Фрикативные, пакеты для R, методы исследования звука
## ── Attaching packages ────────────────────────────────────────────────────── tidyverse 1.2.1 ──## ✔ ggplot2 3.2.0 ✔ purrr 0.3.2
## ✔ tibble 2.1.3 ✔ dplyr 0.8.3
## ✔ tidyr 0.8.3 ✔ stringr 1.4.0
## ✔ readr 1.3.1 ✔ forcats 0.4.0## ── Conflicts ───────────────────────────────────────────────────────── tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()1. Фрикативные
- fricatives, fricatives’ TextGrid, Extracted data: ɬ, s, sh, x, χ
# set your working directory ----------------------------------------------
setwd("...")
# read all files in the derictory to R ------------------------------------
myfiles <- lapply(list.files(), read.delim)
# merge files into one dataframe ------------------------------------------
result_df <- Reduce(rbind, myfiles)
# create labels -----------------------------------------------------------
sounds <- c("l", "sh", "s", "x", "X")
result_df$label <- rep(sounds, sapply(myfiles, nrow))
# draw the plot -----------------------------------------------------------
library(ggplot2)
ggplot(data = result_df,
aes(x = freq.Hz.,
y = pow.dB.Hz.,
color = label))+
geom_line(size = 2)+
theme_bw()+
labs(title = "Smoothed LPC for different fricatives",
x = "frequency (Hz)",
