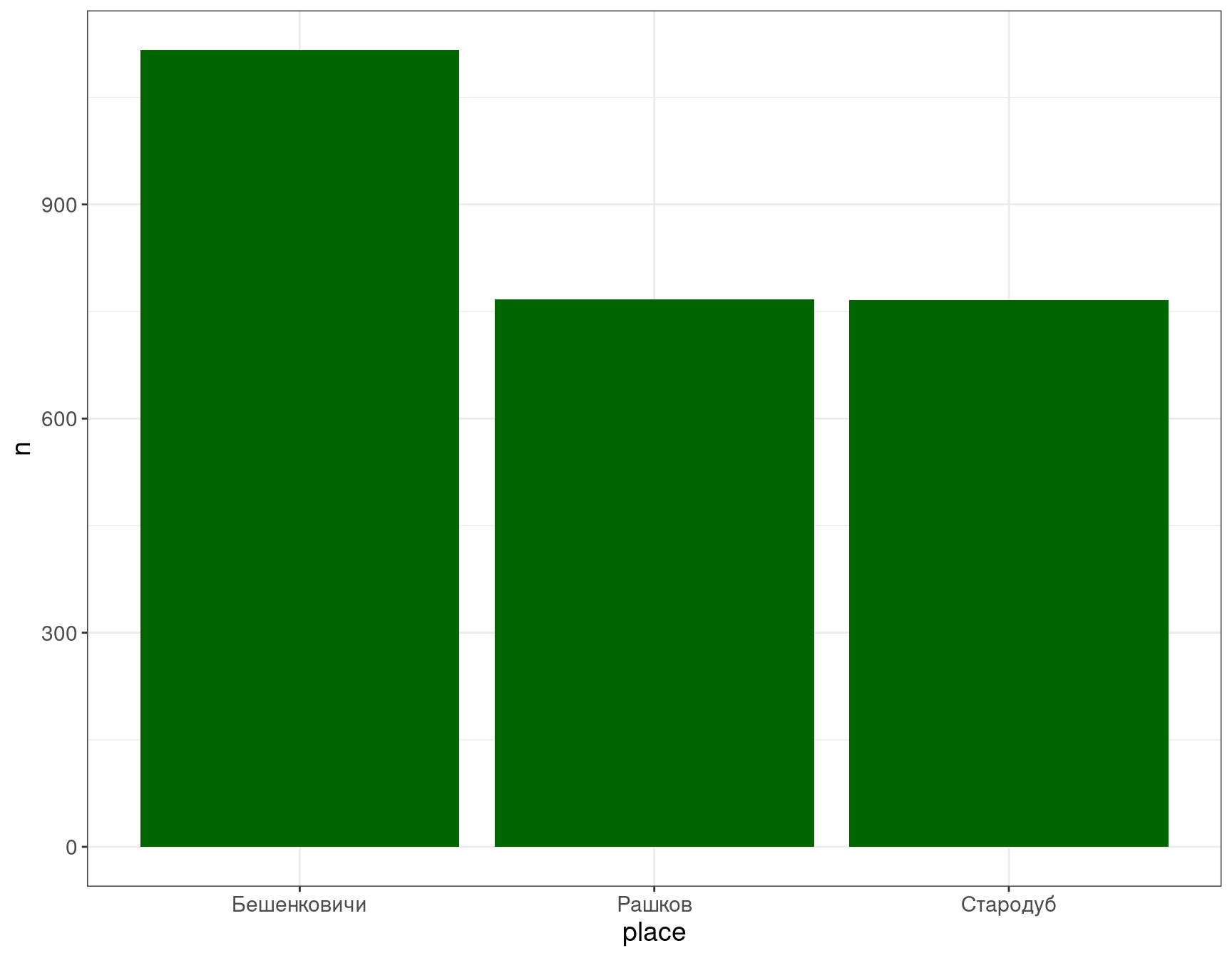
Попробуем добавить гендерную принадлежность усопших:
df %>%
count(gender, place) %>%
ggplot()+
aes(x = place, y = n, fill = gender)+
geom_col()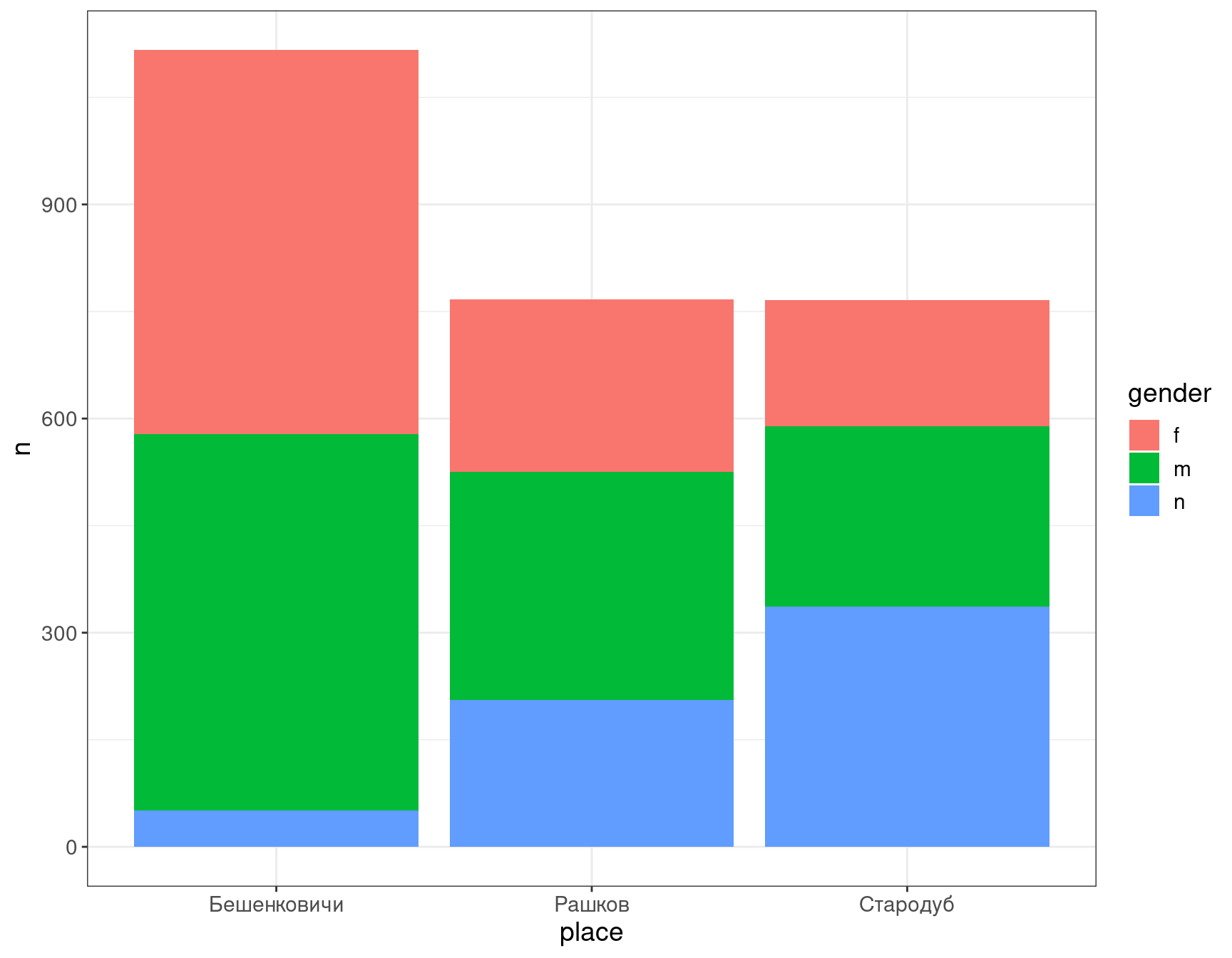
Так распределения сложно сравнивать, так что давайте сделаем их рядом:
df %>%
count(gender, place) %>%
ggplot()+
aes(x = place, y = n, fill = gender)+
geom_col(position = "dodge")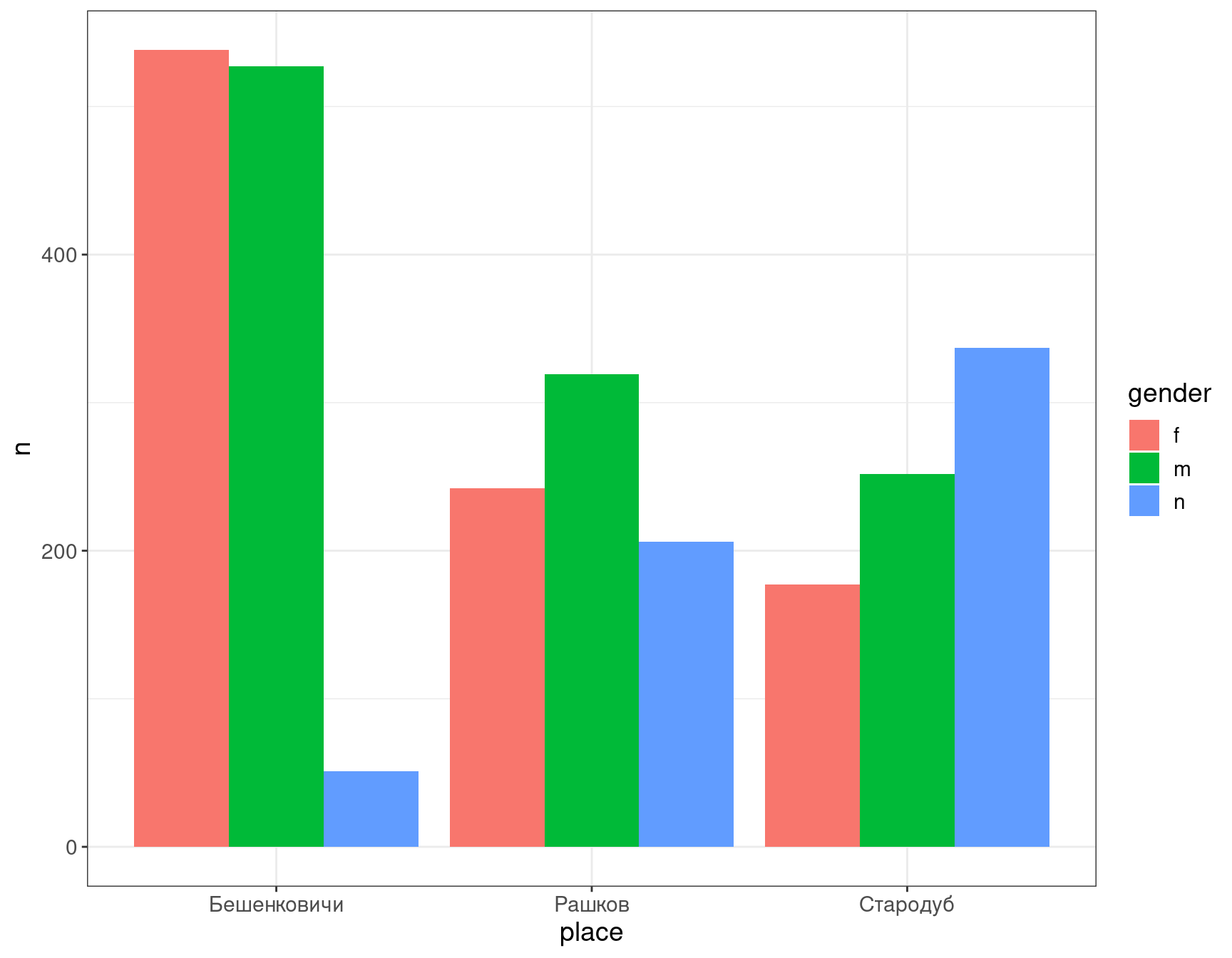
Если мы не хотим сравнивать графики между собой, то их можно развести по разным подграфикам:
df %>%
count(gender, place) %>%
ggplot()+
aes(x = gender, y = n)+
geom_col(position = "dodge")+
