install.packages("stringi")
library(tidyverse)
library(stringi)4 Работа со строками
4.1 Работа со строками в R
Для работы со строками можно использовать:
- базовый R
- пакет
stringr(частьtidyverse) - пакет
stringi– отдельный пакет, так что не забудьте его установить:
Мы будем пользоваться в основном пакетами stingr и stringi, так как они в большинстве случаях удобнее. К счастью, функции этих пакетов легко отличить от остальных: функции пакета stringr всегда начинаются с str_, а функции пакета stringi — c stri_.
Существует cheat sheet по stringr.
4.2 Как получить строку?
- следите за кавычками
"the quick brown fox jumps over the lazy dog"[1] "the quick brown fox jumps over the lazy dog"'the quick brown fox jumps over the lazy dog'[1] "the quick brown fox jumps over the lazy dog""the quick 'brown' fox jumps over the lazy dog"[1] "the quick 'brown' fox jumps over the lazy dog"'the quick "brown" fox jumps over the lazy dog'[1] "the quick \"brown\" fox jumps over the lazy dog""the quick \"brown\" fox jumps over the lazy dog"[1] "the quick \"brown\" fox jumps over the lazy dog"Так как бэкслеш экранирует кавычку, если Вы хотите вставить бэкслеш в строку, придется поставить два бэкслеша.
"the quick \"brown\" \\ fox jumps over the lazy dog"[1] "the quick \"brown\" \\ fox jumps over the lazy dog"Обычная печать RStudio может прятать происходящее, так что используйте функцию str_view(), чтобы посмотреть содержимое:
str_view("the quick \"brown\" \\ fox jumps over the lazy dog")[1] │ the quick "brown" \ fox jumps over the lazy dog- пустая строка
""[1] ""''[1] ""character(3)[1] "" "" ""- преобразование
typeof(4:7)[1] "integer"as.character(4:7)[1] "4" "5" "6" "7"- встроенные векторы
letters [1] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l" "m" "n" "o" "p" "q" "r" "s"
[20] "t" "u" "v" "w" "x" "y" "z"LETTERS [1] "A" "B" "C" "D" "E" "F" "G" "H" "I" "J" "K" "L" "M" "N" "O" "P" "Q" "R" "S"
[20] "T" "U" "V" "W" "X" "Y" "Z"month.name [1] "January" "February" "March" "April" "May" "June"
[7] "July" "August" "September" "October" "November" "December" - cоздание рандомных строк
set.seed(42)
stri_rand_strings(n = 10, length = 5:14) [1] "uwHpd" "Wj8ehS" "ivFSwy7" "TYu8zw5V"
[5] "OuRpjoOg0" "p0CubNR2yQ" "xtdycKLOm2k" "fAGVfylZqBGp"
[9] "gE28DTCi0NV0a" "9MemYE55If0Cvv"- перемешивает символы внутри строки
stri_rand_shuffle("любя, съешь щипцы, — вздохнёт мэр, — кайф жгуч")[1] ",цо м,пюзгу сл аиъ—в кжряд,ыщьчебэн х—штё фй"stri_rand_shuffle(month.name) [1] "aJayunr" "eyrbraFu" "achMr" "Aplri" "ayM" "Jnue"
[7] "uJly" "usuAgt" "tpebermSe" "tOecrbo" "oeNembvr" "Dmceerbe" - псевдорандомный текст1
stri_rand_lipsum(nparagraphs = 2)Warning in stri_rand_lipsum(nparagraphs = 2): The 'nparagraphs' argument in
stri_rand_lipsum is a deprecated alias of 'n_paragraphs' and will be removed in
a future release of 'stringi'.[1] "Lorem ipsum dolor sit amet, donec sit nunc urna sed ultricies ac pharetra orci luctus iaculis, ac tincidunt cum. Neque eu semper at sociosqu hendrerit. Eu aliquet lacus, eu hendrerit donec aliquam eros. Risus nibh, quam in sit facilisi ipsum. Amet sem sed donec sed molestie scelerisque tincidunt. Nisl donec et facilisis interdum non sed dolor purus. In ipsum dignissim torquent velit nec aliquam pellentesque. Ac, adipiscing, neque et at torquent, vestibulum ullamcorper. Ad dictumst enim velit non nulla felis habitant. Egestas placerat consectetur, dictum nostra sed nec. Erat phasellus dolor libero aliquam viverra. Vestibulum leo et. Suscipit egestas in in montes, sapien gravida? Conubia purus varius ut nec feugiat."
