Регрессионный анализ
Для тех, кто хочет следить за кодом, вот загруженные библиотеки:
library(tidyverse)
library(lme4)
library(lmerTest)
# это стиль для ggplot (можно игнорировать эту команду)
theme_set(theme_bw()+
theme(text = element_text(size = 16))) В качестве примера я использую данные из работы [Huttenlocher, Vasilyeva, Cymerman, Levine 2002], в которой авторы проанализировали 46 пар матерей и детей (возрастом от 47 до 59 месяцев, средний возраст … а пасчитайте сами!). Они записали и затранскрибировали 2 часа каждого дня ребенка. Потом они посчитали количество именных групп на предложение у матерей и ребенка. Данные можно скачать командой: np_acquisition <- read.csv("https://raw.githubusercontent.com/agricolamz/2019_PhonDan/master/data/Huttenlocher.csv")
np_acquisition <- read.csv("https://raw.githubusercontent.com/agricolamz/2019_PhonDan/master/data/Huttenlocher.csv")
np_acquisition1 Линейная регрессия
1.1 Простой случай
Представим себе, что мы хотим научиться предсказывать количество именных групп у ребенка на основании количества именных групп у матери.
np_acquisition %>%
ggplot(aes(mother, child))+
geom_point()+
labs(caption = "данные [Huttenlocher, Vasilyeva, Cymerman, Levine 2002]")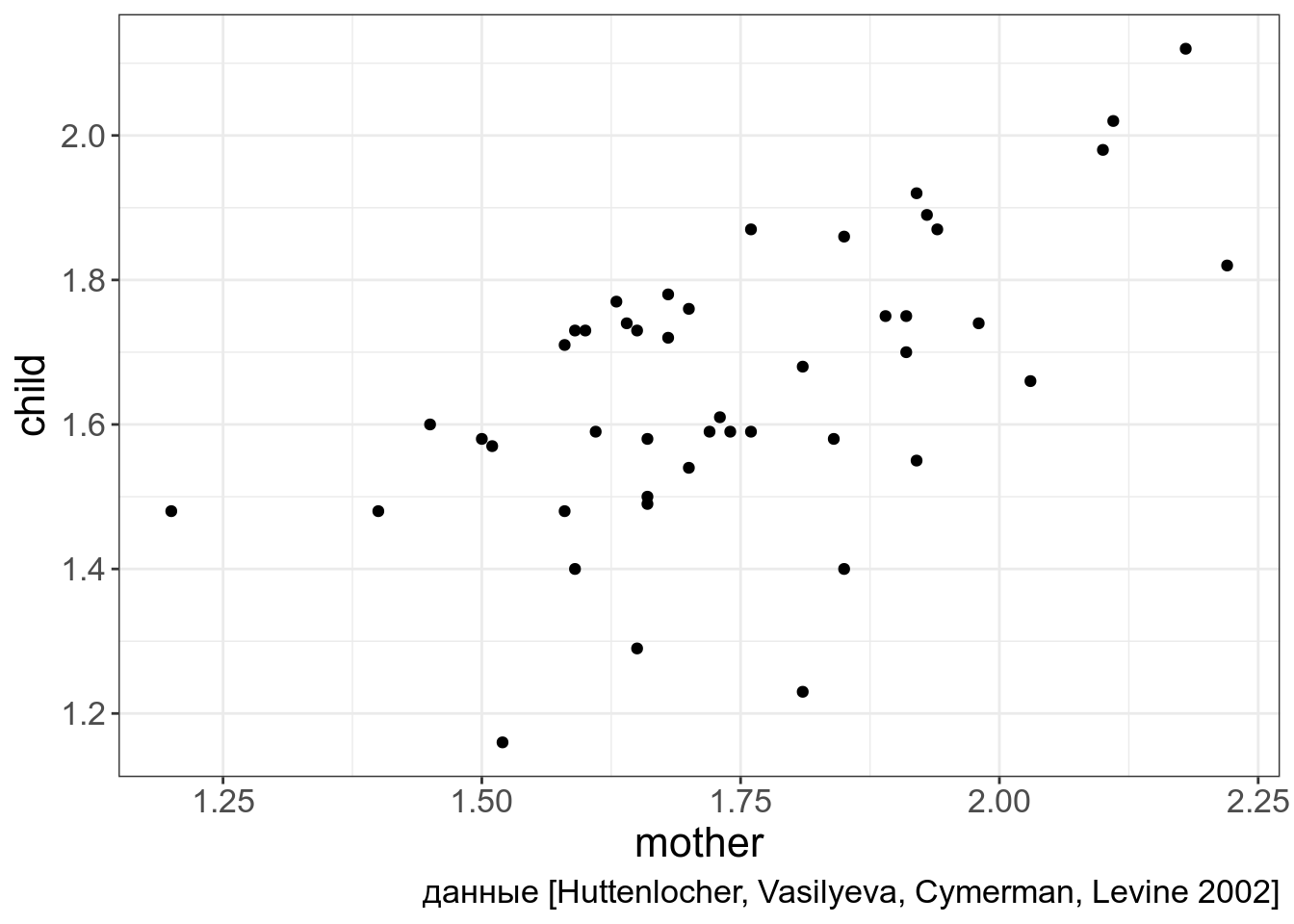
Простейшая статистическая модель будет выглядеть следующим образом:
\[y_i = \beta_0 + e_i\]
- \(y_i\) — множество ответов
- \(\beta_0\) — некоторая константа
- \(e_i\) — остатки/ошибки регресиионной модели
Так как любая регрессионная модель стремиться улучшить свои предсказания, лучшим коэфециентом \(k\) будет тот, при котором \(e_i\) будут минимальны. В нашей простой модели — это понятное дело будет среднее:
np_acquisition %>%
ggplot(aes(mother, child))+
geom_hline(aes(yintercept = (mean(mother))), color = "blue")+
geom_point()+
labs(caption = "данные [Huttenlocher, Vasilyeva, Cymerman, Levine 2002]")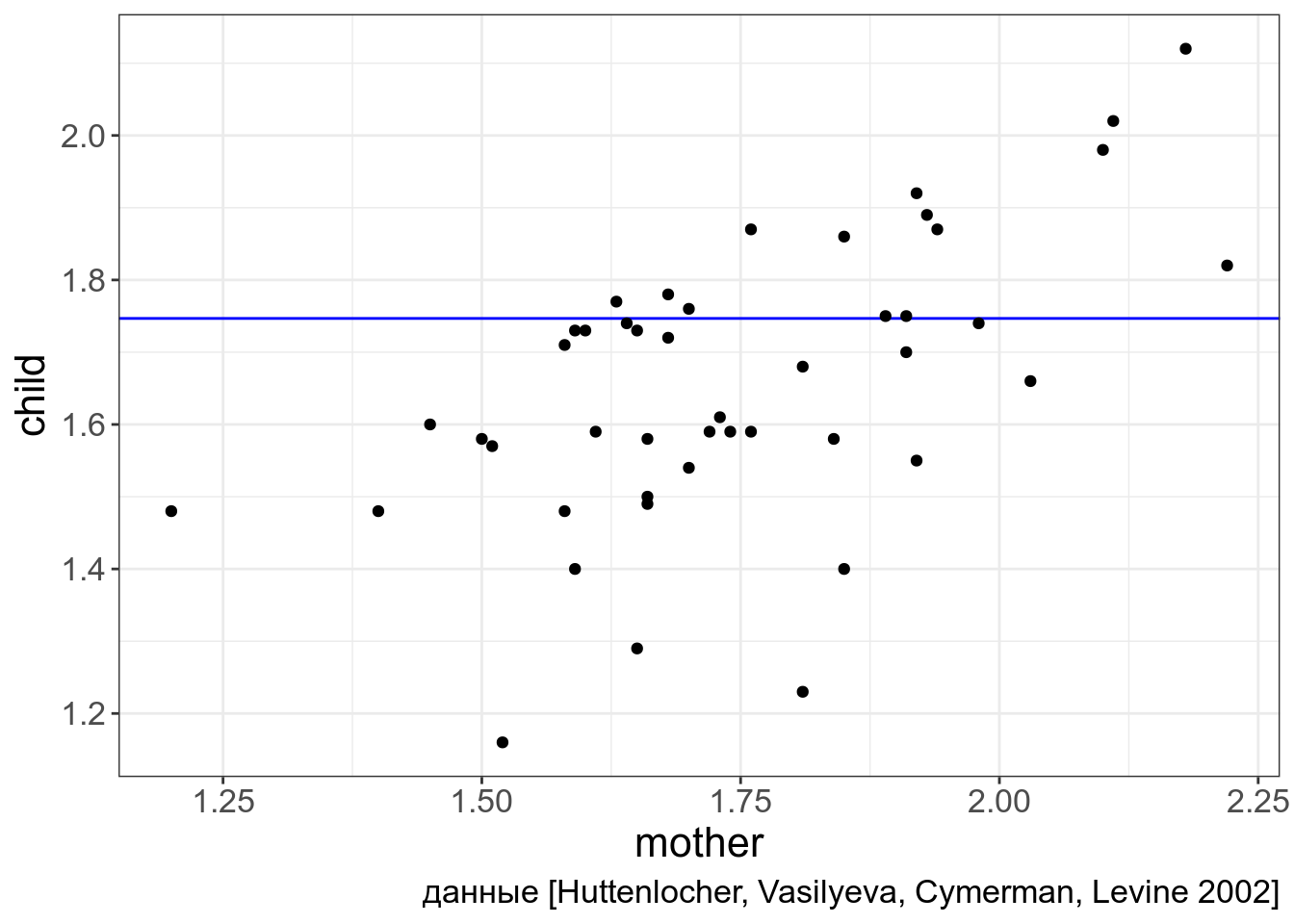
\[child_j = mean(child) + e_j\]
Если мы хотим включить переменную mother в нашу регрессию, то мы это можем сделать используя формулу прямой:
\[y_j = \beta_0 + \beta_1\times x_j + e_j\]
np_acquisition %>%
ggplot(aes(mother, child))+
geom_smooth(method = "lm", se = FALSE)+
geom_point()+
labs(caption = "данные [Huttenlocher, Vasilyeva, Cymerman, Levine 2002]")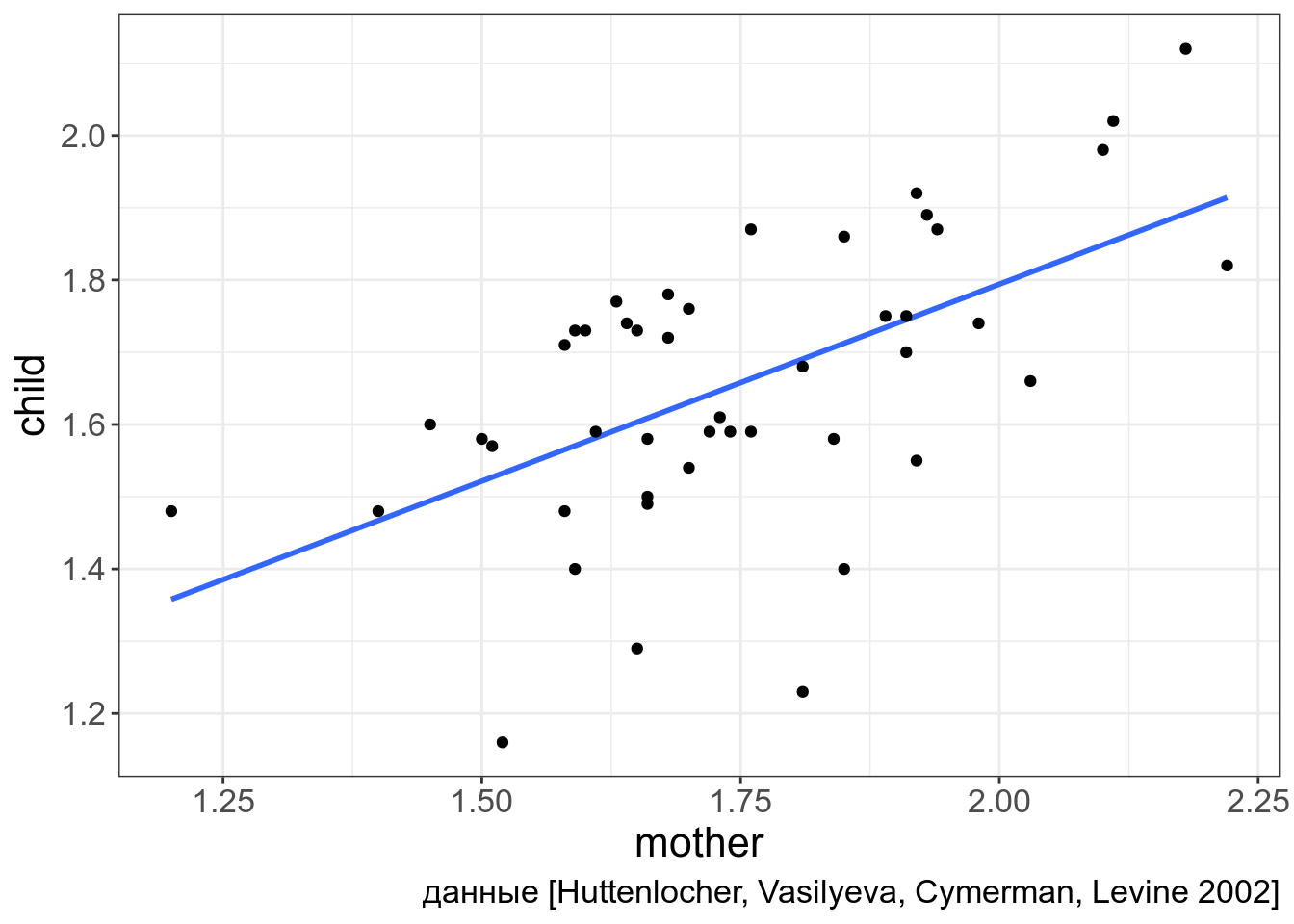
Т. е. формула применительно к нашим данным выглядит следующим образом:
\[child_j = \beta_0 + \beta_1\times mother_j + e_j\]
В R это делается при помощи функции lm:
##
## Call:
## lm(formula = child ~ mother, data = np_acquisition)
##
## Coefficients:
## (Intercept) mother
## 0.7038 0.5452Теперь мы можем полностью записать формулу:
\[child_j = 0.7038 + 0.5452 \times mother_j + e_j\]
Результаты регрессии можно записать в переменную, а потом посмотреть даже статистическую значимость каждого из полученных коэффициентов:
##
## Call:
## lm(formula = child ~ mother, data = np_acquisition)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.46058 -0.08925 0.01071 0.13333 0.22770
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.7038 0.2051 3.432 0.00132 **
## mother 0.5452 0.1166 4.676 2.79e-05 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.1627 on 44 degrees of freedom
## Multiple R-squared: 0.332, Adjusted R-squared: 0.3168
## F-statistic: 21.86 on 1 and 44 DF, p-value: 2.789e-05На что смотреть:
- на статистическую значимость коэффициентов
- Adjusted R-квадрат
- на p-value всей модели
Теперь мы можем предсказывать! Правдо не обязательно все руками вбивать в формулу, например, для значения mother = 1.69:
## 1
## 1.625153🤔 Скачайте датасет с параметрами рассказов А. П. Чехова: количество уникальных слов, длина рассказа. Постройте регрессионную модель предсказывающую количество уникальных слов на основе длины рассказа. Какой получился интерсепт (с точностью до 4 знаков после запятой)?
🤔 Какой получился коэффициент при переменной длина рассказа (с точностью до 4 знаков после запятой)?
🤔 Что полученная модель предсказывает для рассказа размером 855 слов (с точностью до 4 знаков после запятой)?
1.2 Категориальные переменные
А что если одна из переменных у нас категориальная? В таком случае вводятся dummy-переменные. Рассмотрим наш вчерашний пример из [Hau 2007]:
homo <- read.csv("https://raw.githubusercontent.com/agricolamz/2019_PhonDan/master/data/Hau.2007.csv")Попробуем предсказать длительность s на основании ориентации спикера. Для этого в регрссию вводят так-называемые dummy-переменные. Dummy-переменные принимают лишь два значения либо 1, либо 0. В нашем случае 1 — гомосексуал, 0 — гетеросексуал.
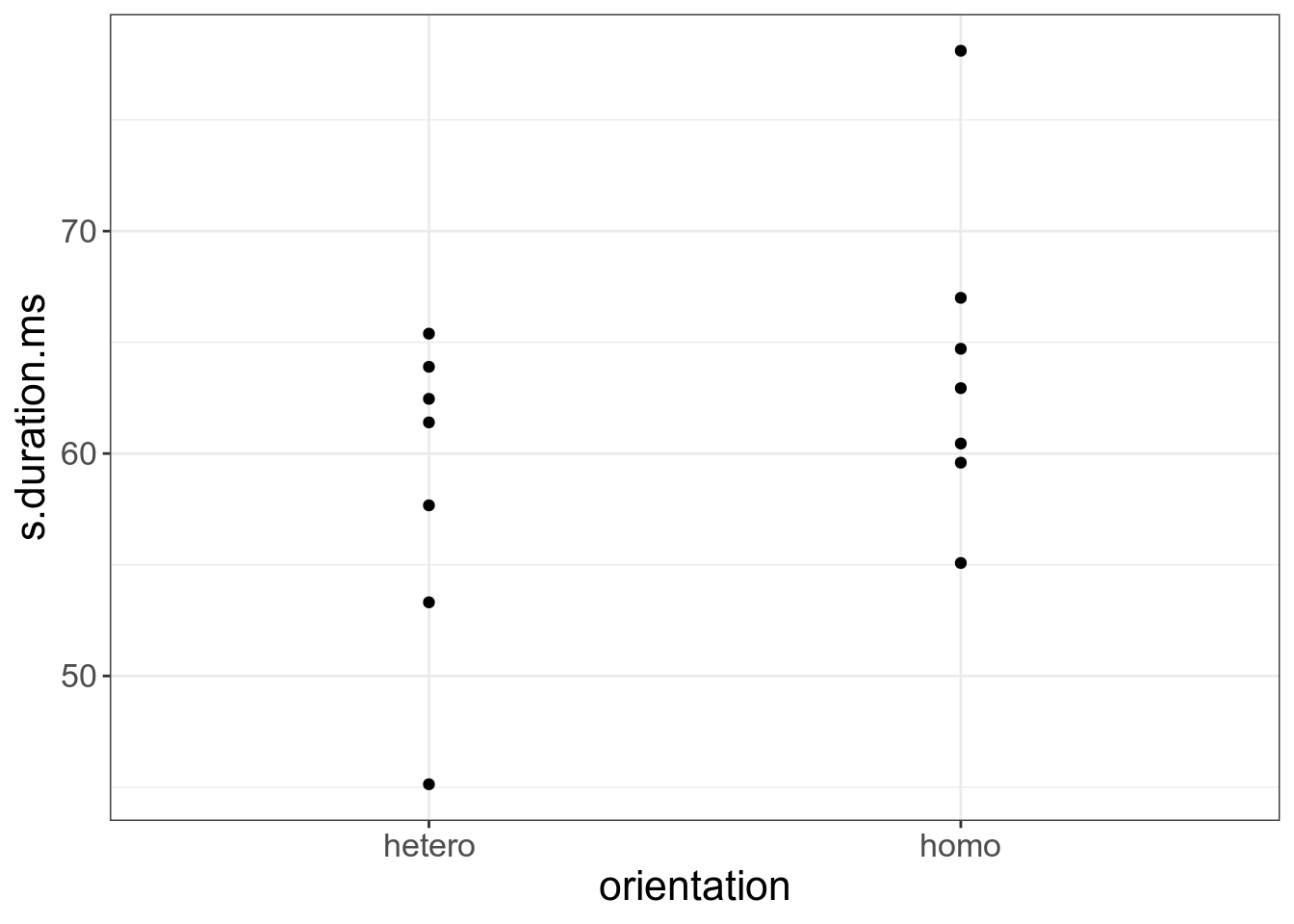
В таком случае наша формула примет следующий вид:
\[y_j = \beta_0 + \beta_1\times x + e_j\]
\[s\_duration_j = \beta_0 + \beta_1\times orientation_j + e_j\]
При описании гетеросексуалов переменная \(orientation = 0\), тогда модель принимает вид: \[s\_duration_j = \beta_0 + \beta_1\times orientation_j + e_j = \beta_0 + \beta_1\times 0 + e_j = \beta_0 + e_j\]
При описании гомосексуалов переменная \(orientation = 1\), тогда модель принимает вид: \[s\_duration_j = \beta_0 + \beta_1\times orientation_j + e_j = \beta_0 + \beta_1\times 1 + e_j = \beta_0 + \beta_1 + e_j\]
##
## Call:
## lm(formula = s.duration.ms ~ orientation, data = homo)
##
## Residuals:
## Min 1Q Median 3Q Max
## -13.3357 -4.1779 -0.0343 3.7500 14.1271
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 58.466 2.735 21.375 6.41e-11 ***
## orientationhomo 5.517 3.868 1.426 0.179
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 7.237 on 12 degrees of freedom
## Multiple R-squared: 0.145, Adjusted R-squared: 0.0737
## F-statistic: 2.034 on 1 and 12 DF, p-value: 0.1793Таким образом эта модель возвращает всего два числа: гетеросексуалы — \(58.466\), гомосексуалы — \(58.466+5.517=63.983\).