facet_wrap(~place)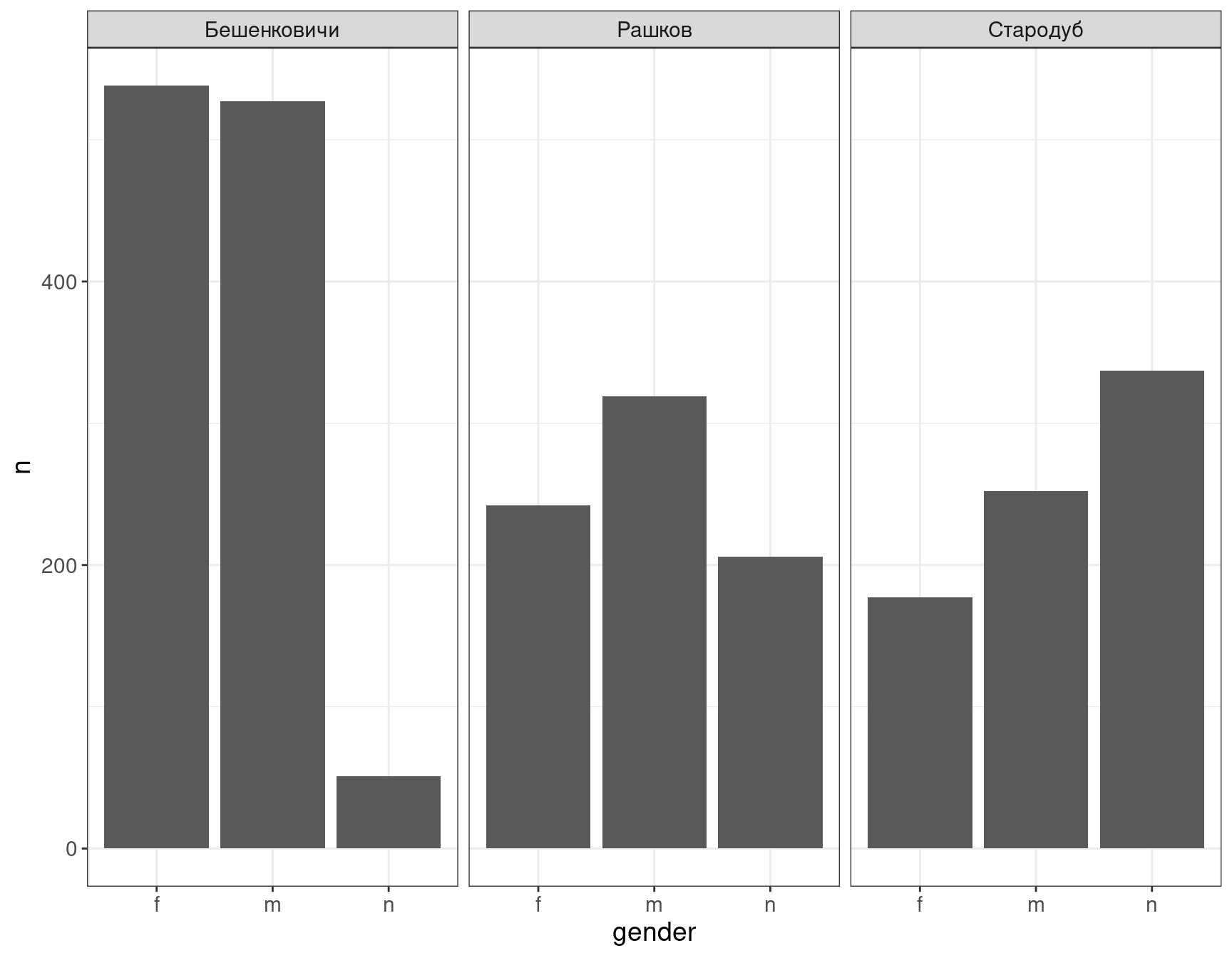
По умолчанию рисуется одинаковая шкала, но можно это изменить при помощи аргумента scales = "free":
df %>%
count(gender, place) %>%
ggplot()+
aes(x = gender, y = n)+
geom_col(position = "dodge")+
facet_wrap(~place, scales = "free")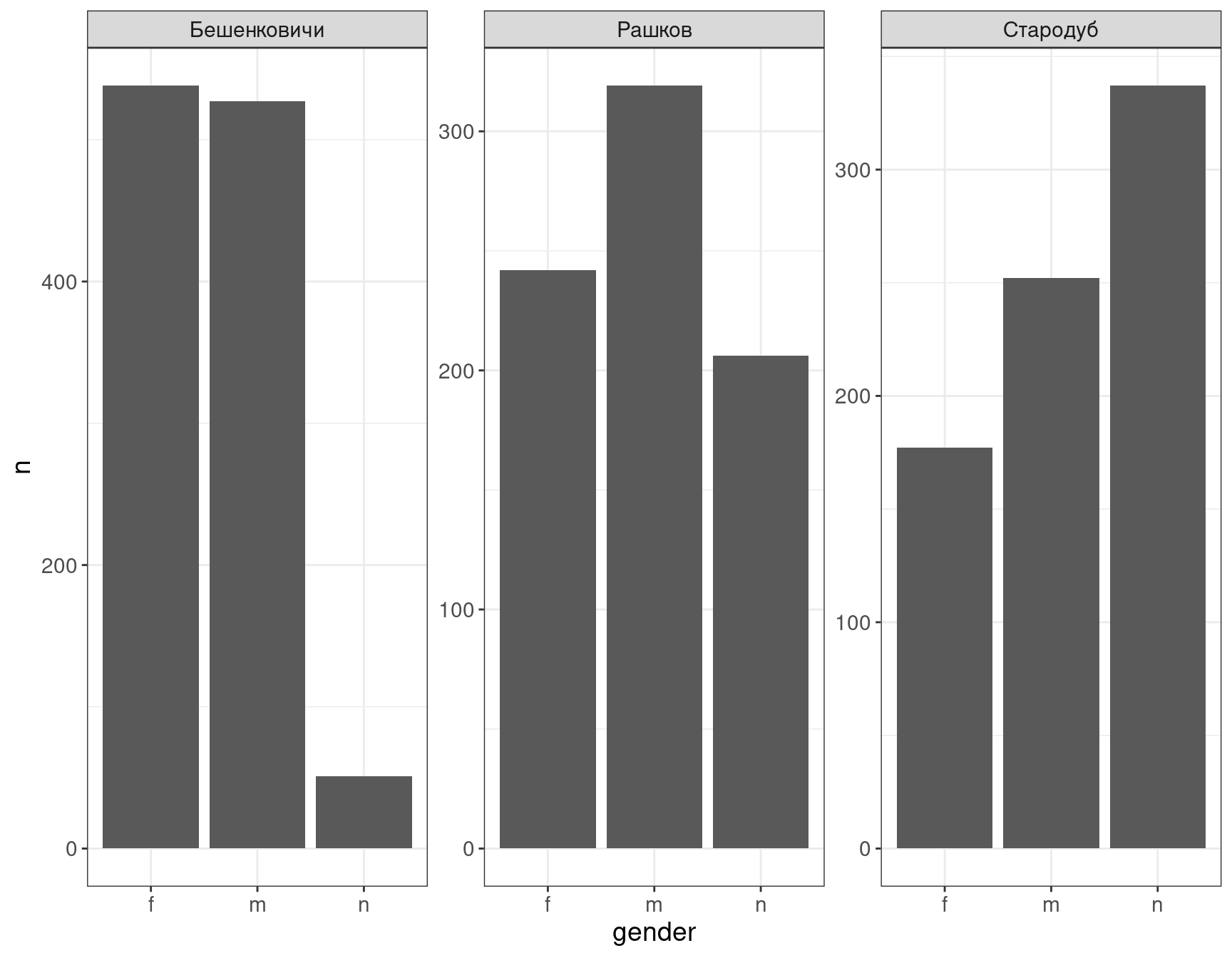
Ну что же настал момент, когда можно остановиться и осмыслить то, что мы видим:
- мужских надгробий больше чем женских (видите исключение?);
- сохранность текстов эпитафий (которые позволяют установить пол покойного) самая высокая в Бешенковичах и самая низкая — в Стародубе.