y = "power (Db/Hz)")3. Методы исследования артикуляционной фонетики
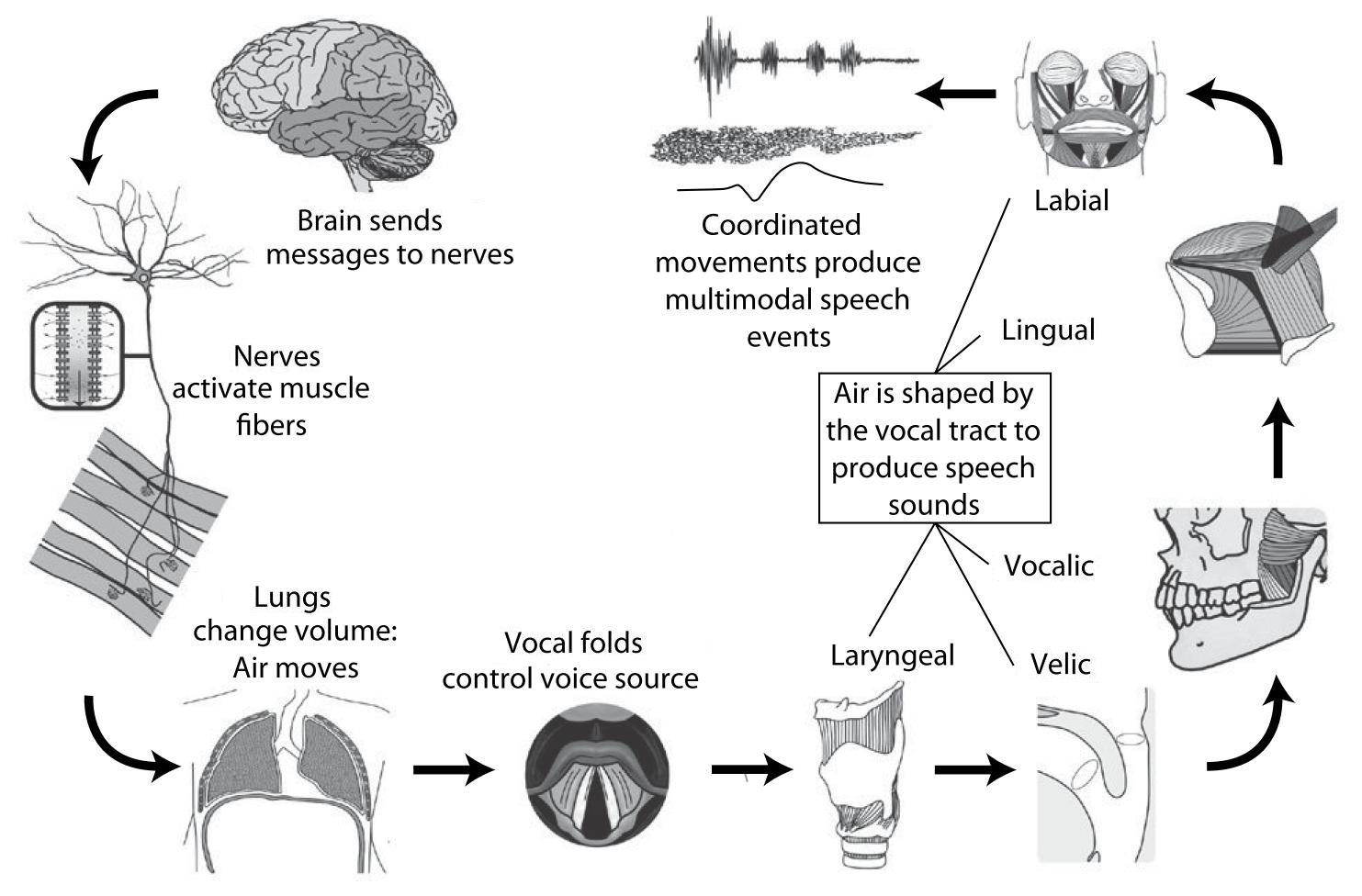
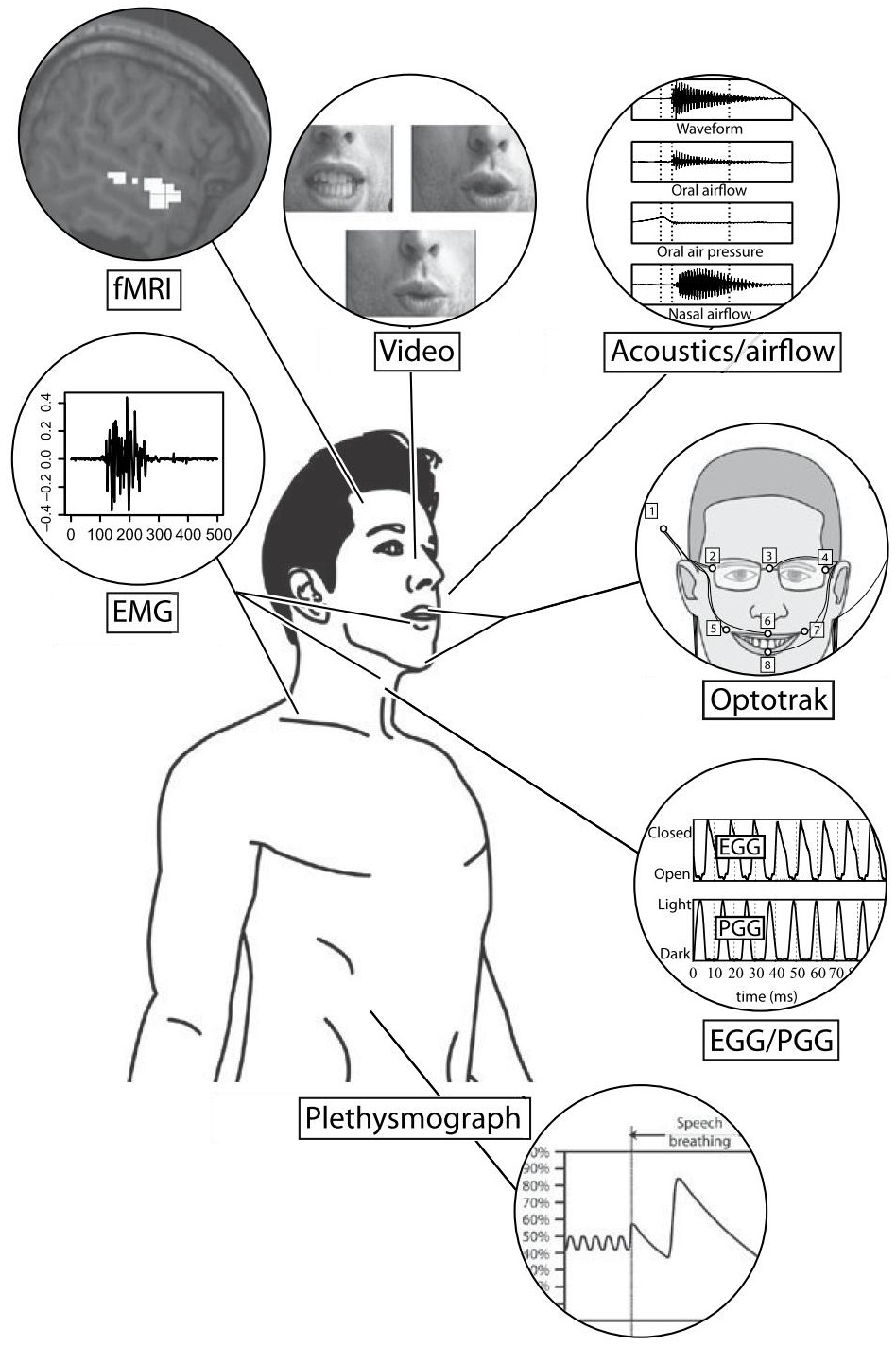
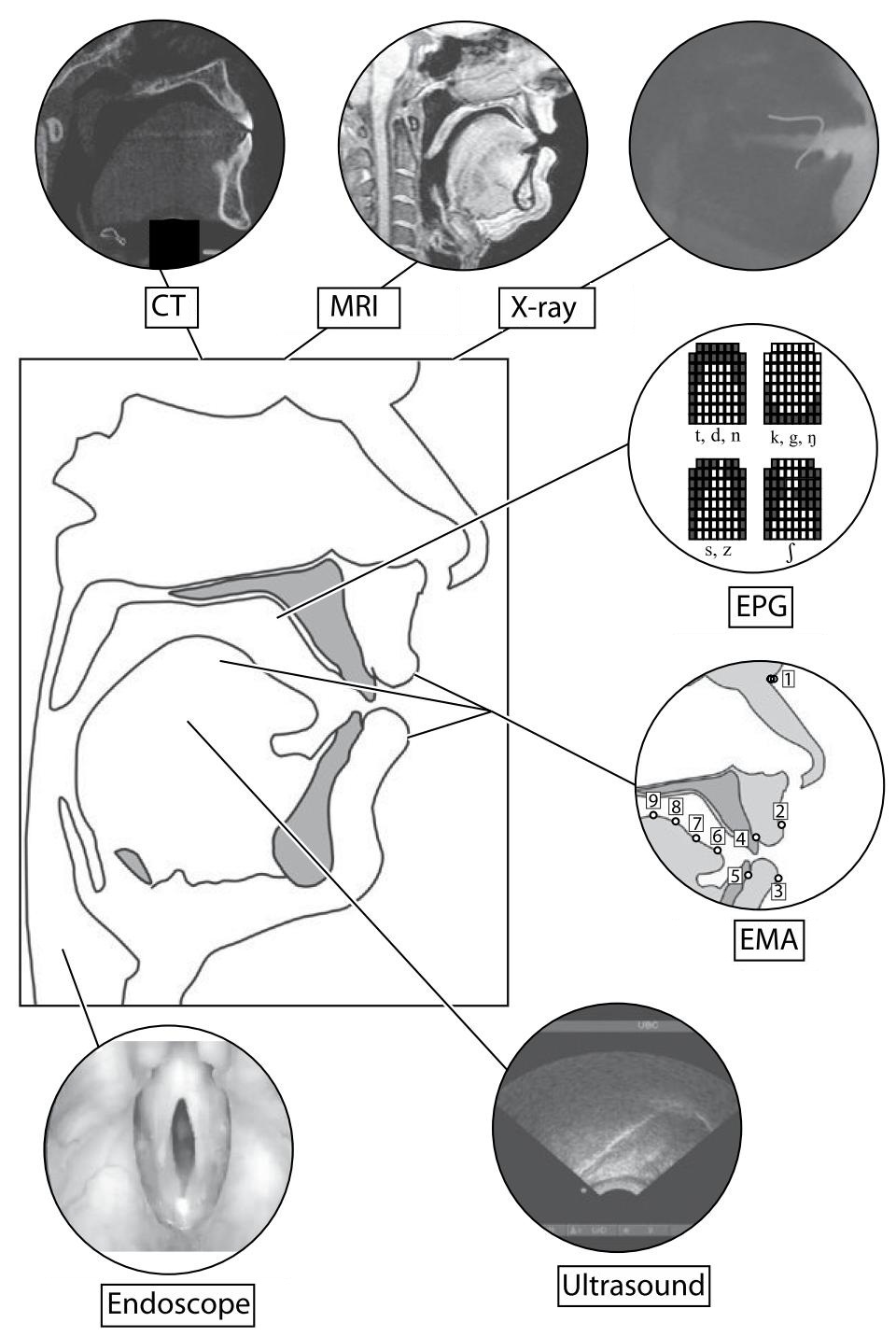
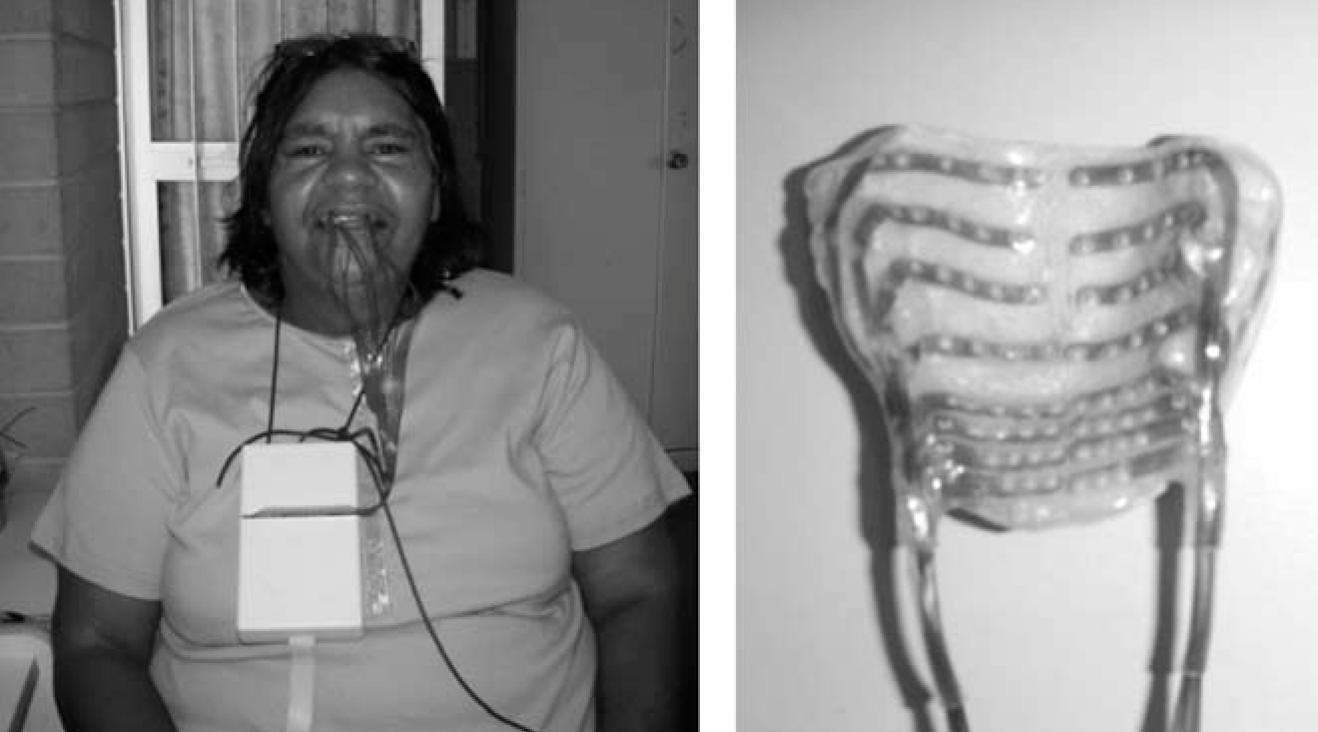
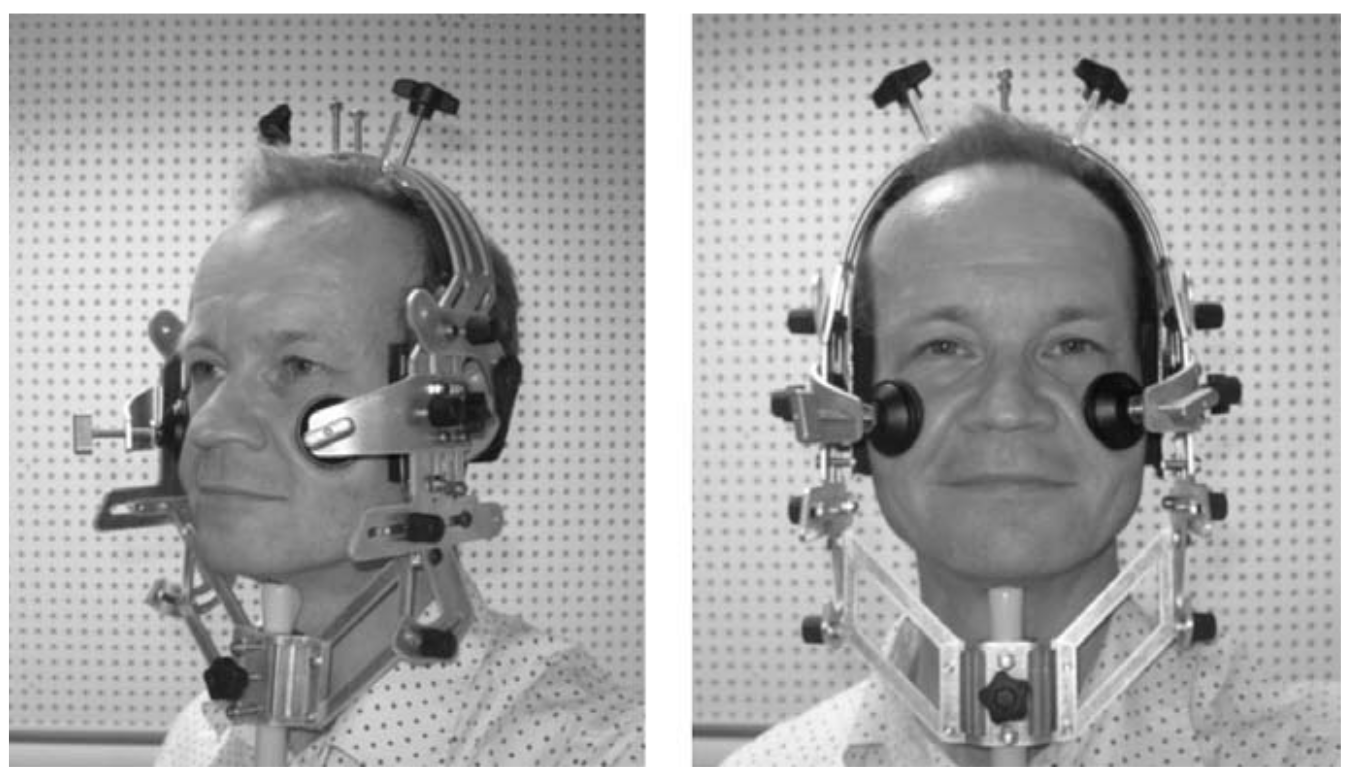
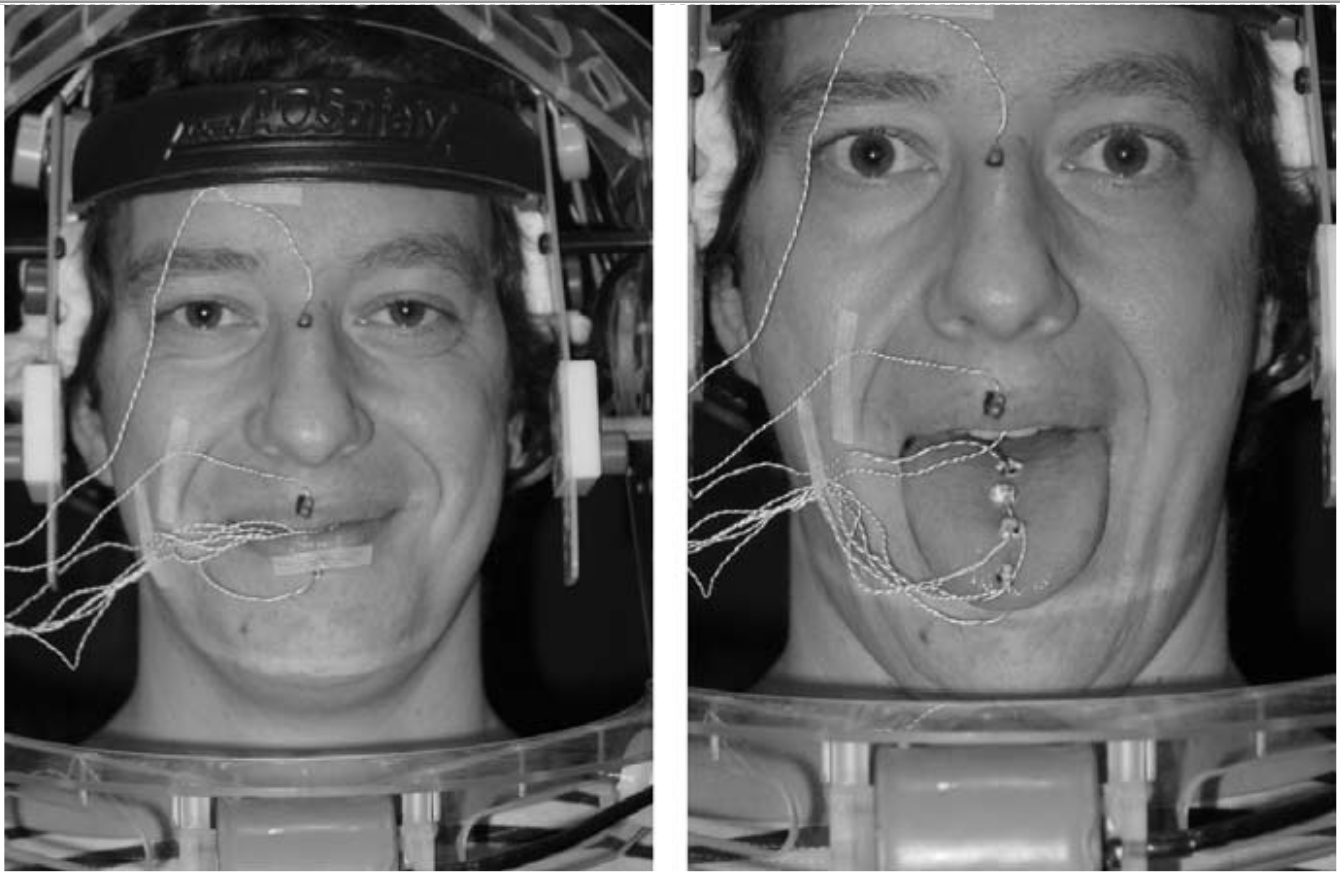
- Gick B., Wilson I. (2013) Articulatory Phonetics
- Jones M., Knight R.-A (2013) The Bloomsbury Companion to Phonetics
3. Пакеты для R
- Sueur J. (2018) Sound Analysis and Synthesis with R
3.1 vowels
Пакет для разных типов нормализации гласных: http://lingtools.uoregon.edu/norm/
3.2 phonTools
Много разных датасетов с гласными.