ОЧЕНЬ ВАЖНО: dummy-переменных всегда (n-1). Т. е. если значений категориальной переменной 7, то dummy-переменных будет 6 и т. д.
ОЧЕНЬ ВАЖНО: сколько бы не было значений категориальных, регрессия выбирает одну категорию (reference level) и проводит сравнение ее со всеми. Т. е. категории не в интерсепте не сравниваются, однако можно поменять reference level при помощи типа переменных factor.
homo$orientation <- factor(homo$orientation, levels = c("homo", "hetero"))
fit <- lm(s.duration.ms~orientation, data = homo)
summary(fit)##
## Call:
## lm(formula = s.duration.ms ~ orientation, data = homo)
##
## Residuals:
## Min 1Q Median 3Q Max
## -13.3357 -4.1779 -0.0343 3.7500 14.1271
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 63.983 2.735 23.392 2.22e-11 ***
## orientationhetero -5.517 3.868 -1.426 0.179
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 7.237 on 12 degrees of freedom
## Multiple R-squared: 0.145, Adjusted R-squared: 0.0737
## F-statistic: 2.034 on 1 and 12 DF, p-value: 0.1793🤔 Скачайте датасет, который содержит данные по количеству согласных в языках мира. Постройте регрессию предсказывающую количество согласных на основании наличия абруптивных. Приведите интерсепт модели (с точностью до 4 знаков после запятой):
🤔 Приведите коэффициент при переменной
have_ejectives(с точностью до 4 знаков после запятой):
1.3 Множественная регрессия
В целом, вообще-то можно в предсказании использовать не одну переменную, а сразу много. Это сложнее визуализировать, но все остальное выглядит так же:
\[y_j = \beta_0 + \beta_1 \times x_{1j} + \dots + \beta_k \times x_{kj} + e_j\]
Кроме того на практике, исследователи сравнивают разные модели, выбирая модели с статистически значимыми предикторами или используя информационные критерии (самый распространенный — критерий Акаике, который реализован в функции AIC)
🤔 В датасете про гомосексуалов попробуйте предсказать восприятие носителей как гомосексуалов на основании переменных длительность s, средняя частота основного тона и размер диапозона частоты основного тона. Првиедите \(R^2\) получившейся модели (с точностью до трех знаков после запятой):
2. Логистическая регрессия
2.1 Введение
Мы хотим чего-то такого: \[\underbrace{y}_{[-\infty, +\infty]}=\underbrace{\mbox{β}_0+\mbox{β}_1\cdot x_1+\mbox{β}_2\cdot x_2 + \dots +\mbox{β}_k\cdot x_k +\mbox{ε}_i}_{[-\infty, +\infty]}\] Вероятность — (в классической статистике) отношение количества успехов к общему числу событий: \[p = \frac{\mbox{# успехов}}{\mbox{# неудач} + \mbox{# успехов}}, \mbox{область значений: }[0, 1]\] Шансы — отношение количества успехов к количеству неудач: \[odds = \frac{p}{1-p} = \frac{p\mbox{(успеха)}}{p\mbox{(неудачи)}}, \mbox{область значений: }[0, +\infty]\] Натуральный логарифм шансов: \[\log(odds), \mbox{область значений: }[-\infty, +\infty]\]
Но, что нам говорит логарифм шансов? Как нам его интерпретировать?
tibble(n = 10,
success = 1:9,
failure = n - success,
prob.1 = success/(success+failure),
odds = success/failure,
log_odds = log(odds),
prob.2 = exp(log_odds)/(1+exp(log_odds)))Как связаны вероятность и логарифм шансов: \[\log(odds) = \log\left(\frac{p}{1-p}\right)\] \[p = \frac{\exp(\log(odds))}{1+\exp(\log(odds))}\]
Как связаны вероятность и логарифм шансов:
data_frame(p = seq(0, 1, 0.001),
log_odds = log(p/(1-p))) %>%
ggplot(aes(log_odds, p))+
geom_line()+
labs(x = latex2exp::TeX("$log\\left(\\frac{p}{1-p}\\right)$"))+
theme_bw()## Warning: `data_frame()` is deprecated, use `tibble()`.
## This warning is displayed once per session.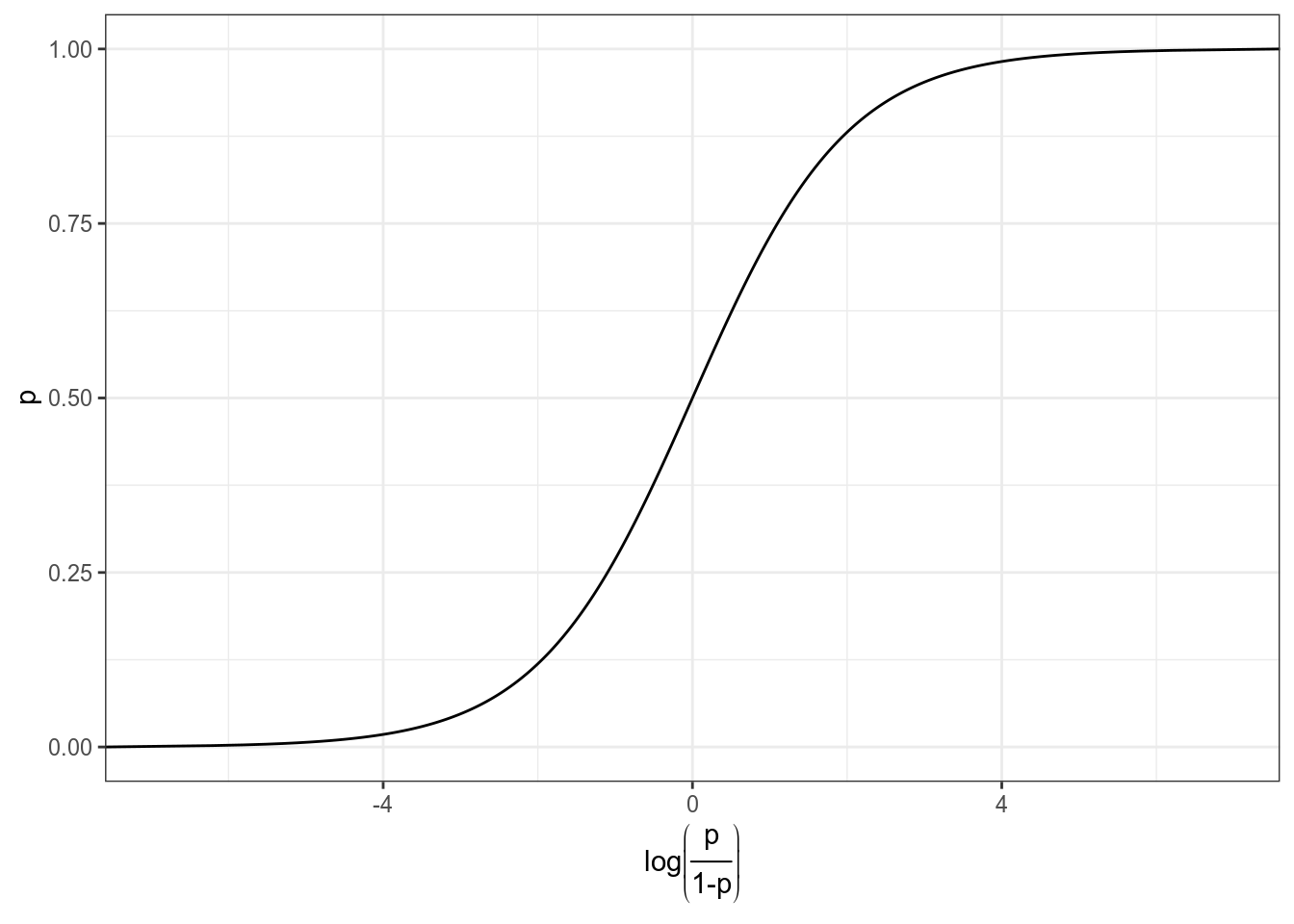
2.2 Почему не линейную регрессию?