Попробуйте воспроизвести график распределения типов надгробий.
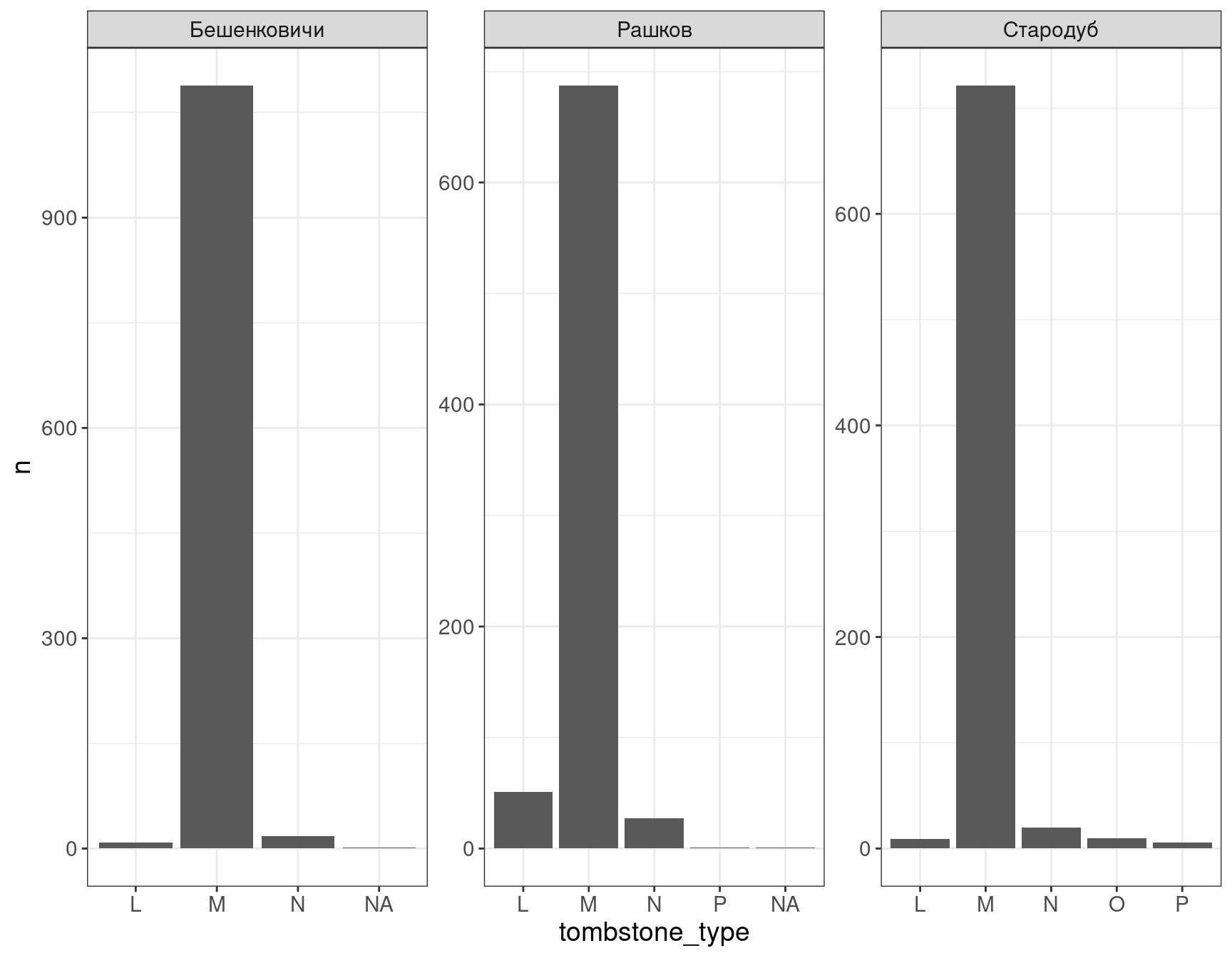
3.2 Другие geom_...-ы
В ggplot2 встроены очень много разных geom_...-ов (их инвентарь можно посмотреть, просто введя geom_ и нажав табуляцию). Например, мы можем украсить график, построенный ранее, просто добавив еще один geom_...:
df %>%
count(gender, place) %>%
ggplot()+
aes(x = gender, y = n, label = n)+
geom_col()+
geom_label()+
facet_wrap(~place, scales = "free")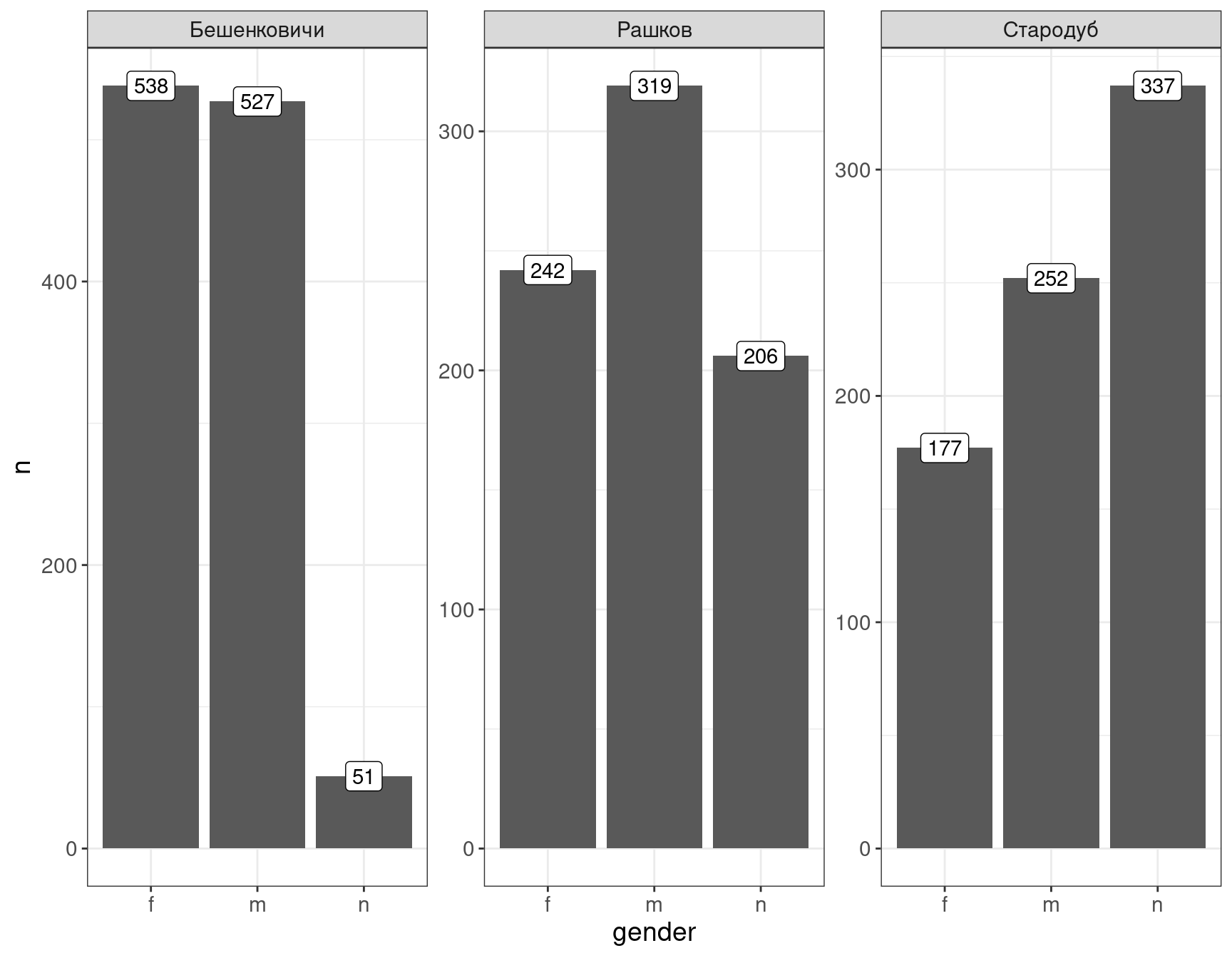
При этом необходимо помнить, что порядок действий имеет значение, если мы поменяем местами два geom_...-а, то получится не самый удачный график:
df %>%
count(gender, place) %>%
ggplot()+
aes(x = gender, y = n, label = n)+
geom_label()+
geom_col()+
facet_wrap(~place, scales = "free")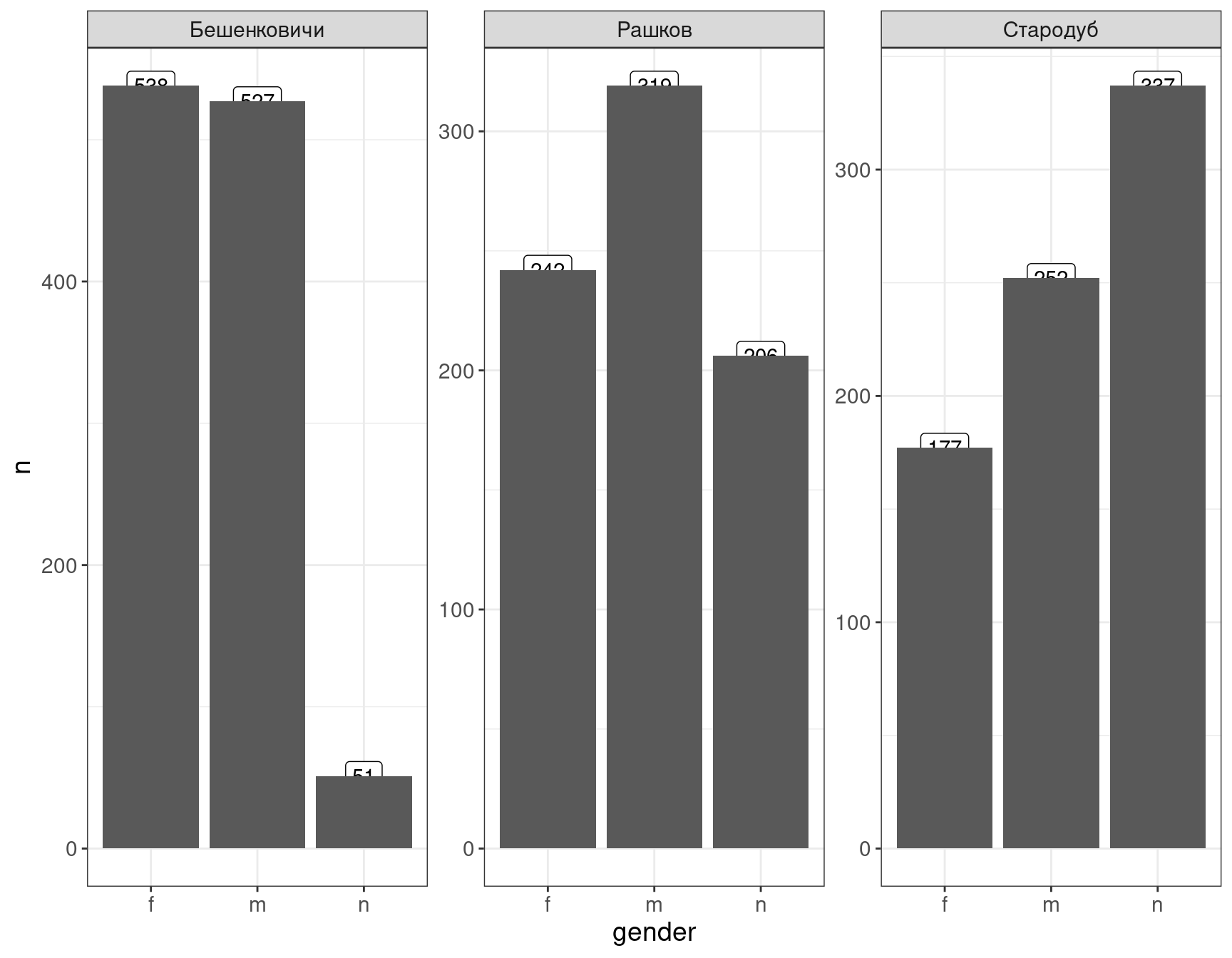
Попробуем вывести вместо абсолютных значений доли. Для этого надо будет вспомнить комбинацию group_by() %>% summurise() из предыдущего раздела:
df %>%
count(gender, place) %>%
group_by(place) %>%
mutate(ratio = n/sum(n),
ratio = round(ratio, 3)) %>% # округлим до 3 знаков после запятой
ggplot()+
aes(x = gender, y = n, label = ratio)+
geom_col()+
geom_label()+
facet_wrap(~place, scales = "free")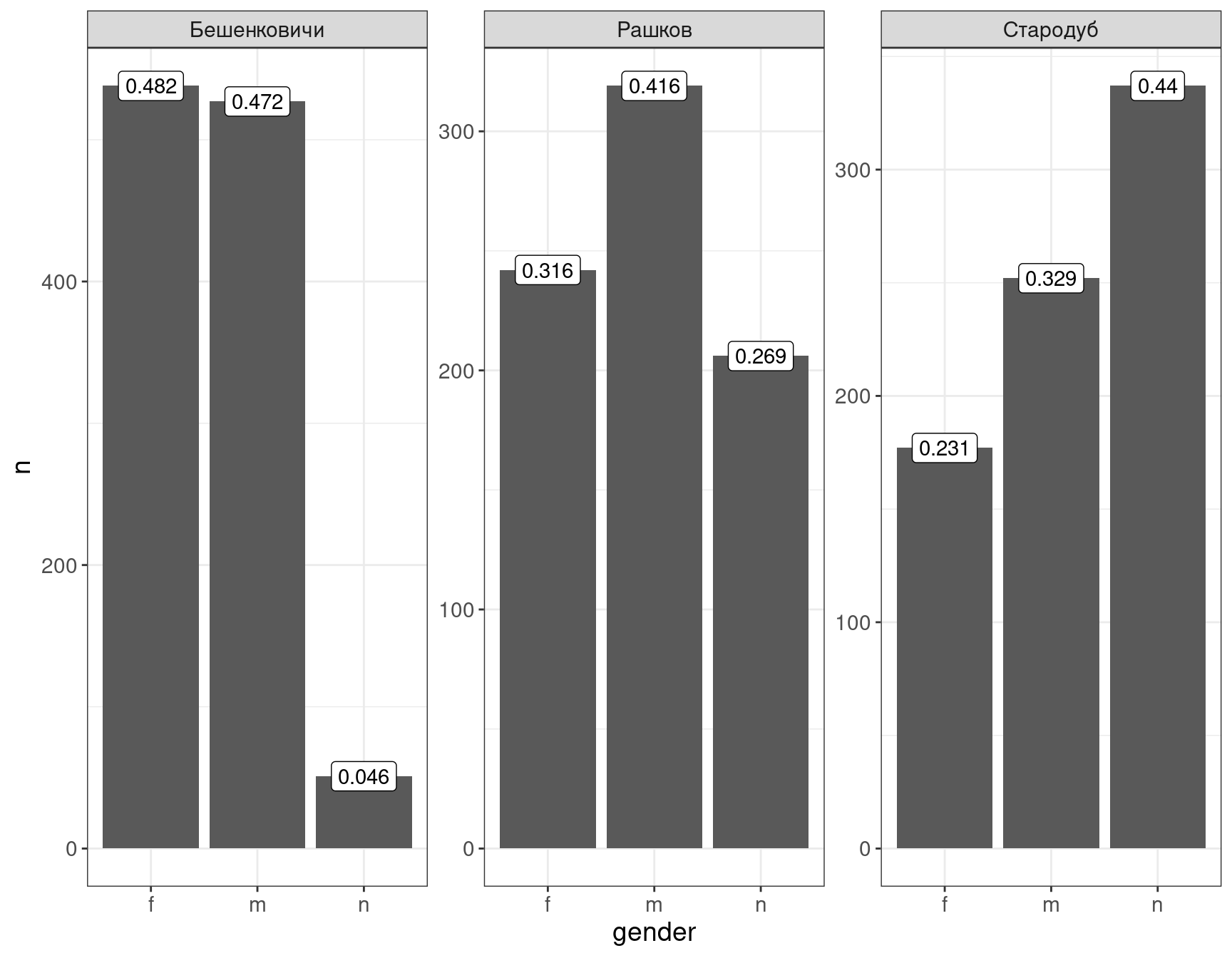
3.3 Сase studies
3.3.1 Гендерное распределение усопших
Посмотрим на распределение надгробий во времени:
df %>%
filter(!is.na(year)) %>%
ggplot()+
aes(year, fill = gender)+
geom_histogram()+
labs(x = "", y = "количество захоронений")+
facet_wrap(~place, scales = "free_y", nrow = 3)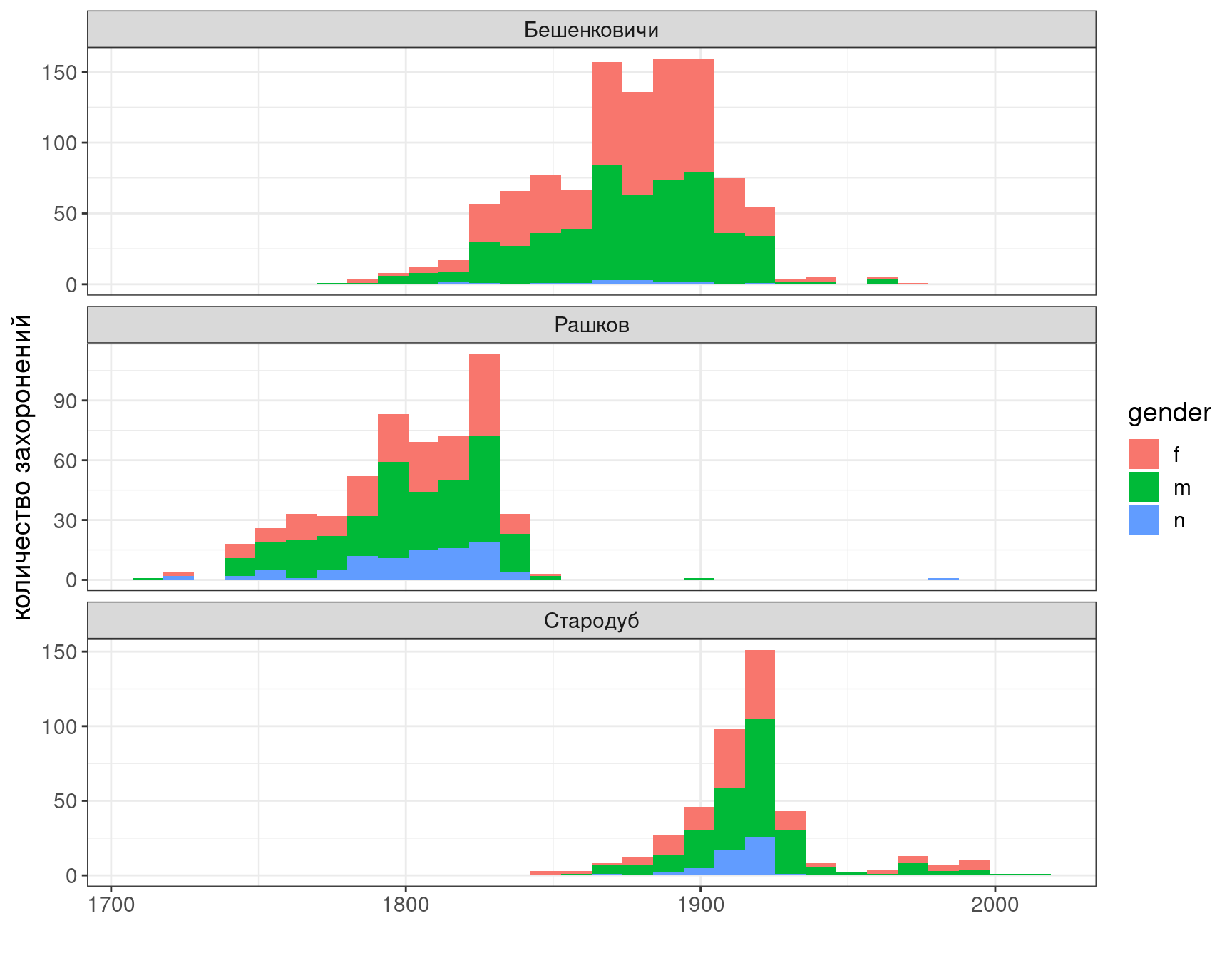
df %>%
filter(!is.na(year)) %>%
arrange(year) %>%
group_by(gender) %>%
mutate(value = 1,
sum = cumsum(value)) %>%
ggplot()+
aes(year, sum, color = gender)+
geom_point()+
geom_line()+
labs(x = "", y = "кумулятивное количество захоронений")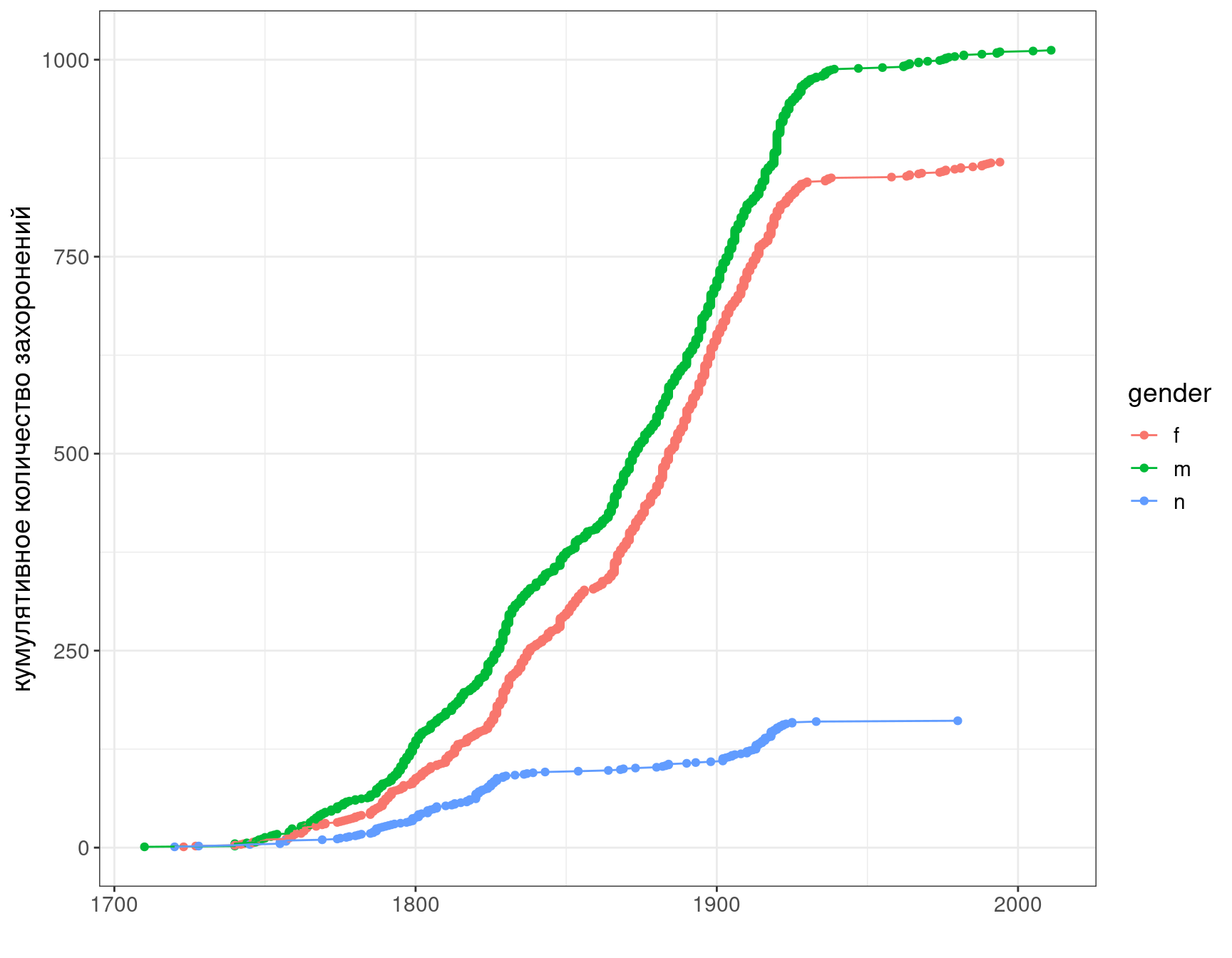
Какой вывод можно сделать на основании этого графика?