[2] "Risus eleifend magnis neque diam, suspendisse ullamcorper nulla adipiscing malesuada massa, nisi sociosqu velit id et. Aliquam facilisis et aenean. Parturient vel ac in convallis, massa diam nibh. Nulla interdum cursus et. Natoque amet, ut praesent. Tortor ultrices a consectetur, augue natoque class faucibus? Ut sed arcu elementum magna. Dignissim ac facilisi quis ut nisl eu, massa." 4.3 Соединение и разделение строк
Соединенить строки можно используя функцию str_c(), в которую, как и в функции с(), можно перечислять элементы через запятую:
tibble(upper = rev(LETTERS), smaller = letters) |>
mutate(merge = str_c(upper, smaller))Кроме того, если хочется, можно использовать особенный разделитель, указав его в аргументе sep:
tibble(upper = rev(LETTERS), smaller = letters) |>
mutate(merge = str_c(upper, smaller, sep = "_"))Иногда хочется составить длинные выражения, которые будут перемежаться значениями из переменных, это можно сделать при помощи функции str_glue():
tibble(month_name = month.name,
month_abb = month.abb) |>
mutate(long_string = str_glue("The month {month_name} is abbreviated as {month_abb}"))В фигурных скобках выступают имена переменных, которые уже есть в датасете. Если Вы хотите вставить в свое длинное выражение фигурные скобки, можно написать их два раза:
tibble(month_name = month.name,
month_abb = month.abb) |>
mutate(long_string = str_glue("The {{month}} {month_name} is abbreviated as {month_abb}"))Для разделения строки на подстроки можно использовать функцию separate(). Это функция разносит разделенные элементы строки в соответствующие столбцы. У функции три обязательных аргумента: col — колонка, которую следует разделить, into — вектор названий новых столбцов, sep — разделитель.
tibble(upper = rev(LETTERS), smaller = letters) |>
mutate(merge = str_c(upper, smaller, sep = "_")) |>
separate(col = merge, into = c("column_1", "column_2"), sep = "_")Кроме того, есть инструмент str_split(), который позволяет разбивать строки на подстроки, но возвращает список.
str_split(month.name, "r")[[1]]
[1] "Janua" "y"
[[2]]
[1] "Feb" "ua" "y"
[[3]]
[1] "Ma" "ch"
[[4]]
[1] "Ap" "il"
[[5]]
[1] "May"
[[6]]
[1] "June"
[[7]]
[1] "July"
[[8]]
[1] "August"
[[9]]
[1] "Septembe" ""
[[10]]
[1] "Octobe" ""
[[11]]
[1] "Novembe" ""
[[12]]
[1] "Decembe" "" 4.4 Количество символов
4.4.1 Подсчет количества символов
tibble(mn = month.name) |>
mutate(n_charactars = str_count(mn))4.4.2 Подгонка количества символов
Можно обрезать строки, используя функцию str_trunc():
tibble(mn = month.name) |>
mutate(mn_new = str_trunc(mn, 6))Можно решить, с какой стороны обрезать, используя аргумент side:
tibble(mn = month.name) |>
mutate(mn_new = str_trunc(mn, 6, side = "left"))tibble(mn = month.name) |>
mutate(mn_new = str_trunc(mn, 6, side = "center"))Можно заменить многоточие, используя аргумент ellipsis:
tibble(mn = month.name) |>
mutate(mn_new = str_trunc(mn, 3, ellipsis = ""))Можно наоборот “раздуть” строку:
tibble(mn = month.name) |>
mutate(mn_new = str_pad(mn, 10))Опять же есть аргумент side:
tibble(mn = month.name) |>
mutate(mn_new = str_pad(mn, 10, side = "right"))Также можно выбрать, чем “раздувать строку”:
tibble(mn = month.name) |>
mutate(mn_new = str_pad(mn, 10, pad = "."))Кроме того бывает полезной функций str_squish(), которая убирает лишние пробелы в конце и начале строки, а также повторяющиеся пробелы между словами:
str_squish(" много пробелов не бывает ")[1] "много пробелов не бывает"4.5 Сортировка
Для сортировки существует str_sort():
unsorted_latin <- c("I", "♥", "N", "Y")
str_sort(unsorted_latin)[1] "♥" "I" "N" "Y"str_sort(unsorted_latin, locale = "lt")[1] "♥" "I" "Y" "N"unsorted_cyrillic <- c("я", "i", "ж")
str_sort(unsorted_cyrillic)[1] "i" "ж" "я"str_sort(unsorted_cyrillic, locale = "ru_UA")[1] "ж" "я" "i"Список локалей на компьютере можно посмотреть командой stringi::stri_locale_list(). Список всех локалей вообще приведен на этой странице. Еще полезные команды: stringi::stri_locale_info и stringi::stri_locale_set.