lm_0 <- lm(as.integer(have_ejectives)~1, data = ejectives)
lm_1 <- lm(as.integer(have_ejectives)~total, data = ejectives)
lm_0##
## Call:
## lm(formula = as.integer(have_ejectives) ~ 1, data = ejectives)
##
## Coefficients:
## (Intercept)
## 0.1129##
## Call:
## lm(formula = as.integer(have_ejectives) ~ total, data = ejectives)
##
## Coefficients:
## (Intercept) total
## -0.085876 0.008077Первая модель: \[ejectives = 1.316 \times consonants\] Вторая модель: \[ejectives = 0.4611 + 0.0353 \times consonants\]
ejectives %>%
ggplot(aes(total, as.integer(have_ejectives)))+
geom_point()+
geom_smooth(method = "lm")+
theme_bw()+
labs(y = "ejectives (yes = 2, no = 1)")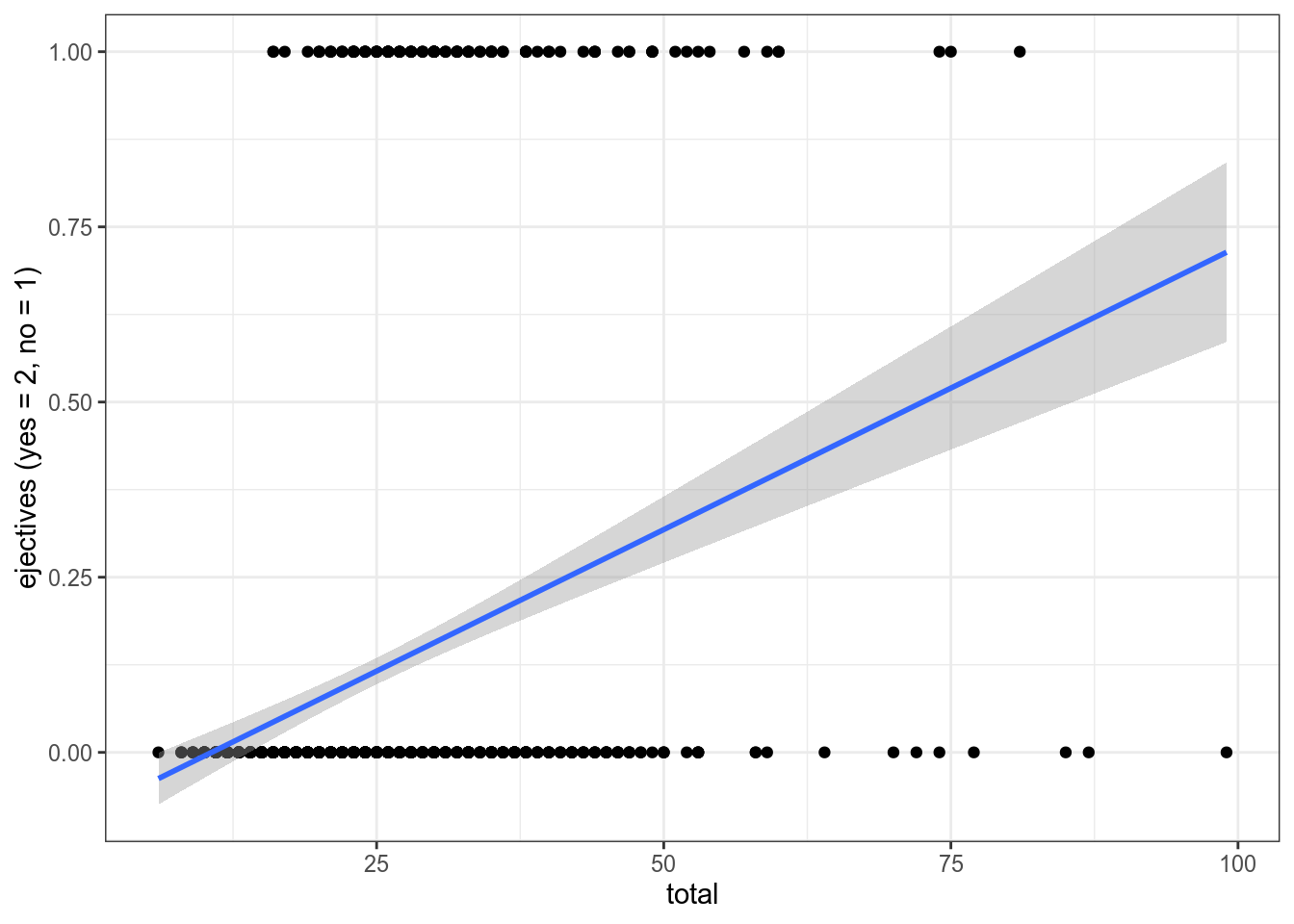
2.3 Логит: модель без предиктора
Будьте осторожны, glm не работает с тибблом.
##
## Call:
## glm(formula = have_ejectives ~ 1, family = "binomial", data = ejectives)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -0.4895 -0.4895 -0.4895 -0.4895 2.0886
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -2.0613 0.1008 -20.45 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 693.17 on 982 degrees of freedom
## Residual deviance: 693.17 on 982 degrees of freedom
## AIC: 695.17
##
## Number of Fisher Scoring iterations: 4## (Intercept)
## -2.061259##
## FALSE TRUE
## 872 111## [1] -2.061259## [1] 0.1129196## [1] 0.11291962.4 Логит: модель c одним числовым предиктором
##
## Call:
## glm(formula = have_ejectives ~ total, family = "binomial", data = ejectives)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.1944 -0.4687 -0.3933 -0.3292 2.3776
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -3.74452 0.26122 -14.335 < 2e-16 ***
## total 0.06119 0.00803 7.621 2.52e-14 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 693.17 on 982 degrees of freedom
## Residual deviance: 630.41 on 981 degrees of freedom
## AIC: 634.41
##
## Number of Fisher Scoring iterations: 5## (Intercept) total
## -3.74451734 0.06119122ejectives %>%
mutate(have_ejectives = as.integer(have_ejectives)) %>%
ggplot(aes(total, have_ejectives)) +
geom_point()+
theme_bw()+
geom_smooth(method = "glm",
method.args = list(family = "binomial"),
se = FALSE)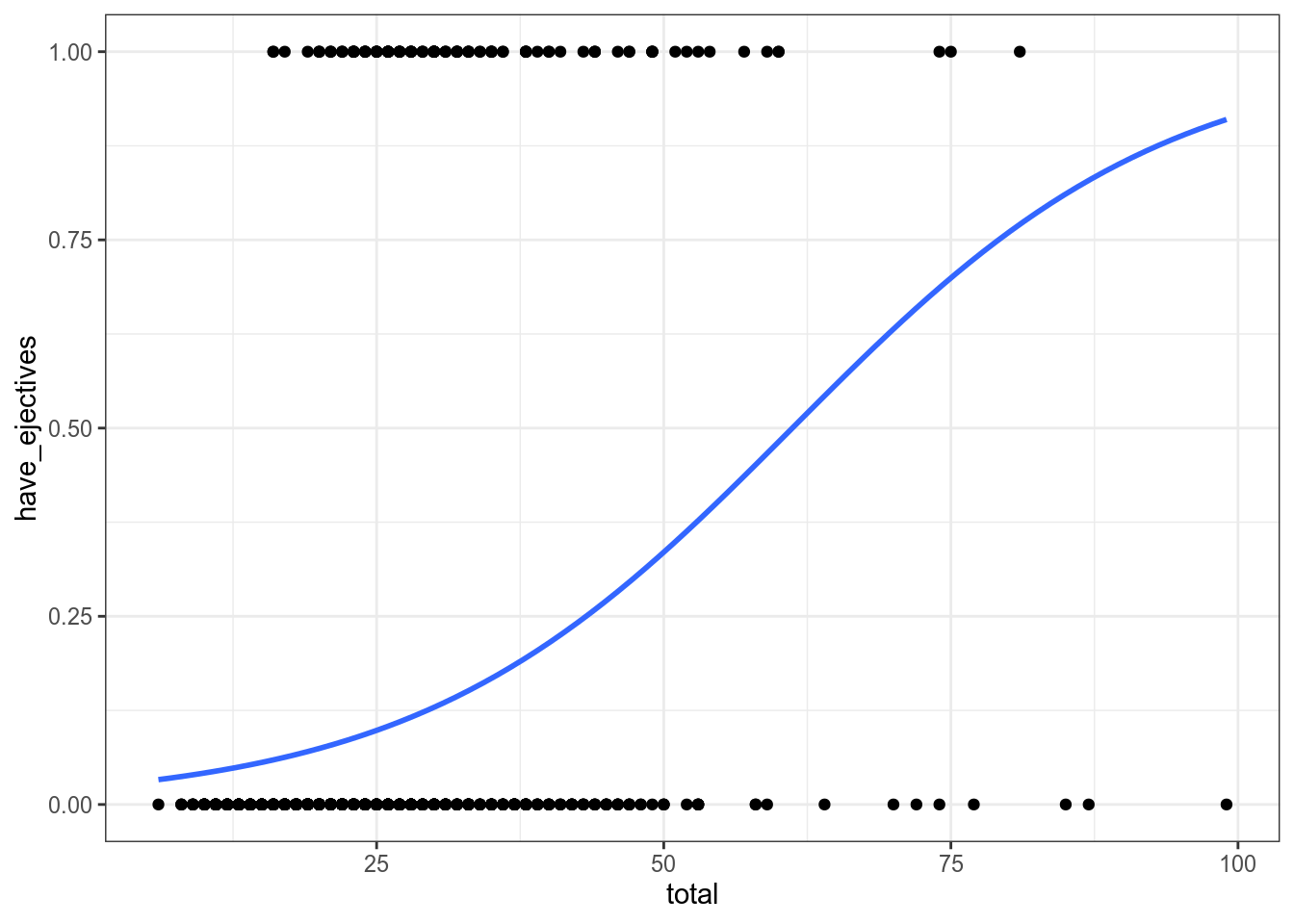
Какова вероятность, что в языке с 29 согласными есть абруптивные?
## (Intercept) total
## -3.74451734 0.06119122\[\log\left({\frac{p}{1-p}}\right)_i=\beta_0+\beta_1\times consinants_i + \epsilon_i\] \[\log\left({\frac{p}{1-p}}\right)=-12.1123347 + 0.4576095 \times 29 = 1.158341\] \[p = \frac{e^{1.158341}}{1+e^{1.158341}} = 0.7610311\]
## 1
## -1.969972## 1
## 0.12239192.5 Логит: модель c одним категориальным предиктором
##
## Call:
## glm(formula = have_ejectives ~ area, family = "binomial", data = ejectives)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.10816 -0.46538 -0.44865 -0.00013 2.21664
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -2.16832 0.16904 -12.827 < 2e-16 ***
## areaAustralia -16.39775 1581.97224 -0.010 0.992
## areaEurasia -0.07711 0.30002 -0.257 0.797
## areaNorth America 2.00324 0.27560 7.269 3.63e-13 ***
## areaPapua -16.39775 555.24390 -0.030 0.976
## areaSouth America -0.19880 0.31858 -0.624 0.533
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 693.17 on 982 degrees of freedom
## Residual deviance: 589.74 on 977 degrees of freedom
## AIC: 601.74
##
## Number of Fisher Scoring iterations: 17## (Intercept) areaAustralia areaEurasia areaNorth America
## -2.16832083 -16.39774768 -0.07710585 2.00324108
## areaPapua areaSouth America
## -16.39774768 -0.19880278##
## Africa Australia Eurasia North America Papua South America
## FALSE 341 17 170 46 138 160
## TRUE 39 0 18 39 0 15## [1] -1.791759## [1] 1.0986122.6 Логит: множественная регрессия
##
## Call:
## glm(formula = have_ejectives ~ total + area, family = "binomial",
## data = ejectives)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.21414 -0.42232 -0.33162 -0.00015 2.44830
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -4.402e+00 3.662e-01 -12.021 < 2e-16 ***
## total 7.282e-02 9.629e-03 7.562 3.96e-14 ***
## areaAustralia -1.557e+01 1.570e+03 -0.010 0.9921
## areaEurasia -4.458e-01 3.348e-01 -1.331 0.1830
## areaNorth America 2.444e+00 3.022e-01 8.088 6.05e-16 ***
## areaPapua -1.556e+01 5.383e+02 -0.029 0.9769
## areaSouth America 6.069e-01 3.483e-01 1.742 0.0814 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 693.17 on 982 degrees of freedom
## Residual deviance: 525.76 on 976 degrees of freedom
## AIC: 539.76
##
## Number of Fisher Scoring iterations: 172.7 Логит: сравнение моделей
## [1] 695.1651## [1] 634.4102## [1] 601.7417## [1] 539.7573Для того, чтобы интерпретировать коэффициенты нужно проделать трансформацю:
## (Intercept) total
## -97.635296 6.310218Перед нами процентное изменние шансов при увеличении независимой переменной на 1.
Было предложено много аналогов R\(^2\), например, McFadden’s R squared:
## llh llhNull G2 McFadden r2ML
## -315.20508447 -346.58253511 62.75490127 0.09053385 0.06184508
## r2CU
## 0.12223149🤔 В датасете про гомосексуалов попробуйте предсказать ориентацию носителей на основании переменных длительность s, средняя частота основного тона и размер диапозона частоты основного тона. Приведите коэффициент при предикторе
average.f0.Hzполучившейся модели (с точностью до 3 знака после запятой).
🤔 Посчитайте вероятность быть гомосексуалом с условием `s.duration.ms = 62, average.f0.Hz =120, f0.range.Hz = 60. Ответ приведите с точностью до 3 знаков после запятой.
3 Регрессия со случайными эффектами
In this dataset we have number of consonants and vowels in 402 languages collected from UPSID database (http://www.lapsyd.ddl.ish-lyon.cnrs.fr/lapsyd/). There is an variable of the area based on Glottolog (http://glottolog.org/). In this part we will try to make models that predict number of vowels by number of consonants.
upsid <- read_csv("https://raw.githubusercontent.com/agricolamz/2019_data_analysis_for_linguists/master/data/upsid.csv")## Parsed with column specification:
## cols(
## language = col_character(),
## area = col_character(),
## consonants = col_double(),
## vowels = col_double()
## )lingtypology::map.feature(upsid$language,
features = upsid$area,
label = upsid$language,
label.hide = TRUE)upsid %>%
ggplot(aes(consonants, vowels))+
geom_point()+
labs(x = "number of consonants",
y = "number of vowels",
caption = "data from LAPSyD")+
theme_bw()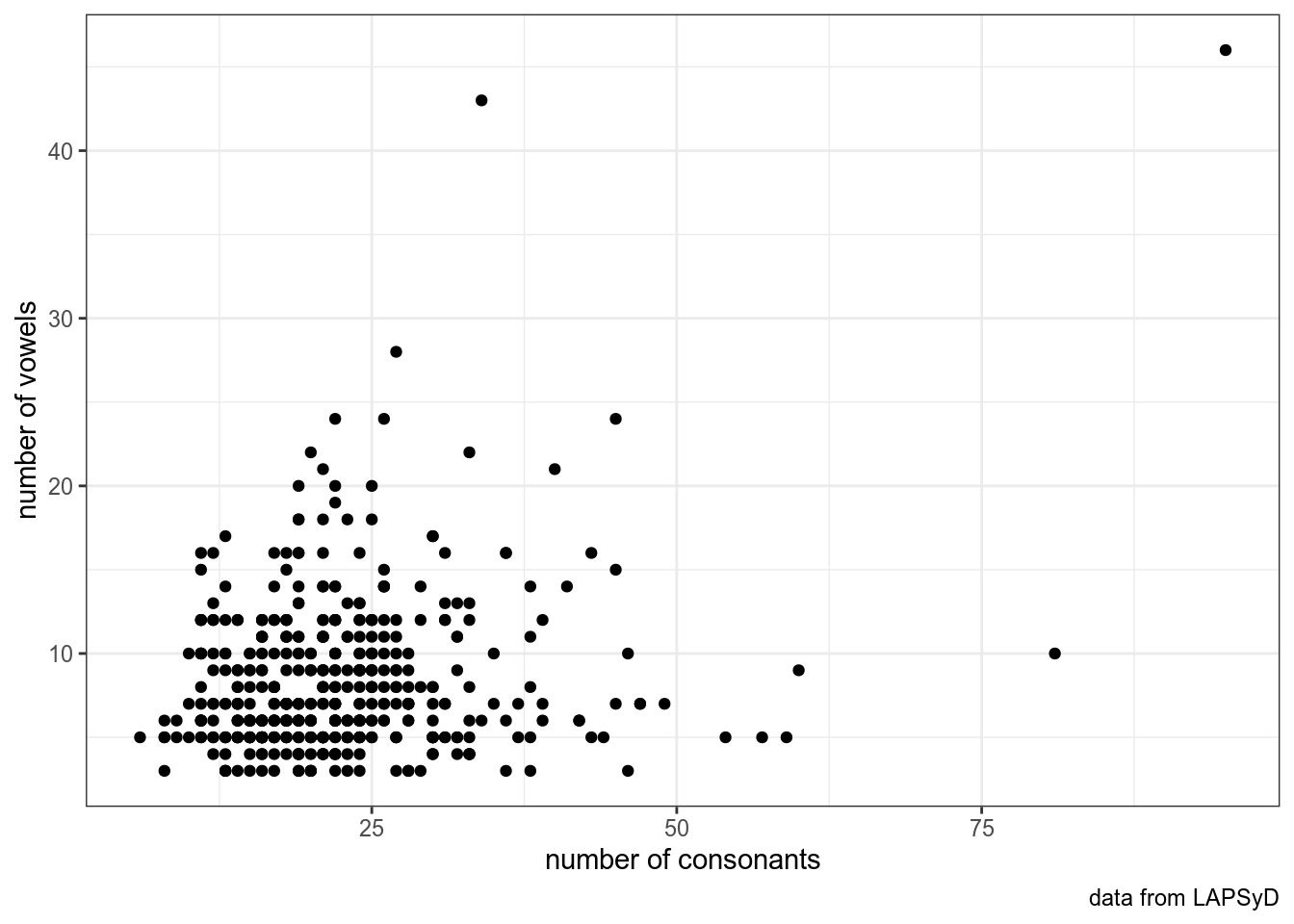
Обведем наблюдения по каждому спикеру:
upsid %>%
ggplot(aes(consonants, vowels, color = area))+
geom_point()+
labs(x = "number of consonants",
y = "number of vowels",
caption = "data from LAPSyD")+
theme_bw()+
stat_ellipse()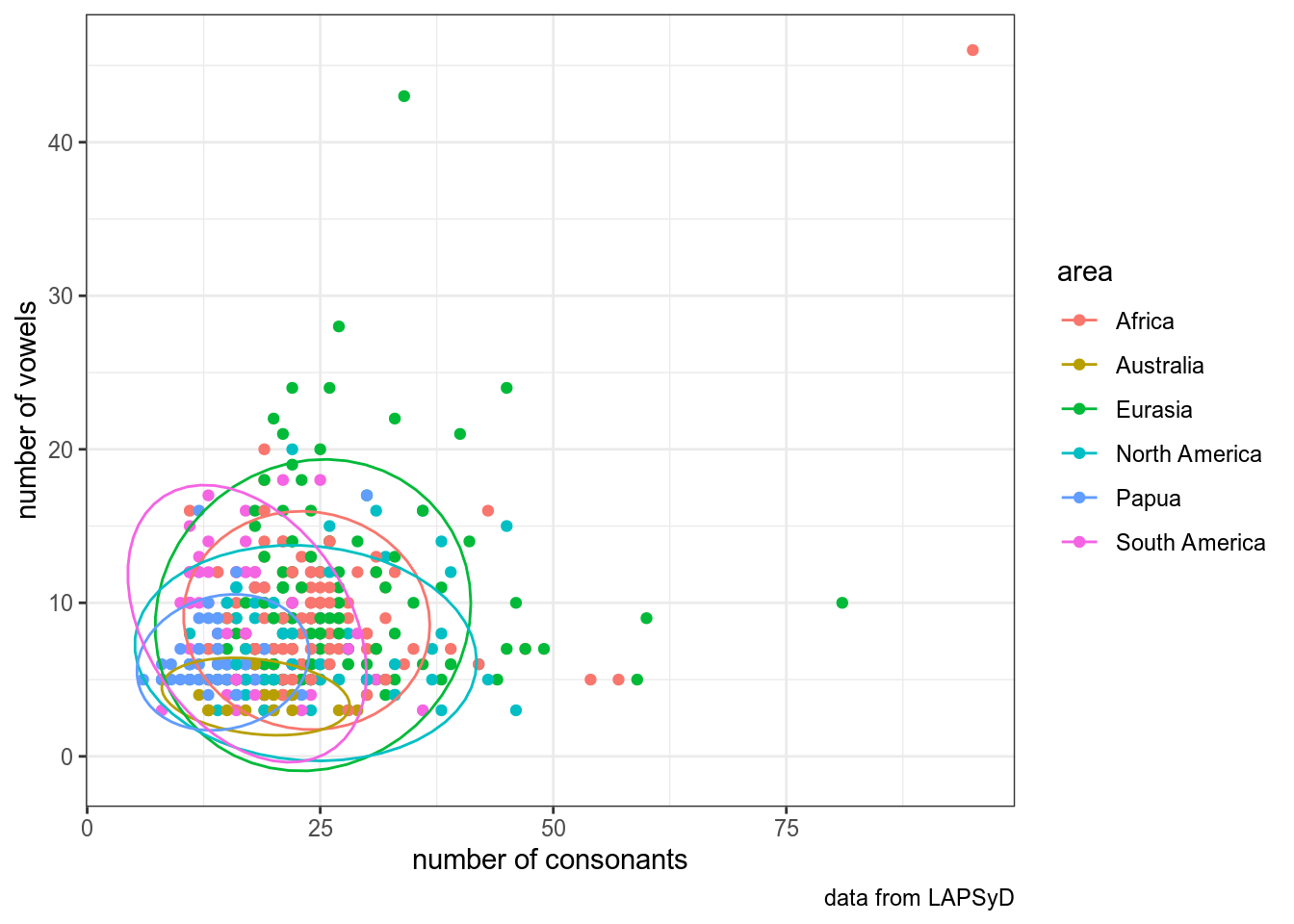
Построим простую регрессию и добавим ее на график:
##
## Call:
## lm(formula = vowels ~ consonants, data = upsid)
##
## Residuals:
## Min 1Q Median 3Q Max
## -8.148 -2.897 -1.208 2.441 33.203
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 5.96920 0.56512 10.563 < 2e-16 ***
## consonants 0.11259 0.02317 4.859 1.63e-06 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 4.67 on 449 degrees of freedom
## Multiple R-squared: 0.04996, Adjusted R-squared: 0.04785
## F-statistic: 23.61 on 1 and 449 DF, p-value: 1.63e-06upsid %>%
ggplot(aes(consonants, vowels))+
geom_point()+
labs(x = "number of consonants",
y = "number of vowels",
caption = "data from LAPSyD")+
theme_bw()+
geom_line(data = fortify(fit1), aes(x = consonants, y = .fitted), color = "blue")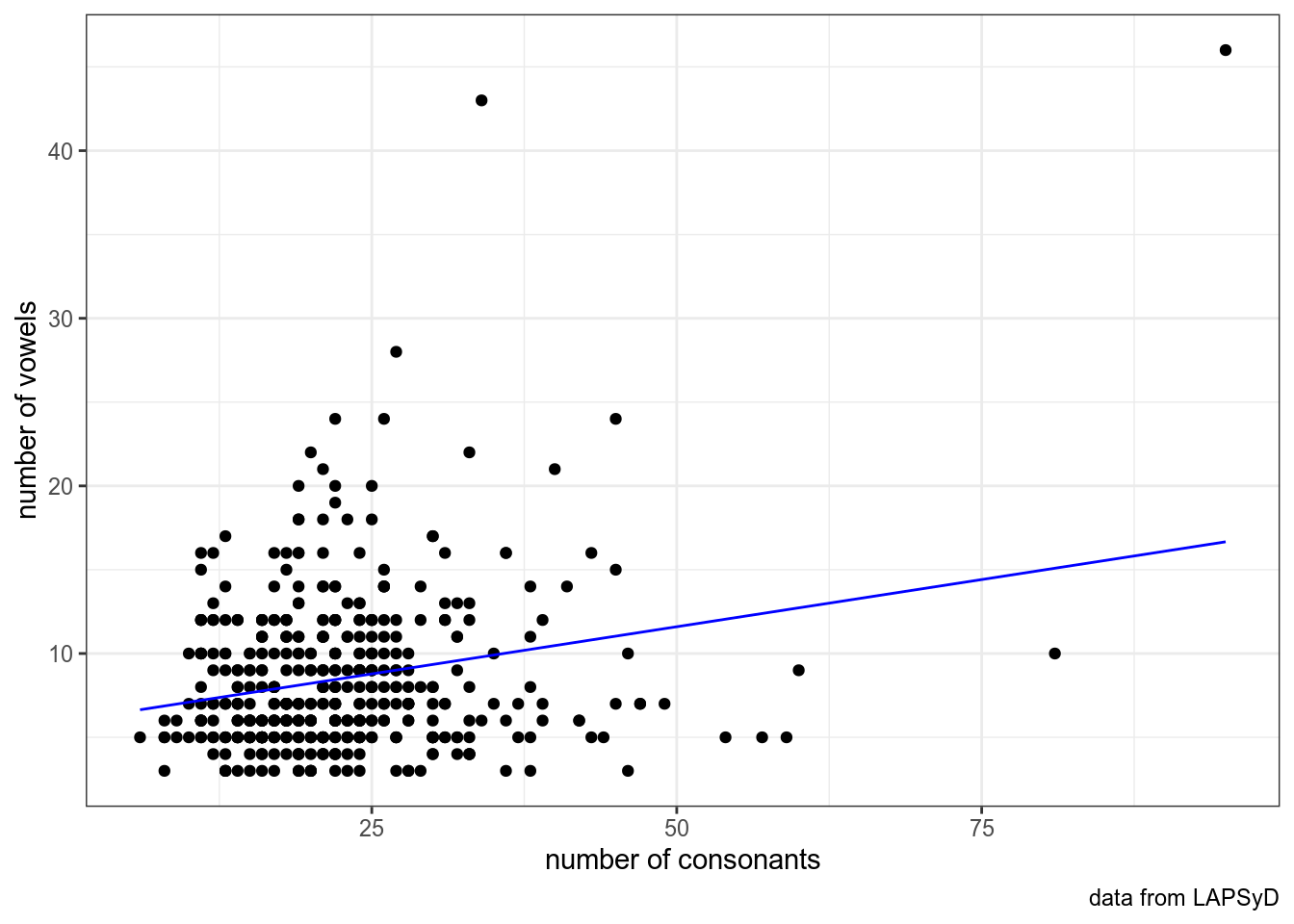
## Linear mixed model fit by REML. t-tests use Satterthwaite's method [
## lmerModLmerTest]
## Formula: vowels ~ consonants + (1 | area)
## Data: upsid
##
## REML criterion at convergence: 2649.4
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -1.7378 -0.6176 -0.2127 0.4484 7.2066
##
## Random effects:
## Groups Name Variance Std.Dev.
## area (Intercept) 3.336 1.826
## Residual 20.053 4.478
## Number of obs: 451, groups: area, 6
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 6.07766 0.94134 9.15205 6.456 0.000109 ***
## consonants 0.08212 0.02458 446.67797 3.341 0.000905 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr)
## consonants -0.556upsid %>%
ggplot(aes(consonants, vowels))+
geom_point()+
labs(x = "number of consonants",
y = "number of vowels",
caption = "data from LAPSyD")+
theme_bw() +
geom_line(data = fortify(fit2), aes(x = consonants, y = .fitted, color = area))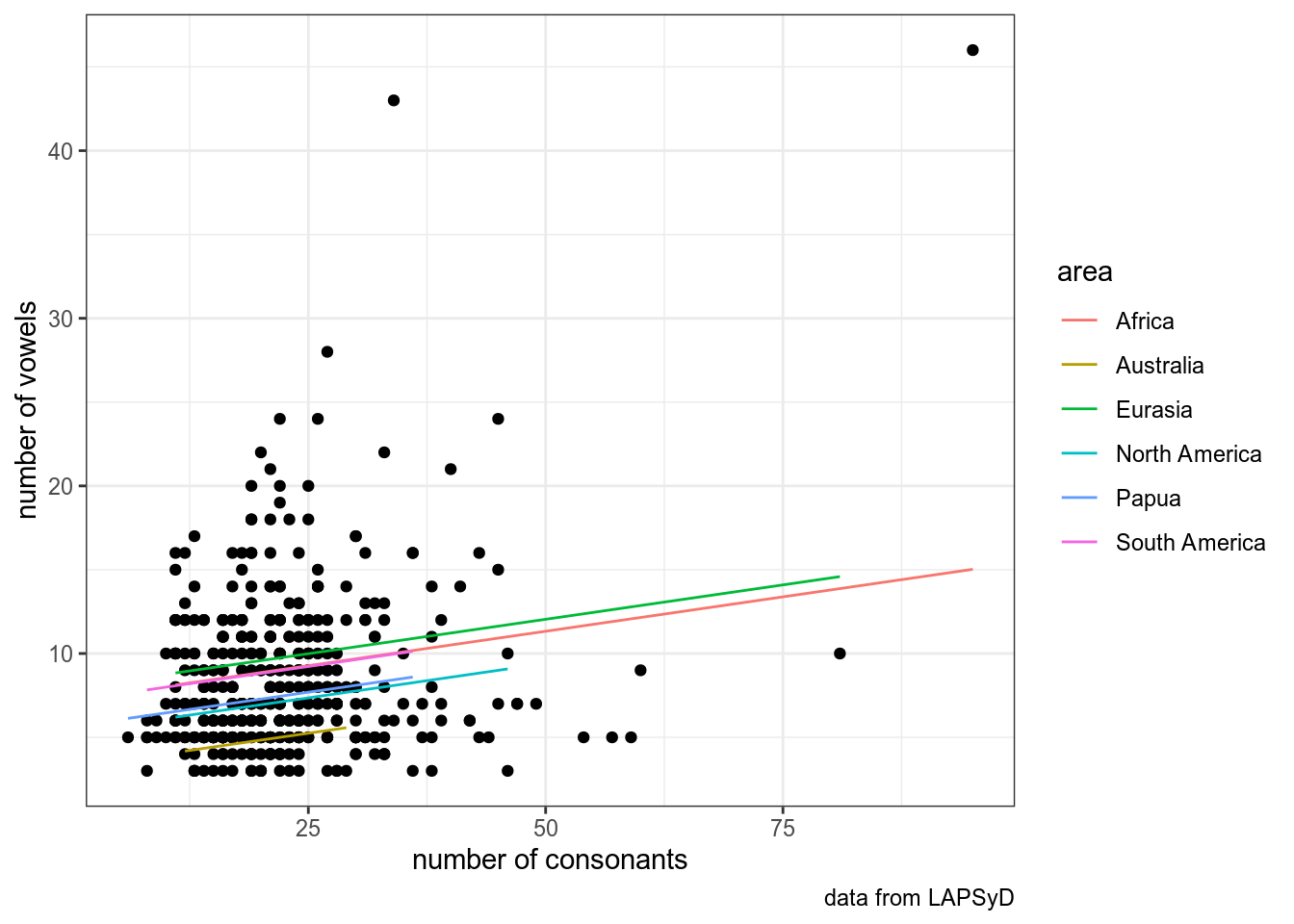
Если мы предполагаем скоррелированность свободных эффектов:
## Warning in checkConv(attr(opt, "derivs"), opt$par, ctrl =
## control$checkConv, : Model failed to converge with max|grad| = 0.118439
## (tol = 0.002, component 1)## Linear mixed model fit by REML. t-tests use Satterthwaite's method [
## lmerModLmerTest]
## Formula: vowels ~ consonants + (1 + consonants | area)
## Data: upsid
##
## REML criterion at convergence: 2640
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -2.3273 -0.5771 -0.2206 0.4202 7.4023