##
## Attaching package: 'phonTools'## The following object is masked from 'package:dplyr':
##
## slicedata(t07)
t07 %>%
ggplot(aes(f2, f1, label = vowel, color = gender))+
geom_text()+
scale_x_reverse()+
scale_y_reverse()+
labs(subtitle = "Modeling L1/L2 interactions in the perception and production of English vowels by Mandarin L1 speakers",
caption = "Thomson, R. (2007)")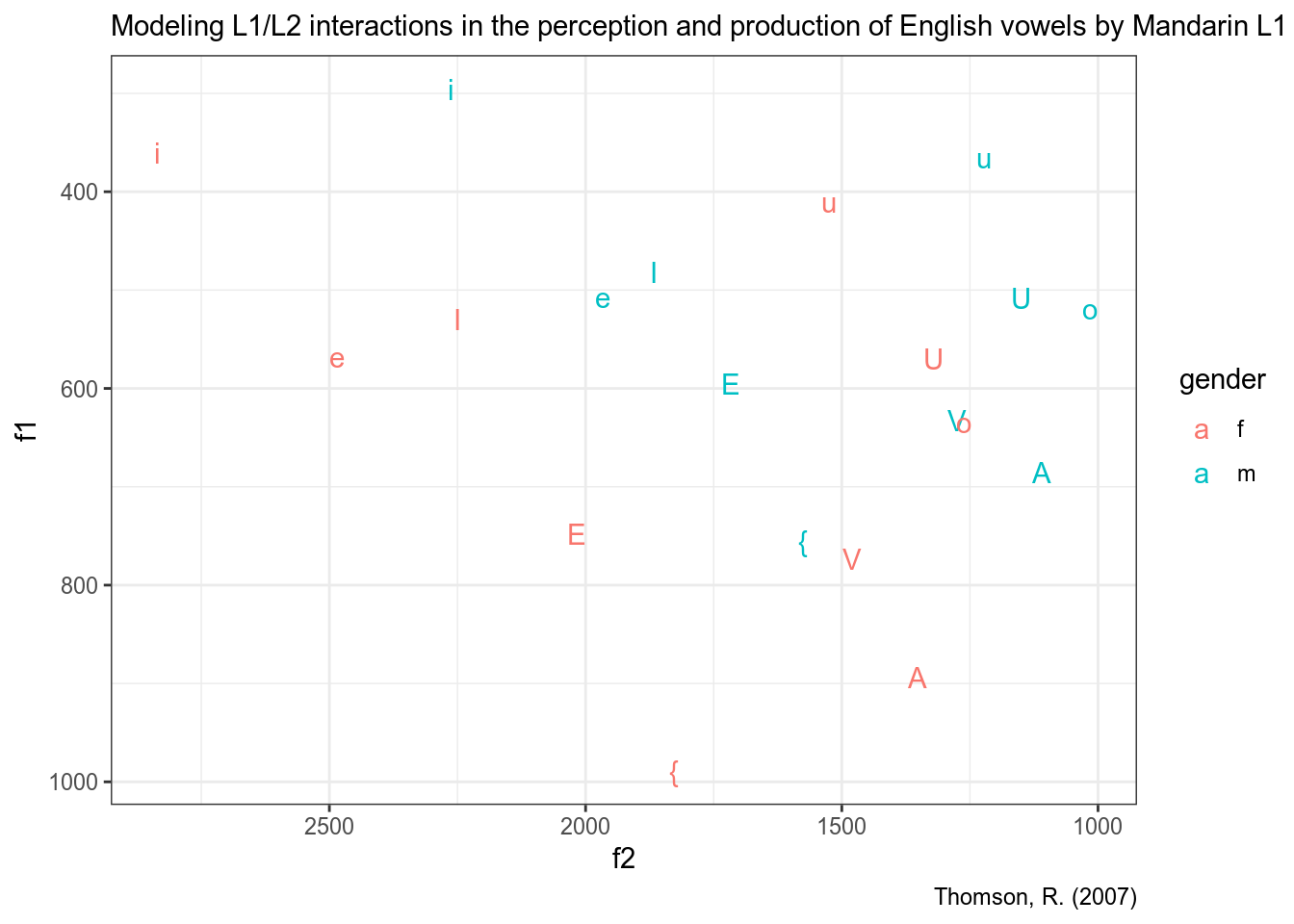
data(a96)
a96 %>%
ggplot(aes(f2, f1, label = vowel, color = sex))+
geom_text()+
scale_x_reverse()+
scale_y_reverse()+
labs(subtitle = "An acoustic analysis of modern Hebrew vowels and voiced consonants",
caption = "Aronson et al. (1996)")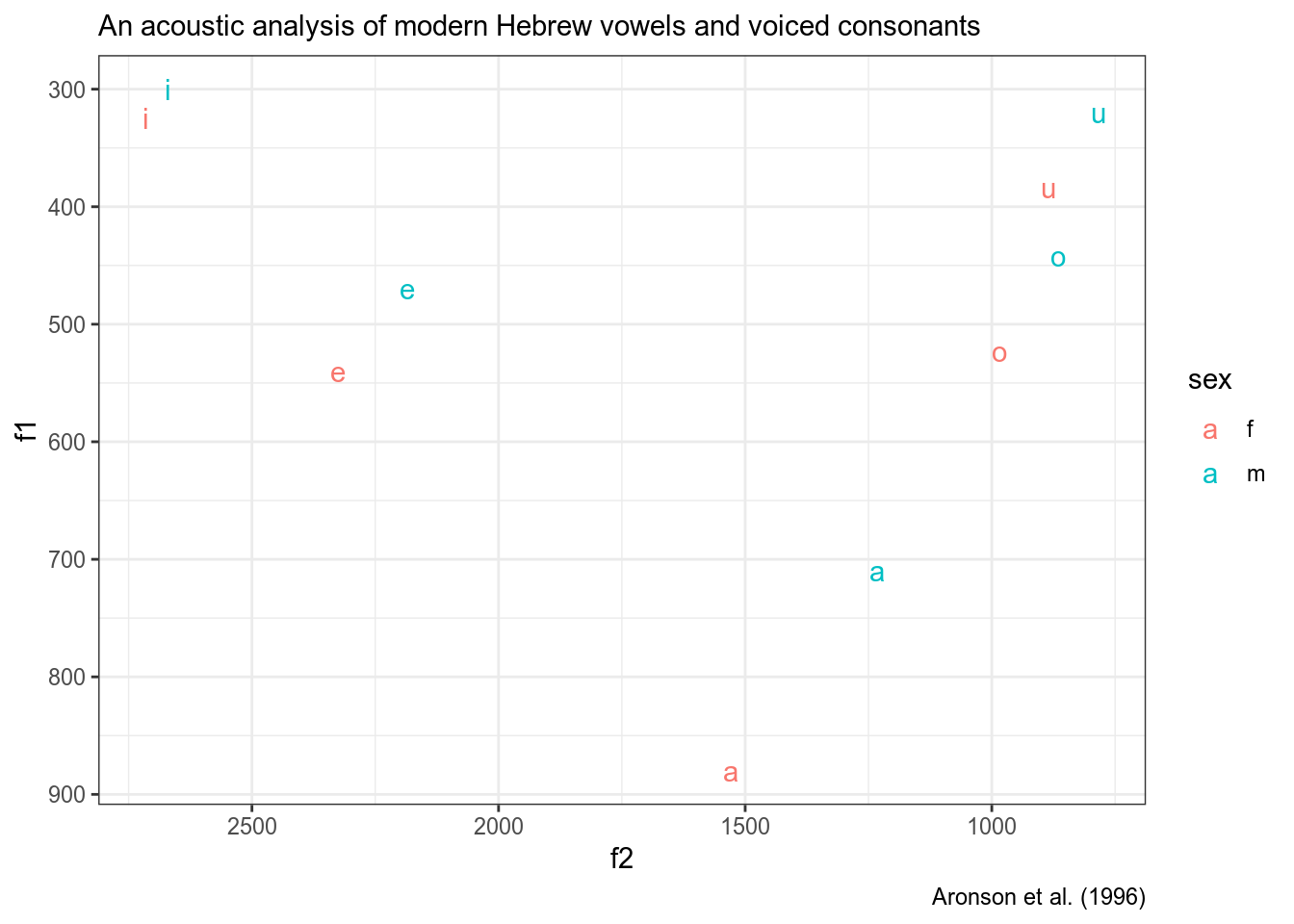
3.3 phonfieldwork
Пока мой пакет не загрузили на CRAN, его устанавливать нужно так:
install.packages("devtools")
devtools::install_github("agricolamz/phonfieldwork")
library(phonfieldwork)create_presentation()rename_soundfiles()concatenate_soundfiles()annotate_textgrid()extract_intervals()tier_to_df()иdf_to_tier()
5. Костя Филатов – Редукция гласных в рутульском
4. Домашнее задание
4.1 Более простое
Вот звук и текстгрид. Разметьте CD и VOT и извлеките их при помощи скрипта Lennes M. длительность и визуализируйте при помощи R скрипта.
4.2 Более сложное
На флешке есть мои данные с абазинскими гласными и их разметкой. Воспользуйтесь вот этим скриптом на гитхабе, чтобы извлечь форманты. Отфильтруйте полученные данные в R, чтобы остались только гласные a и ə. Постройте регрессию:
- предсказывающую f1 по типу гласного и длительносте
- предсказывающую f2 по типу гласного и длительносте
Помните про случайные эффекты.