4.6 Поиск подстроки
Можно использовать функцию str_detect():
tibble(mn = month.name) |>
mutate(has_r = str_detect(mn, "r"))Кроме того, существует функция, которая возвращает индексы, а не значения TRUE/FALSE:
tibble(mn = month.name) |>
slice(str_which(month.name, "r"))Также можно посчитать количество вхождений какой-то подстроки:
tibble(mn = month.name) |>
mutate(has_r = str_count(mn, "r"))4.7 Изменение строк
4.7.1 Изменение регистра
latin <- "tHe QuIcK BrOwN fOx JuMpS OvEr ThE lAzY dOg"
cyrillic <- "лЮбЯ, сЪеШь ЩиПцЫ, — вЗдОхНёТ мЭр, — кАйФ жГуЧ"
str_to_upper(latin)[1] "THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG"str_to_lower(cyrillic)[1] "любя, съешь щипцы, — вздохнёт мэр, — кайф жгуч"str_to_title(latin)[1] "The Quick Brown Fox Jumps Over The Lazy Dog"str_to_sentence(latin)[1] "The quick brown fox jumps over the lazy dog"4.7.2 Выделение подстроки
Подстроку в строке можно выделить двумя способами: по индексам функцией str_sub(), и по подстроке функцией str_png().
tibble(mn = month.name) |>
mutate(mutate = str_sub(mn, start = 1, end = 2))tibble(mn = month.name) |>
mutate(mutate = str_extract(mn, "r"))По умолчанию функция str_extract() возвращает первое вхождение подстроки, соответствующей шаблону. Также существует функция str_extract_all(), которая возвращает все вхождения подстрок, соответствующих шаблону в виде объекта типа список.
str_extract_all(month.name, "r")[[1]]
[1] "r"
[[2]]
[1] "r" "r"
[[3]]
[1] "r"
[[4]]
[1] "r"
[[5]]
character(0)
[[6]]
character(0)
[[7]]
character(0)
[[8]]
character(0)
[[9]]
[1] "r"
[[10]]
[1] "r"
[[11]]
[1] "r"
[[12]]
[1] "r"4.7.3 Замена подстроки
Существует функция str_replace(), которая позволяет заменить одну подстроку в строке на другую:
tibble(mn = month.name) |>
mutate(mutate = str_replace(mn, "r", "R"))Как и другие функции, str_replace() делает лишь одну замену, чтобы заменить все вхождения подстроки следует использовать функцию str_replace_all():
tibble(mn = month.name) |>
mutate(mutate = str_replace_all(mn, "r", "R"))4.7.4 Удаление подстроки
Для удаления подстроки на основе шаблона используется функция str_remove() и str_remove_all()
tibble(month.name) |>
mutate(mutate = str_remove(month.name, "r"))tibble(month.name) |>
mutate(mutate = str_remove_all(month.name, "r"))4.7.5 Транслитерация строк
В пакете stringi существует достаточно много методов транслитераций строк, которые можно вывести командой stri_trans_list(). Вот пример использования некоторых из них:
stri_trans_general("stringi", "latin-cyrillic")[1] "стринги"stri_trans_general("сырники", "cyrillic-latin")[1] "syrniki"stri_trans_general("stringi", "latin-greek")[1] "στριγγι"stri_trans_general("stringi", "latin-armenian")[1] "ստրինգի"4.8 Регулярные выражения
Большинство функций из раздела об операциях над векторами (str_detect(), str_extract(), str_remove() и т. п.) имеют следующую структуру:
- строка, с которой работает функция
- образец (pattern)
Дальше мы будем использовать функцию str_view(), которая позволяет показывать выделенное образцом в исходной строке.
str_view("Я всегда путаю с и c", "c") # я ищу латинскую c[1] │ Я всегда путаю с и <c>4.8.1 Экранирование метасимволов
a <- "Всем известно, что 4$\\2 + 3$ * 5 = 17$? Да? Ну хорошо (а то я не был уверен). [|}^{|]"
str_view(a, "$")[1] │ Всем известно, что 4$\2 + 3$ * 5 = 17$? Да? Ну хорошо (а то я не был уверен). [|}^{|]<>str_view(a, "\\$")[1] │ Всем известно, что 4<$>\2 + 3<$> * 5 = 17<$>? Да? Ну хорошо (а то я не был уверен). [|}^{|]str_view(a, "\\.")[1] │ Всем известно, что 4$\2 + 3$ * 5 = 17$? Да? Ну хорошо (а то я не был уверен)<.> [|}^{|]str_view(a, "\\*")[1] │ Всем известно, что 4$\2 + 3$ <*> 5 = 17$? Да? Ну хорошо (а то я не был уверен). [|}^{|]str_view(a, "\\+")[1] │ Всем известно, что 4$\2 <+> 3$ * 5 = 17$? Да? Ну хорошо (а то я не был уверен). [|}^{|]str_view(a, "\\?")[1] │ Всем известно, что 4$\2 + 3$ * 5 = 17$<?> Да<?> Ну хорошо (а то я не был уверен). [|}^{|]str_view(a, "\\(")[1] │ Всем известно, что 4$\2 + 3$ * 5 = 17$? Да? Ну хорошо <(>а то я не был уверен). [|}^{|]str_view(a, "\\)")[1] │ Всем известно, что 4$\2 + 3$ * 5 = 17$? Да? Ну хорошо (а то я не был уверен<)>. [|}^{|]str_view(a, "\\|")[1] │ Всем известно, что 4$\2 + 3$ * 5 = 17$? Да? Ну хорошо (а то я не был уверен). [<|>}^{<|>]str_view(a, "\\^")[1] │ Всем известно, что 4$\2 + 3$ * 5 = 17$? Да? Ну хорошо (а то я не был уверен). [|}<^>{|]str_view(a, "\\[")[1] │ Всем известно, что 4$\2 + 3$ * 5 = 17$? Да? Ну хорошо (а то я не был уверен). <[>|}^{|]str_view(a, "\\]")[1] │ Всем известно, что 4$\2 + 3$ * 5 = 17$? Да? Ну хорошо (а то я не был уверен). [|}^{|<]>str_view(a, "\\{")[1] │ Всем известно, что 4$\2 + 3$ * 5 = 17$? Да? Ну хорошо (а то я не был уверен). [|}^<{>|]str_view(a, "\\}")[1] │ Всем известно, что 4$\2 + 3$ * 5 = 17$? Да? Ну хорошо (а то я не был уверен). [|<}>^{|]str_view(a, "\\\\")[1] │ Всем известно, что 4$<\>2 + 3$ * 5 = 17$? Да? Ну хорошо (а то я не был уверен). [|}^{|]4.8.2 Классы знаков
\\d– цифры.\\D– не цифры.