##
## Random effects:
## Groups Name Variance Std.Dev. Corr
## area (Intercept) 9.46650 3.0768
## consonants 0.01698 0.1303 -0.82
## Residual 19.33665 4.3973
## Number of obs: 451, groups: area, 6
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 6.65459 1.44029 4.40533 4.620 0.00783 **
## consonants 0.05160 0.06358 4.07234 0.812 0.46182
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr)
## consonants -0.845
## convergence code: 0
## Model failed to converge with max|grad| = 0.118439 (tol = 0.002, component 1)upsid %>%
ggplot(aes(consonants, vowels))+
geom_point()+
labs(x = "number of consonants",
y = "number of vowels",
caption = "data from LAPSyD")+
theme_bw()+
geom_line(data = fortify(fit3), aes(x = consonants, y = .fitted, color = area))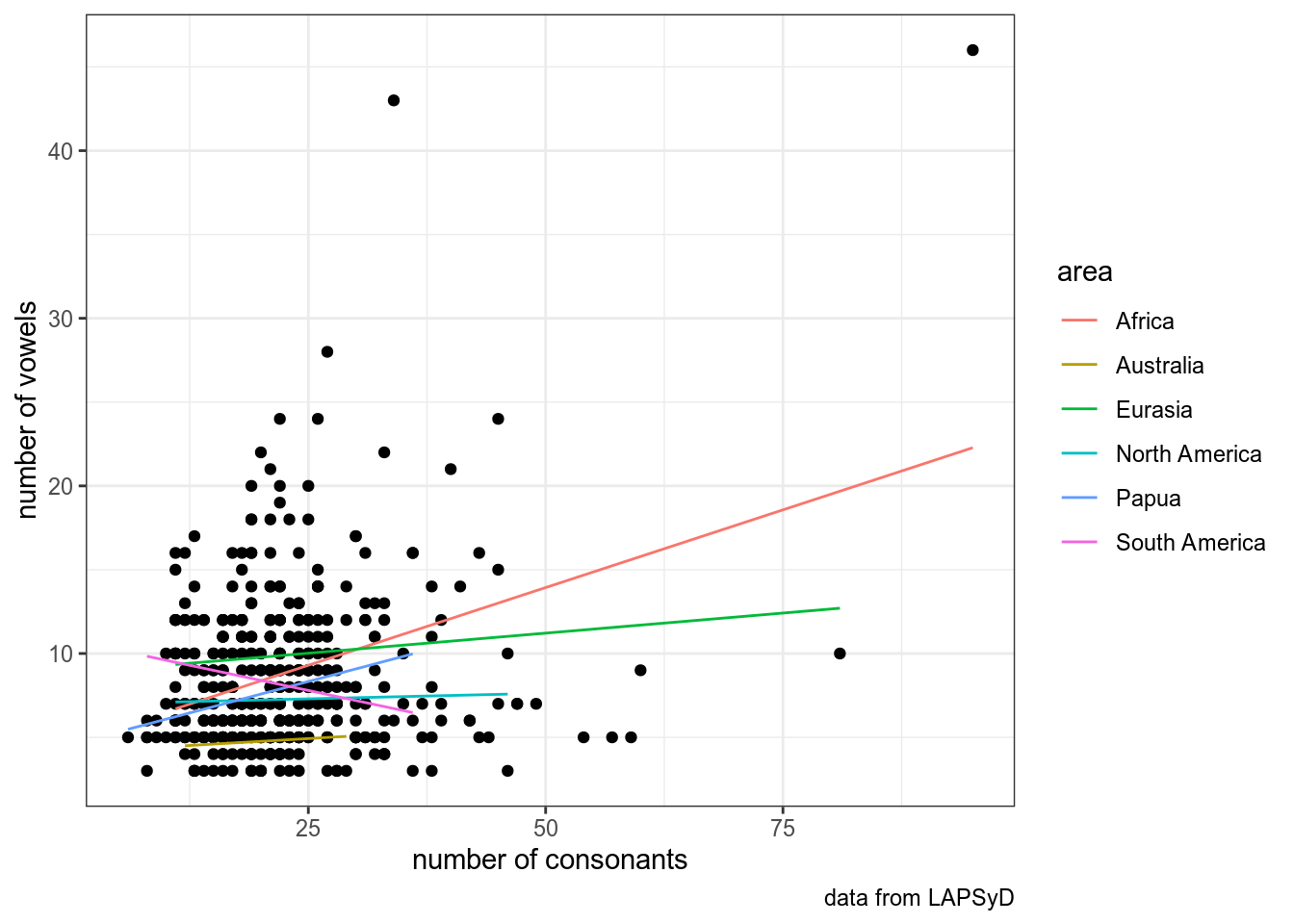
## Linear mixed model fit by REML. t-tests use Satterthwaite's method [
## lmerModLmerTest]
## Formula: vowels ~ consonants + (0 + consonants | area)
## Data: upsid
##
## REML criterion at convergence: 2650.9
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -1.8910 -0.5705 -0.2539 0.4255 7.2020
##
## Random effects:
## Groups Name Variance Std.Dev.
## area consonants 0.007731 0.08793
## Residual 20.106719 4.48405
## Number of obs: 451, groups: area, 6
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 6.93418 0.61286 437.37643 11.314 <2e-16 ***
## consonants 0.03417 0.04630 8.68189 0.738 0.48
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr)
## consonants -0.578upsid %>%
ggplot(aes(consonants, vowels))+
geom_point()+
labs(x = "number of consonants",
y = "number of vowels",
caption = "data from LAPSyD")+
theme_bw()+
geom_line(data = fortify(fit4), aes(x = consonants, y = .fitted, color = area))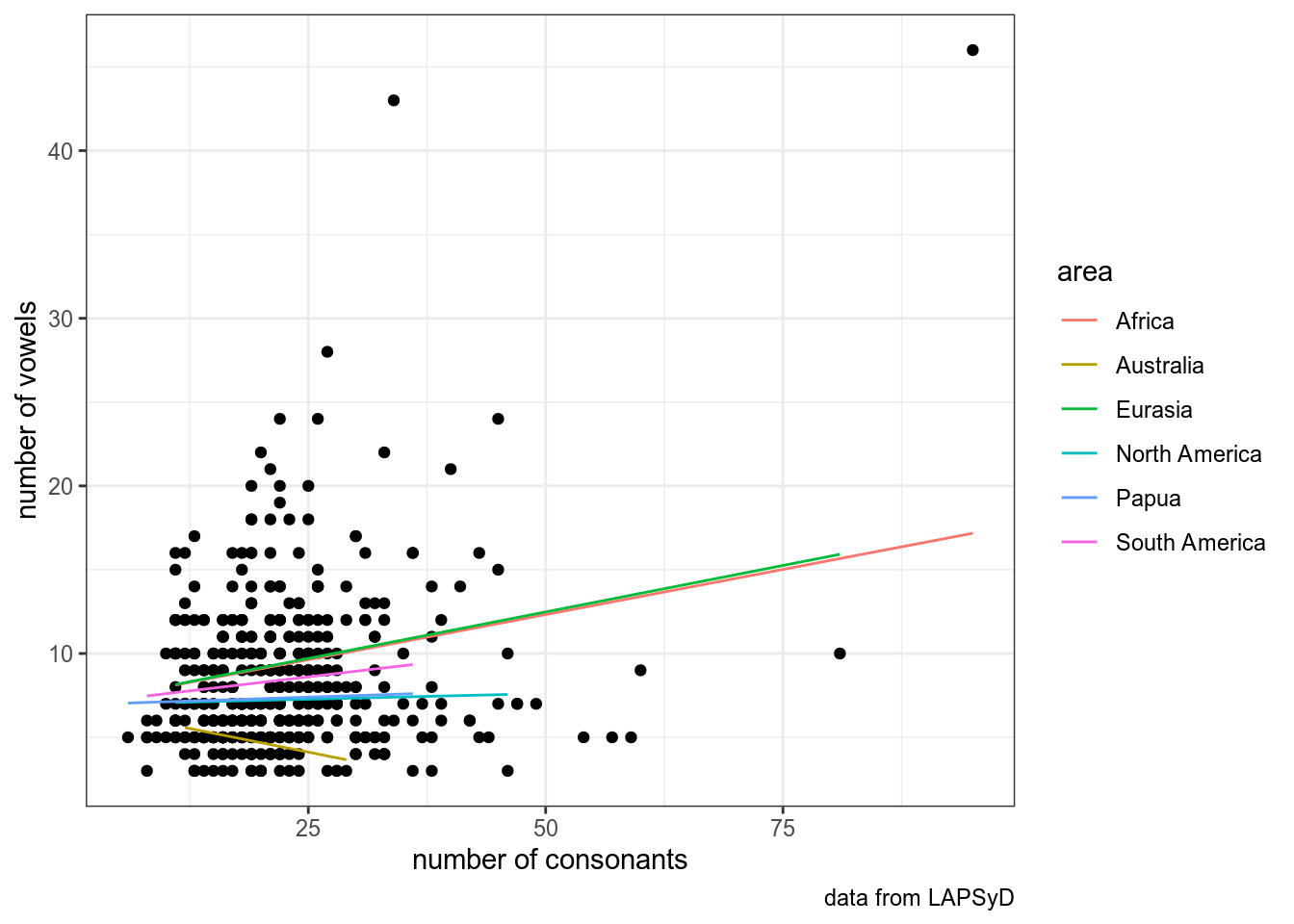
Если мы не предполагаем скоррелированность свободных эффектов:
## Linear mixed model fit by REML. t-tests use Satterthwaite's method [
## lmerModLmerTest]
## Formula: vowels ~ consonants + (1 | area) + (0 + consonants | area)
## Data: upsid
##
## REML criterion at convergence: 2643.3
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -2.1630 -0.6011 -0.2275 0.4219 7.3599