df %>%
filter(!is.na(year)) %>%
arrange(year) %>%
group_by(place, gender) %>%
mutate(value = 1,
sum = cumsum(value)) %>%
ggplot()+
aes(year, sum, color = gender)+
geom_point()+
geom_line()+
facet_wrap(~place, scales = "free_y", nrow = 3)+
labs(x = "", y = "кумулятивное количество захоронений")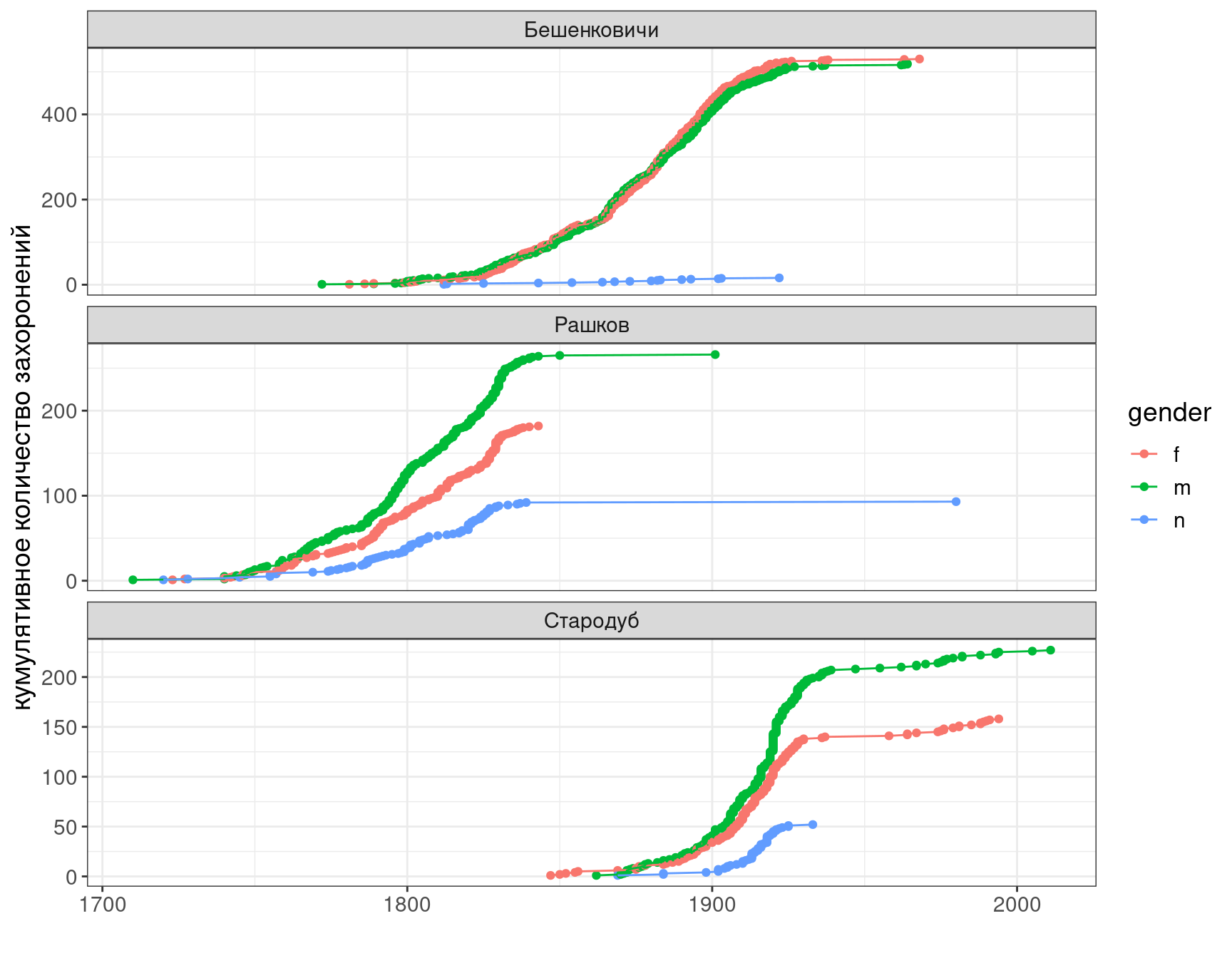
Какой вывод можно сделать на основании этого графика?
3.3.2 Распределение мучеников
df %>%
filter(place == "Рашков") %>%
mutate(kadosh = str_detect(tags, "кадош"),
kadosh = ifelse(is.na(kadosh), FALSE, kadosh)) %>%
ggplot()+
aes(x = year, fill = kadosh)+
geom_histogram()+
labs(x = "год", y = "количество захоронений")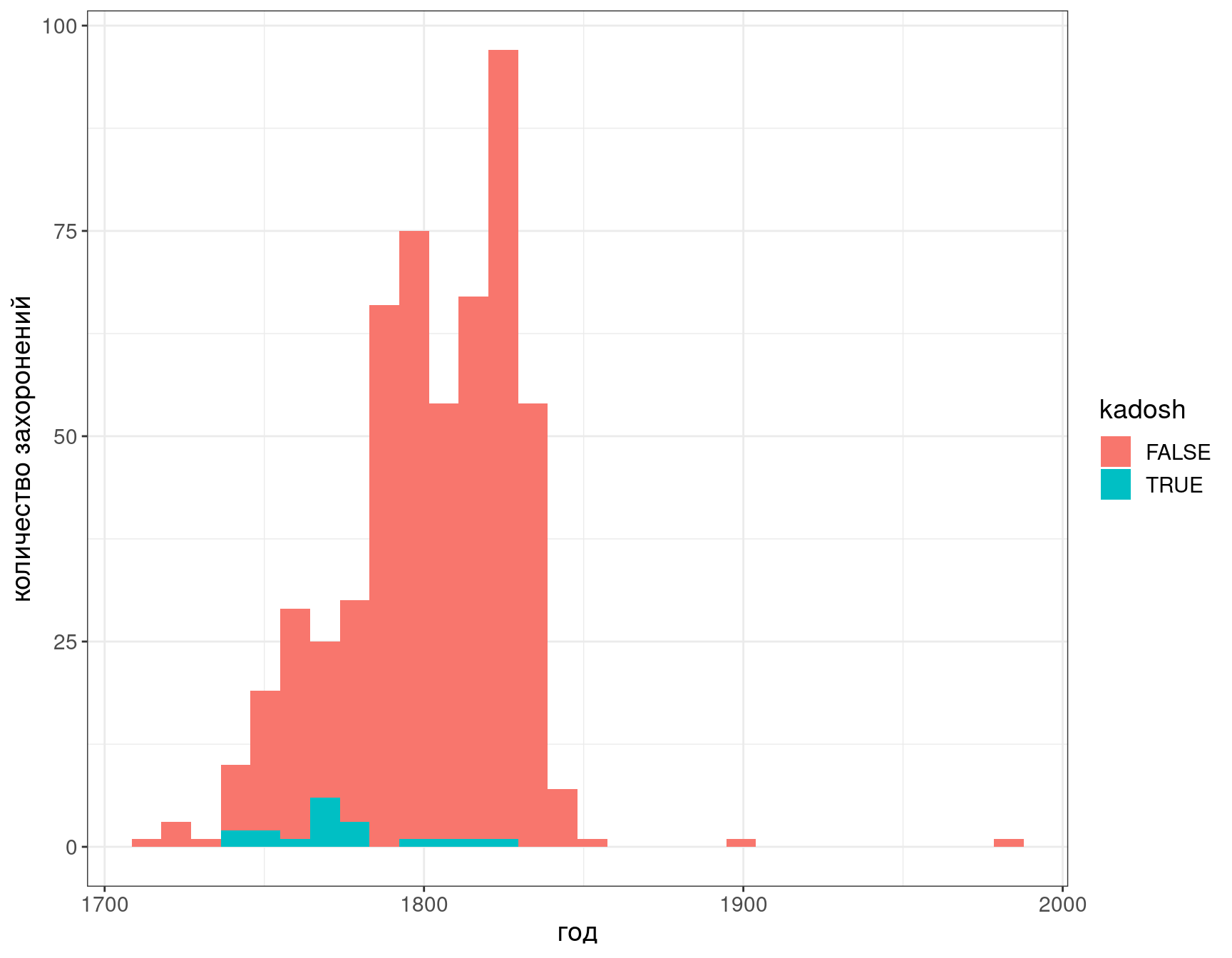
3.3.3 Распределение некоторых имен во времени
Возьмем наш датасет и выясним 10 самых популярных мужских и женских имен:
df %>%
filter(!is.na(name),
gender != "n") %>%
mutate(name = str_split(name, " ")) %>%
unnest_longer(name) %>%
count(name, gender, sort = TRUE) %>%
group_by(gender) %>%
top_n(10) %>%
ungroup() %>%
mutate(name = fct_reorder(name, n)) %>%
ggplot()+
aes(n, name)+
geom_col()+
facet_wrap(~gender, scales = "free")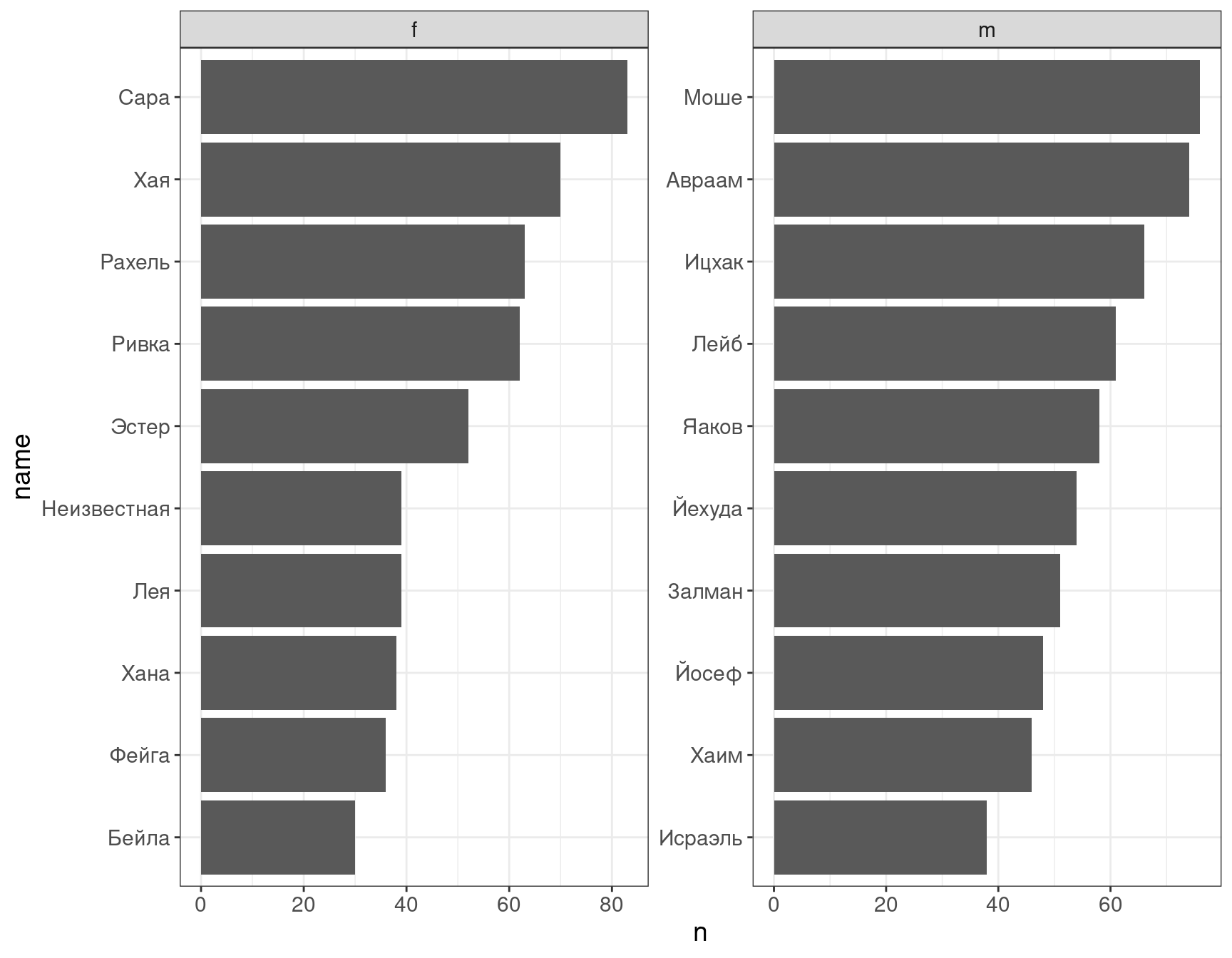
Мы также можем посмотреть на распределение в каждом населенном пункте:
library(tidytext) # этот пакет нужен для функции reorder_within()
df %>%
filter(!is.na(name),
gender != "n") %>%
mutate(name = str_split(name, " ")) %>%
unnest_longer(name) %>%
count(name, gender, place, sort = TRUE) %>%
group_by(place, gender) %>%
top_n(10) %>%
ungroup() %>%
mutate(name = reorder_within(name, by = n, within = place)) %>%
ggplot()+
aes(n, name)+
geom_col()+
facet_wrap(gender~place, scales = "free")+
scale_y_reordered()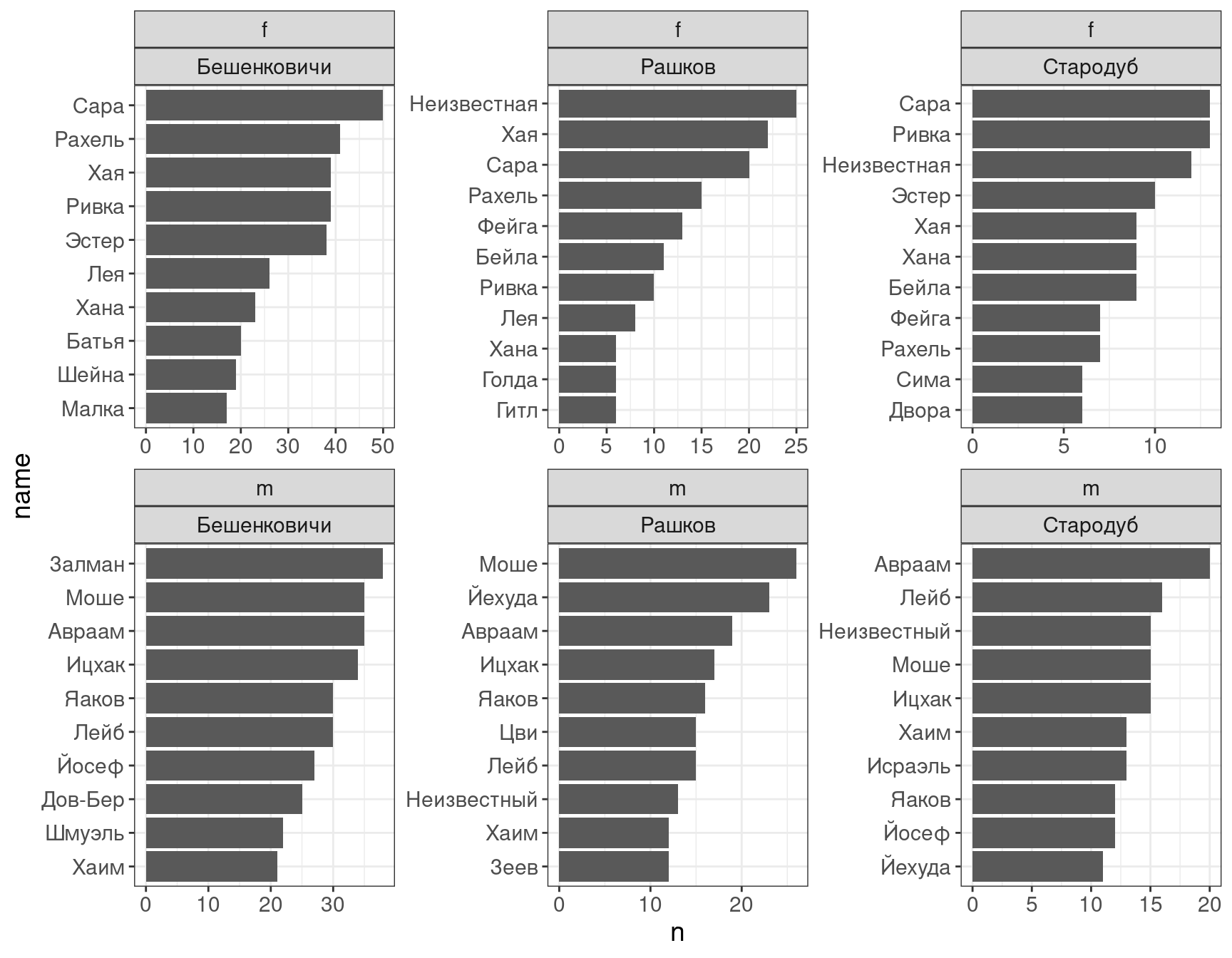
Попробуем посмотреть, как эти имена распределены во времени. Для начала создадим датасет с самыми популярными именами:
df %>%
filter(!is.na(name),
gender != "n") %>%
mutate(name = str_split(name, " ")) %>%
unnest_longer(name) %>%
count(name, gender, sort = TRUE) %>%
group_by(gender) %>%
top_n(3) %>%
pull(name) ->
popular_names
popular_names## [1] "Сара" "Моше" "Авраам" "Хая" "Ицхак" "Рахель"df %>%
filter(!is.na(name),
!is.na(year),
gender != "n") %>%
mutate(name = str_split(name, " ")) %>%
unnest_longer(name) %>%
mutate(name = ifelse(name %in% popular_names, name, "другие")) %>%
ggplot()+
aes(year, fill = name)+
geom_histogram()+
facet_wrap(gender~place, scales = "free_y", nrow = 2)+
labs(x = "", y = "количество захоронений")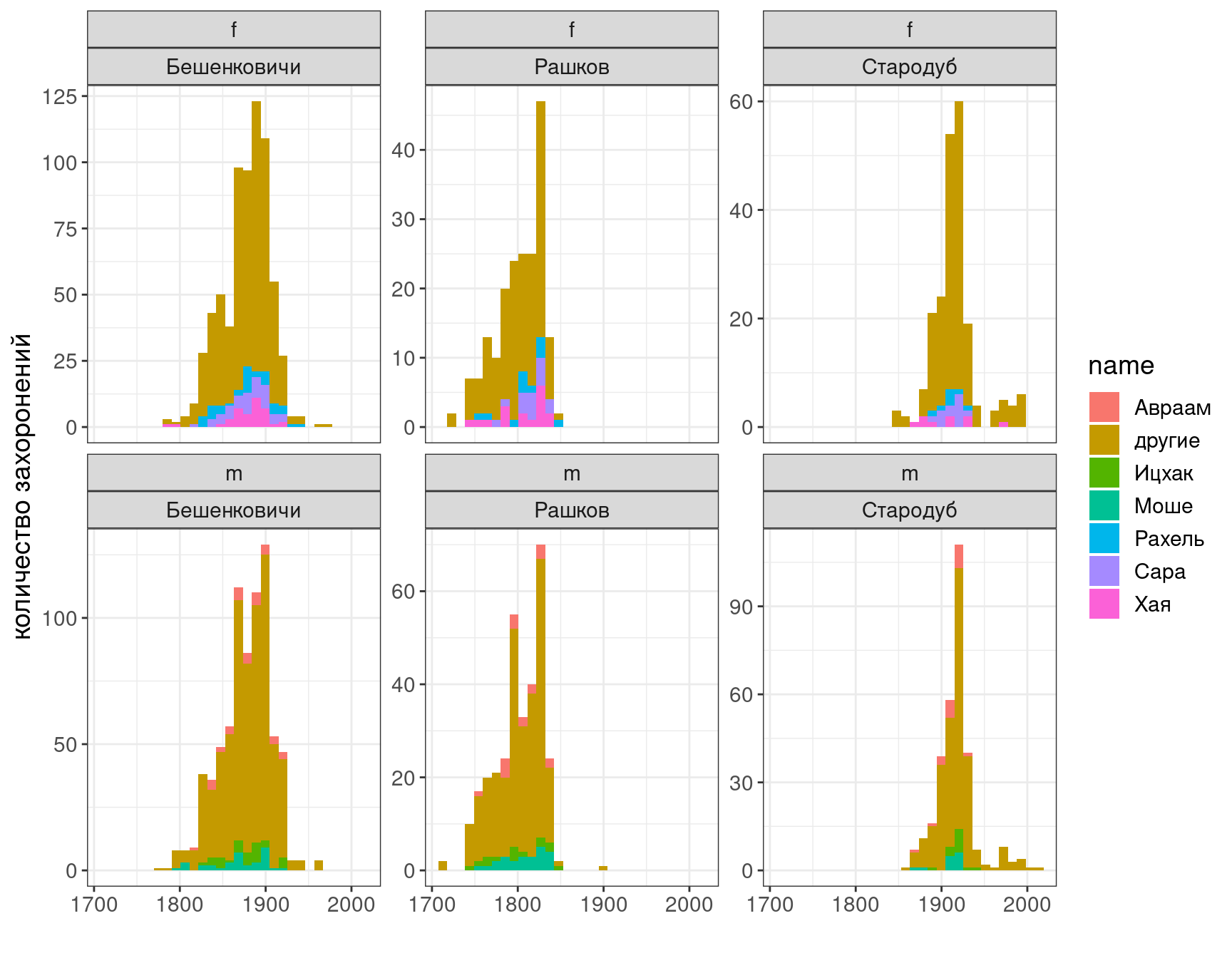
df %>%
filter(!is.na(name),
!is.na(year),
gender != "n") %>%
mutate(name = str_split(name, " ")) %>%
unnest_longer(name) %>%
filter(name %in% popular_names) %>%
arrange(year) %>%
mutate(value = 1) %>%
group_by(place, name) %>%
mutate(sum = cumsum(value)) %>%
ggplot()+
aes(year, sum, color = name)+
geom_point()+
geom_line()+
facet_grid(gender~place, scales = "free")+
labs(x = "", y = "количество захоронений")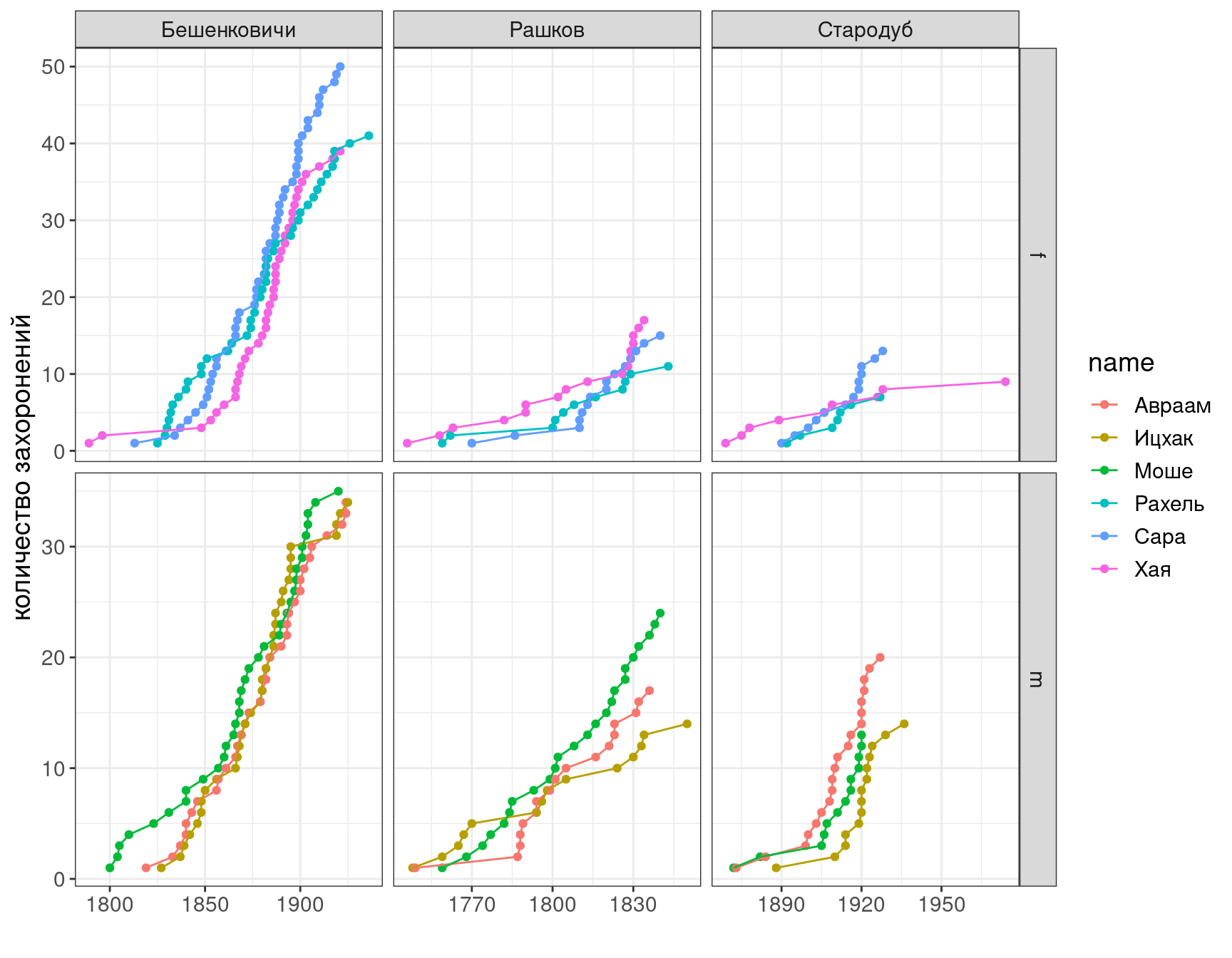
Какую разницу вы видите между разными населенными пунктами?