str_view("два 15 42. 42 15. 37 08 5. 20 20 20!", "\\d")[1] │ два <1><5> <4><2>. <4><2> <1><5>. <3><7> <0><8> <5>. <2><0> <2><0> <2><0>!str_view("два 15 42. 42 15. 37 08 5. 20 20 20!", "\\D")[1] │ <д><в><а>< >15< >42<.>< >42< >15<.>< >37< >08< >5<.>< >20< >20< >20<!>\\s– пробелы.\\S– не пробелы.
str_view("два 15 42. 42 15. 37 08 5. 20 20 20!", "\\s")[1] │ два< >15< >42.< >42< >15.< >37< >08< >5.< >20< >20< >20!str_view("два 15 42. 42 15. 37 08 5. 20 20 20!", "\\S")[1] │ <д><в><а> <1><5> <4><2><.> <4><2> <1><5><.> <3><7> <0><8> <5><.> <2><0> <2><0> <2><0><!>\\w– не пробелы и не знаки препинания.\\W– пробелы и знаки препинания.
str_view("два 15 42. 42 15. 37 08 5. 20 20 20!", "\\w")[1] │ <д><в><а> <1><5> <4><2>. <4><2> <1><5>. <3><7> <0><8> <5>. <2><0> <2><0> <2><0>!str_view("два 15 42. 42 15. 37 08 5. 20 20 20!", "\\W")[1] │ два< >15< >42<.>< >42< >15<.>< >37< >08< >5<.>< >20< >20< >20<!>- произвольная группа символов и обратная к ней
str_view("Умей мечтать, не став рабом мечтанья", "[оауиыэёеяю]")[1] │ Ум<е>й м<е>чт<а>ть, н<е> ст<а>в р<а>б<о>м м<е>чт<а>нь<я>str_view("И мыслить, мысли не обожествив", "[^оауиыэёеяю]")[1] │ <И>< ><м>ы<с><л>и<т><ь><,>< ><м>ы<с><л>и< ><н>е< >о<б>о<ж>е<с><т><в>и<в>- встроенные группы символов
str_view("два 15 42. 42 15. 37 08 5. 20 20 20!", "[0-9]")[1] │ два <1><5> <4><2>. <4><2> <1><5>. <3><7> <0><8> <5>. <2><0> <2><0> <2><0>!str_view("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "[а-я]")[1] │ К<а><р><л> <у> К<л><а><р><ы> <у><к><р><а><л> <к><о><р><а><л><л><ы>, <а> К<л><а><р><а> <у> К<а><р><л><а> <у><к><р><а><л><а> <к><л><а><р><н><е><т>str_view("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "[А-Я]")[1] │ <К>арл у <К>лары украл кораллы, а <К>лара у <К>арла украла кларнетstr_view("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "[А-я]")[1] │ <К><а><р><л> <у> <К><л><а><р><ы> <у><к><р><а><л> <к><о><р><а><л><л><ы>, <а> <К><л><а><р><а> <у> <К><а><р><л><а> <у><к><р><а><л><а> <к><л><а><р><н><е><т>str_view("The quick brown Fox jumps over the lazy Dog", "[a-z]")[1] │ T<h><e> <q><u><i><c><k> <b><r><o><w><n> F<o><x> <j><u><m><p><s> <o><v><e><r> <t><h><e> <l><a><z><y> D<o><g>str_view("два 15 42. 42 15. 37 08 5. 20 20 20!", "[^0-9]")[1] │ <д><в><а>< >15< >42<.>< >42< >15<.>< >37< >08< >5<.>< >20< >20< >20<!>- выбор из нескольких групп
str_view("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "лар|рал|арл")[1] │ К<арл> у К<лар>ы ук<рал> ко<рал>лы, а К<лар>а у К<арл>а ук<рал>а к<лар>нет- произвольный символ
str_view("Везет Сенька Саньку с Сонькой на санках. Санки скок, Сеньку с ног, Соньку в лоб, все — в сугроб", "[Сс].н")[1] │ Везет <Сен>ька <Сан>ьку с <Сон>ькой на <сан>ках. <Сан>ки скок, <Сен>ьку <с н>ог, <Сон>ьку в лоб, все — в сугроб- знак начала и конца строки
str_view("от топота копыт пыль по полю летит.", "^о")[1] │ <о>т топота копыт пыль по полю летит.str_view("У ежа — ежата, у ужа — ужата", "жата$")[1] │ У ежа — ежата, у ужа — у<жата>- есть еще другие группы и другие обозначения уже приведенных групп, см.
?regex
4.8.3 Квантификация
?— ноль или один раз
str_view("хорошее длинношеее животное", "еее?")[1] │ хорош<ее> длиннош<еее> животное*— ноль и более раз
str_view("хорошее длинношеее животное", "ее*")[1] │ хорош<ее> длиннош<еее> животно<е>+— один и более раз
str_view("хорошее длинношеее животное", "е+")[1] │ хорош<ее> длиннош<еее> животно<е>{n}—nраз
str_view("хорошее длинношеее животное", "е{2}")[1] │ хорош<ее> длиннош<ее>е животное{n,}—nраз и более
str_view("хорошее длинношеее животное", "е{1,}")[1] │ хорош<ее> длиннош<еее> животно<е>{n,m}— отnдоm. Отсутствие пробела важно:{1,2}— правильно,{1,␣2}— неправильно.
str_view("хорошее длинношеее животное", "е{2,3}")[1] │ хорош<ее> длиннош<еее> животное- группировка символов
str_view("Пушкиновед, Лермонтовед, Лермонтововед", "(ов)+")[1] │ Пушкин<ов>ед, Лермонт<ов>ед, Лермонт<овов>едstr_view("беловатый, розоватый, розововатый", "(ов)+")[1] │ бел<ов>атый, роз<ов>атый, роз<овов>атый- жадный vs. нежадный алоритмы
str_view("Пушкиновед, Лермонтовед, Лермонтововед", "в.*ед")[1] │ Пушкино<вед, Лермонтовед, Лермонтововед>str_view("Пушкиновед, Лермонтовед, Лермонтововед", "в.*?ед")[1] │ Пушкино<вед>, Лермонто<вед>, Лермонто<вовед>4.8.4 Позиционная проверка (look arounds)
Позиционная проверка – выглядит достаточно непоследовательно даже в свете остальных регулярных выражений.
Давайте найдем все а перед р:
str_view("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "а(?=р)")[1] │ К<а>рл у Кл<а>ры украл кораллы, а Кл<а>ра у К<а>рла украла кл<а>рнетА теперь все а перед р или л:
str_view("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "а(?=[рл])")[1] │ К<а>рл у Кл<а>ры укр<а>л кор<а>ллы, а Кл<а>ра у К<а>рла укр<а>ла кл<а>рнетДавайте найдем все а после р
str_view("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "(?<=р)а")[1] │ Карл у Клары укр<а>л кор<а>ллы, а Клар<а> у Карла укр<а>ла кларнетА теперь все а после р или л:
str_view("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "(?<=[рл])а")[1] │ Карл у Кл<а>ры укр<а>л кор<а>ллы, а Кл<а>р<а> у Карл<а> укр<а>л<а> кл<а>рнетТакже у этих выражений есть формы с отрицанием. Давайте найдем все р не перед а:
str_view("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "р(?!а)")[1] │ Ка<р>л у Кла<р>ы украл кораллы, а Клара у Ка<р>ла украла кла<р>нетА теперь все р не после а:
str_view("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "(?<!а)р")[1] │ Карл у Клары ук<р>ал ко<р>аллы, а Клара у Карла ук<р>ала кларнетЗапомнить с ходу это достаточно сложно, так что подсматривайте сюда:
knitr::include_graphics("images/04_01_lookarounds.png")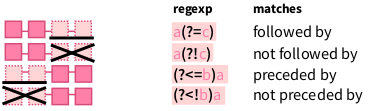

Lorem ipsum — классический текст-заполнитель на основе трактата Марка Туллия Цицерона “О пределах добра и зла”. Его используют, чтобы посмотреть, как страница смотрится, когда заполнена текстом↩︎