##
## Random effects:
## Groups Name Variance Std.Dev.
## area (Intercept) 4.735695 2.17617
## area.1 consonants 0.008716 0.09336
## Residual 19.441478 4.40925
## Number of obs: 451, groups: area, 6
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 6.70370 1.10137 5.13860 6.087 0.00157 **
## consonants 0.04515 0.04942 4.20174 0.914 0.41030
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr)
## consonants -0.347upsid %>%
ggplot(aes(consonants, vowels))+
geom_point()+
labs(x = "number of consonants",
y = "number of vowels",
caption = "data from LAPSyD")+
theme_bw()+
geom_line(data = fortify(fit5), aes(x = consonants, y = .fitted, color = area))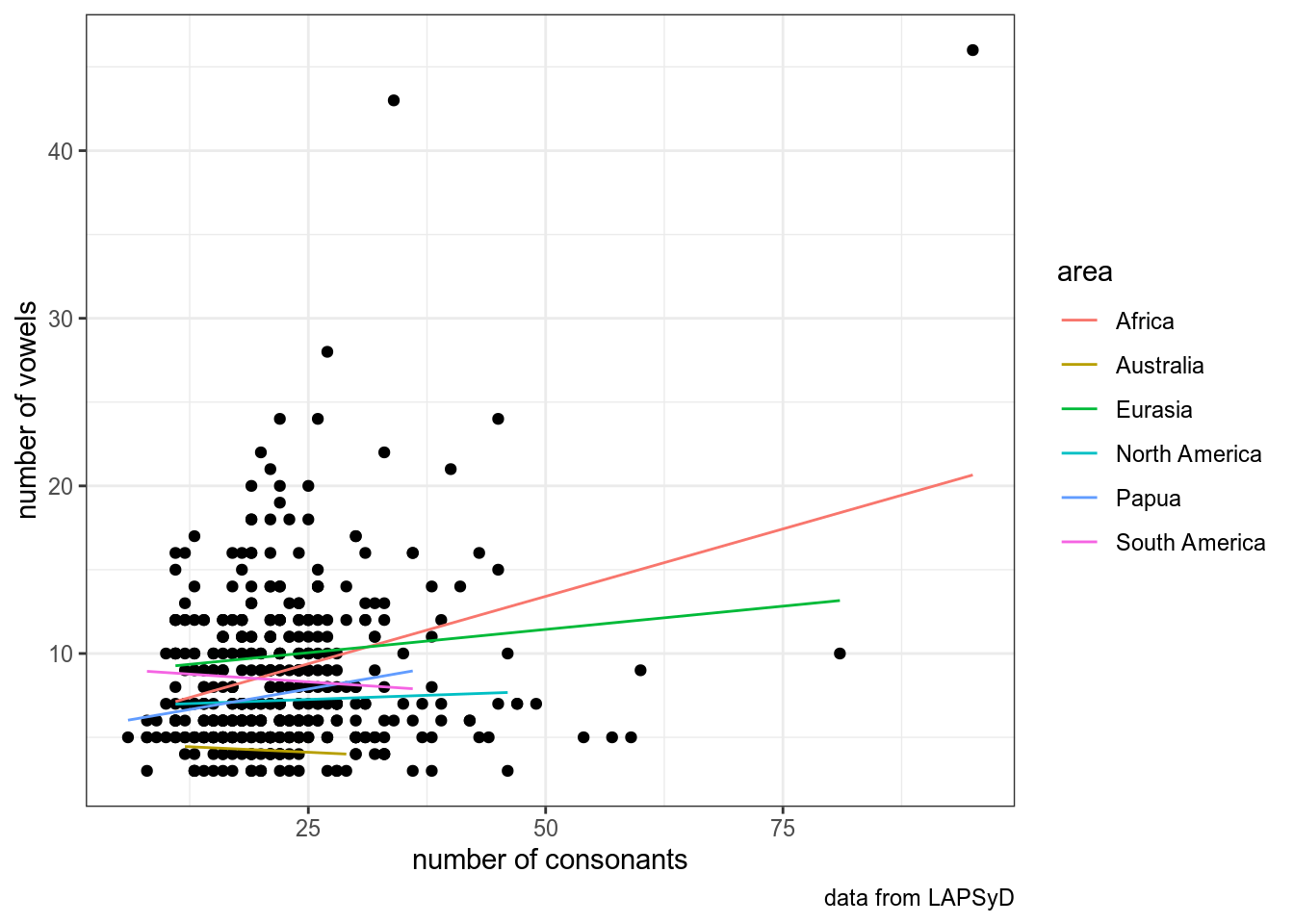
## Warning in checkConv(attr(opt, "derivs"), opt$par, ctrl =
## control$checkConv, : Model failed to converge with max|grad| = 0.119134
## (tol = 0.002, component 1)## Linear mixed model fit by REML. t-tests use Satterthwaite's method [
## lmerModLmerTest]
## Formula: vowels ~ 1 + (1 | area) + (0 + consonants | area)
## Data: upsid
##
## REML criterion at convergence: 2640
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -2.1244 -0.6117 -0.2240 0.4078 7.3782
##
## Random effects:
## Groups Name Variance Std.Dev.
## area (Intercept) 4.88902 2.2111
## area.1 consonants 0.00984 0.0992
## Residual 19.40686 4.4053
## Number of obs: 451, groups: area, 6
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 7.044 1.051 3.864 6.704 0.00291 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## convergence code: 0
## Model failed to converge with max|grad| = 0.119134 (tol = 0.002, component 1)## refitting model(s) with ML (instead of REML)3.1 Task
Pavel Duryagin ran an experiment on perception of vowel reduction in Russian language. The dataset shva includes the following variables:
- time1 - reaction time 1<>
- duration - duration of the vowel in the stimuly (in milliseconds, ms)<>
- time2 - reaction time 2<>
- f1, f2, f3 - the 1st, 2nd and 3rd formant of the vowel measured in Hz (for a short introduction into formants, see here)<>
- vowel - vowel classified according the 3-fold classification (A - a under stress, a - a/o as in the first syllable before the stressed one, y (stands for shva) - a/o as in the second etc. syllable before the stressed one or after the stressed syllable, cf. g[y]g[a]t[A]l[y] gogotala ‘guffawed’). In this part, we will ask you to analyse correlation between f1, f2, and duration.
shva <- read_tsv("https://raw.githubusercontent.com/agricolamz/2019_PhonDan/master/data/duryagin_ReductionRussian.txt")## Parsed with column specification:
## cols(
## time1 = col_double(),
## duration = col_double(),
## time2 = col_double(),
## f2 = col_double(),
## f1 = col_double(),
## f3 = col_double(),
## vowel = col_character()
## )shva %>%
ggplot(aes(x=f2, y=f1, color=vowel)) +
geom_point(show.legend = FALSE) +
scale_x_reverse()+
scale_y_reverse()+
labs(x = "f2",
y = "f1",
title = "f2 and f1 of the reduced and stressed vowels",
caption = "Data from Duryagin 2018")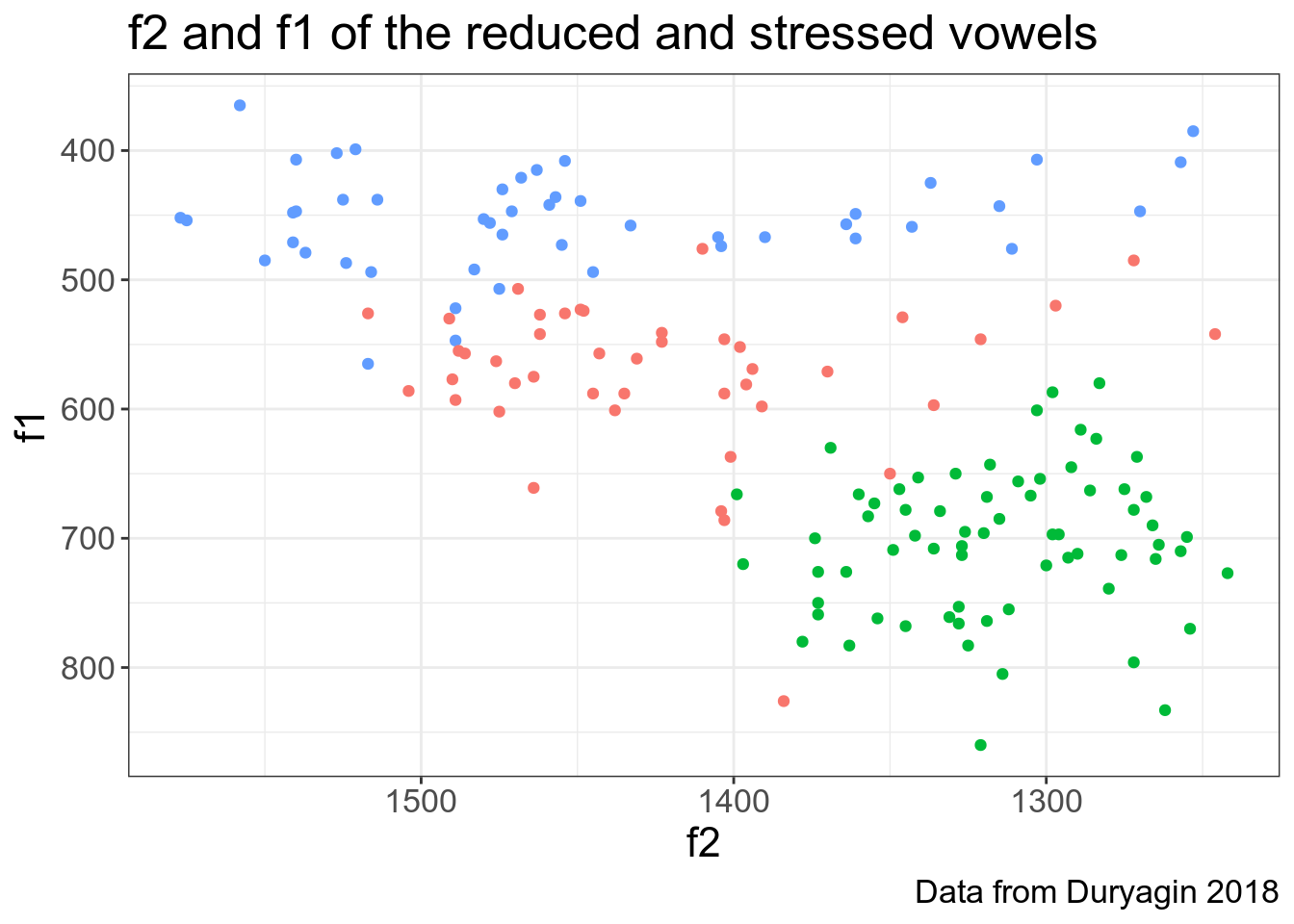
Постройте регрессию со смешанными эффектами, предсказывая f2 на основе f1 и гласный – в случайных эффектах. В ответе приведите коэффициент при f1 (с точностью до 4 знаков после запятой: