6 Визуализация данных
library("tidyverse")6.1 Зачем визуализировать данные?
6.1.1 Квартет Анскомба
В работе Anscombe, F. J. (1973). “Graphs in Statistical Analysis” представлен следующий датасет:
quartet <- read_csv("https://raw.githubusercontent.com/agricolamz/2020-2021-ds4dh/master/data/anscombe.csv")
quartetquartet %>%
group_by(dataset) %>%
summarise(mean_X = mean(x),
mean_Y = mean(y),
sd_X = sd(x),
sd_Y = sd(y),
cor = cor(x, y),
n_obs = n()) %>%
select(-dataset) %>%
round(2)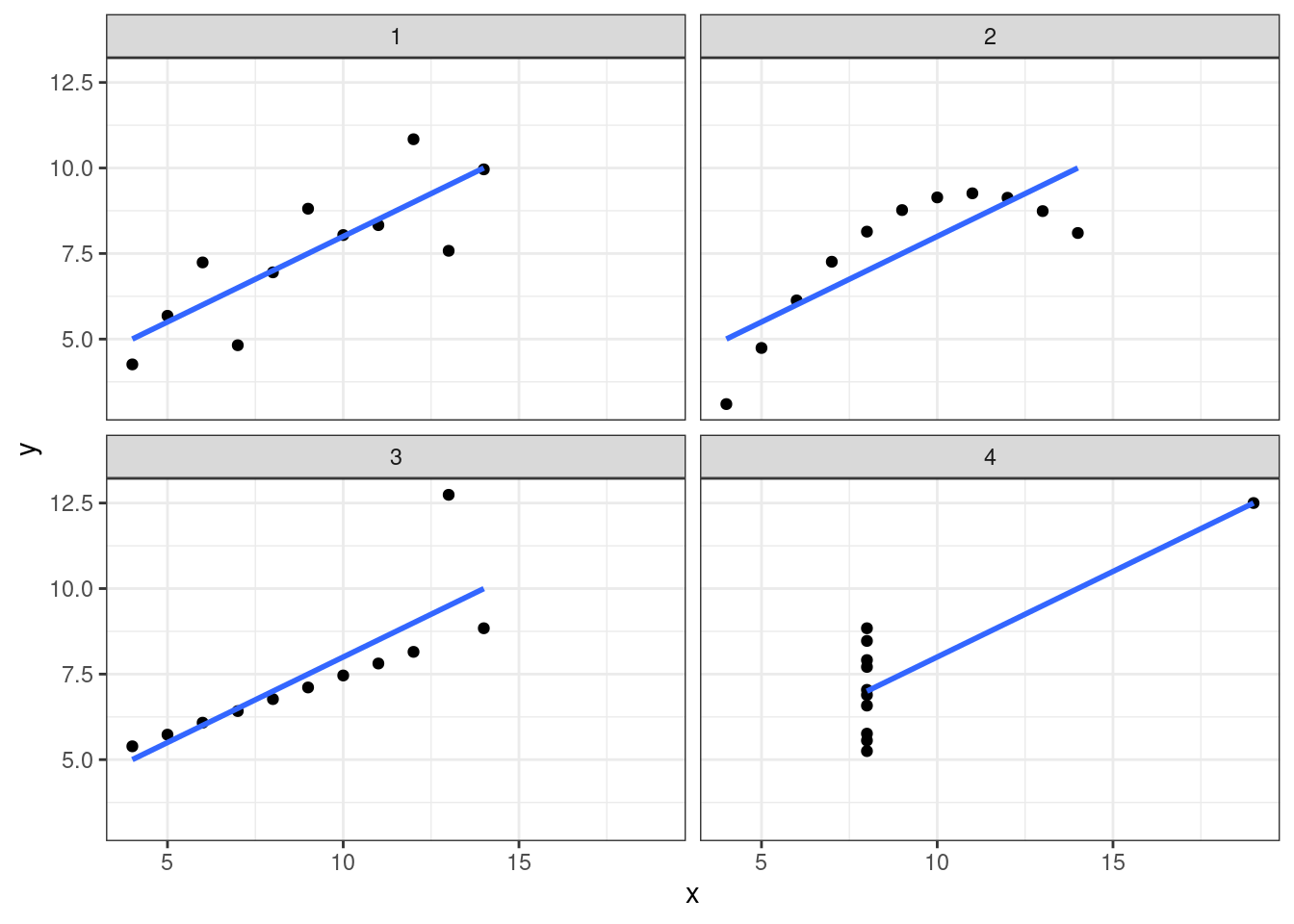
6.1.2 Датазаурус
В работе Matejka and Fitzmaurice (2017) “Same Stats, Different Graphs” были представлены следующие датасеты:
datasaurus <- read_csv("https://raw.githubusercontent.com/agricolamz/2020-2021-ds4dh/master/data/datasaurus.csv")
datasaurus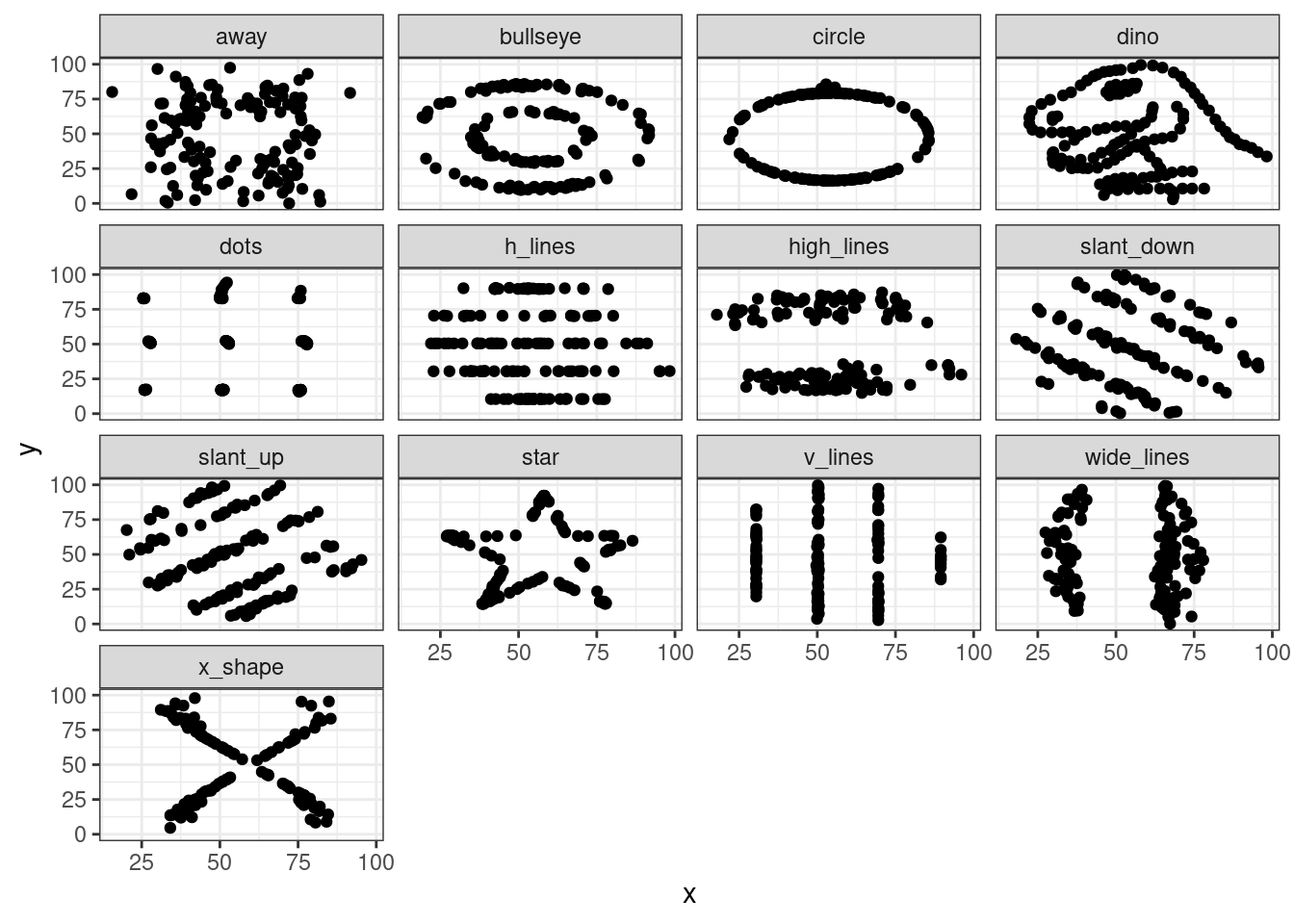
datasaurus %>%
group_by(dataset) %>%
summarise(mean_X = mean(x),
mean_Y = mean(y),
sd_X = sd(x),
sd_Y = sd(y),
cor = cor(x, y),
n_obs = n()) %>%
select(-dataset) %>%
round(1)6.2 Основы ggplot2
Пакет ggplot2 – современный стандарт для создания графиков в R. Для этого пакета пишут массу расширений. В сжатом виде информация про ggplot2 содержиться здесь.
6.2.1 Диаграмма рассеяния (Scaterplot)
- ggplot2
ggplot(data = diamonds, aes(carat, price)) +
geom_point()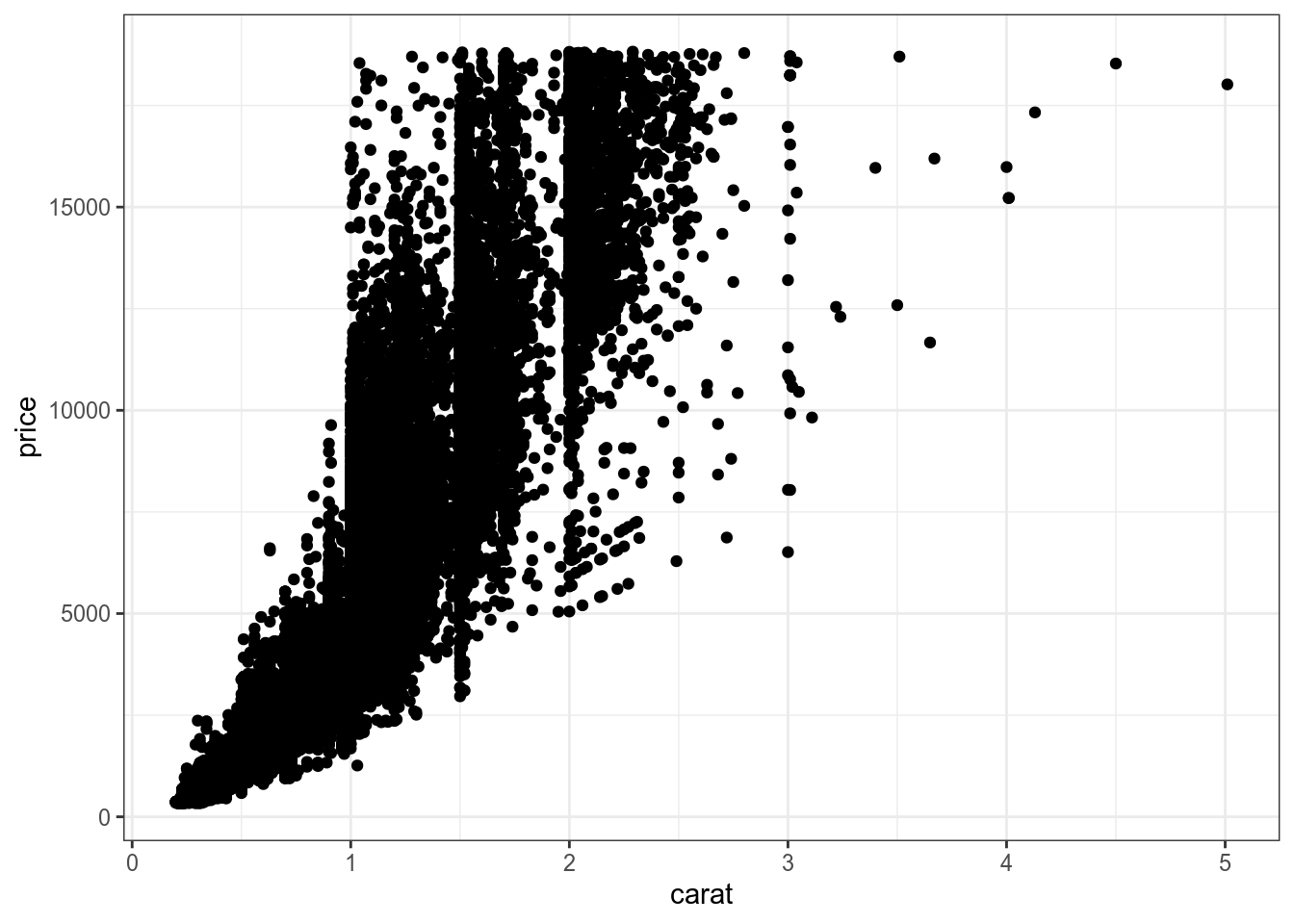
- dplyr, ggplot2
diamonds %>%
ggplot(aes(carat, price))+
geom_point()
6.2.2 Слои
diamonds %>%
ggplot(aes(carat, price))+
geom_point()+
geom_smooth()## `geom_smooth()` using method = 'gam' and formula 'y ~ s(x, bs = "cs")'
diamonds %>%
ggplot(aes(carat, price))+
geom_smooth()+
geom_point()## `geom_smooth()` using method = 'gam' and formula 'y ~ s(x, bs = "cs")'
6.2.3 aes()
diamonds %>%
ggplot(aes(carat, price, color = cut))+
geom_point()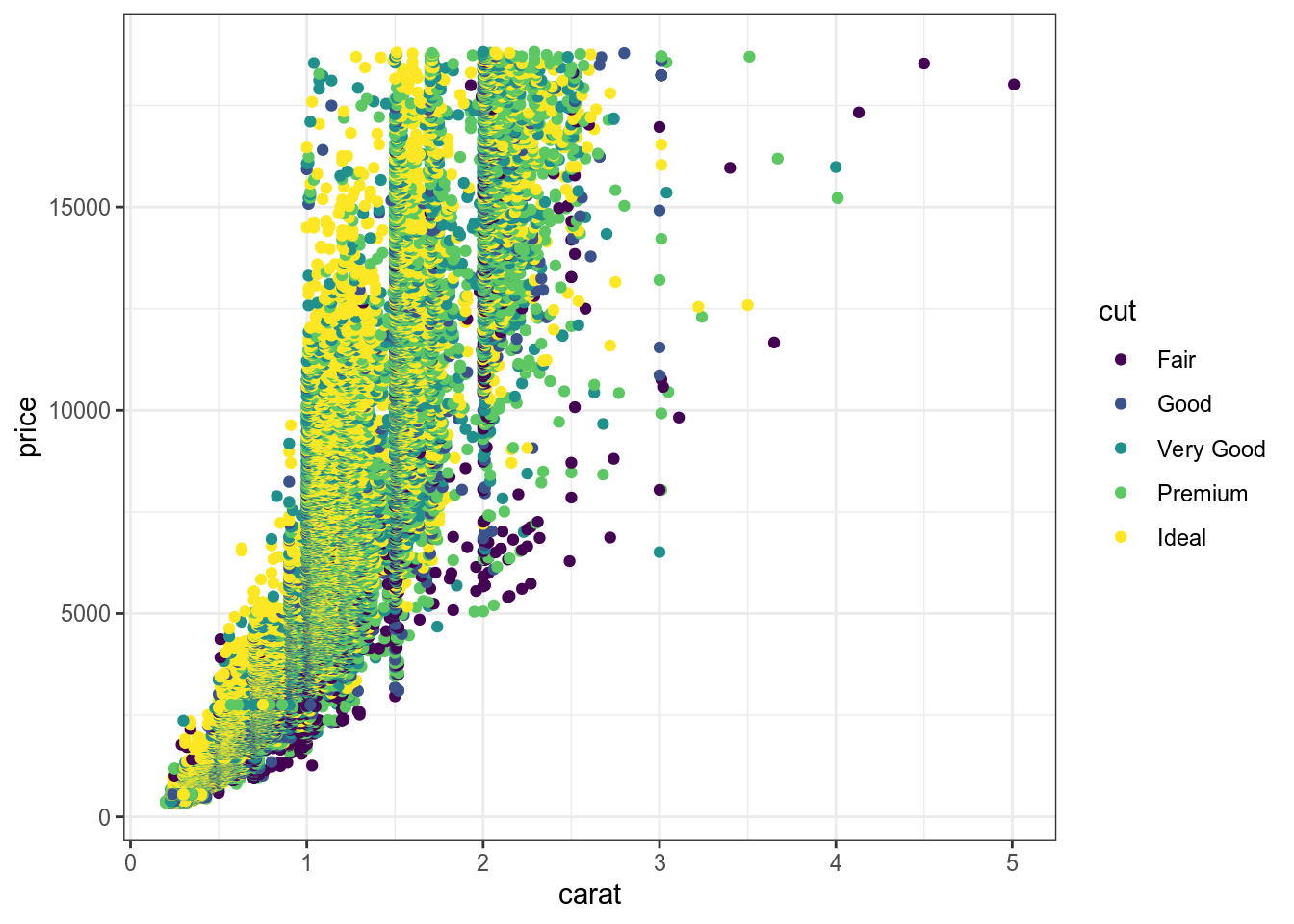
diamonds %>%
ggplot(aes(carat, price))+
geom_point(color = "green")
diamonds %>%
ggplot(aes(carat, price))+
geom_point(aes(color = cut))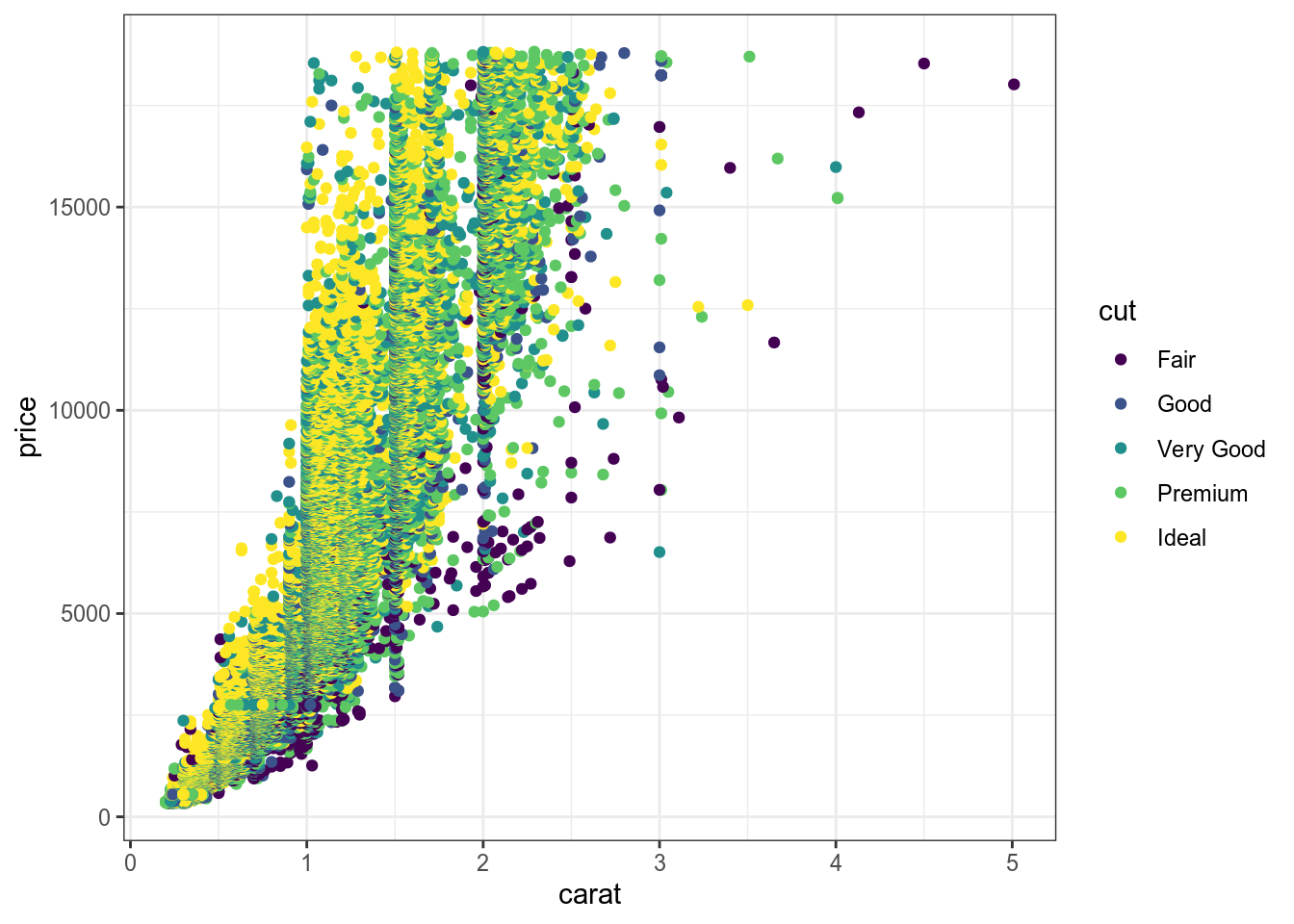
diamonds %>%
ggplot(aes(carat, price, shape = cut))+
geom_point()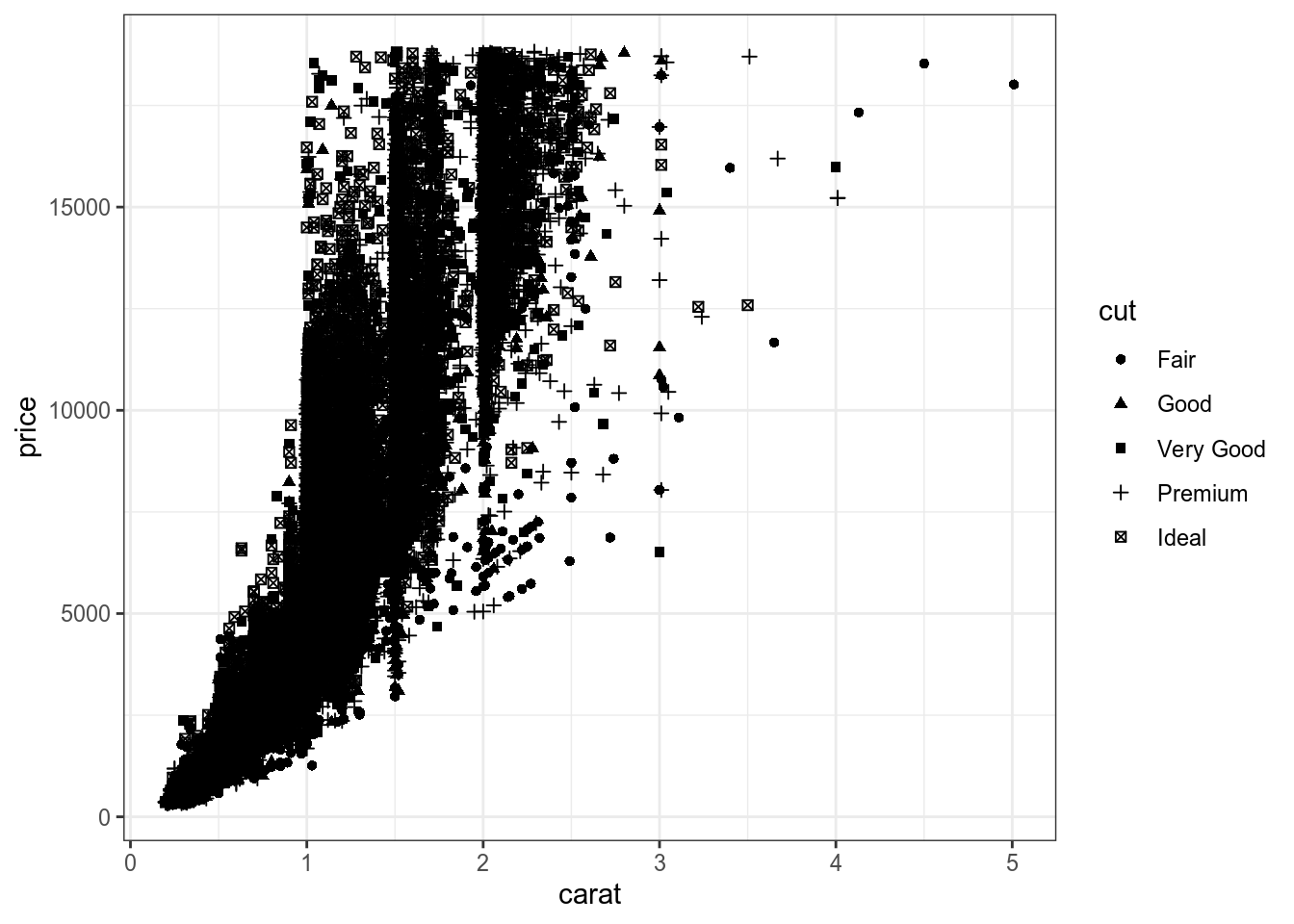
diamonds %>%
ggplot(aes(carat, price, label = color))+
geom_text()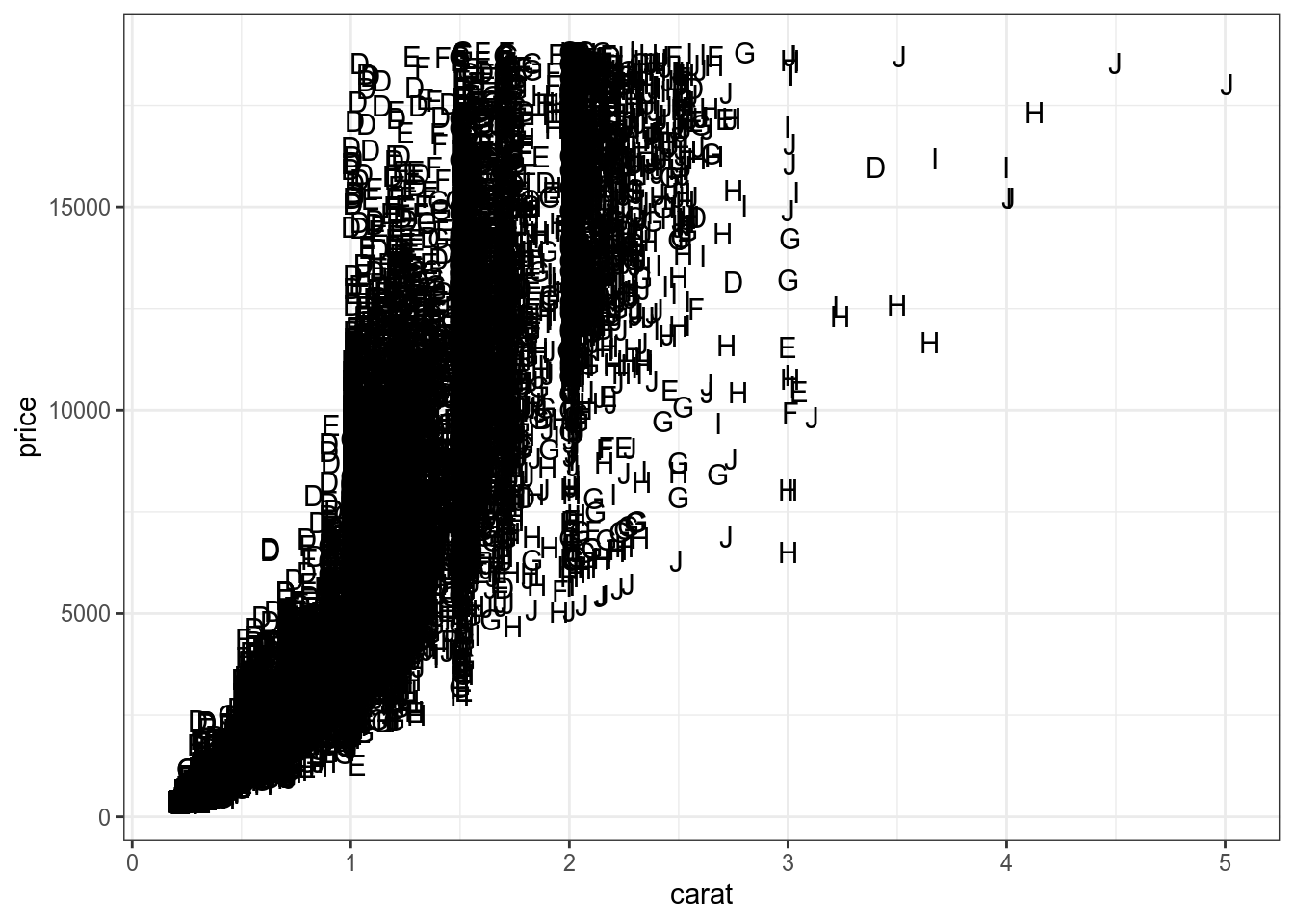
diamonds %>%
slice(1:100) %>%
ggplot(aes(carat, price, label = color))+
geom_label()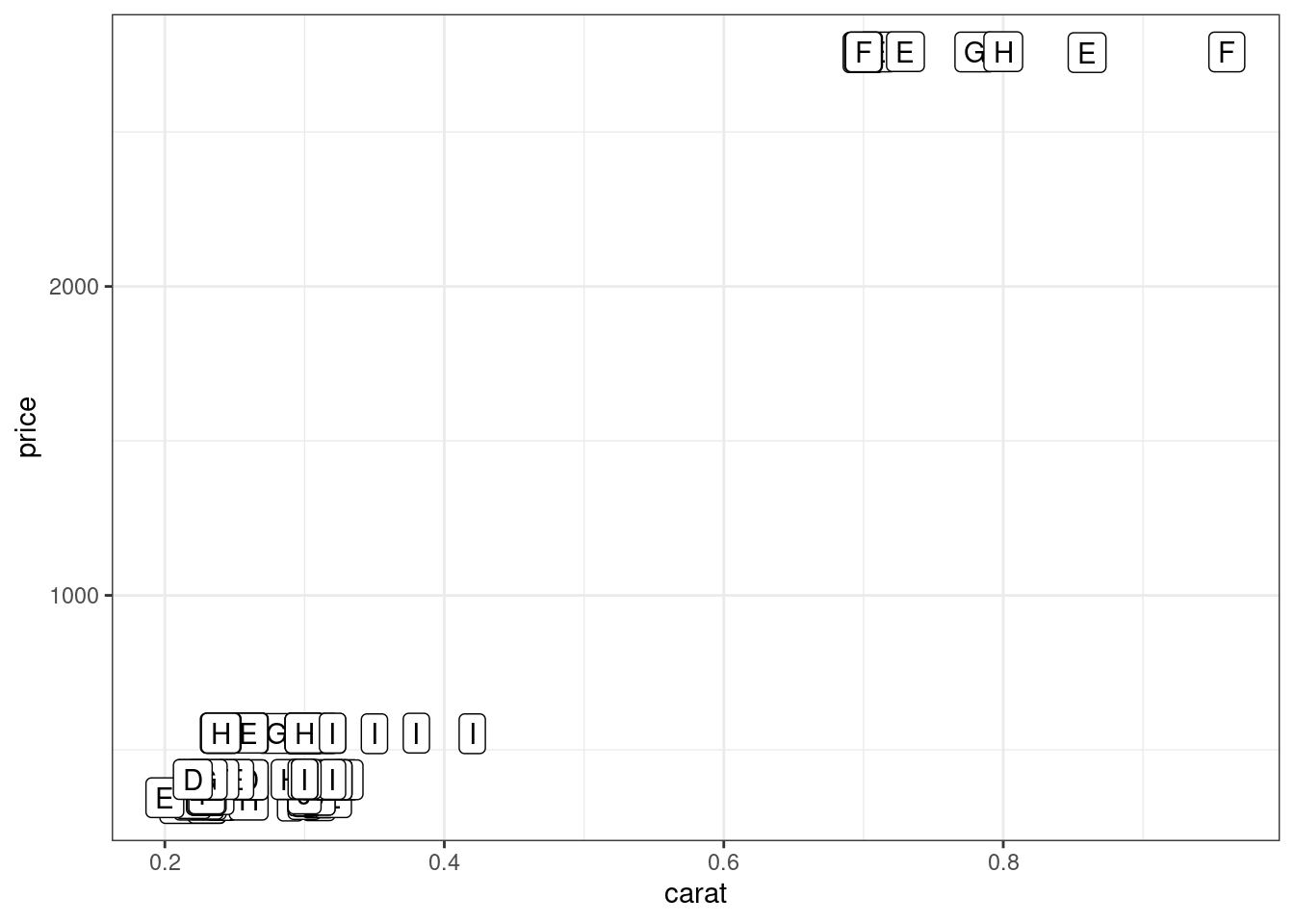
Иногда аннотации налезают друг на друга:
library(ggrepel)
diamonds %>%
slice(1:100) %>%
ggplot(aes(carat, price, label = color))+
geom_text_repel()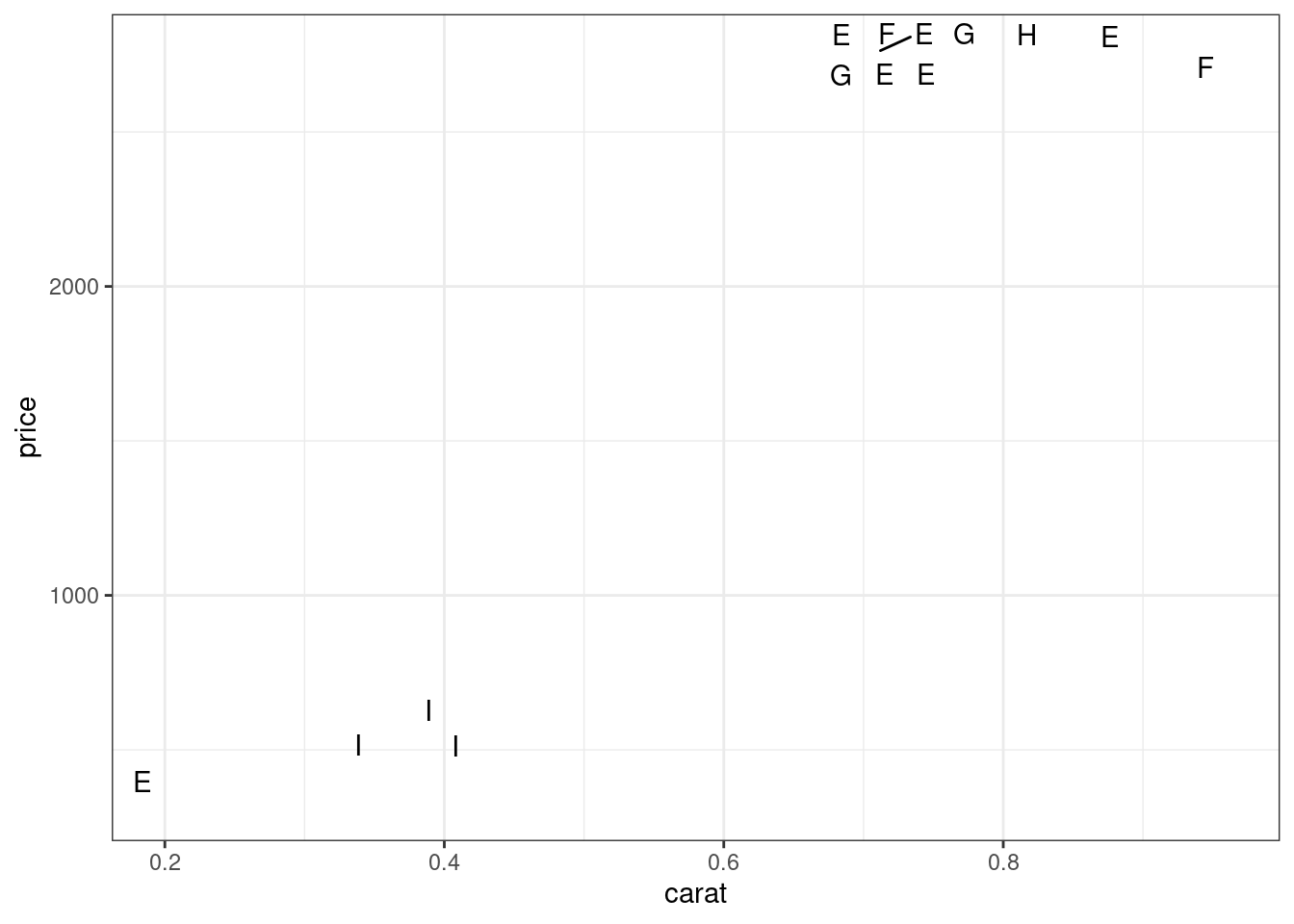
diamonds %>%
slice(1:100) %>%
ggplot(aes(carat, price, label = color))+
geom_text_repel()+
geom_point()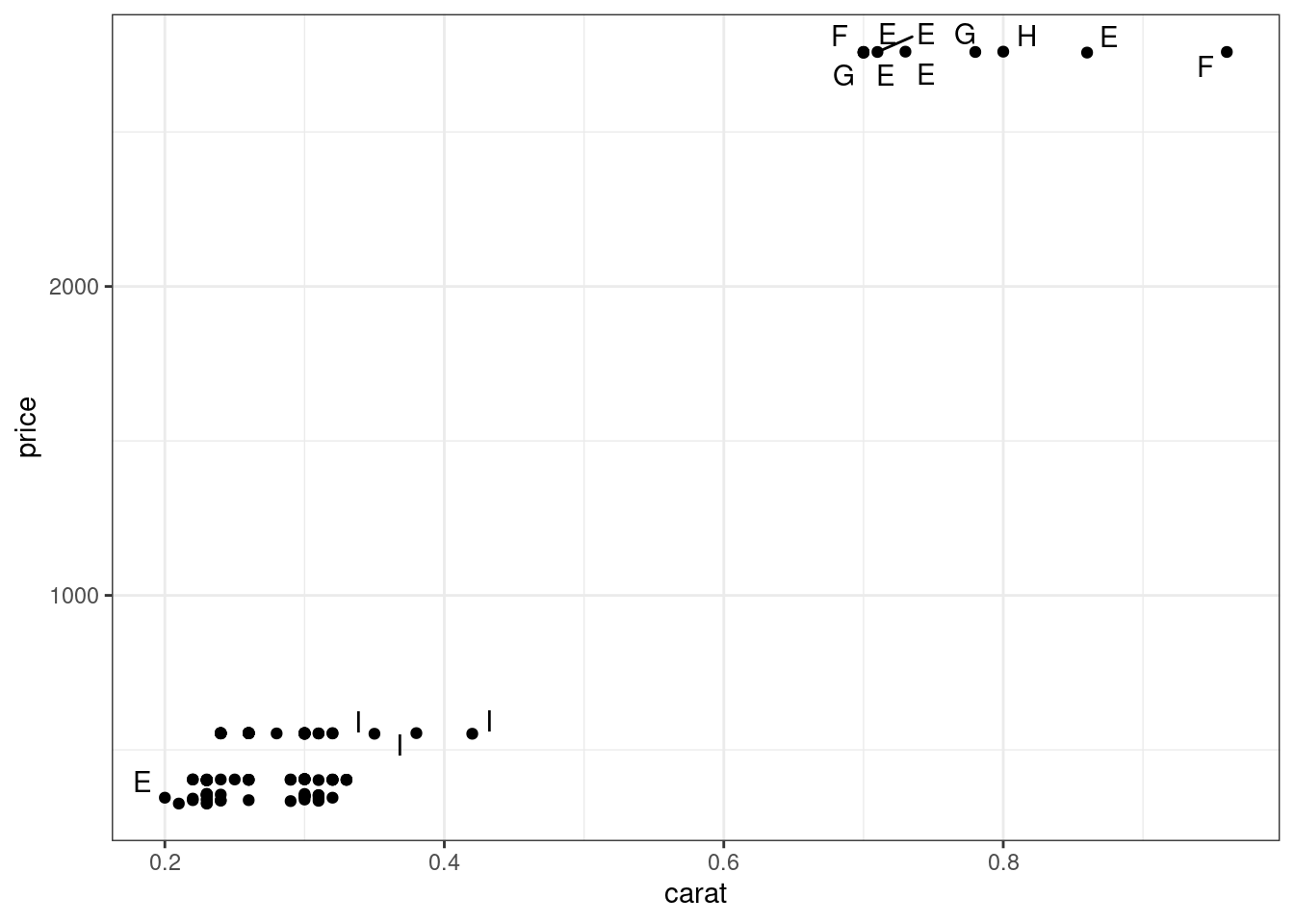
diamonds %>%
slice(1:100) %>%
ggplot(aes(carat, price, label = color, fill = cut))+ # fill отвечает за закрашивание
geom_label_repel(alpha = 0.5)+ # alpha отвечает за прозрачность
geom_point()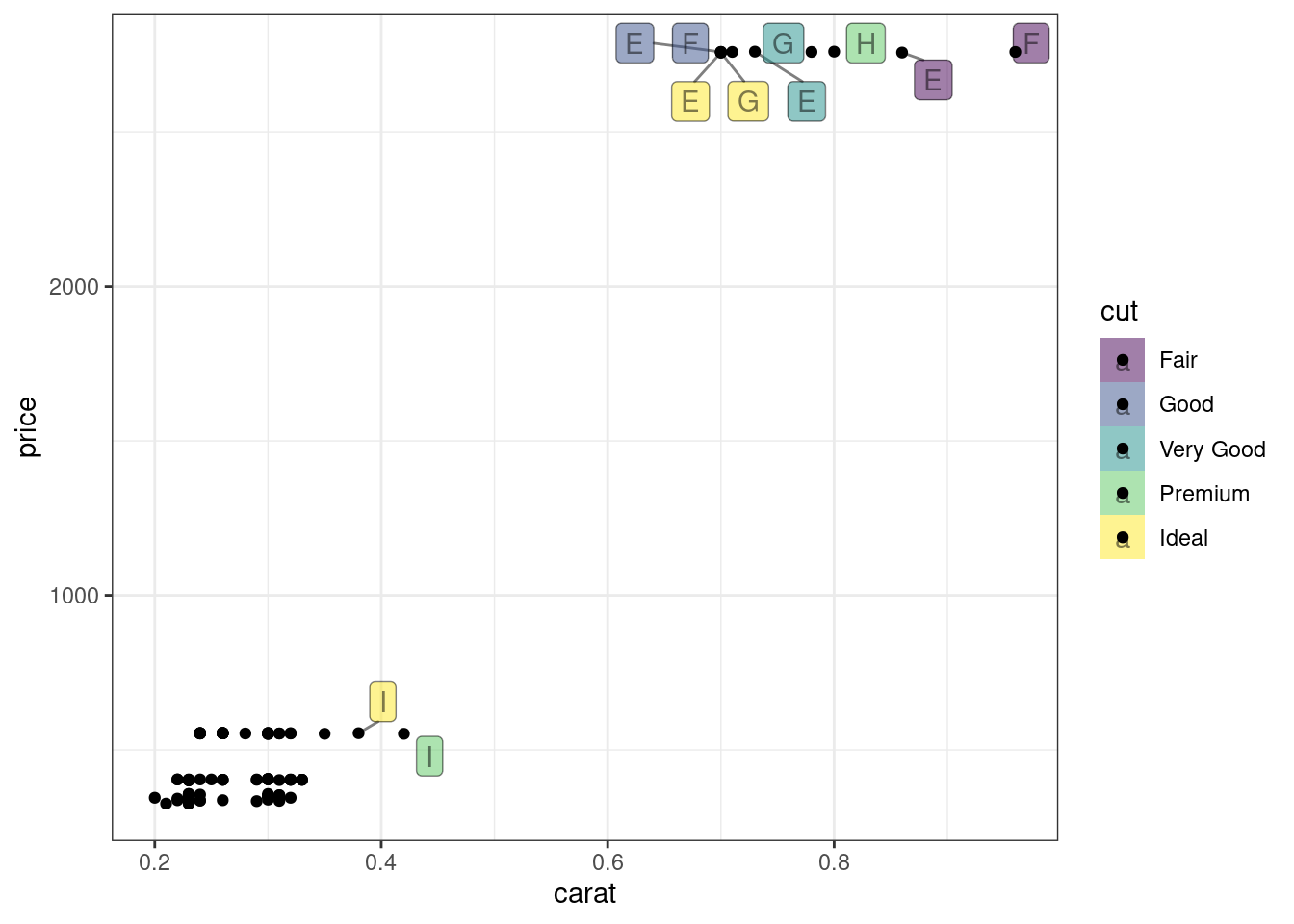
6.2.4 Оформление
diamonds %>%
ggplot(aes(carat, price, color = cut))+
geom_point() +
labs(x = "вес (в каратах)",
y = "цена (в долларах)",
title = "Связь цены и веса бриллиантов",
subtitle = "Данные взяты из датасеты diamonds",
caption = "график сделан при помощи пакета ggplot2")+
theme(legend.position = "bottom") # у функции theme() огромный функционал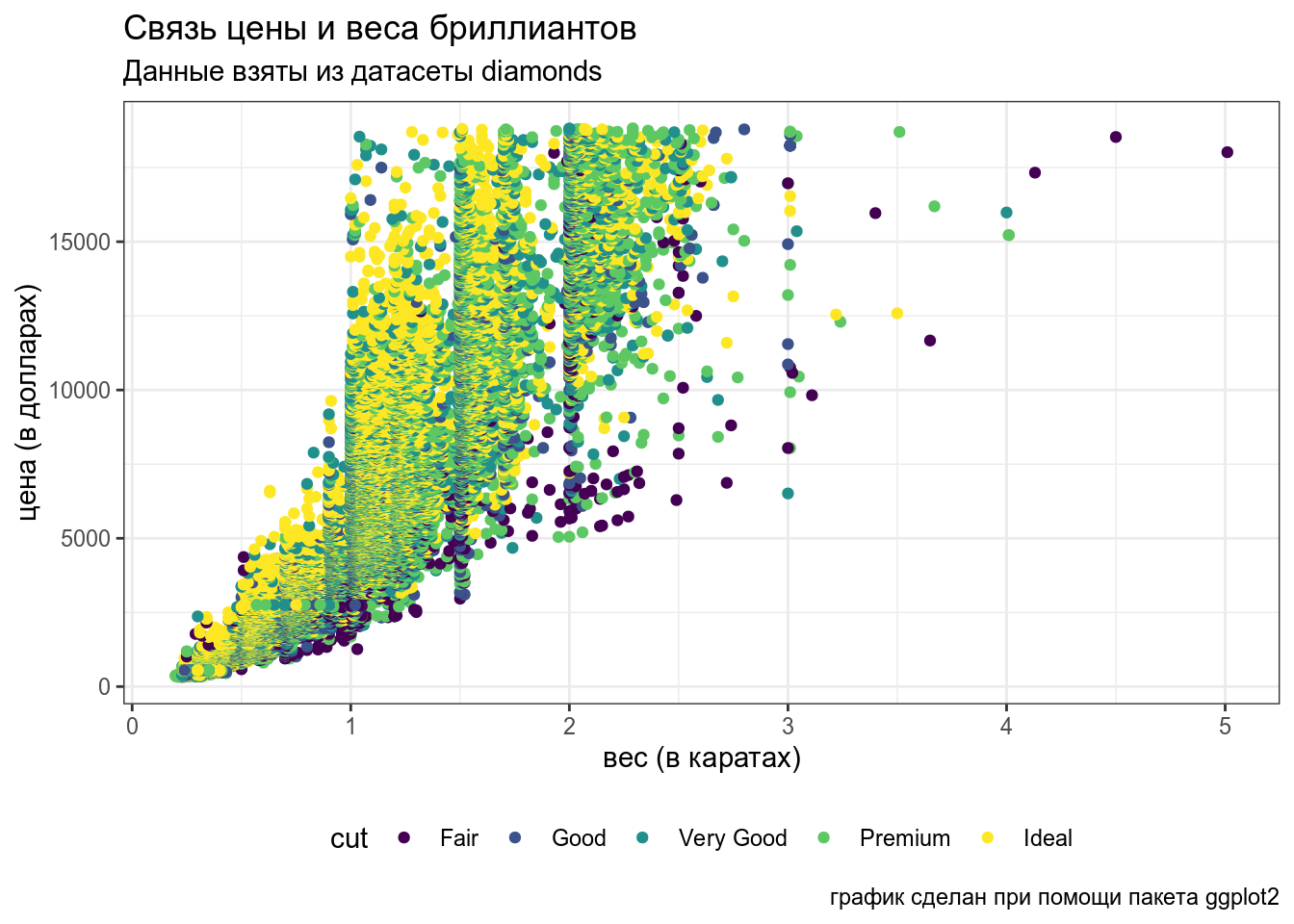
6.2.5 Логарифмические шкалы
Рассмотрим словарь [Ляшевской, Шарова 2011]
freqdict <- read_tsv("https://github.com/agricolamz/2020-2021-ds4dh/raw/master/data/freq_dict_2011.csv")##
## ── Column specification ────────────────────────────────────────────────────────
## cols(
## lemma = col_character(),
## pos = col_character(),
## freq_ipm = col_double()
## )freqdict %>%
arrange(desc(freq_ipm)) %>%
mutate(id = 1:n()) %>%
slice(1:150) %>%
ggplot(aes(id, freq_ipm))+
geom_point()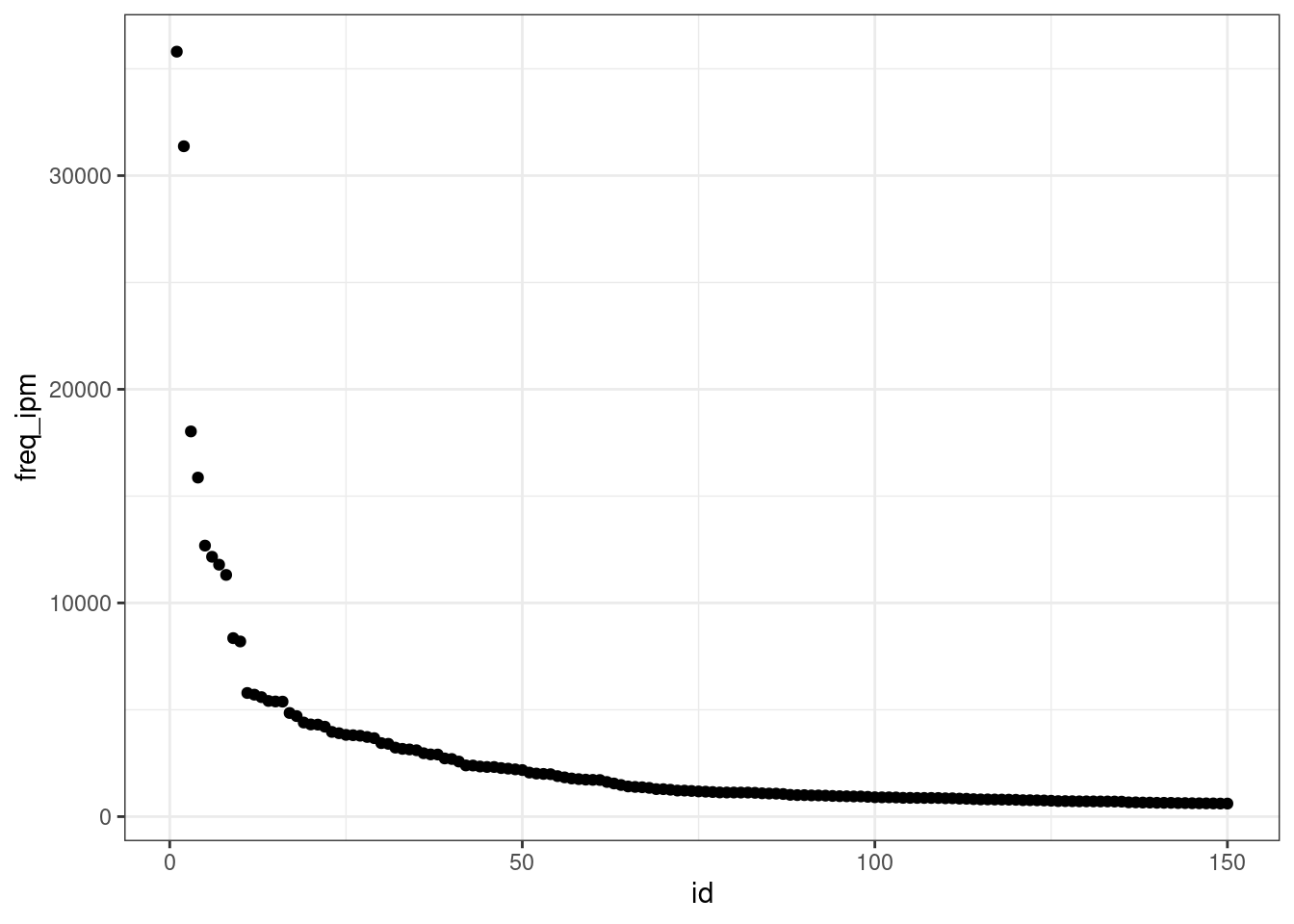
freqdict %>%
arrange(desc(freq_ipm)) %>%
mutate(id = 1:n()) %>%
slice(1:150) %>%
ggplot(aes(id, freq_ipm, label = lemma))+
geom_point()+
geom_text_repel()+
scale_y_log10()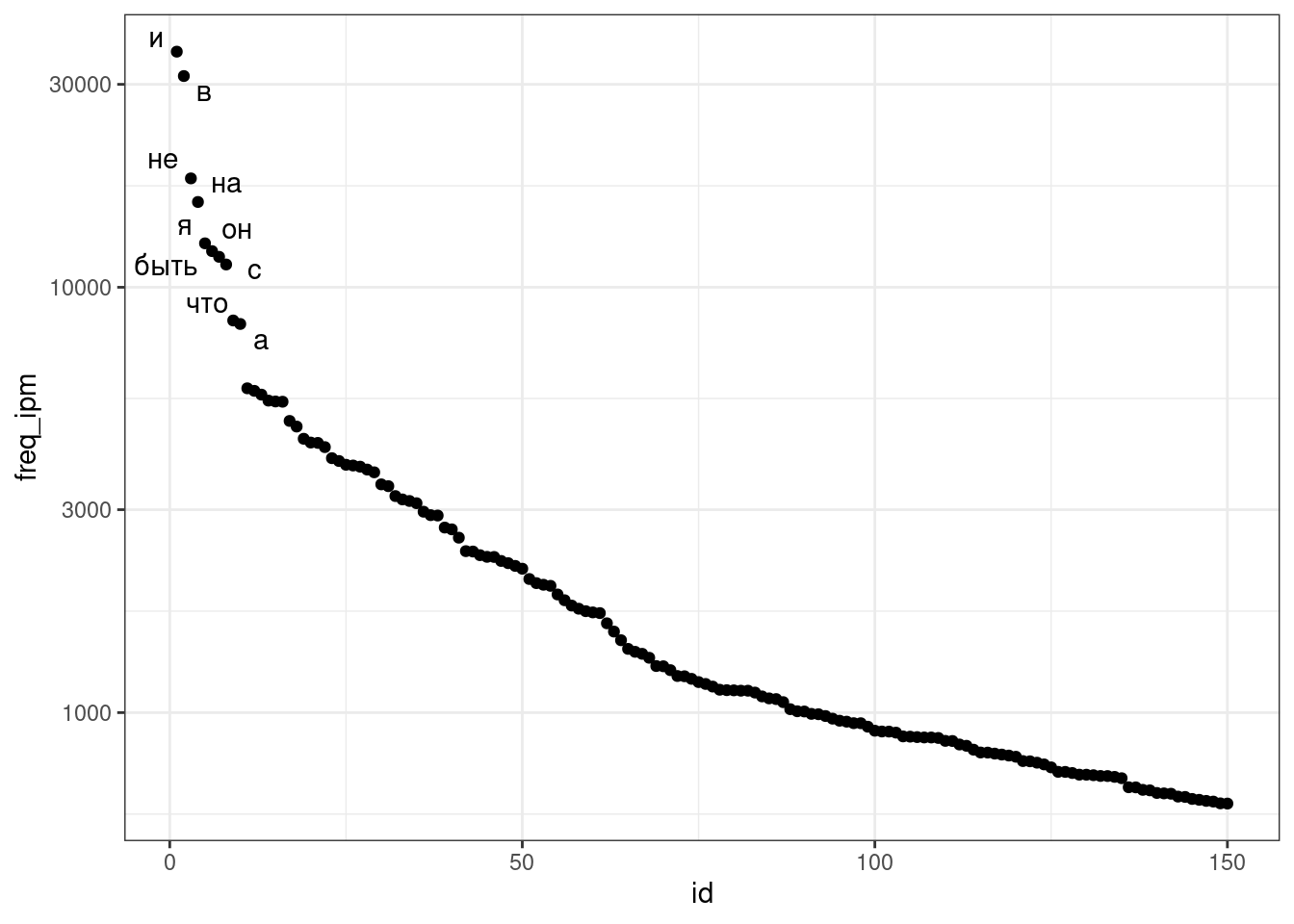
6.2.6 annotate()
Функция annotate добавляет geom к графику.
diamonds %>%
ggplot(aes(carat, price, color = cut))+
geom_point()+
annotate(geom = "rect", xmin = 4.8, xmax = 5.2,
ymin = 17500, ymax = 18500, fill = "red", alpha = 0.2) +
annotate(geom = "text", x = 4.7, y = 16600,
label = "помогите...\n я в розовом\nквадратике")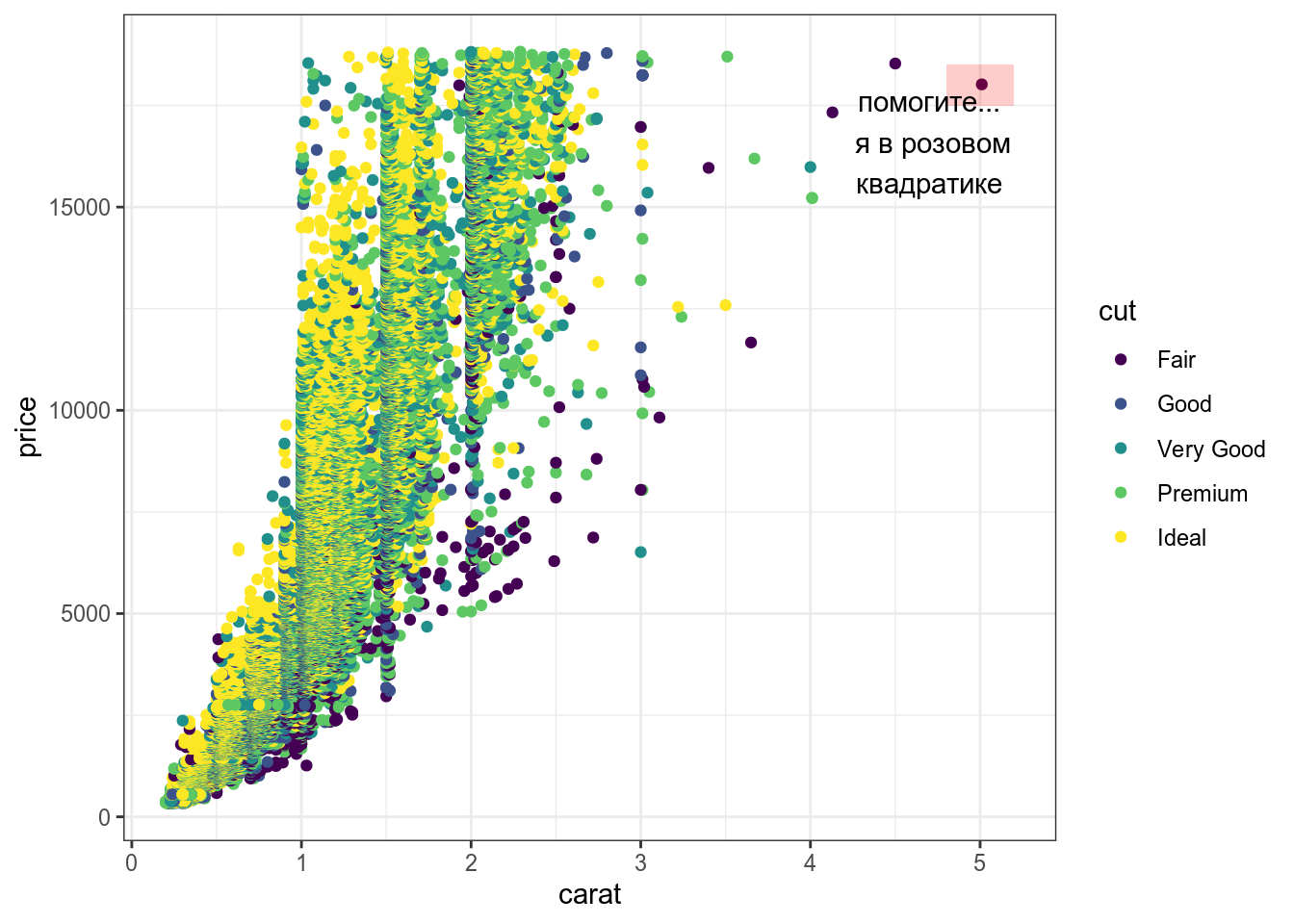
Скачайте вот этот датасет и постройте диаграмму рассеяния.
6.3 Столбчатые диаграммы (barplots)
Одна и та же информация может быть представлена в агрегированном и не агрегированном варианте:
misspelling <- read_csv("https://raw.githubusercontent.com/agricolamz/2020-2021-ds4dh/master/data/misspelling_dataset.csv")##
## ── Column specification ────────────────────────────────────────────────────────
## cols(
## correct = col_character(),
## spelling = col_character(),
## count = col_double()
## )misspelling - переменные spelling аггрегирована: для каждого значения представлено значение в столбце count, которое обозначает количество каждого из написаний
- переменные correct неаггрегированы: в этом столбце она повторяется, для того, чтобы сделать вывод, нужно отдельно посчитать количество вариантов
Для аггрегированных данных используется geom_col()
misspelling %>%
slice(1:20) %>%
ggplot(aes(spelling, count))+
geom_col()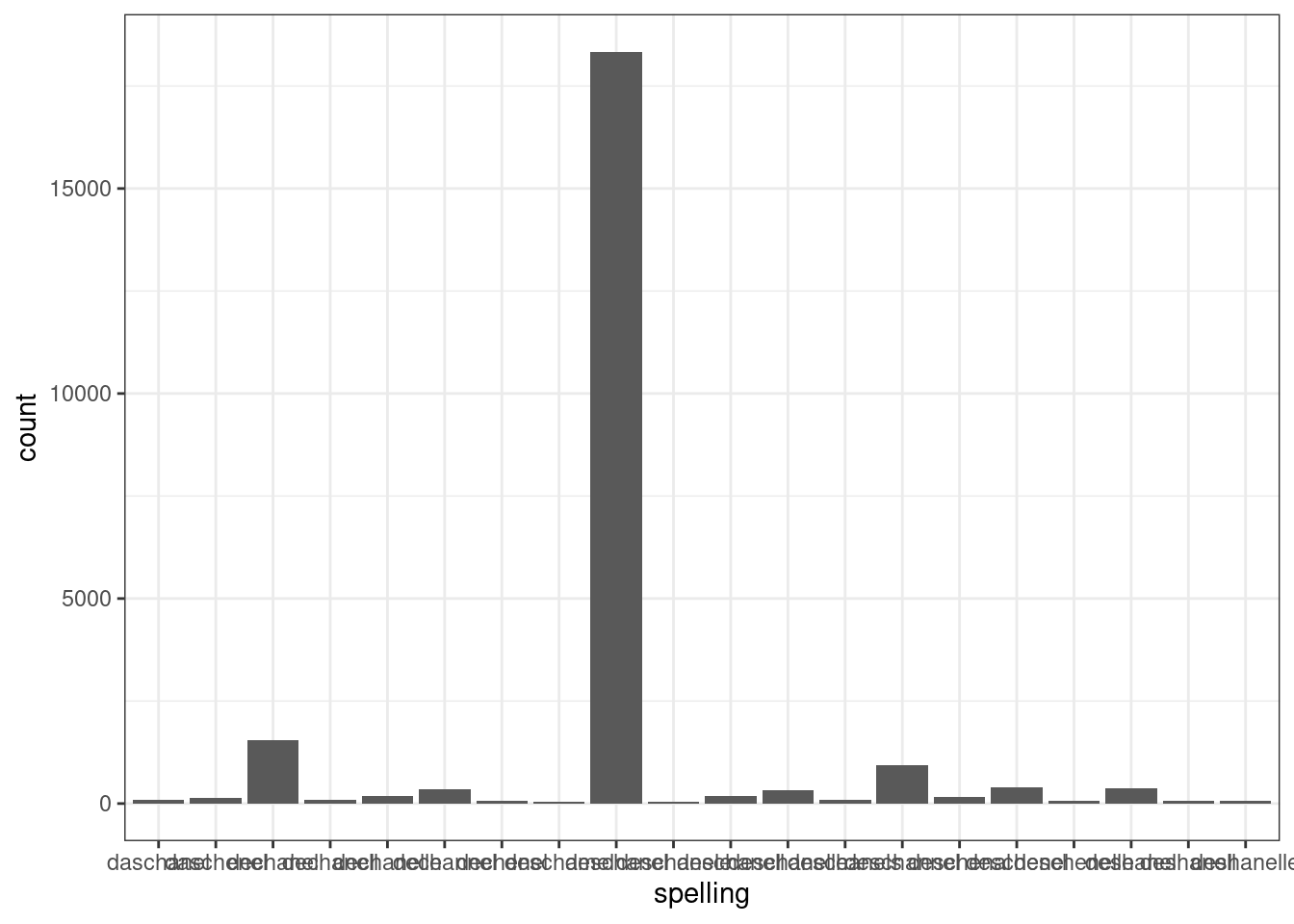
Перевернем оси:
misspelling %>%
slice(1:20) %>%
ggplot(aes(spelling, count))+
geom_col()+
coord_flip()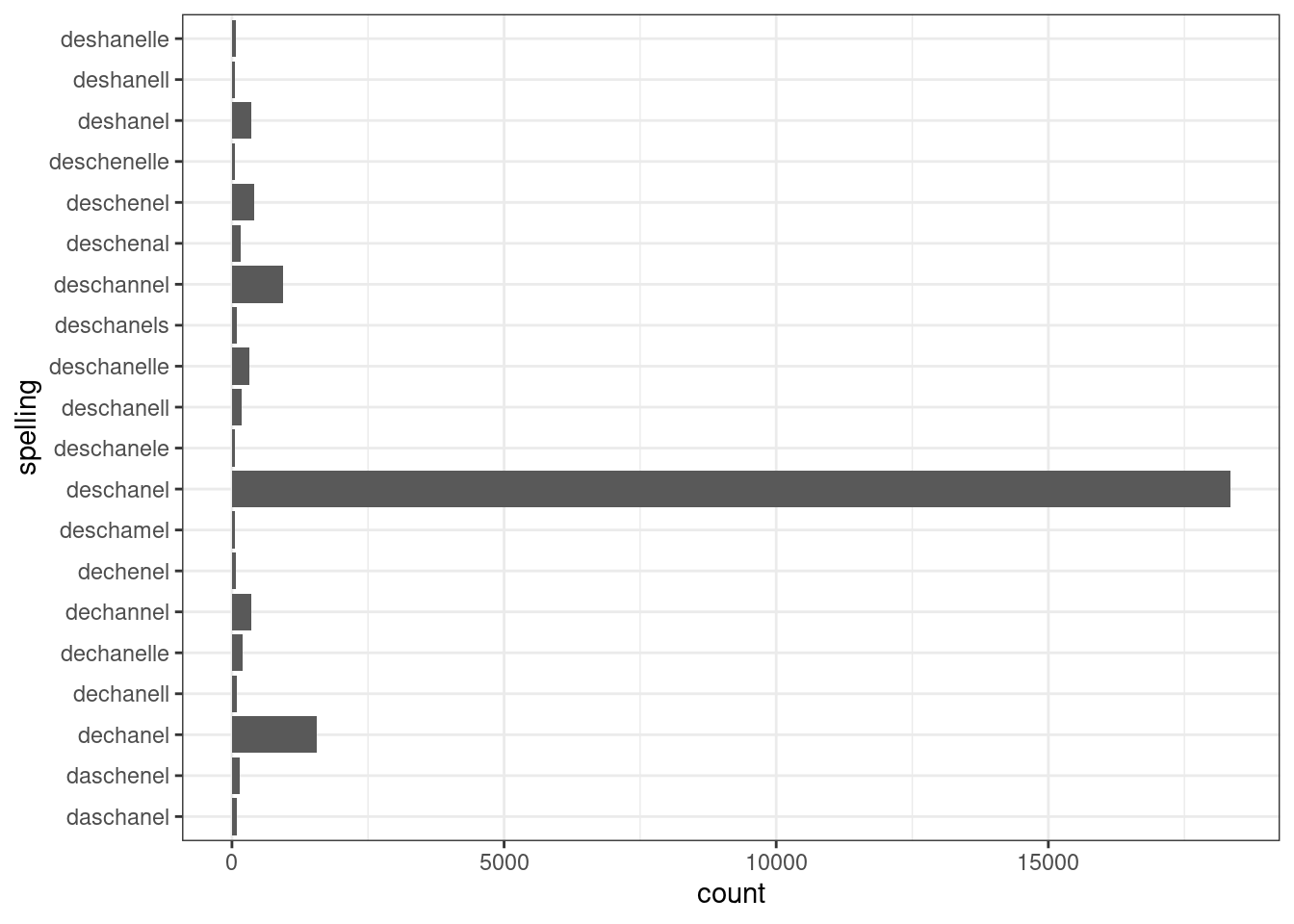
Для неаггрегированных данных используется geom_bar()
misspelling %>%
ggplot(aes(correct))+
geom_bar()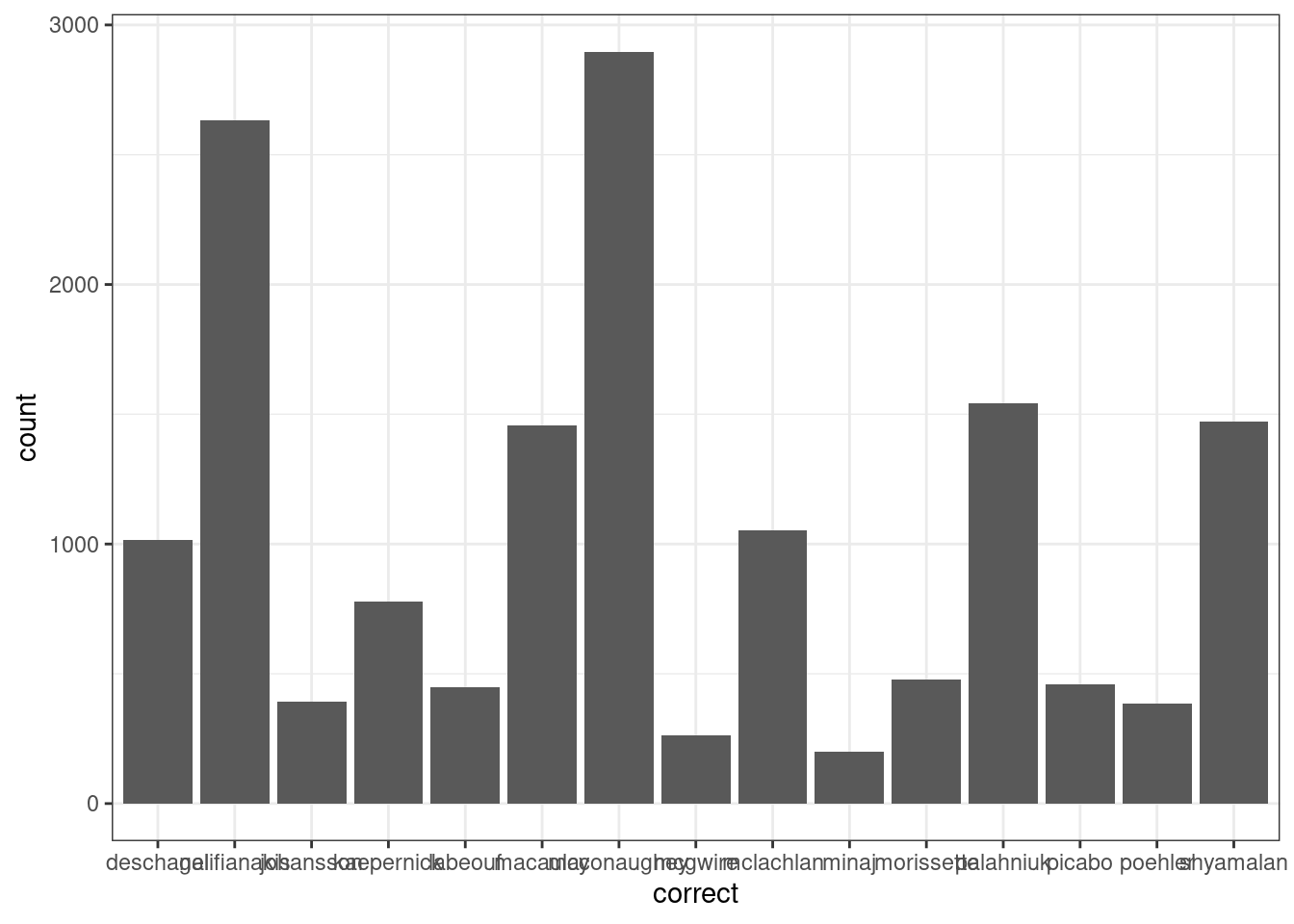
Перевернем оси:
misspelling %>%
ggplot(aes(correct))+
geom_bar()+
coord_flip()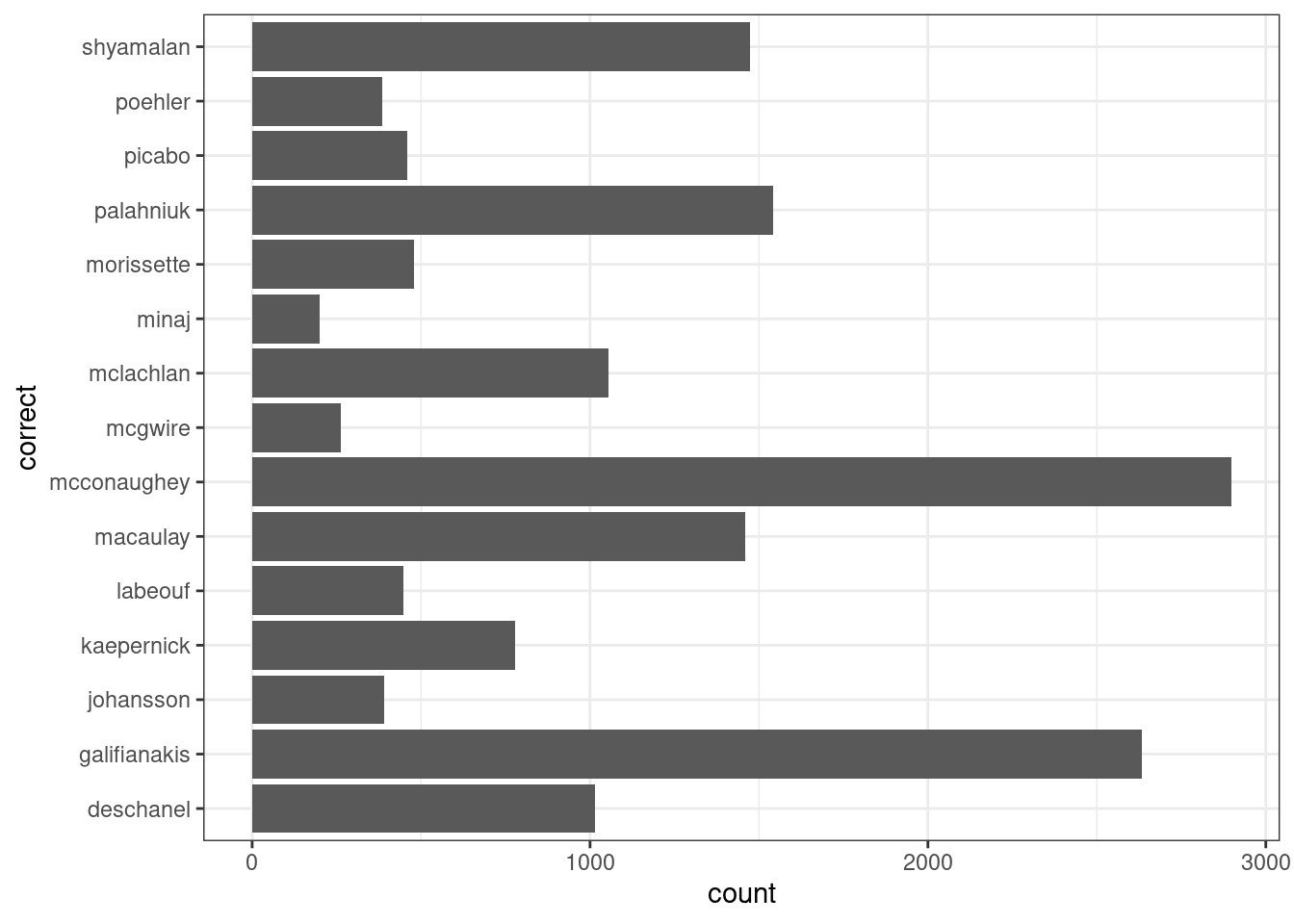
Неаггрегированный вариант можно перевести в аггрегированный:
diamonds %>%
count(cut)Аггрегированный вариант можно перевести в неаггрегированный:
diamonds %>%
count(cut) %>%
uncount(n)6.4 Факторы
Как можно заметить по предыдущему разделу, переменные на графике упорядочены по алфавиту. Чтобы это исправить нужно обсудить факторы:
my_factor <- factor(misspelling$correct)
head(my_factor)## [1] deschanel deschanel deschanel deschanel deschanel deschanel
## 15 Levels: deschanel galifianakis johansson kaepernick labeouf ... shyamalanlevels(my_factor)## [1] "deschanel" "galifianakis" "johansson" "kaepernick" "labeouf"
## [6] "macaulay" "mcconaughey" "mcgwire" "mclachlan" "minaj"
## [11] "morissette" "palahniuk" "picabo" "poehler" "shyamalan"levels(my_factor) <- rev(levels(my_factor))
head(my_factor)## [1] shyamalan shyamalan shyamalan shyamalan shyamalan shyamalan
## 15 Levels: shyamalan poehler picabo palahniuk morissette minaj ... deschanelmisspelling %>%
mutate(correct = factor(correct, levels = c("deschanel",
"galifianakis",
"johansson",
"kaepernick",
"labeouf",
"macaulay",
"mcgwire",
"mclachlan",
"minaj",
"morissette",
"palahniuk",
"picabo",
"poehler",
"shyamalan",
"mcconaughey"))) %>%
ggplot(aes(correct))+
geom_bar()+
coord_flip()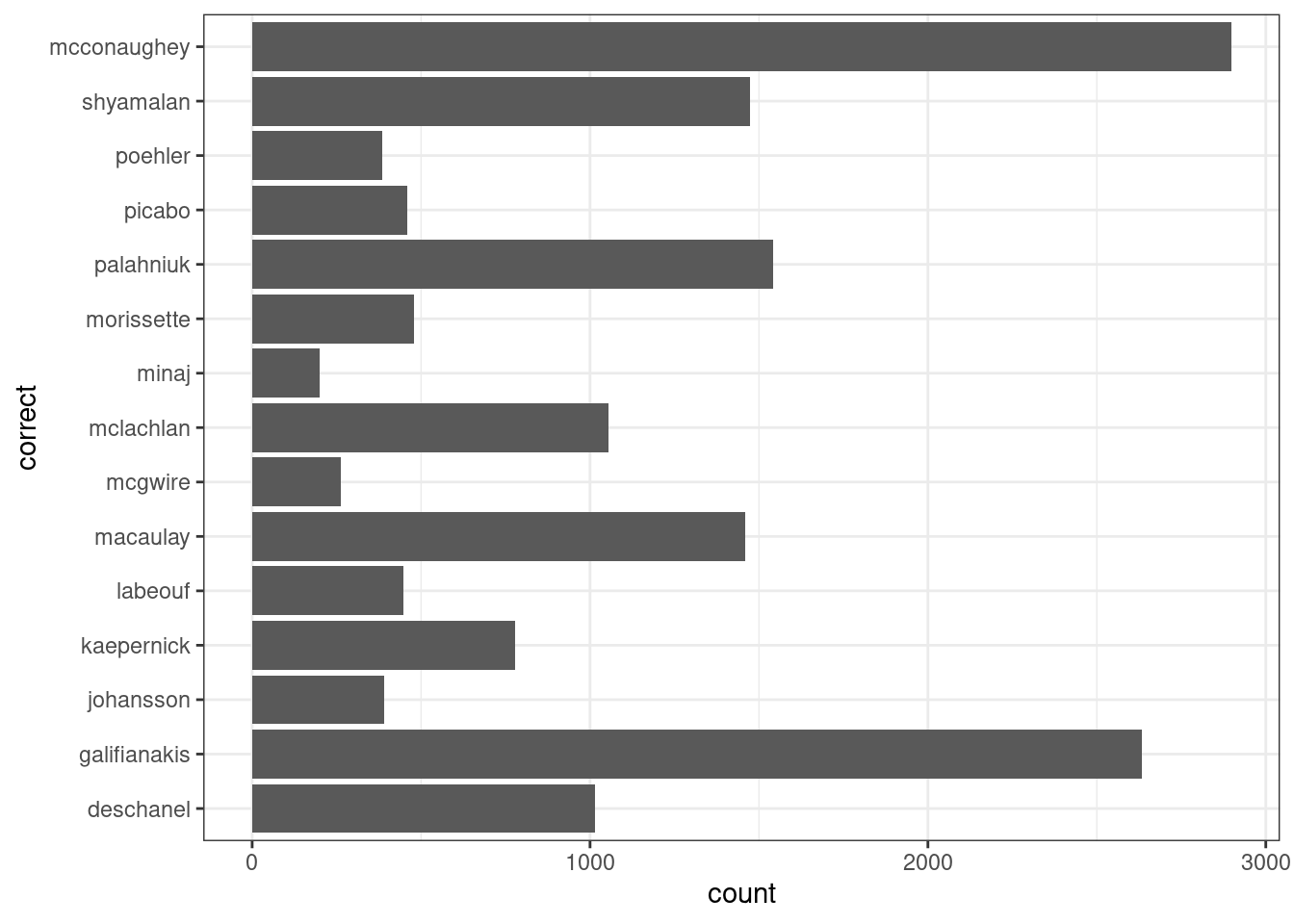
Для работы с факторами удобно использовать пакет forcats (входит в tidyverse, вот ссылка на cheatsheet).
Иногда полезной бывает функция fct_reorder():
misspelling %>%
count(correct)misspelling %>%
count(correct) %>%
ggplot(aes(fct_reorder(correct, n), n))+
geom_col()+
coord_flip()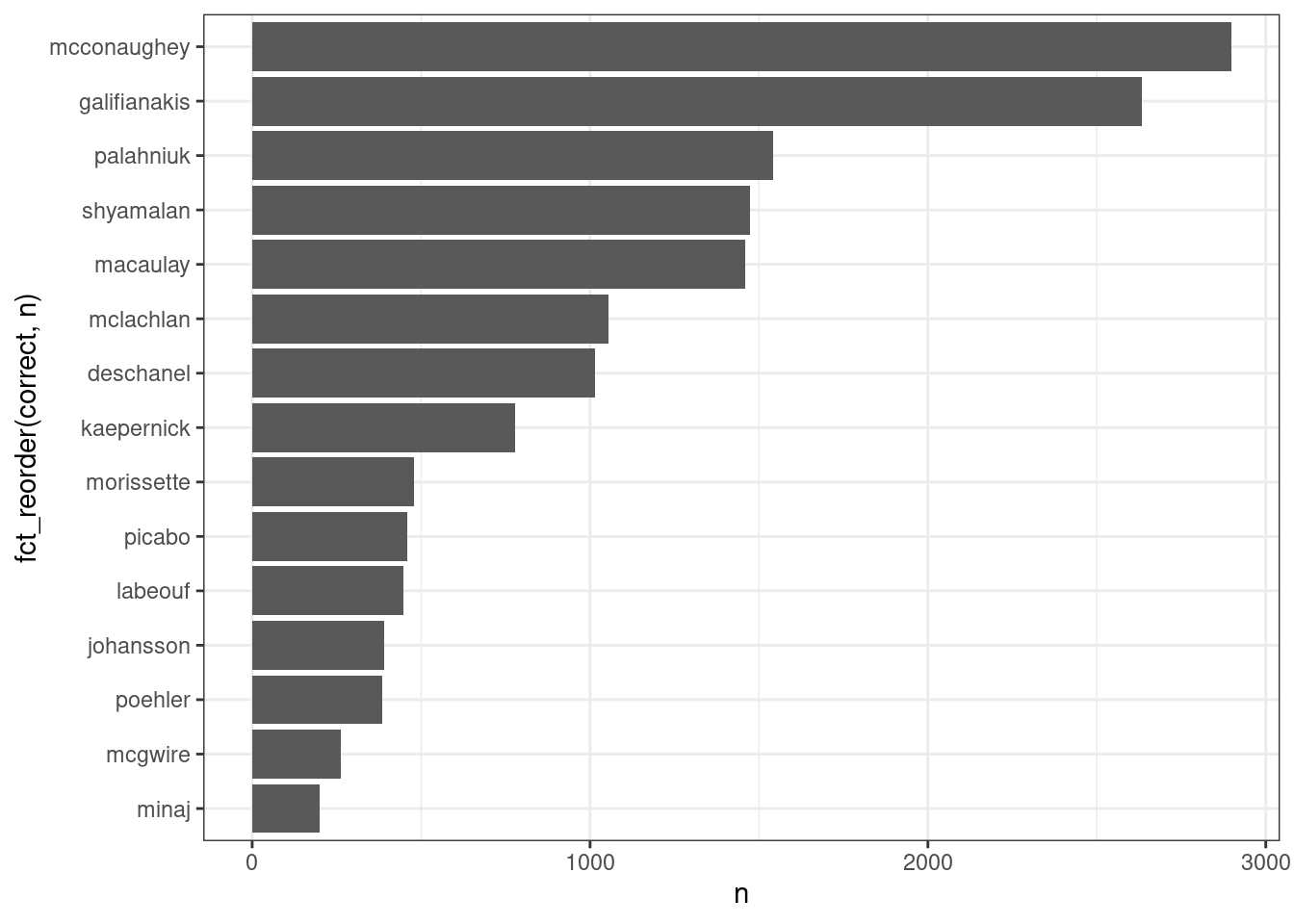
Кроме того, в функцию fct_reorder() можно добавит функцию, которая будет считаться на векторе, по которому группируют:
diamonds %>%
mutate(cut = fct_reorder(cut, price, mean)) %>%
ggplot(aes(cut)) +
geom_bar()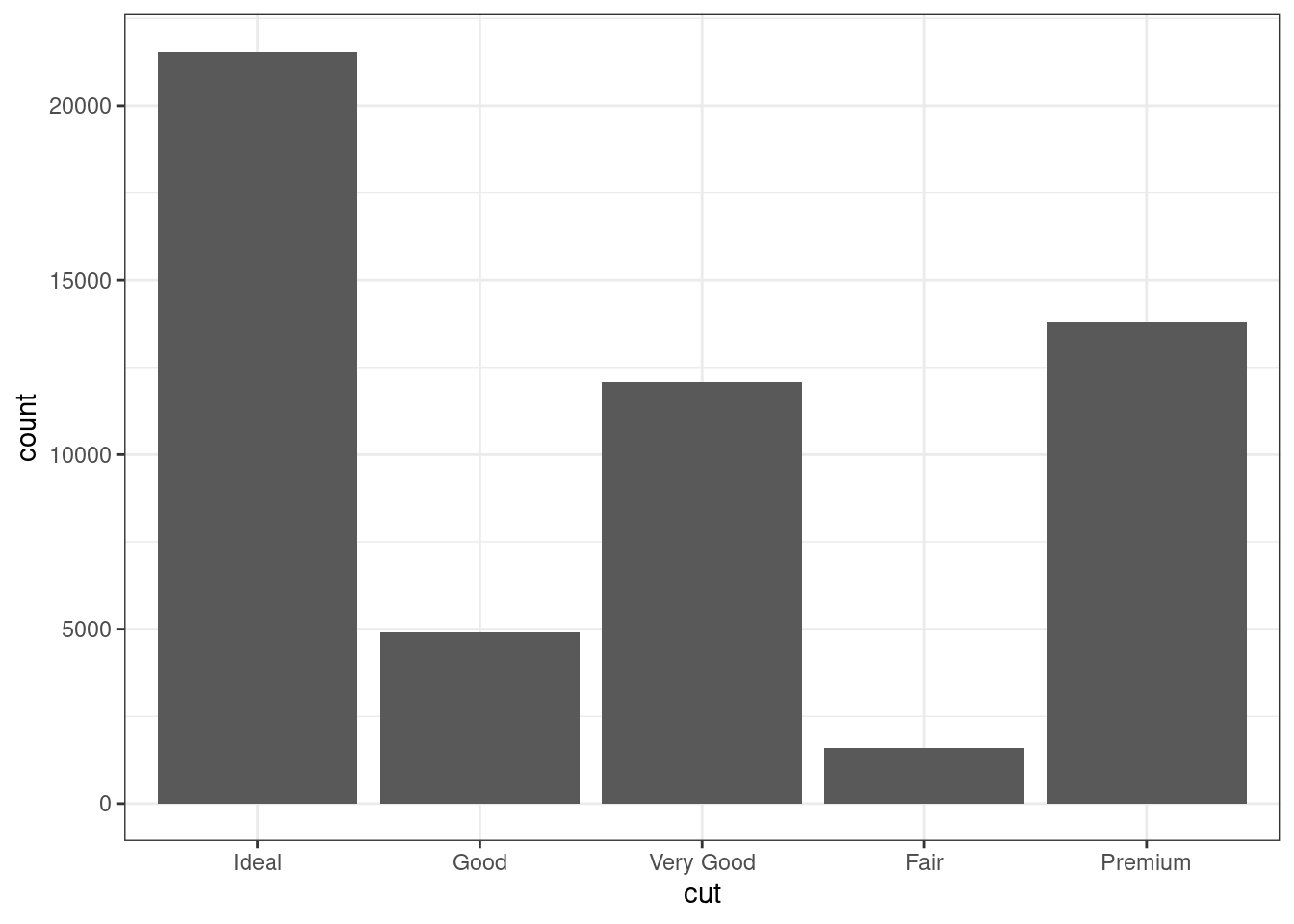
В этом примере переменная cut упорядочена по средней mean цене price. Естественно, вместо mean можно использовать другие функции (median, min, max или даже собственные функции).
Можно совмещать разные geom_...:
misspelling %>%
count(correct) %>%
ggplot(aes(fct_reorder(correct, n), n, label = n))+
geom_col()+
geom_text(nudge_y = 150)+
coord_flip()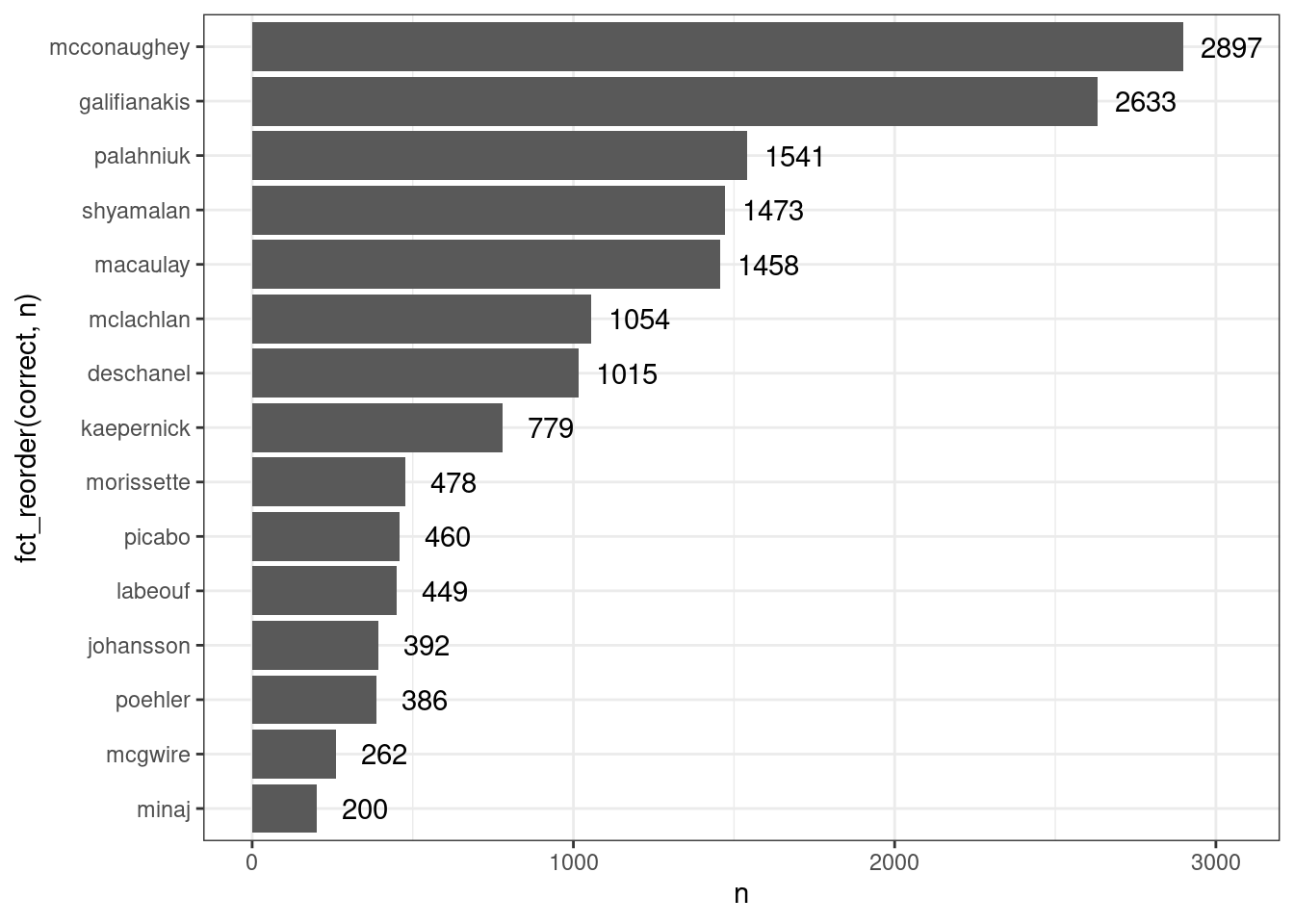
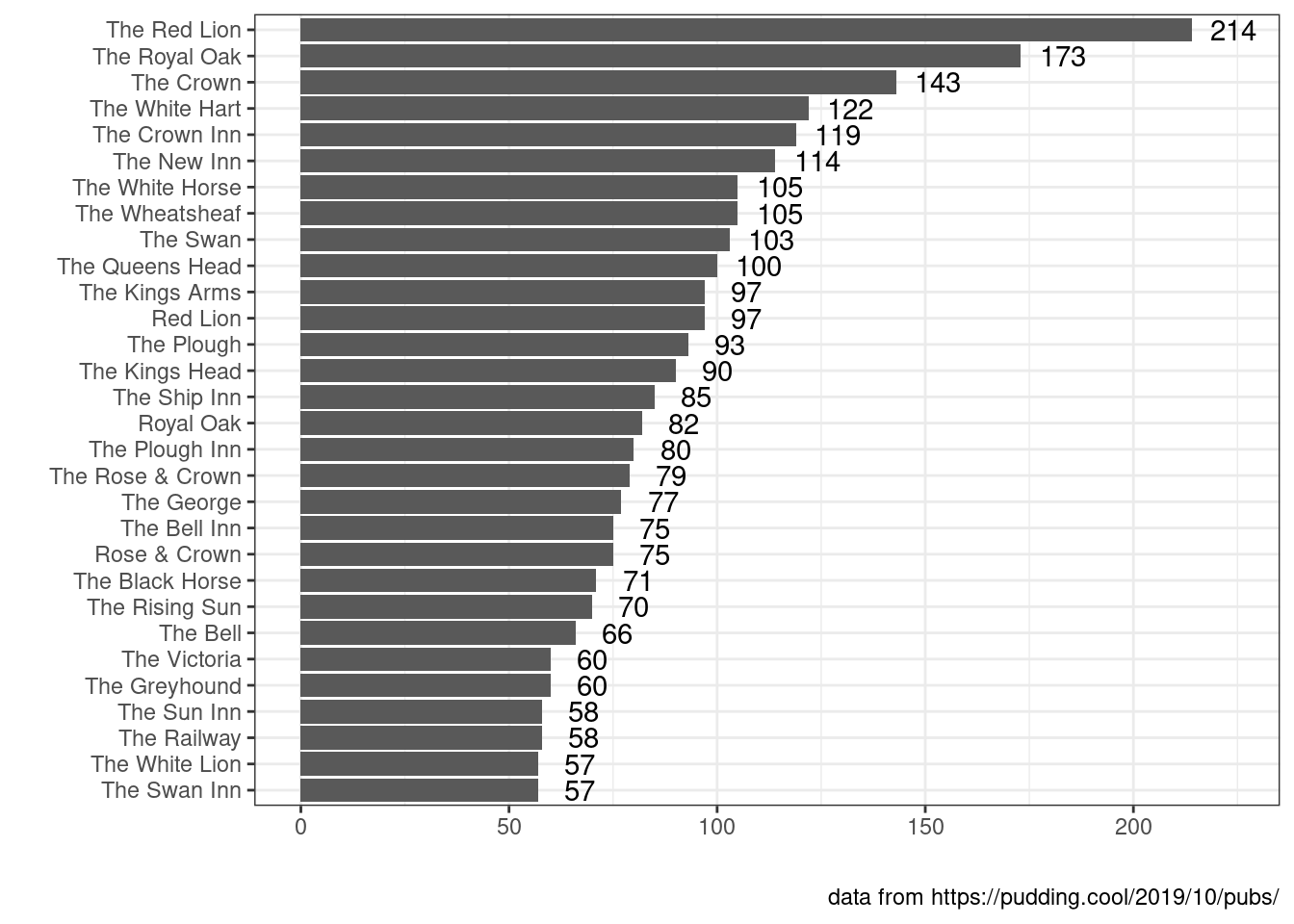
На Pudding вышла статья про английские пабы. Здесь лежит немного обработанный датасет, которые они использовали. Визуализируйте 30 самых частотоных названий пабов в Великобритании.
📋 список подсказок ➡
На новостном портале meduza.io недавно вышла новость о применения закона “о неуважении к власти в интернете”. Постройте графики из этой новости. При построении графиков я использовал цвет “tan3”.
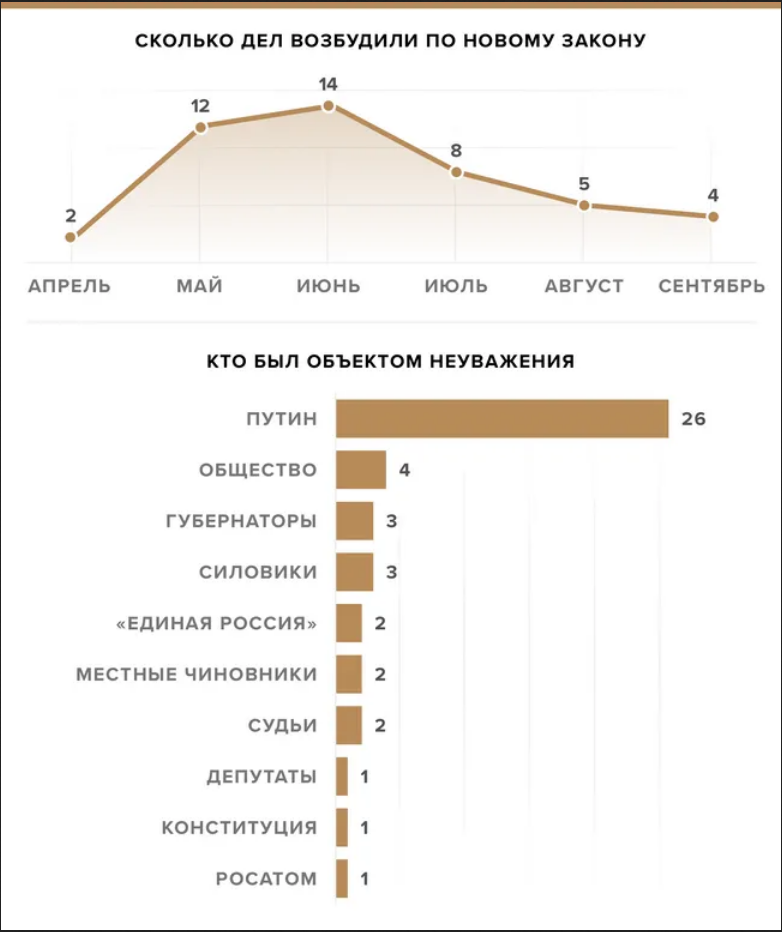
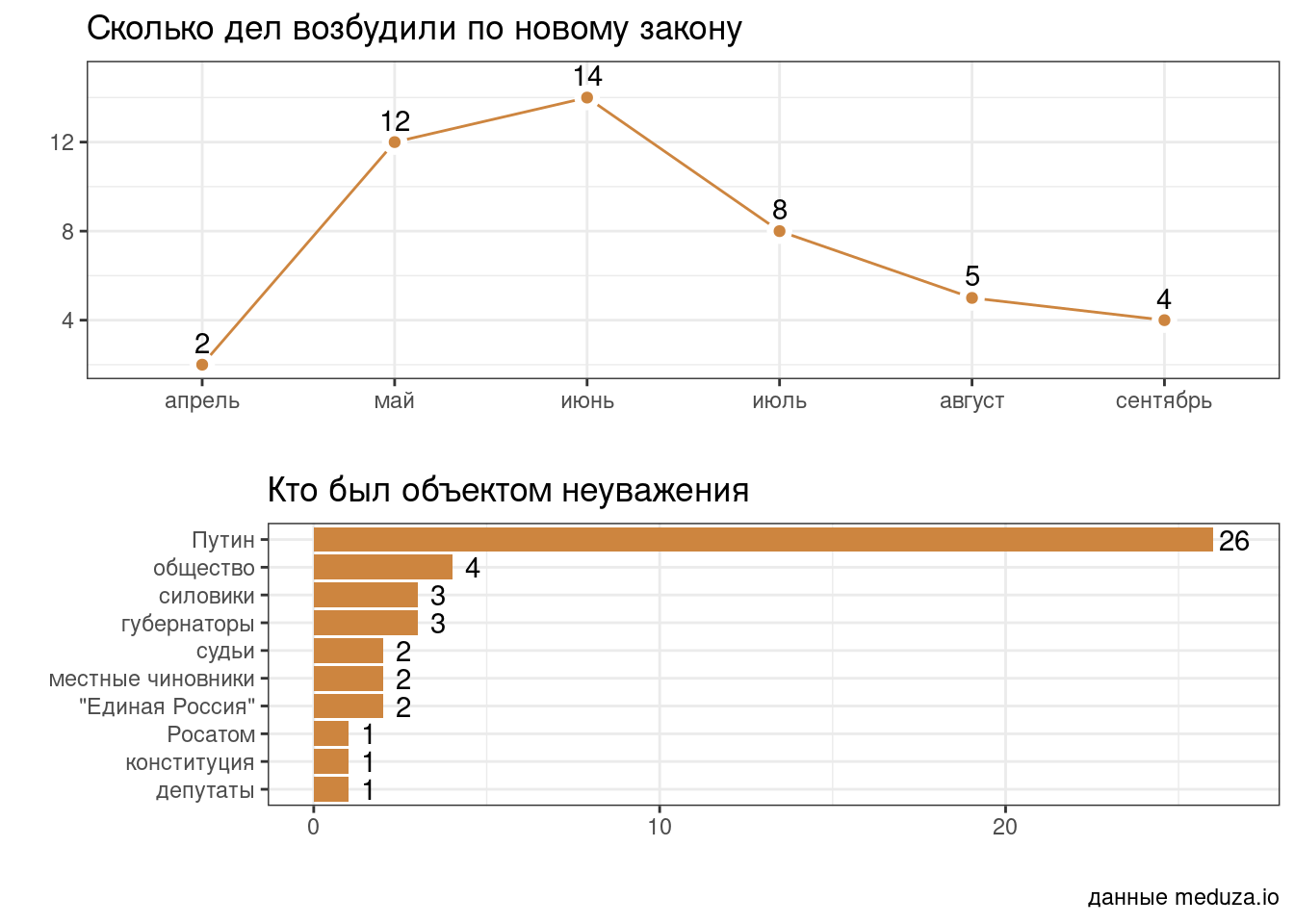
📋 список подсказок ➡
6.5 Дотплот
Иногда для случаев, когда мы исследуем числовую переменную подходит простой график, который отображает распределение наших наблюдений на одной соответствующей числовой шкале.
mtcars %>%
ggplot(aes(mpg)) +
geom_dotplot(method = "histodot")## `stat_bindot()` using `bins = 30`. Pick better value with `binwidth`.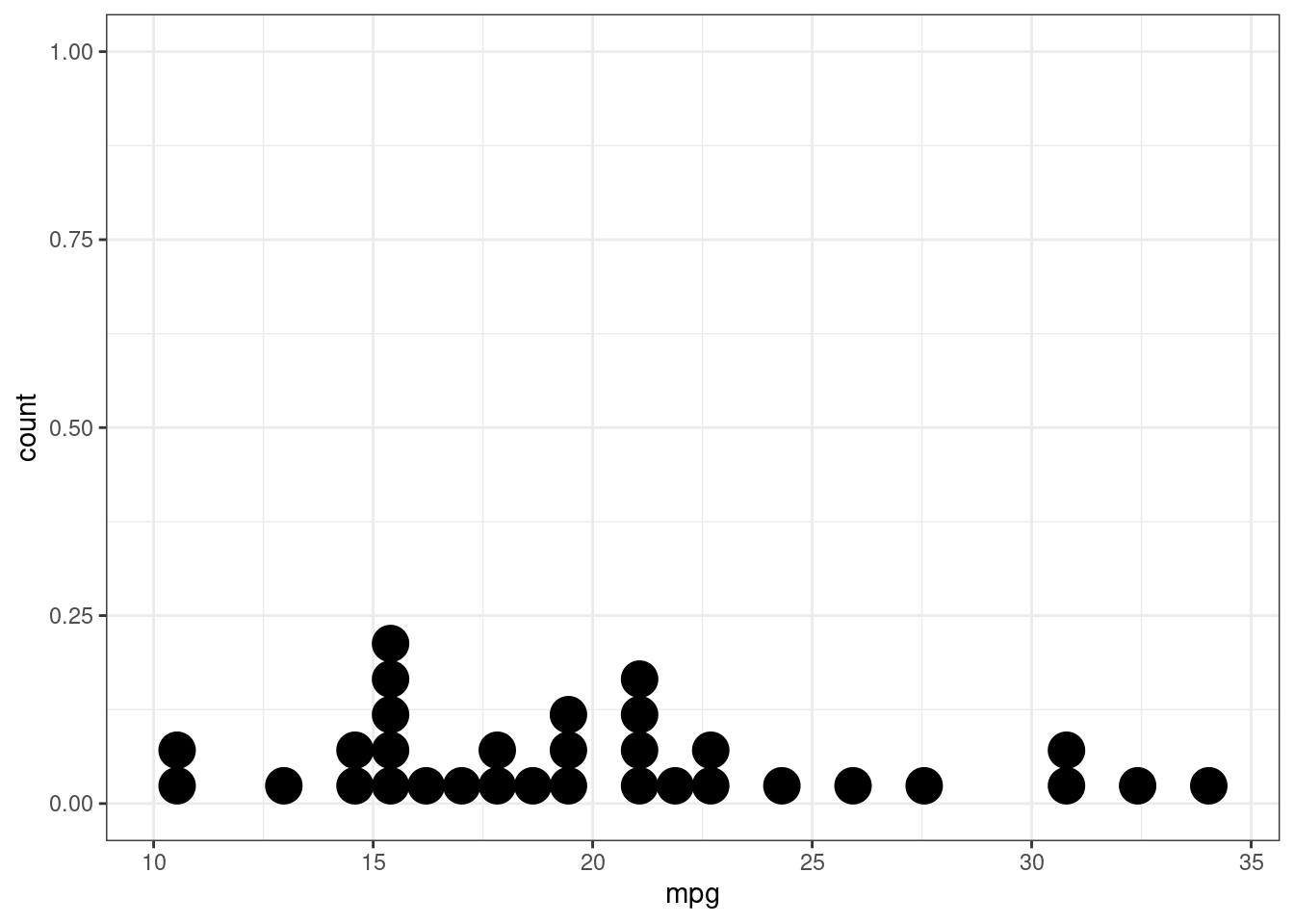
По оси x отложена наша переменная, каждая точка – одно наблюдение, а отложенное по оси y стоит игнорировать – оно появляется из-за ограничений пакета ggplot2. Возможно чуть понятнее будет, если добавить geom_rug(), который непосредственно отображает каждое наблюдение.
mtcars %>%
ggplot(aes(mpg)) +
geom_rug()+
geom_dotplot(method = "histodot")## `stat_bindot()` using `bins = 30`. Pick better value with `binwidth`.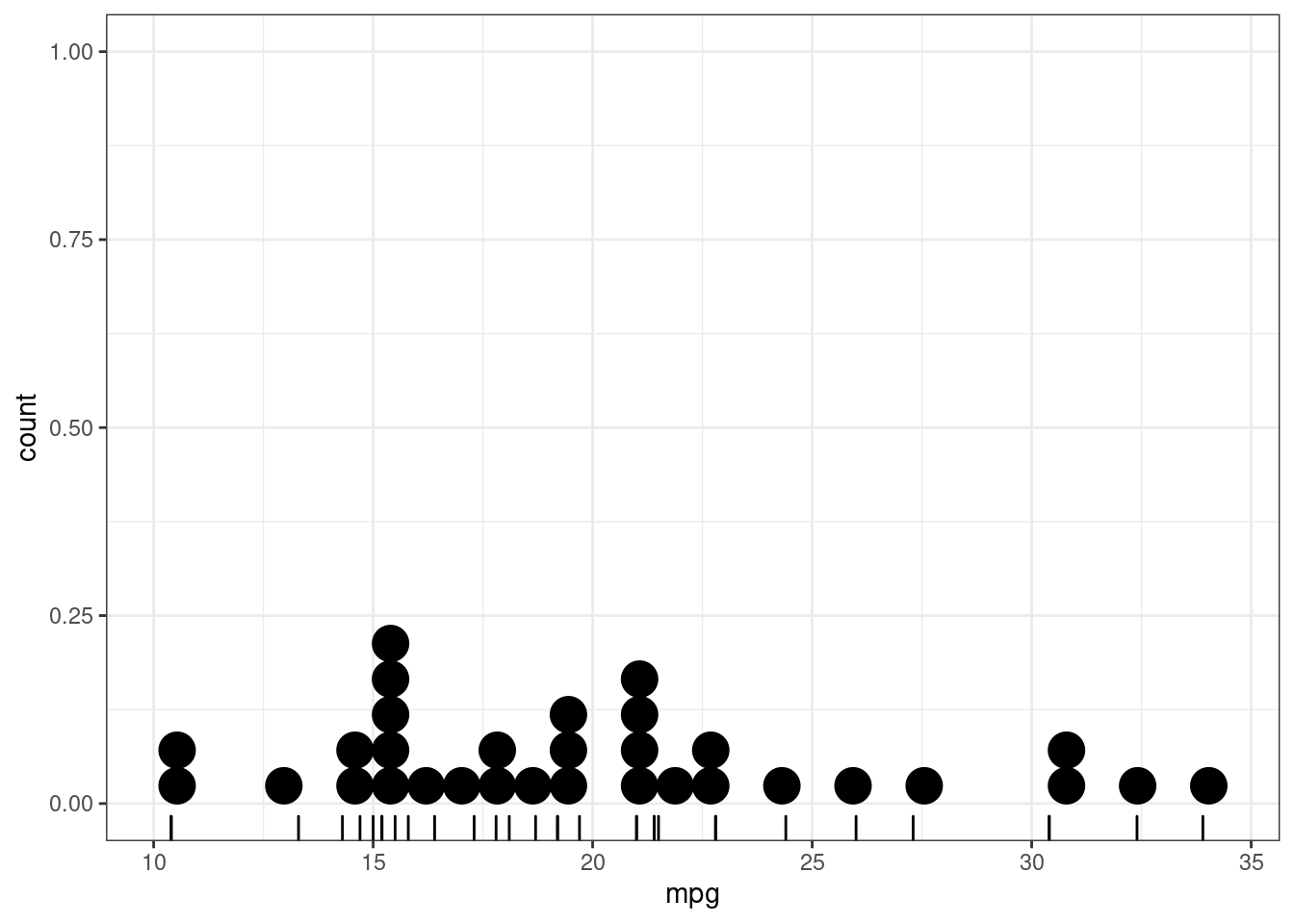
Больший смысл имеет раскрашенный вариант:
mtcars %>%
mutate(cyl = factor(cyl)) %>%
ggplot(aes(mpg, fill = cyl)) +
geom_rug()+
geom_dotplot(method = "histodot")+
scale_y_continuous(NULL, breaks = NULL) # чтобы убрать ось y## `stat_bindot()` using `bins = 30`. Pick better value with `binwidth`.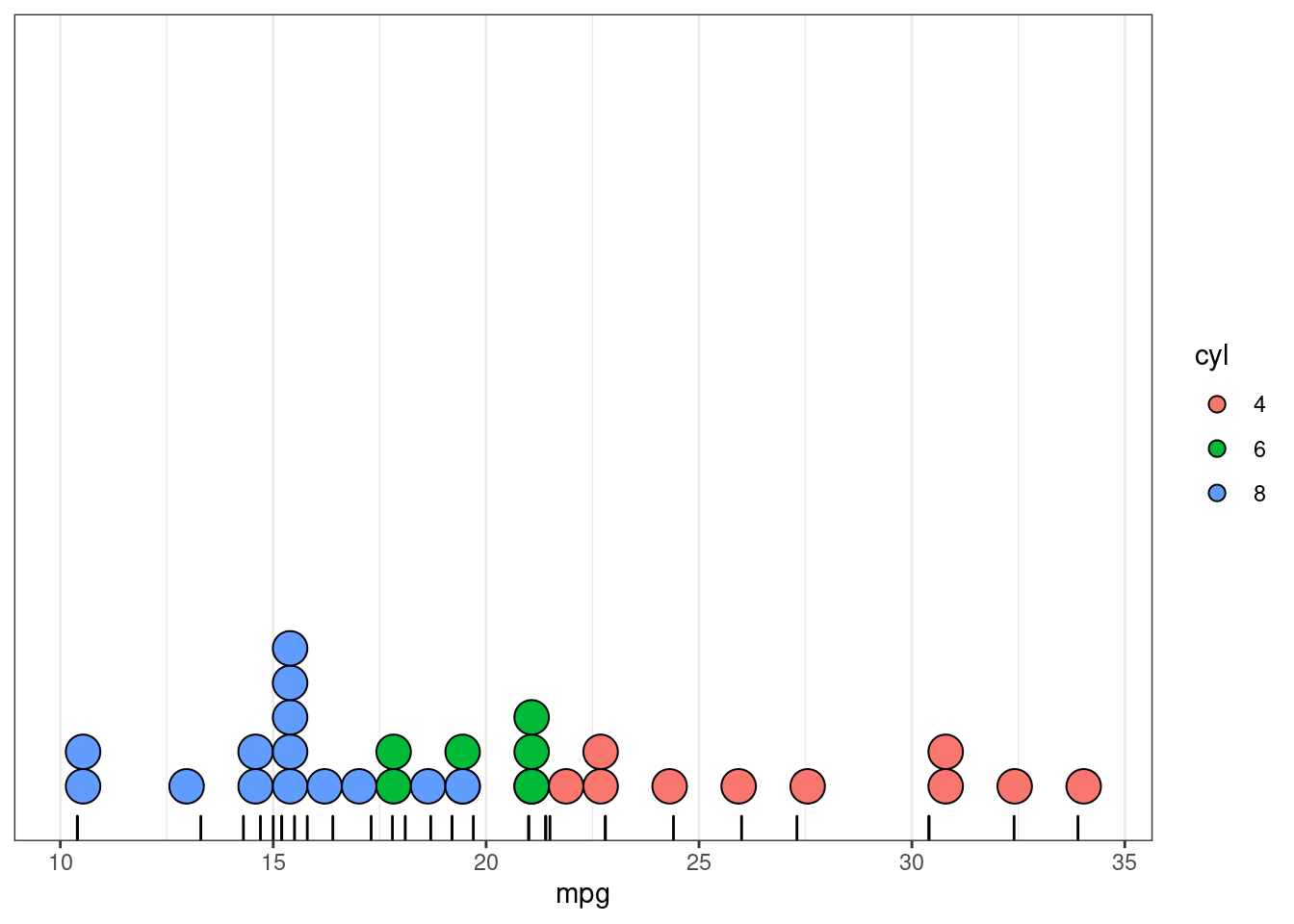 Как видно, на графике, одна синяя точка попала под одну зеленую: значит они имеют общее наблюдение.
Как видно, на графике, одна синяя точка попала под одну зеленую: значит они имеют общее наблюдение.
6.6 Гистограммы
Если наблюдений слишком много, дотплот не имеем много смысла:
diamonds %>%
ggplot(aes(price)) +
geom_dotplot(method = "histodot")+
scale_y_continuous(NULL, breaks = NULL) # чтобы убрать ось y## `stat_bindot()` using `bins = 30`. Pick better value with `binwidth`.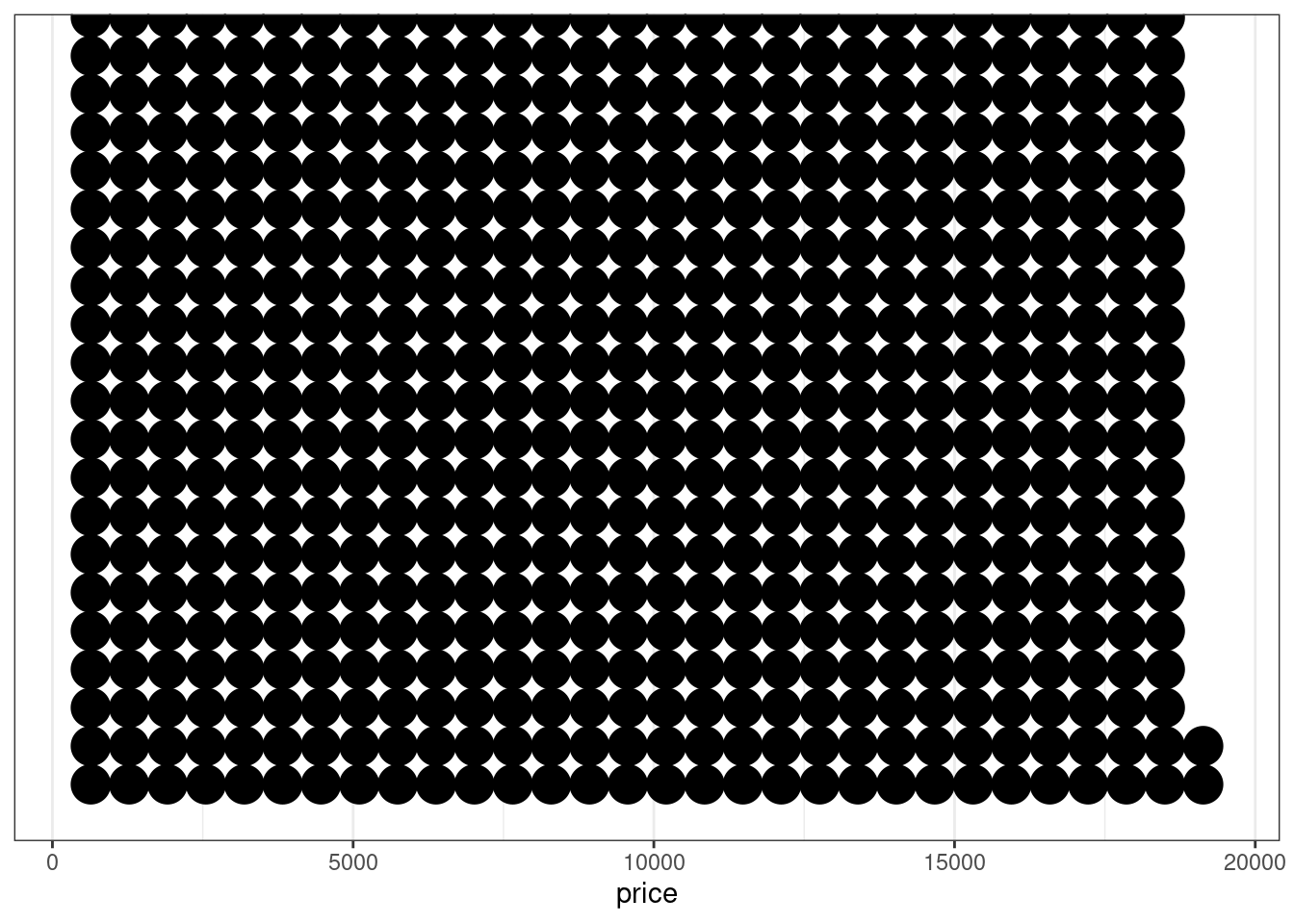
diamonds %>%
ggplot(aes(price)) +
geom_histogram()## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.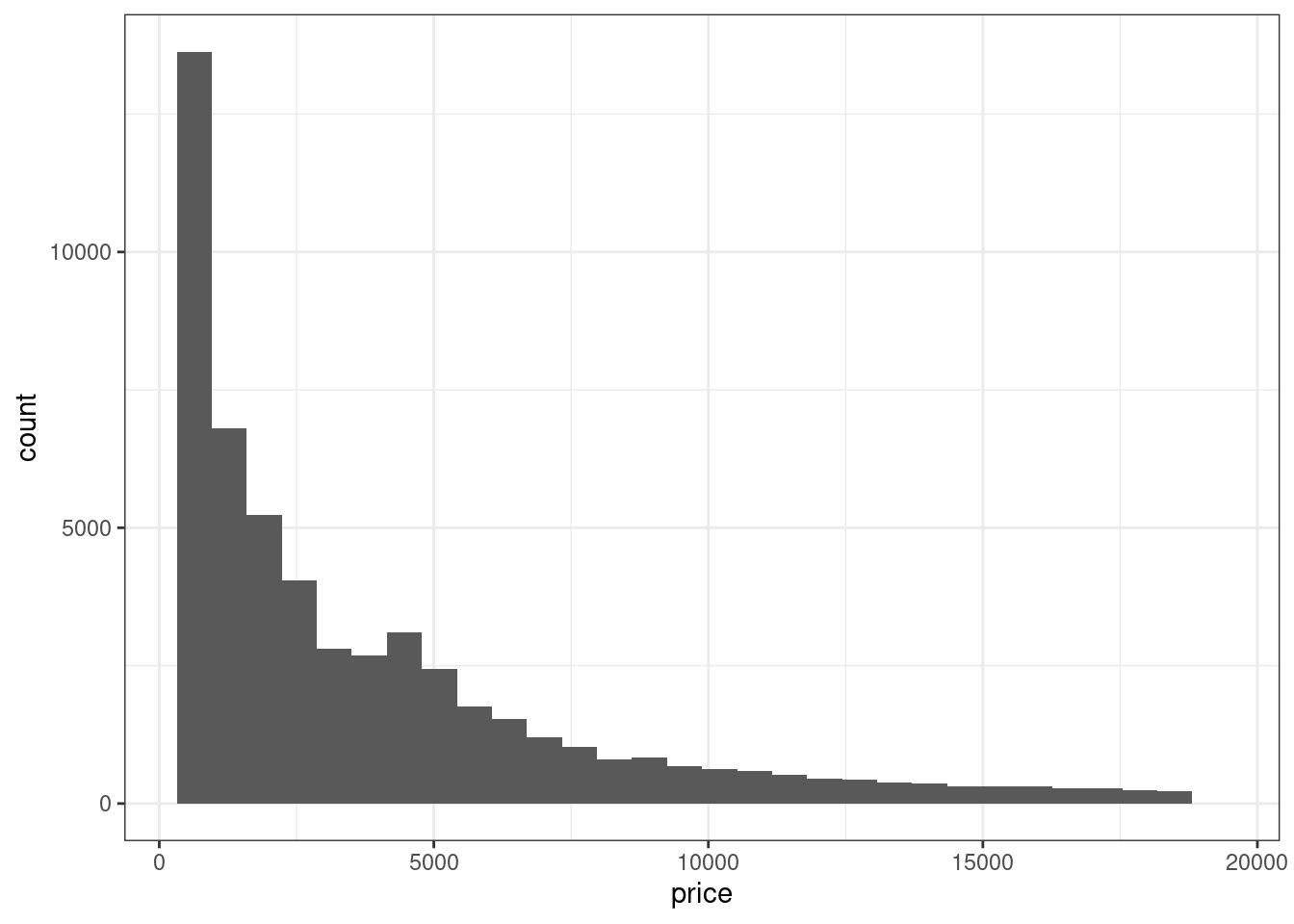
Обсудим на предыдущем примере
mtcars %>%
ggplot(aes(mpg))+
geom_rug()+
geom_histogram()## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.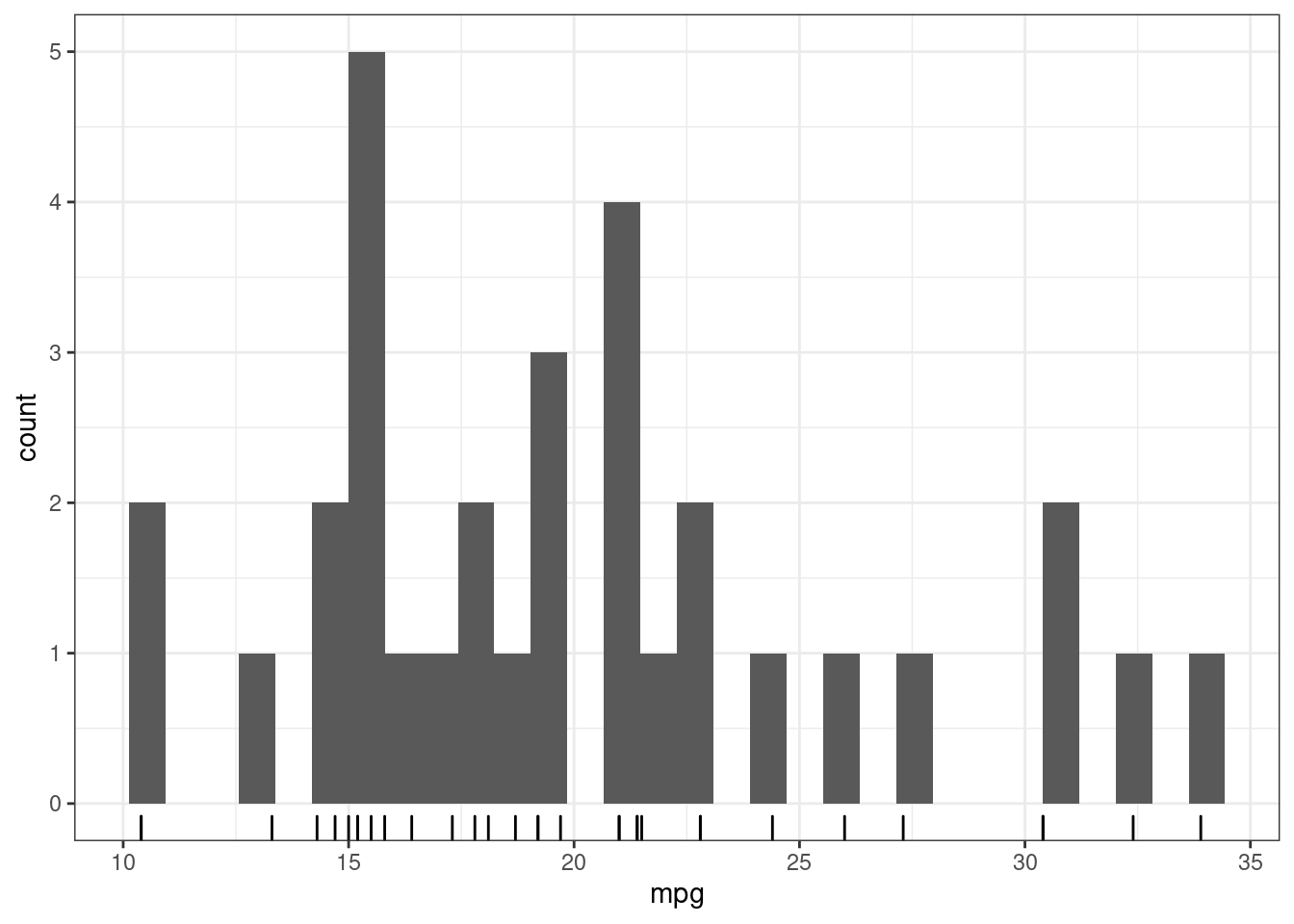
По оси x отложена наша переменная, а высота столбца говорит, сколько наблюдений имеют такое же наблюдение. Однако многое зависит от того, что мы считаем одинаковым значением:
mtcars %>%
ggplot(aes(mpg)) +
geom_rug()+
geom_histogram(bins = 100)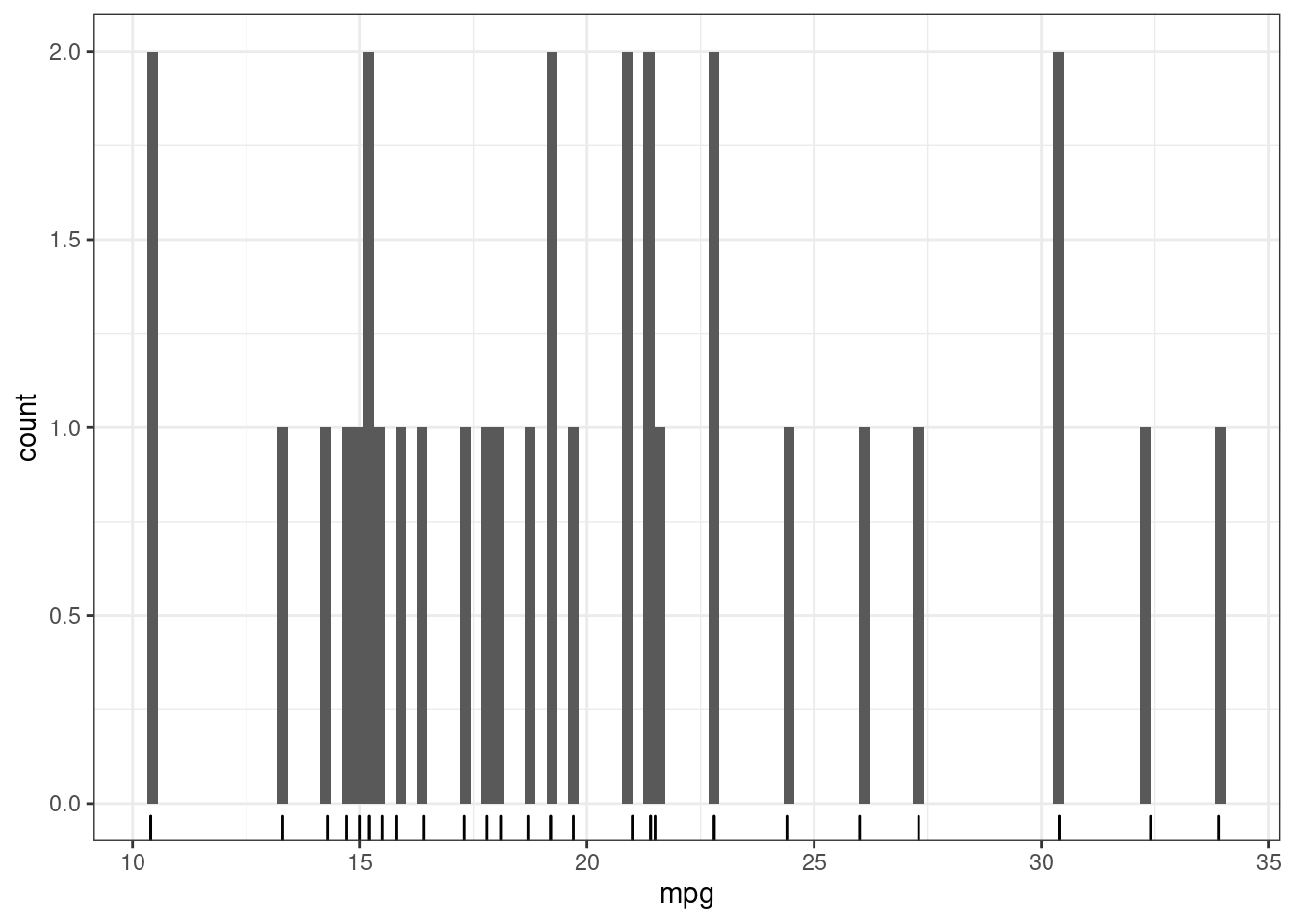
mtcars %>%
ggplot(aes(mpg)) +
geom_rug()+
geom_histogram(bins = 5)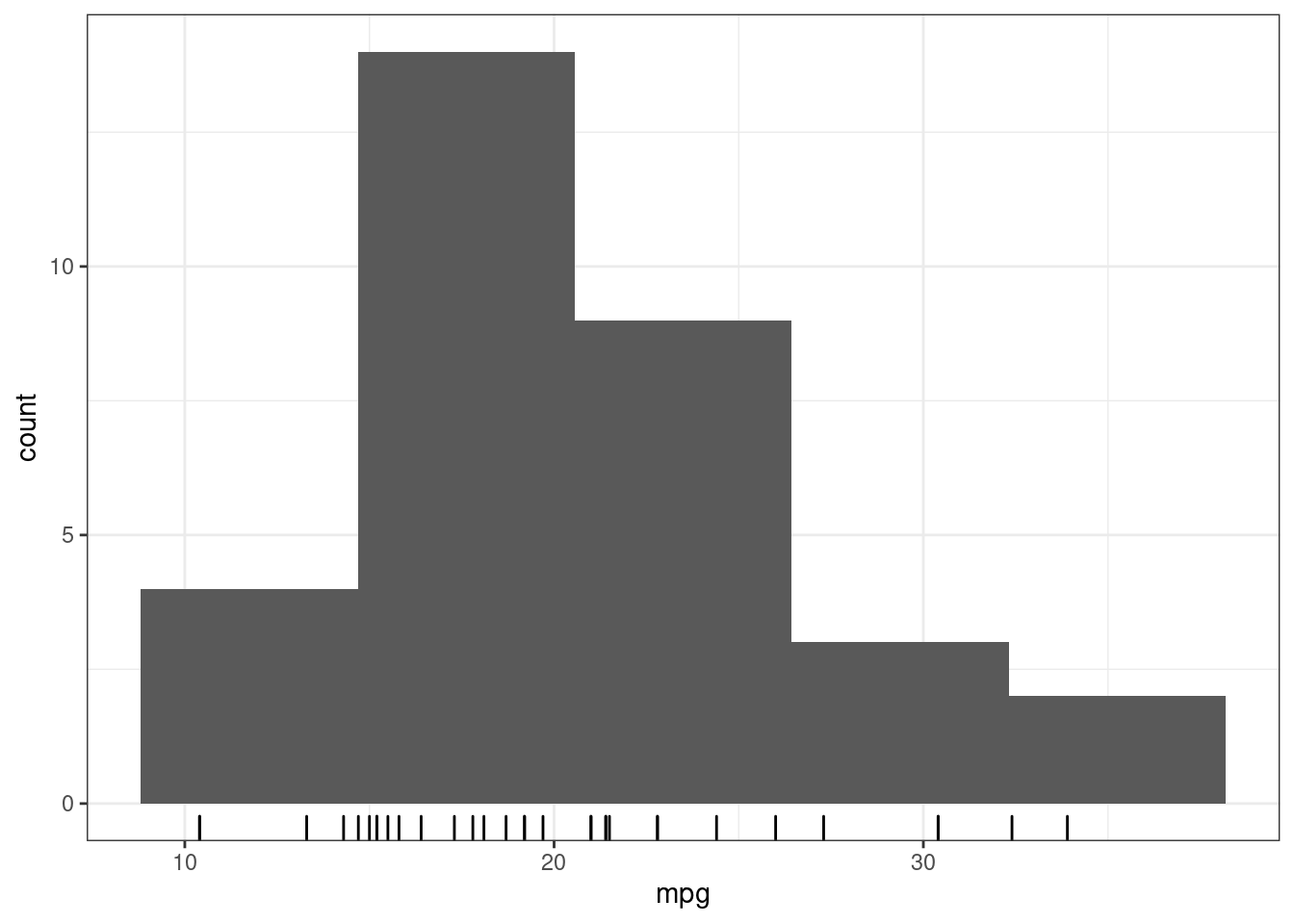
Существует три алгоритма встроенные в R, которые можно использовать и снимать с себя ответственность:
- [Sturgers 1926]
nclass.Sturges(mtcars$mpg) - [Scott 1979]
nclass.scott(mtcars$mpg) - [Freedman, Diaconis 1981]
nclass.FD(mtcars$mpg)
mtcars %>%
ggplot(aes(mpg)) +
geom_histogram(bins = nclass.FD(mtcars$mpg))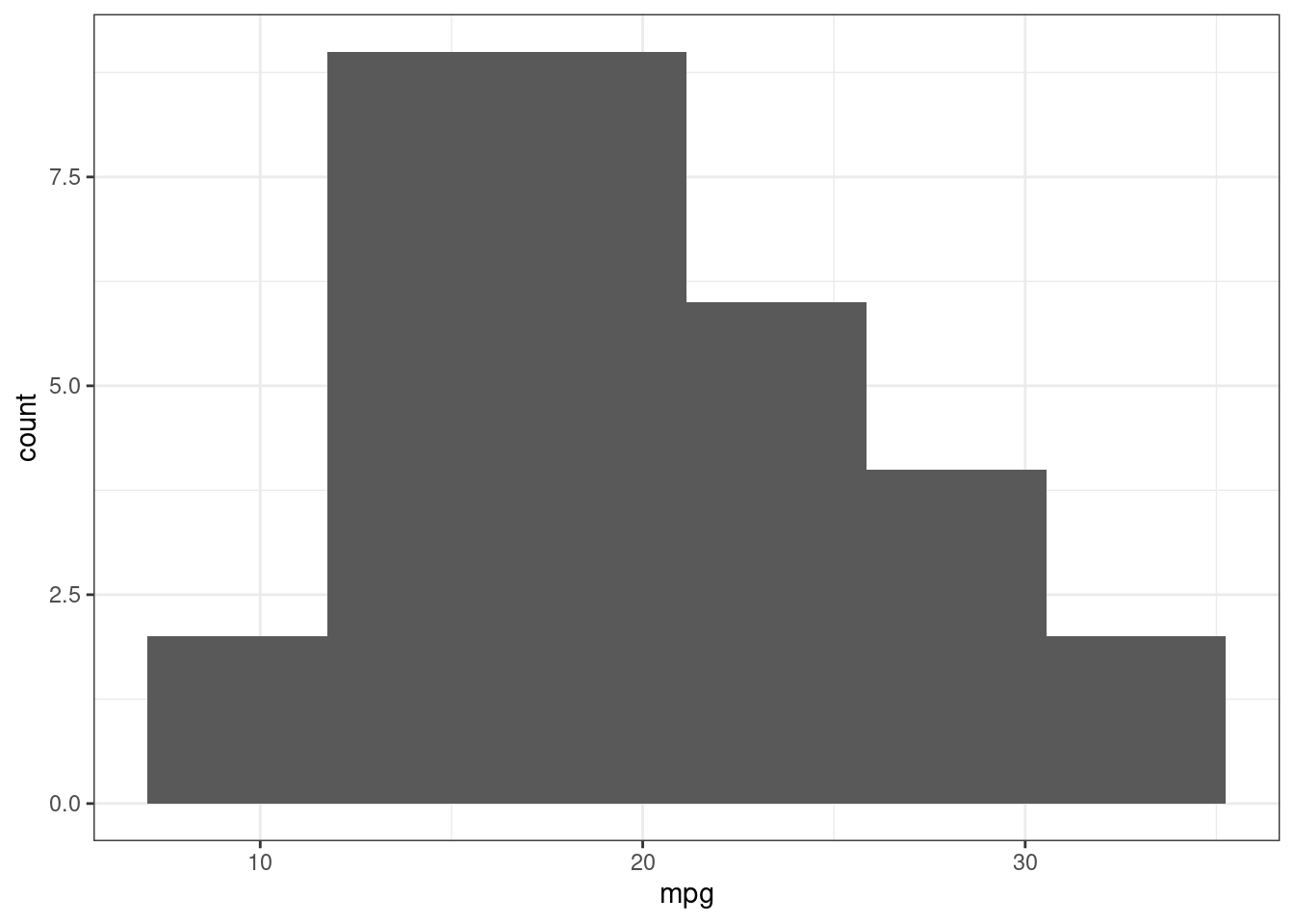
Какой из методов использовался при создании следующего графика на основе встроенного датасета iris?
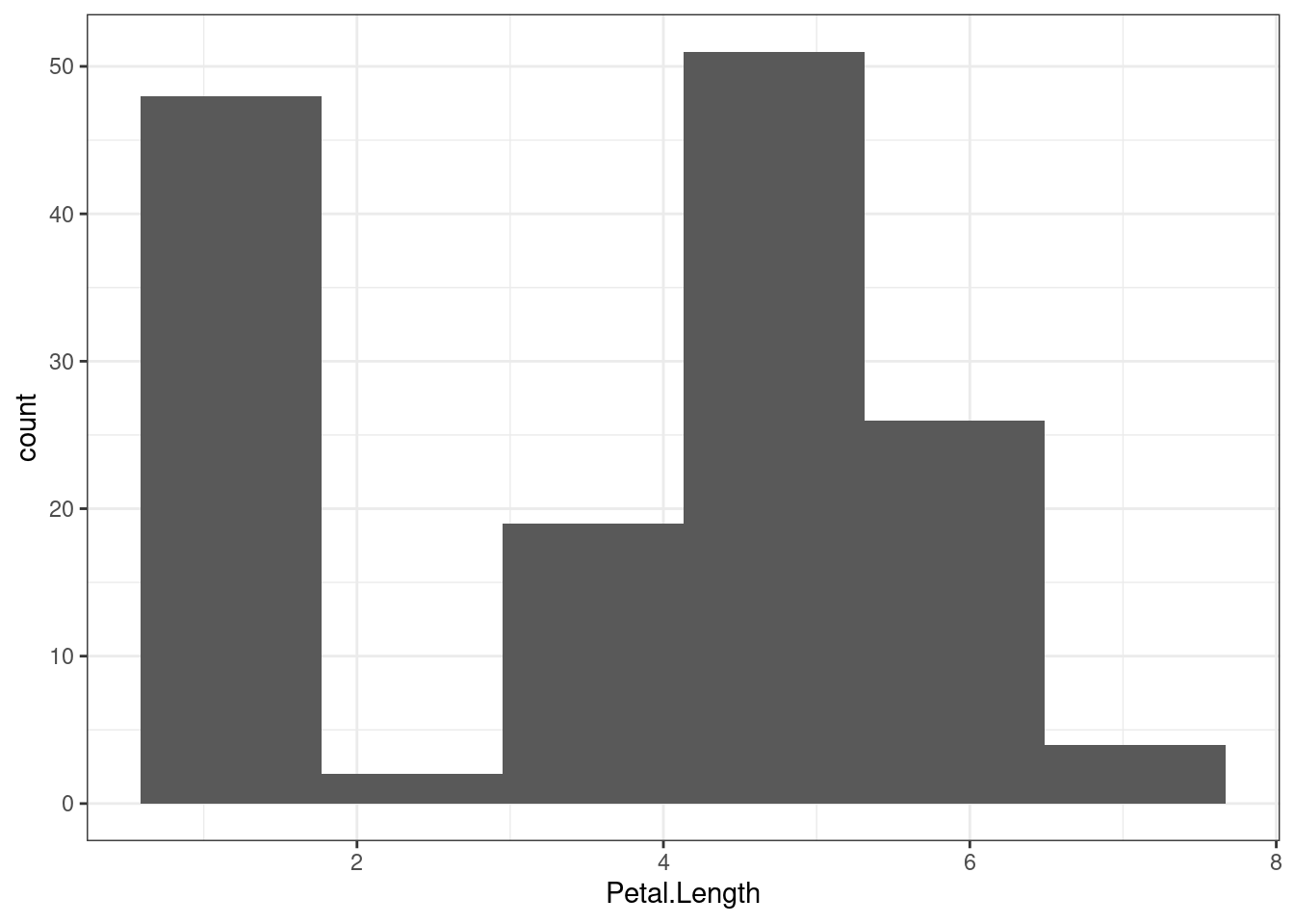
В этом типе графика точно так же можно раскрашивать на основании другой переменной:
iris %>%
ggplot(aes(Petal.Length, fill = Species)) +
geom_rug()+
geom_histogram()## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.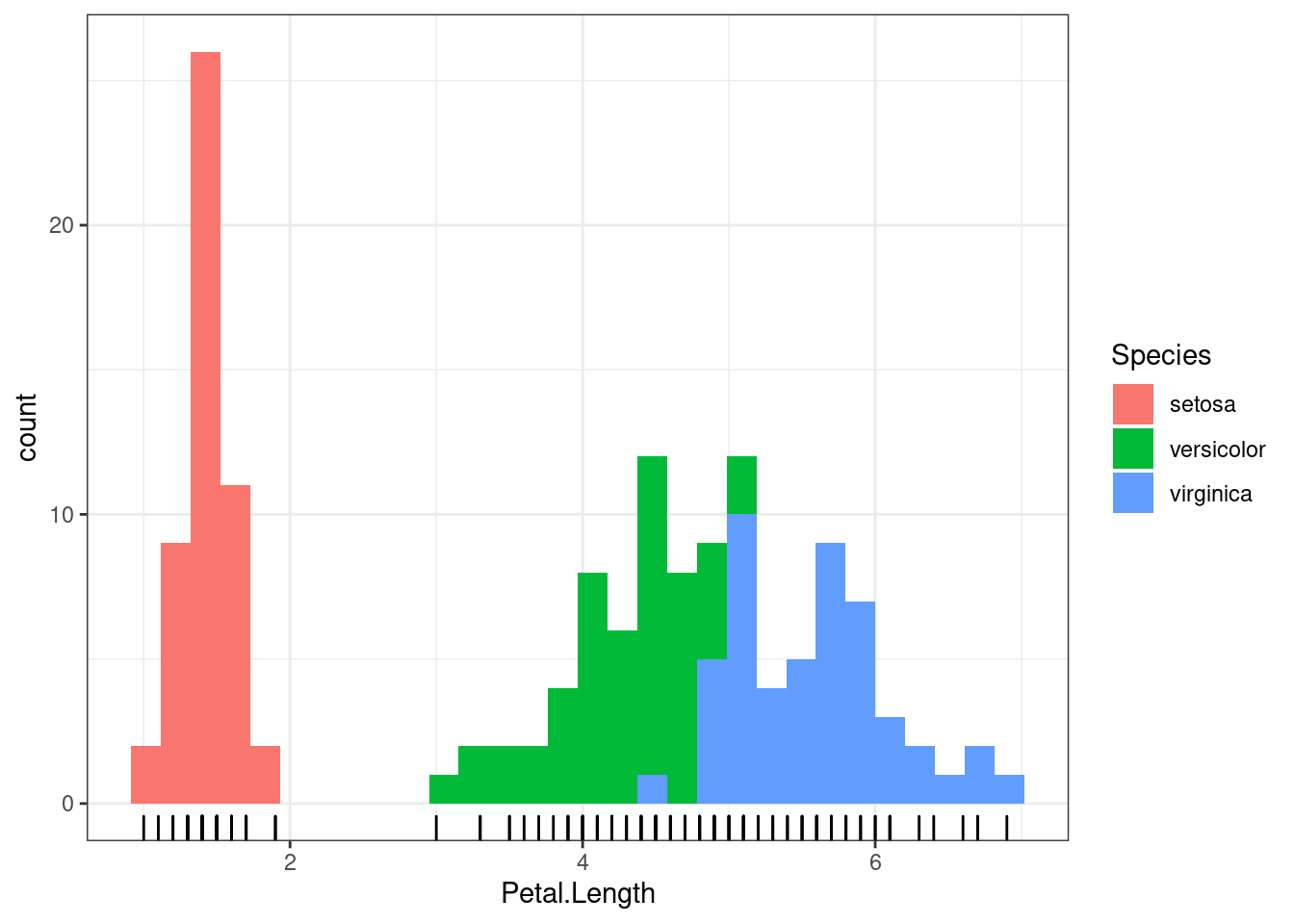
6.7 Функции плотности
Кроме того, существует способ использовать не такой рубленный график, а его сглаженную вариант, ыйторый строиться при помои функции плотядерной оценки ности. Важное свойство, которое стоит понимать про функцию плотности — что кривая, получаемая ядерной оценкой плотности, не зависит от величины коробки гистделения (хотя есть аргумент, который от adjustвечает за степень “близости” функции плотности к гистограмме).
iris %>%
ggplot(aes(Petal.Length)) +
geom_rug()+
geom_density()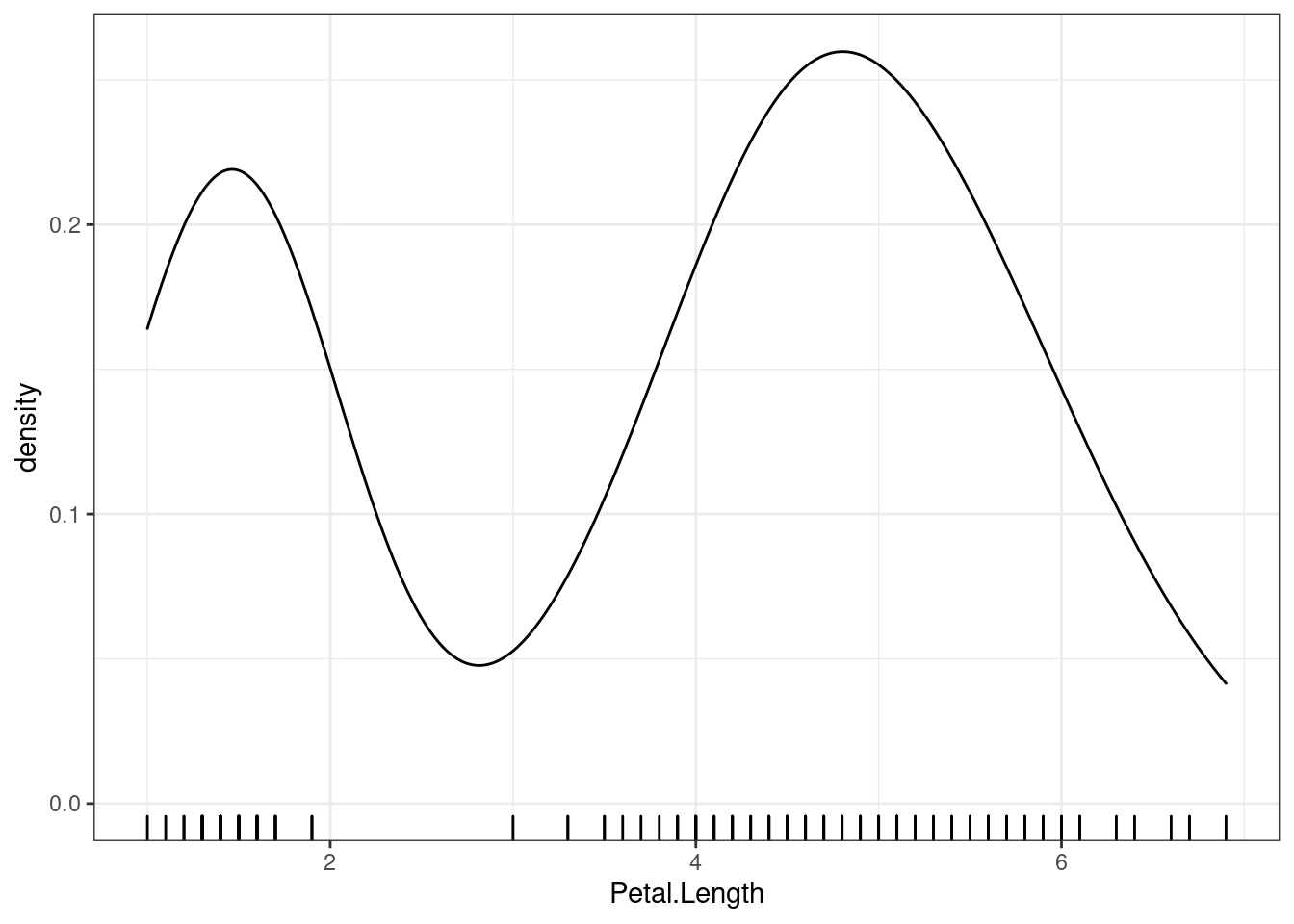
Таким образом мы можем сравнивать распределения:
iris %>%
ggplot(aes(Petal.Length, fill = Species)) +
geom_rug()+
geom_density()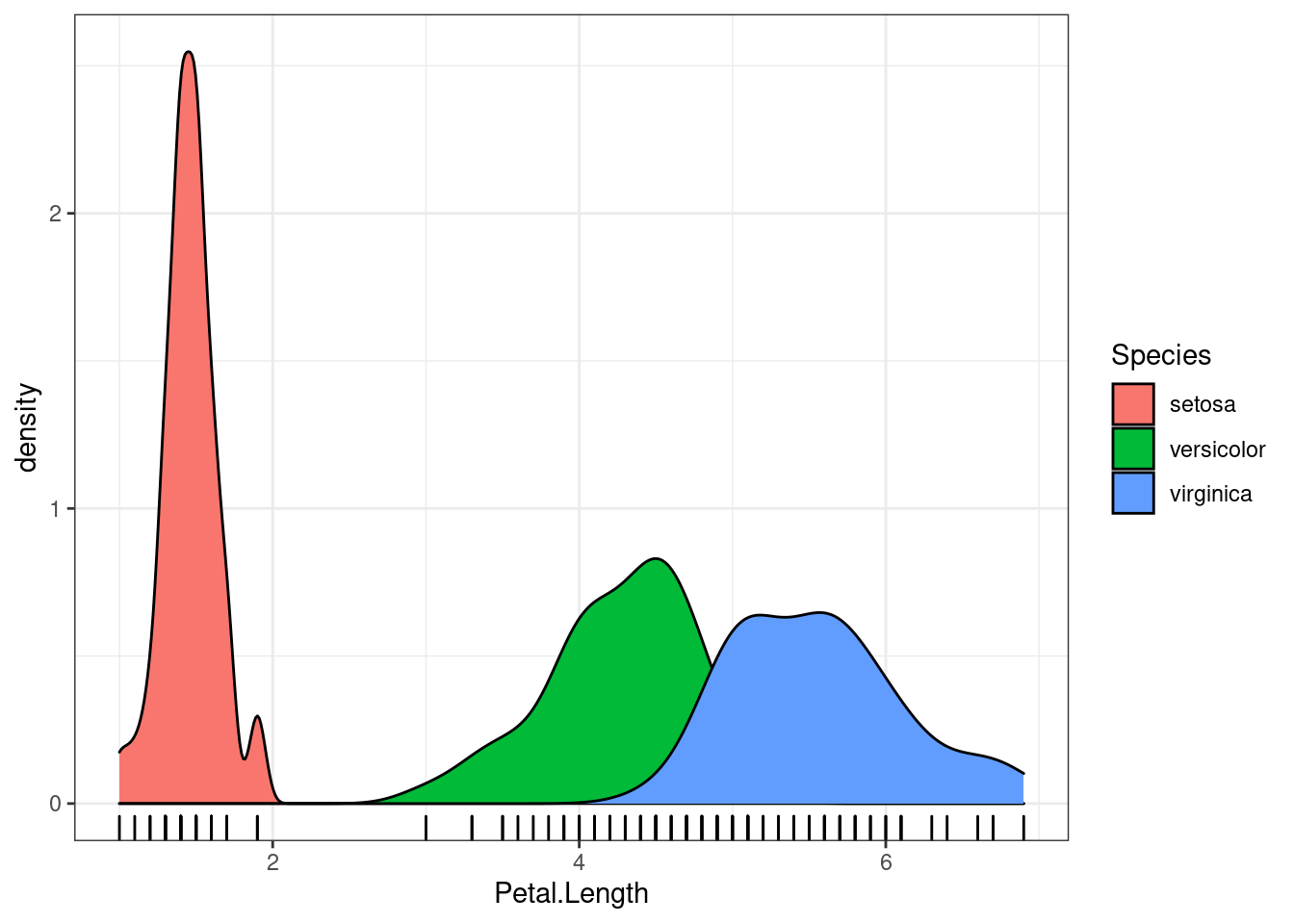
Часто имеет смысл настроить прозрачность:
iris %>%
ggplot(aes(Petal.Length, fill = Species)) +
geom_rug()+
geom_density(alpha = 0.6) # значение прозрачности изменяется от 0 до 1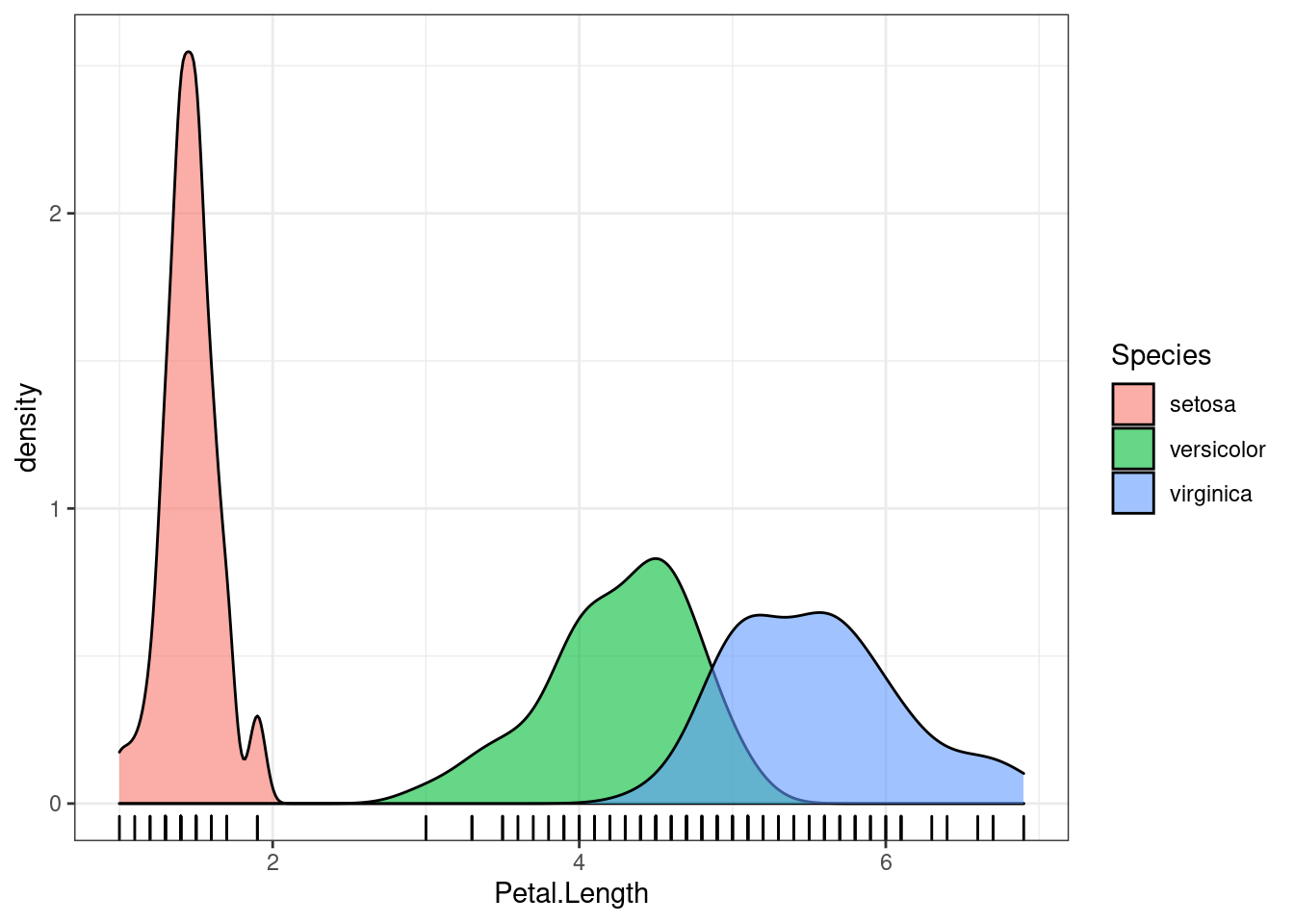
Кроме того, иногда удобно разделять группы на разные уровни:
# install.packages(ggridges)
library(ggridges)
iris %>%
ggplot(aes(Petal.Length, Species, fill = Species)) +
geom_density_ridges(alpha = 0.6) # значение прозрачности изменяется от 0 до 1## Picking joint bandwidth of 0.155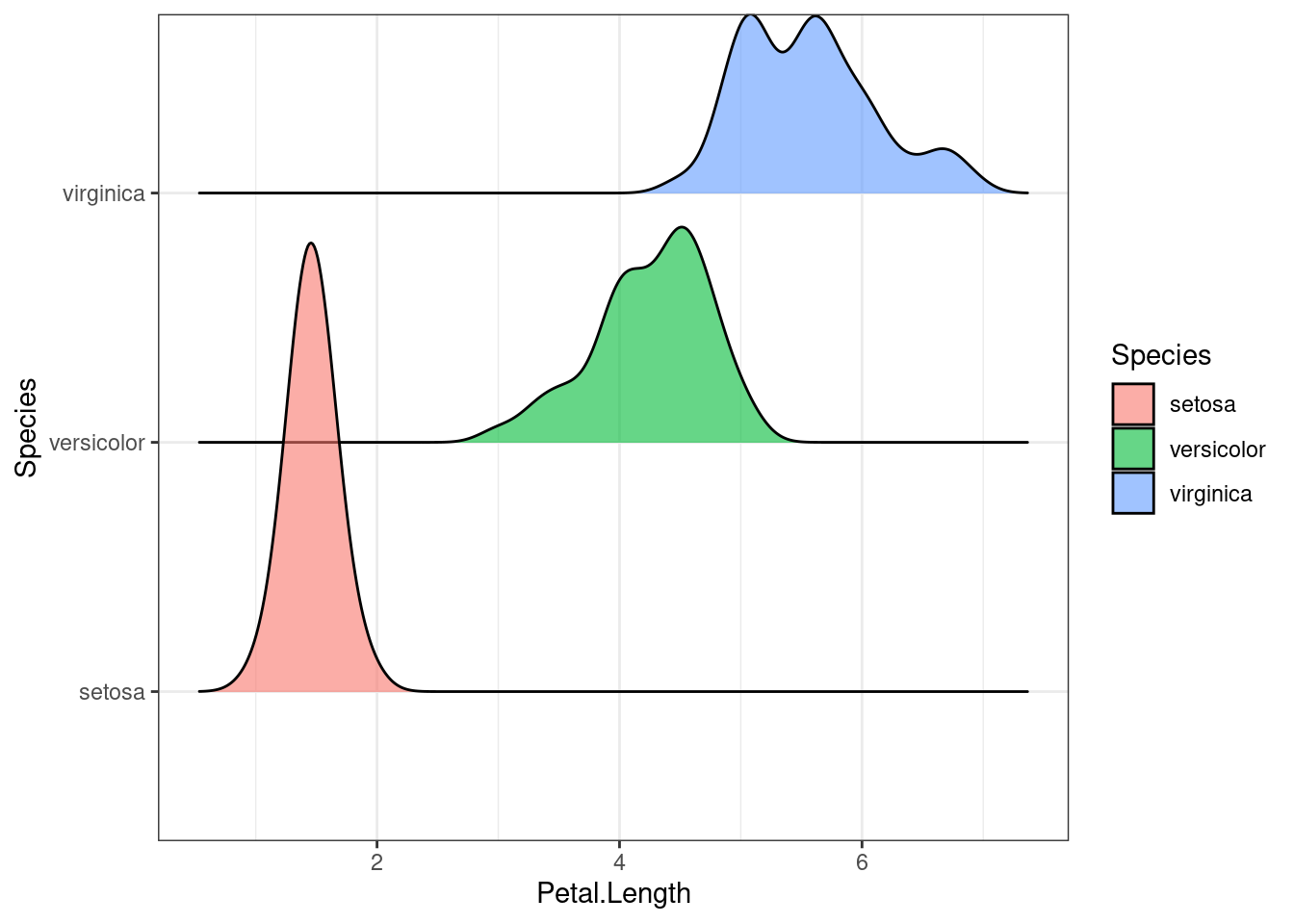
В длинный список “2015 Kantar Information is Beautiful Awards” попала визуализация Perceptions of Probability, сделанная пользователем zonination в ggplot2. Попробуйте воспроизвести ее с этими данными.
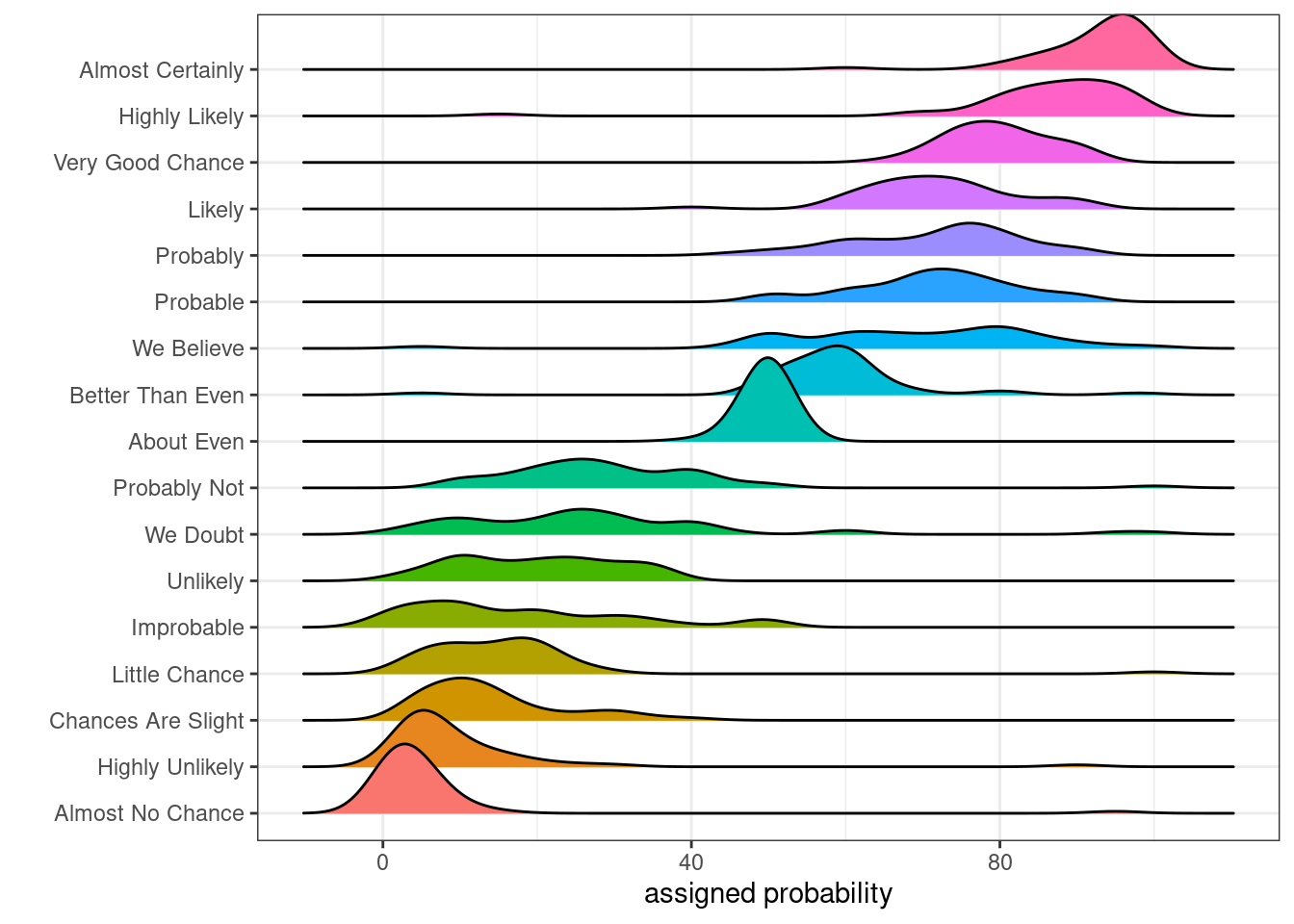
📋 список подсказок ➡
6.8 Точки, джиттер (jitter), вайолинплот (violinplot), ящики с усами (boxplot),
Вот другие способы показать распределение числовой переменной:
iris %>%
ggplot(aes(Species, Petal.Length))+
geom_point()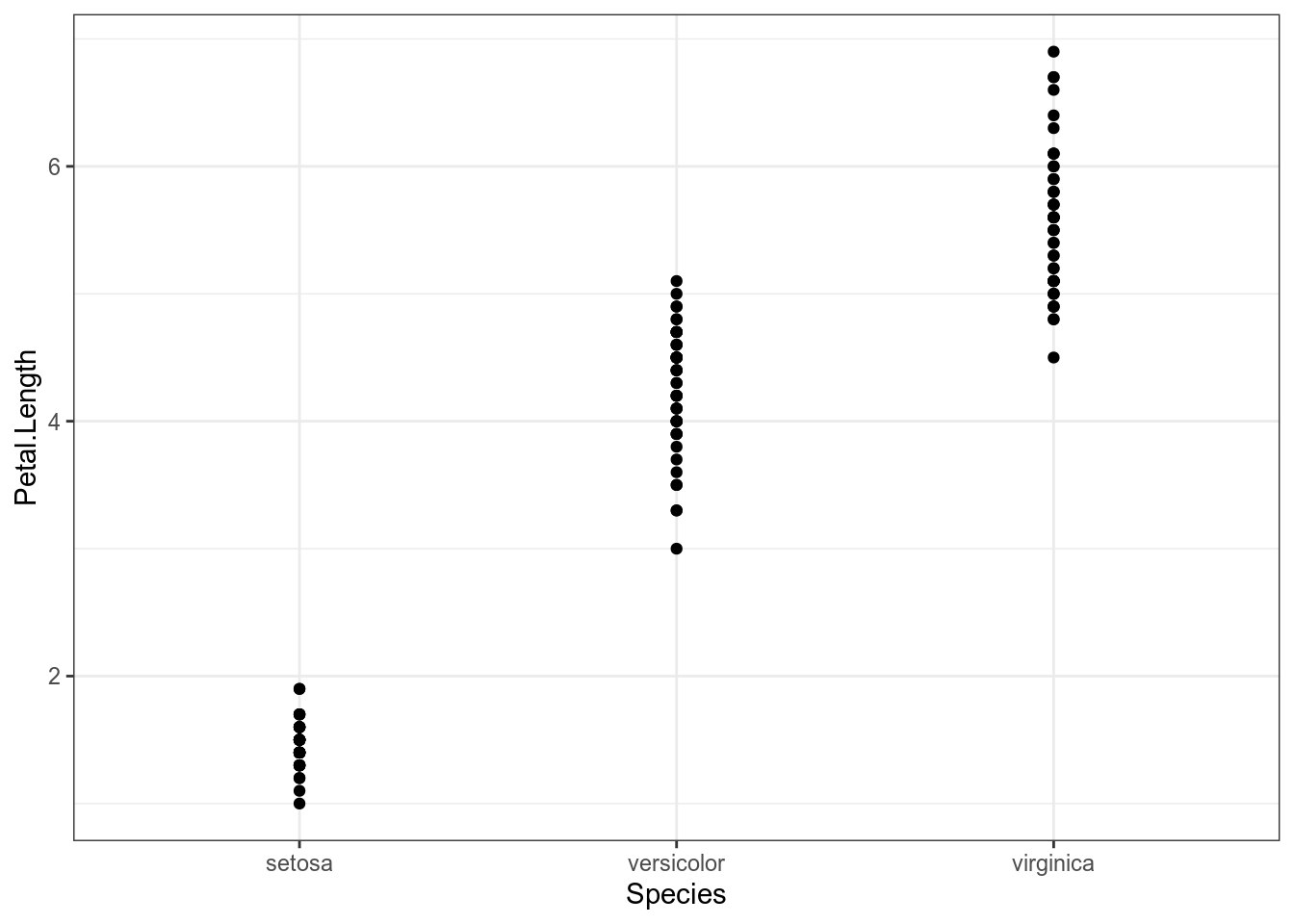
iris %>%
ggplot(aes(Species, Petal.Length))+
geom_jitter()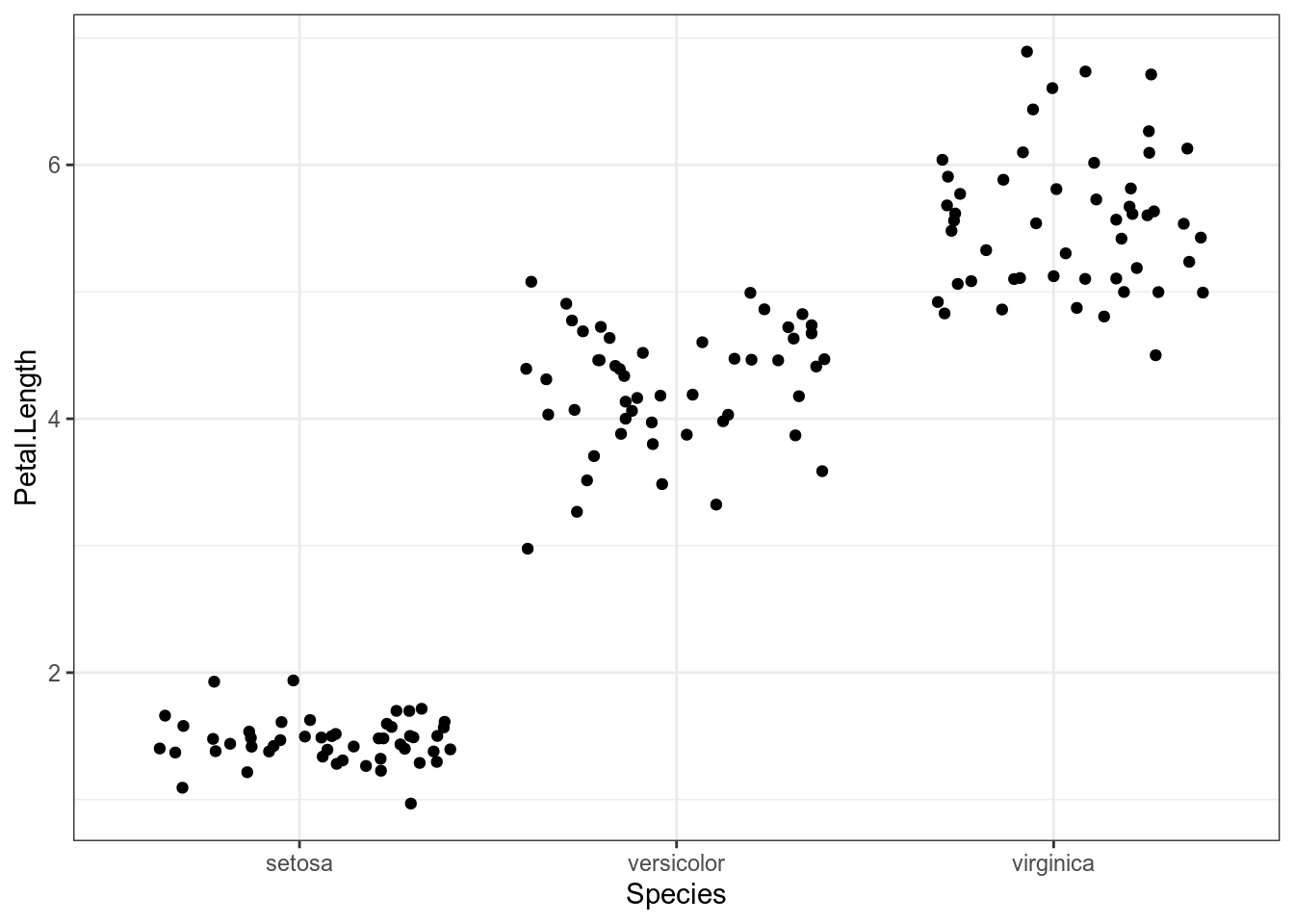
iris %>%
ggplot(aes(Species, Petal.Length))+
geom_jitter(width = 0.3)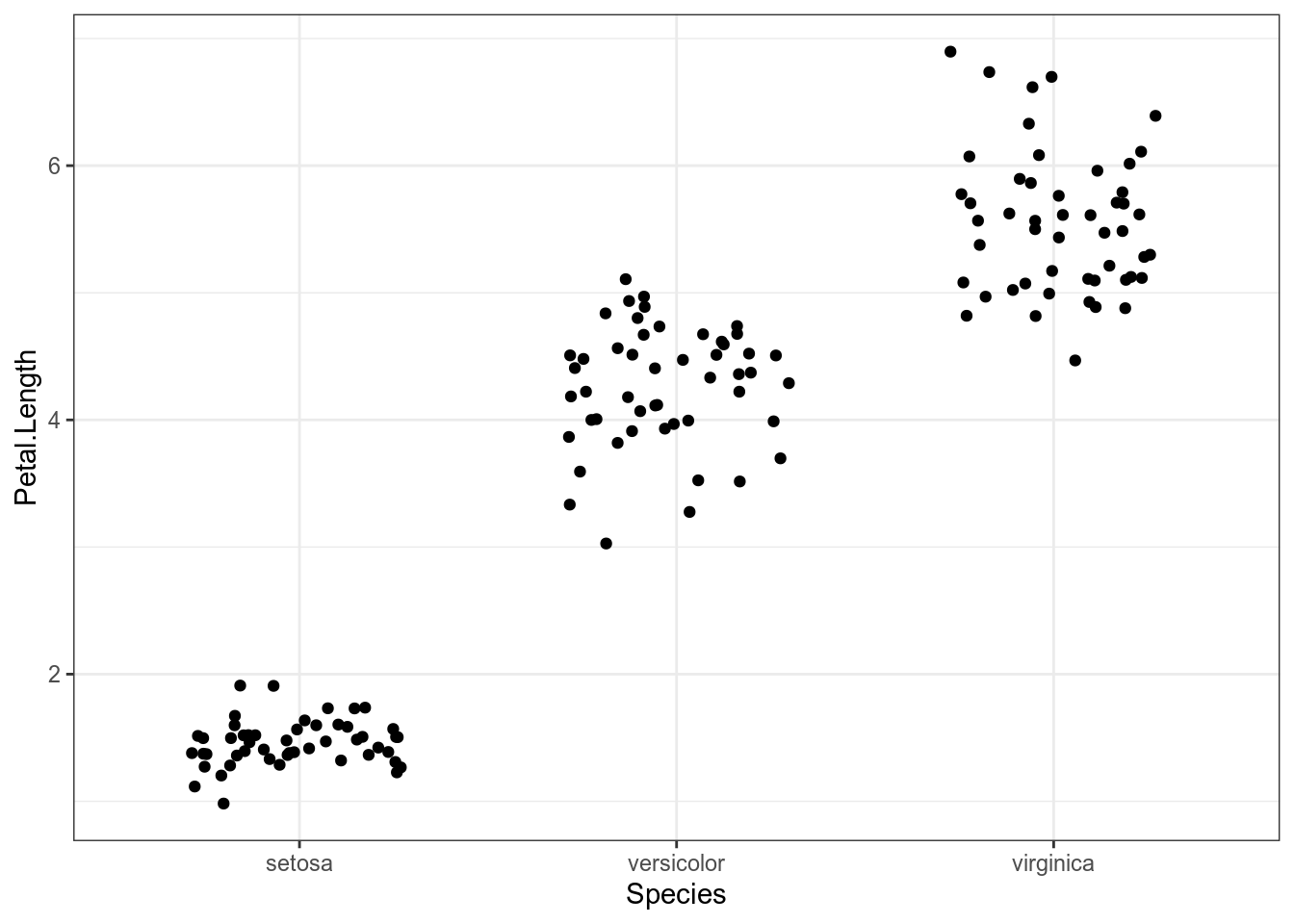
library("ggbeeswarm")
iris %>%
ggplot(aes(Species, Petal.Length))+
geom_quasirandom()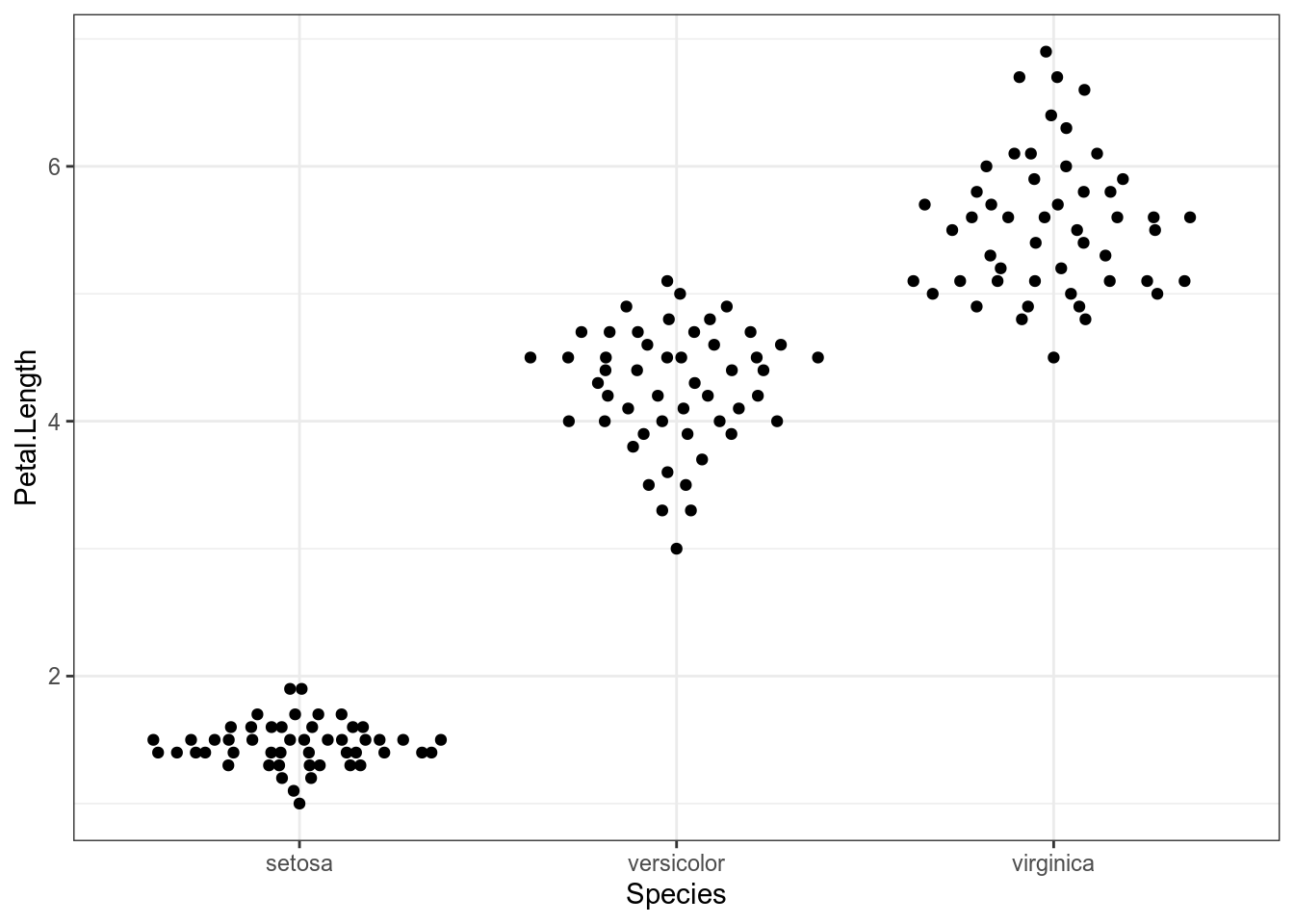
diamonds %>%
ggplot(aes(cut, price))+
geom_violin()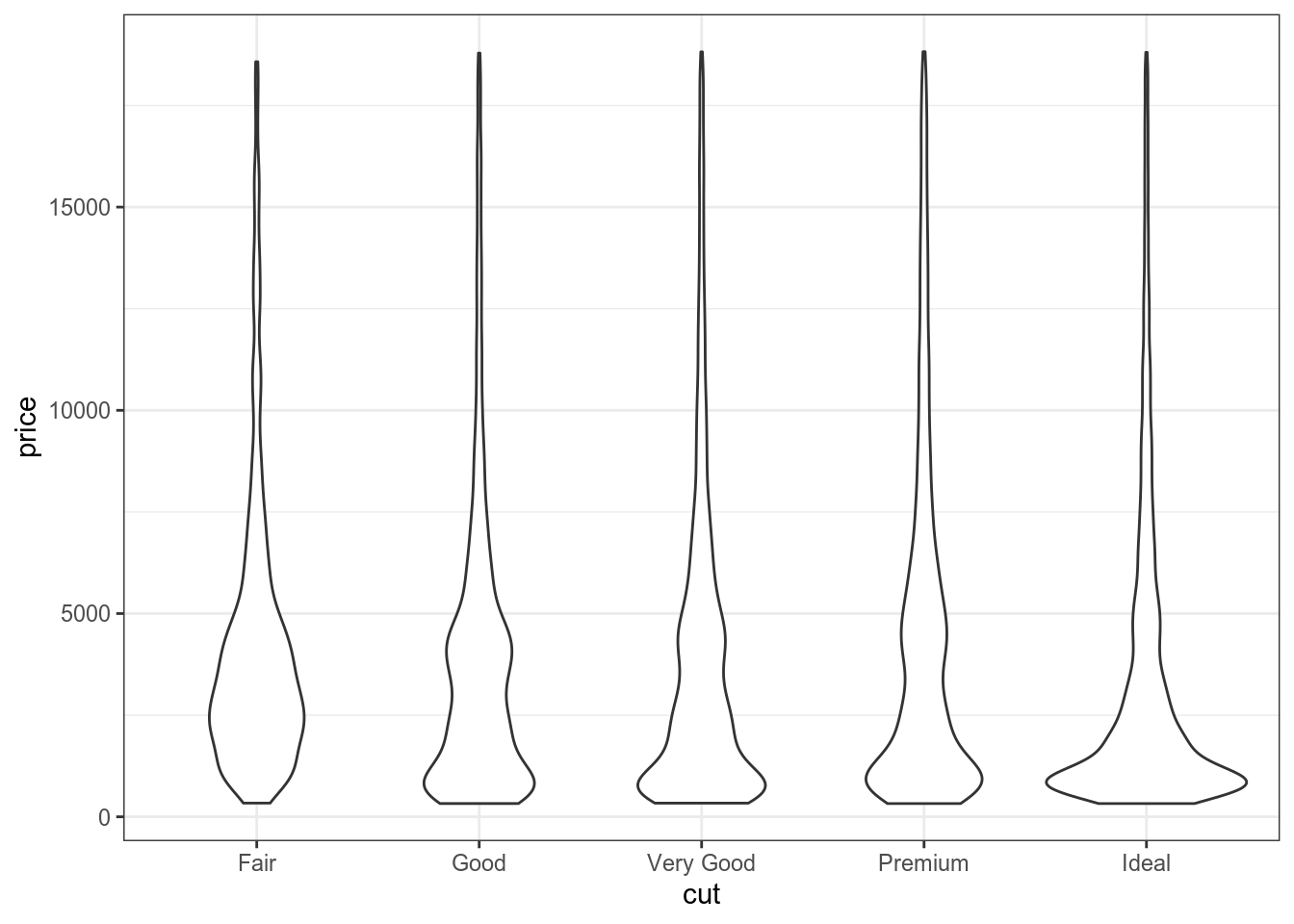
diamonds %>%
ggplot(aes(cut, price))+
geom_boxplot()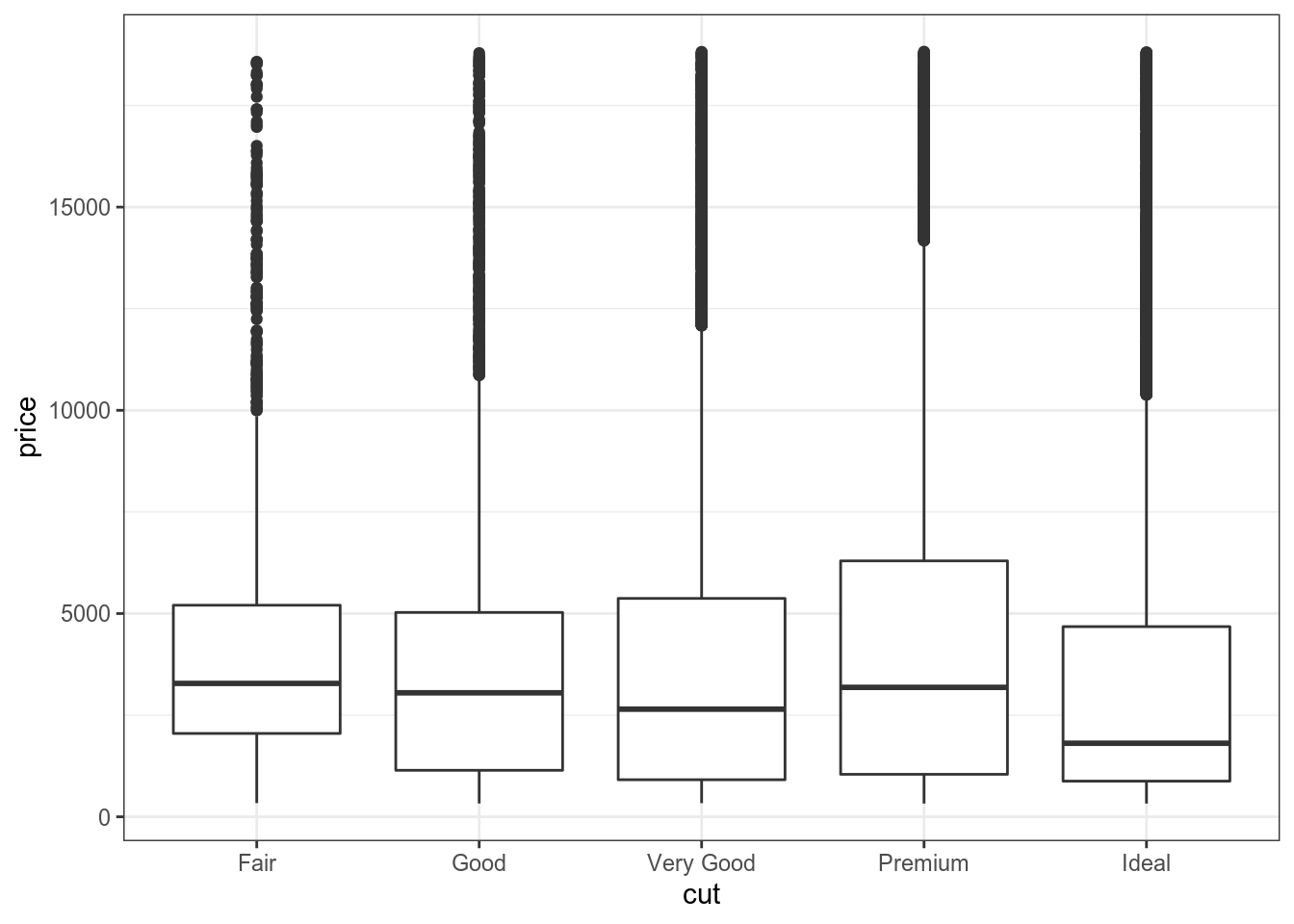

6.9 Фасетизация
Достаточно мощным инструментом анализа данных является фасетизация, которая позволяет разбивать графики на основе какой-то переменной.
diamonds %>%
ggplot(aes(carat, price))+
geom_point(size = 0.3)+
facet_wrap(~cut)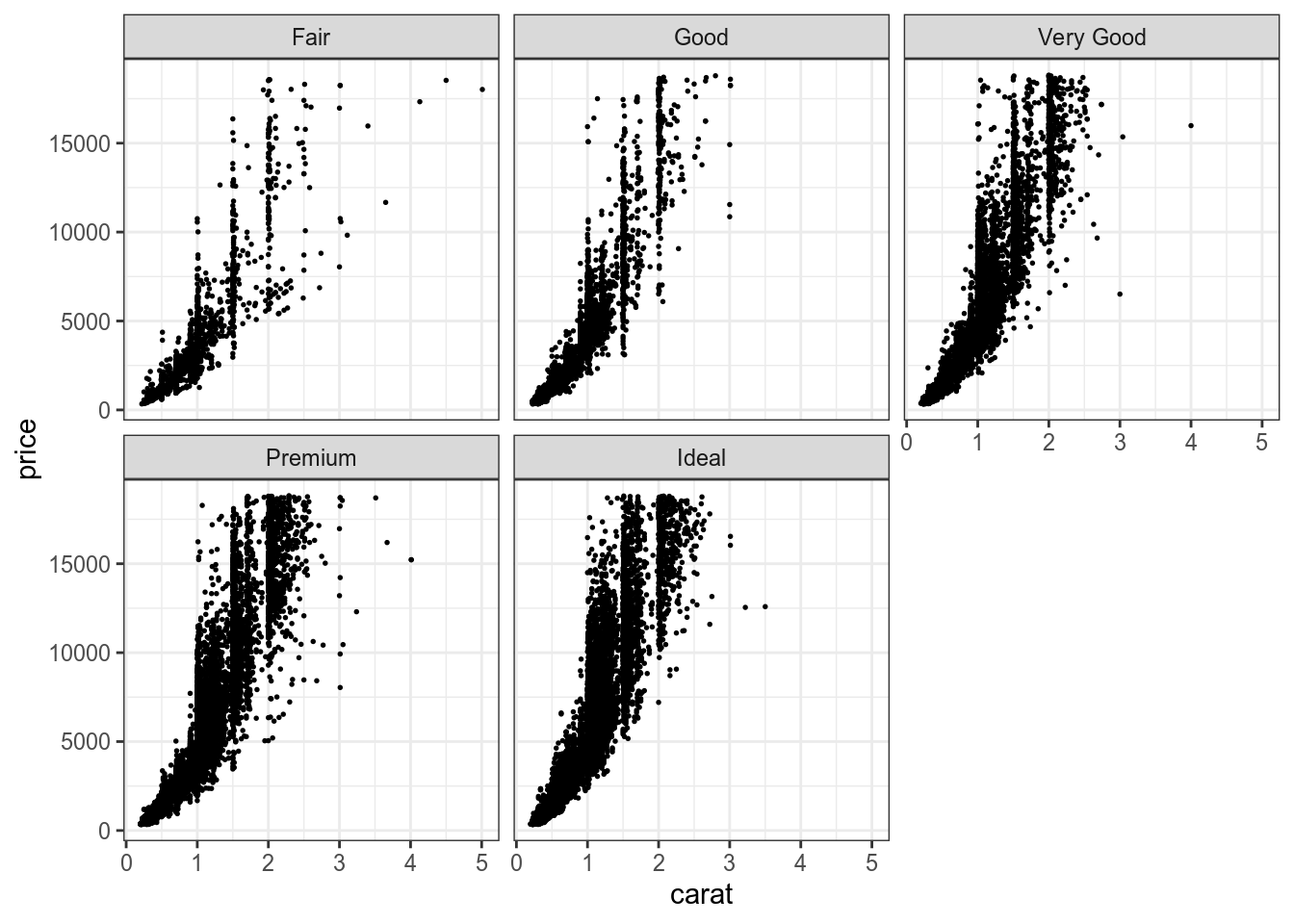 При этом иногда так бывает, что наличие какой-то одного значение в одном из фасетов, заставляет иметь одну и ту же шкалу для всех остальных. Это можно изменить при помощи аргумента
При этом иногда так бывает, что наличие какой-то одного значение в одном из фасетов, заставляет иметь одну и ту же шкалу для всех остальных. Это можно изменить при помощи аргумента scales:
diamonds %>%
ggplot(aes(carat, price))+
geom_point(size = 0.3)+
facet_wrap(~cut, scales = "free")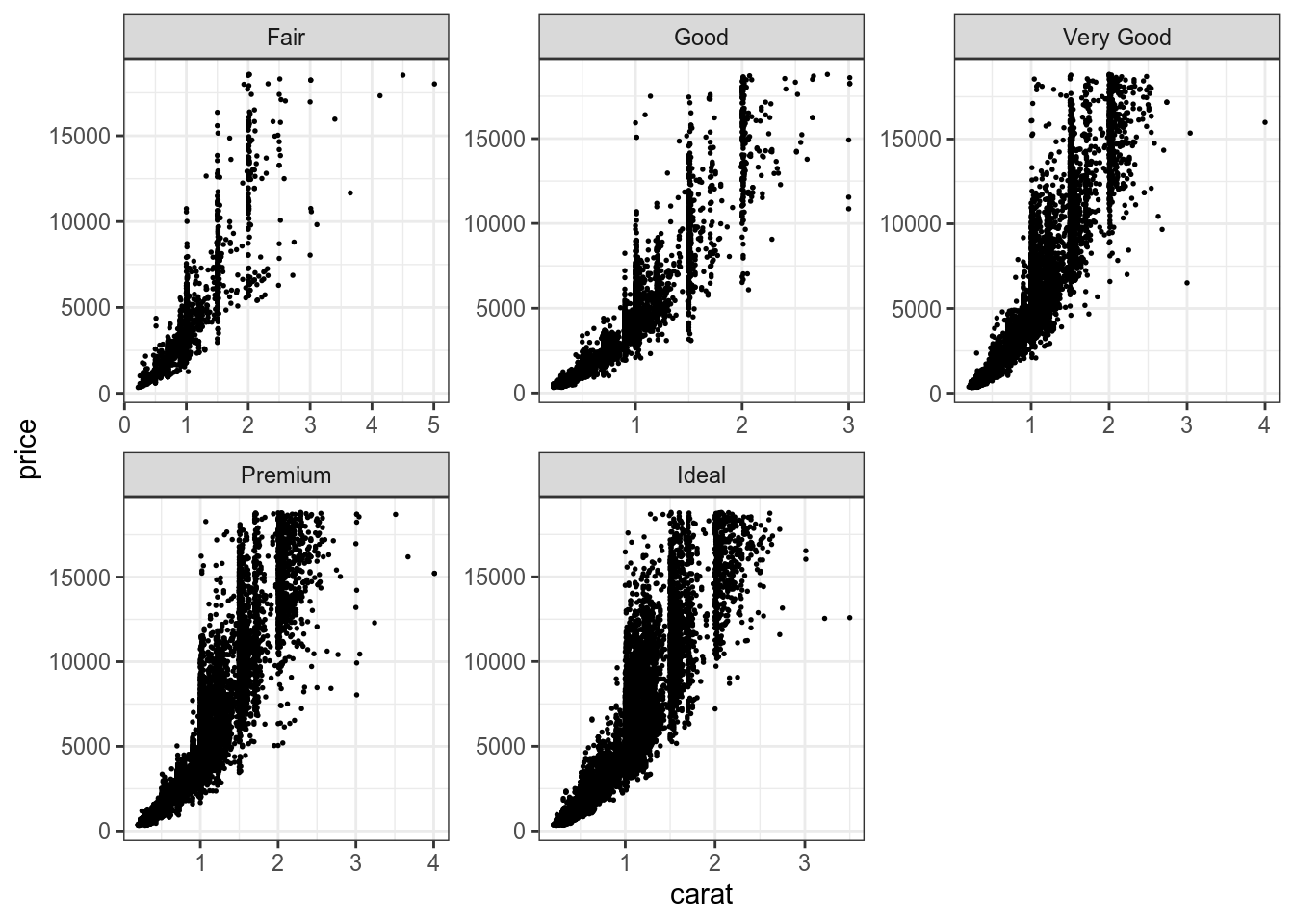
Кроме того, можно добавлять дополнительные аргументы:
diamonds %>%
ggplot(aes(carat, price))+
geom_point(size = 0.3)+
facet_wrap(~cut+color)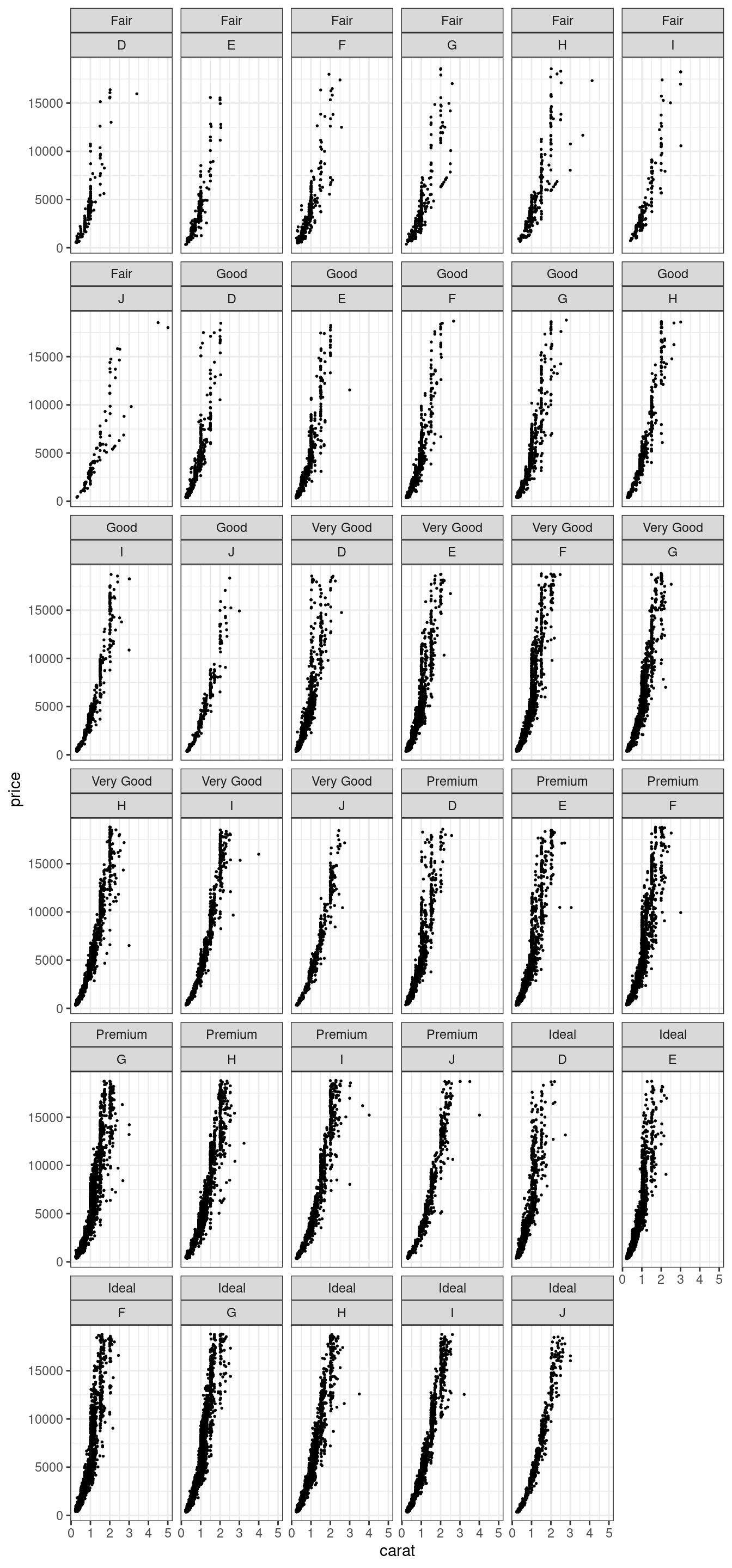
Кроме того, можно создавать сетки переменных используя geom_grid(), они facet_grid()ньше места, чем facet_wrap():
diamonds %>%
ggplot(aes(carat, price))+
geom_point(size = 0.3)+
facet_grid(cut~color, scales = "free")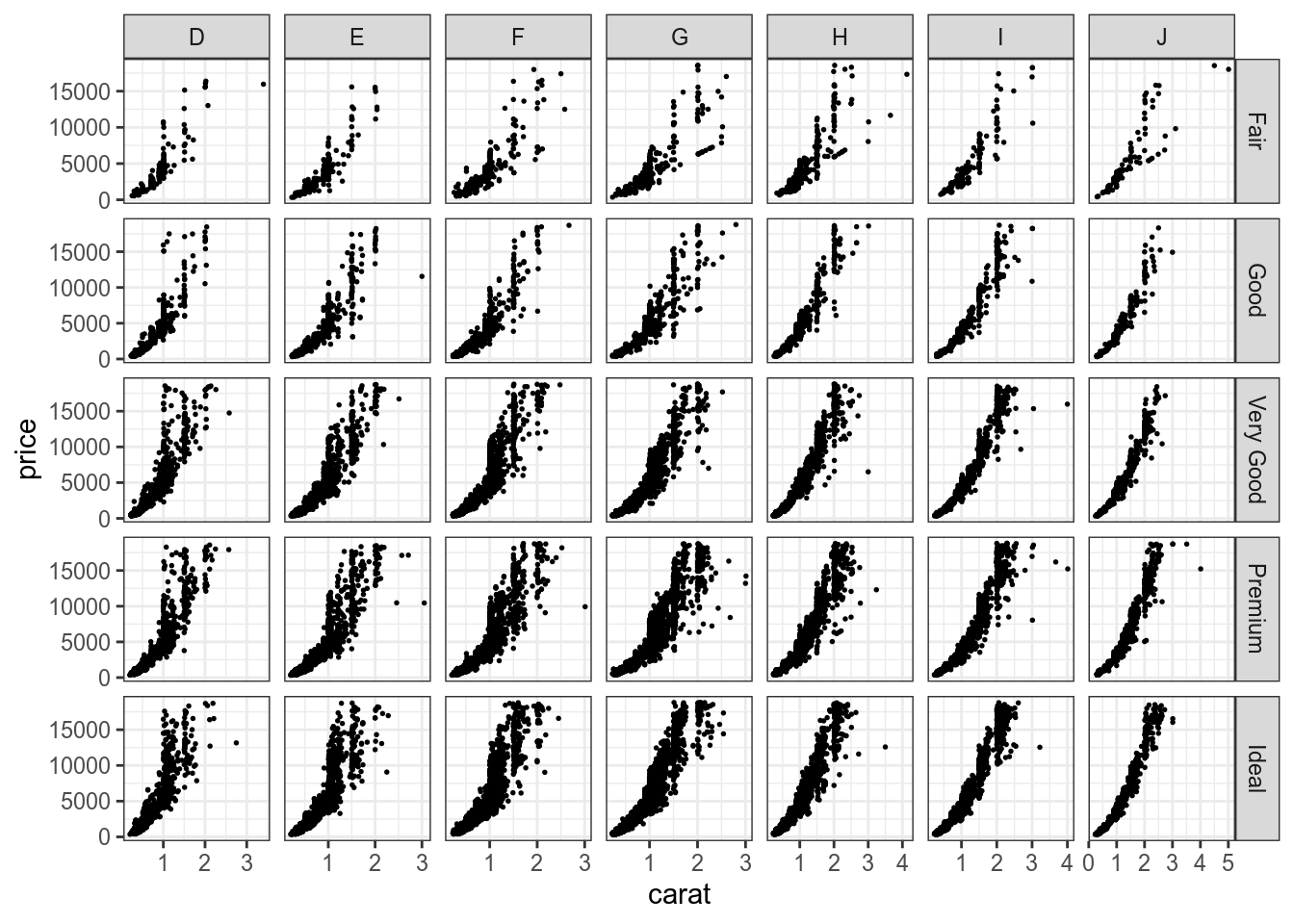
Кроме того facet_grid() позволяет делать обощающие поля, где представлены все данные по какой-то строчке или столбцу:
diamonds %>%
ggplot(aes(carat, price))+
geom_point(size = 0.3)+
facet_grid(cut~color, scales = "free", margins = TRUE)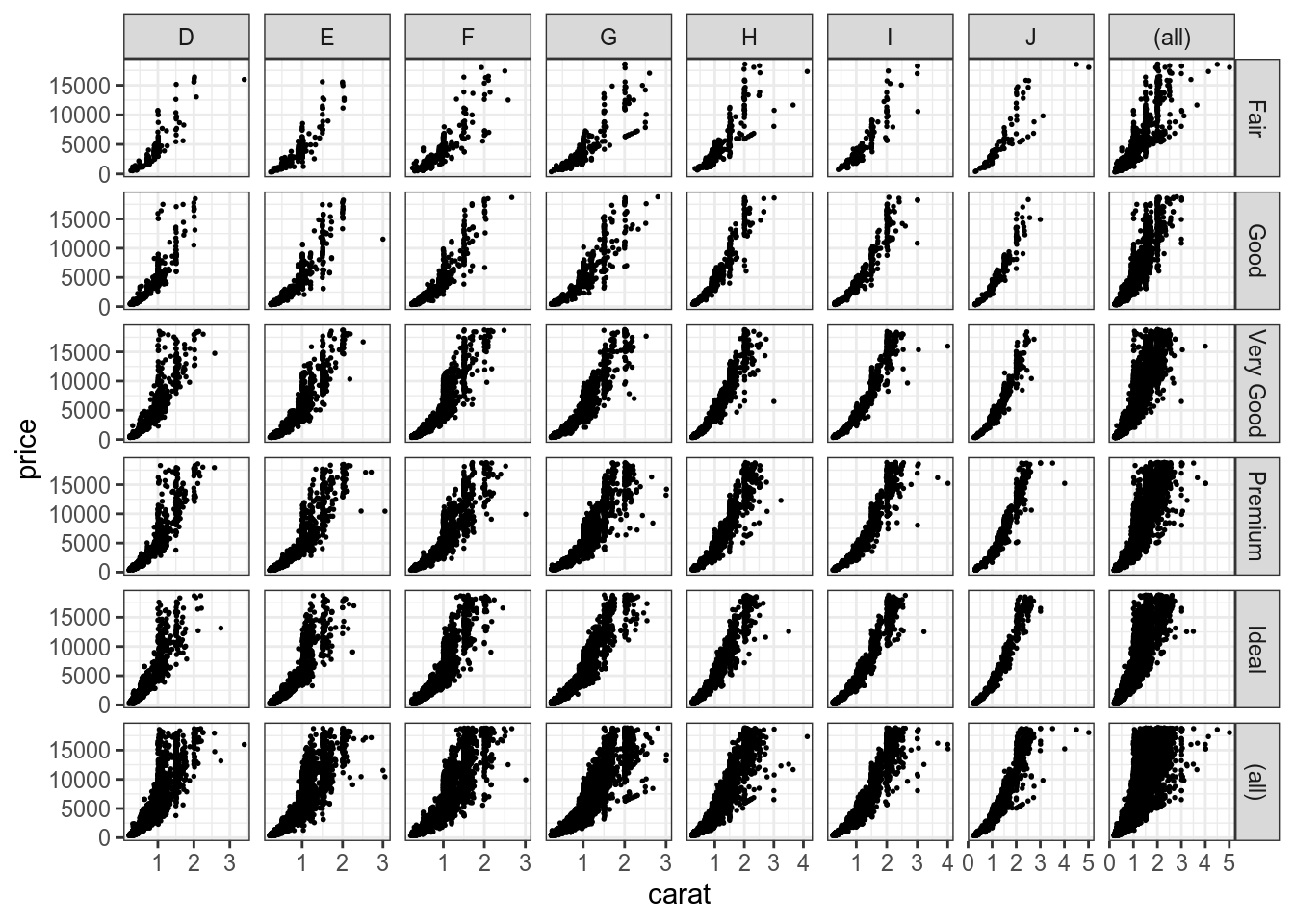
6.10 Визуализация комбинаций признаков
6.10.1 Потоковая Диаграмма (Sankey diagram)
Один из способов визуализации отношений между признаками называется потоковая диаграмма.
library("ggforce")
zhadina <- read_csv("https://raw.githubusercontent.com/agricolamz/2020-2021-ds4dh/master/data/zhadina.csv")##
## ── Column specification ────────────────────────────────────────────────────────
## cols(
## word_1 = col_character(),
## word_2 = col_character(),
## word_3 = col_character(),
## type = col_character(),
## n = col_double()
## )zhadina %>%
gather_set_data(1:3) %>%
ggplot(aes(x, id = id, split = y, value = n))+
geom_parallel_sets(aes(fill = type), alpha = 0.6, axis.width = 0.5) +
geom_parallel_sets_axes(axis.width = 0.5, color = "lightgrey", fill = "white") +
geom_parallel_sets_labels(angle = 0) +
theme_no_axes()+
theme(legend.position = "bottom")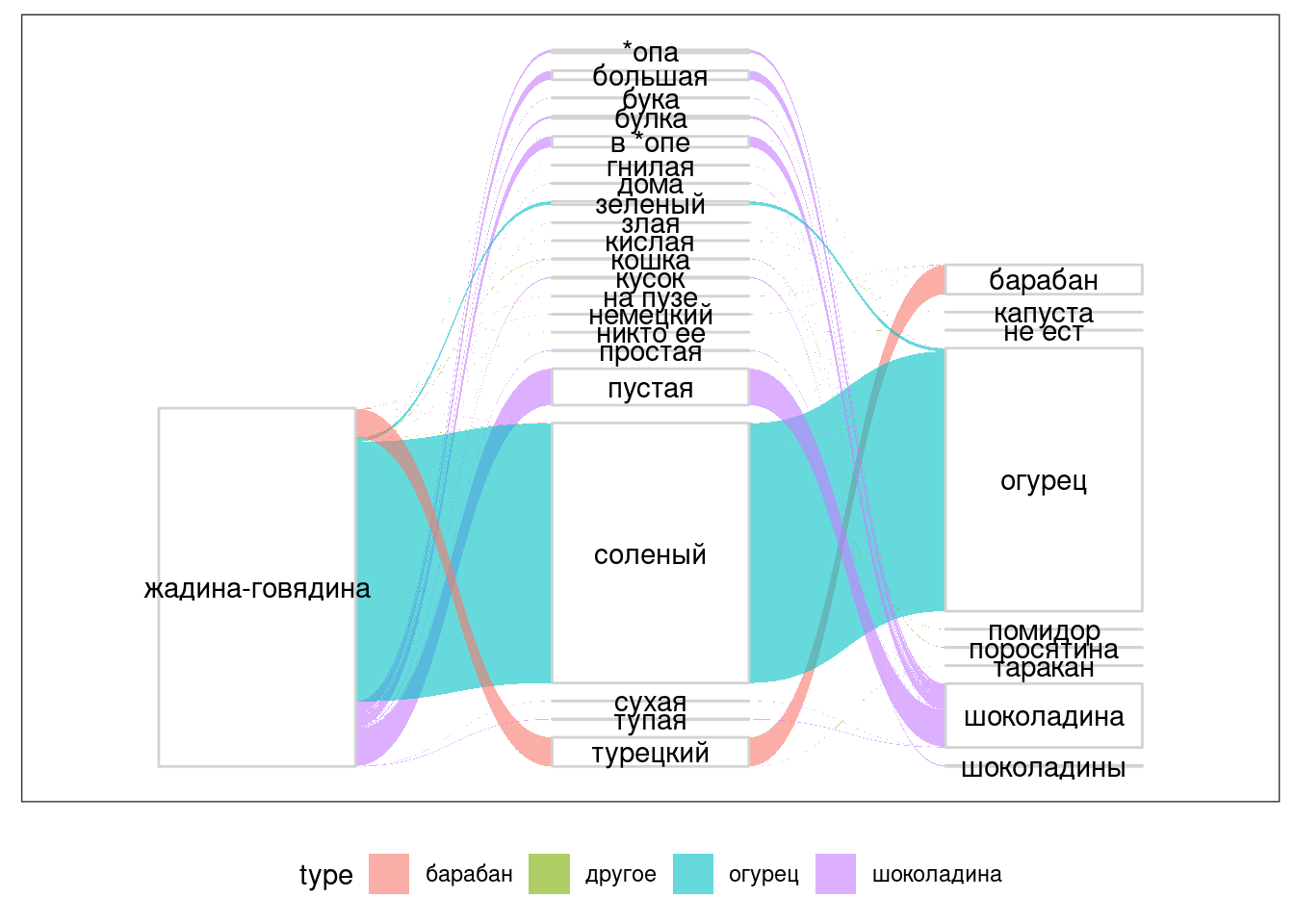
А как поменять порядок? Снова факторы.
zhadina %>%
gather_set_data(1:3) %>%
mutate(y = fct_reorder(y, n, mean)) %>%
ggplot(aes(x, id = id, split = y, value = n))+
geom_parallel_sets(aes(fill = type), alpha = 0.6, axis.width = 0.5) +
geom_parallel_sets_axes(axis.width = 0.5, color = "lightgrey", fill = "white") +
geom_parallel_sets_labels(angle = 0) +
theme_no_axes()+
theme(legend.position = "bottom")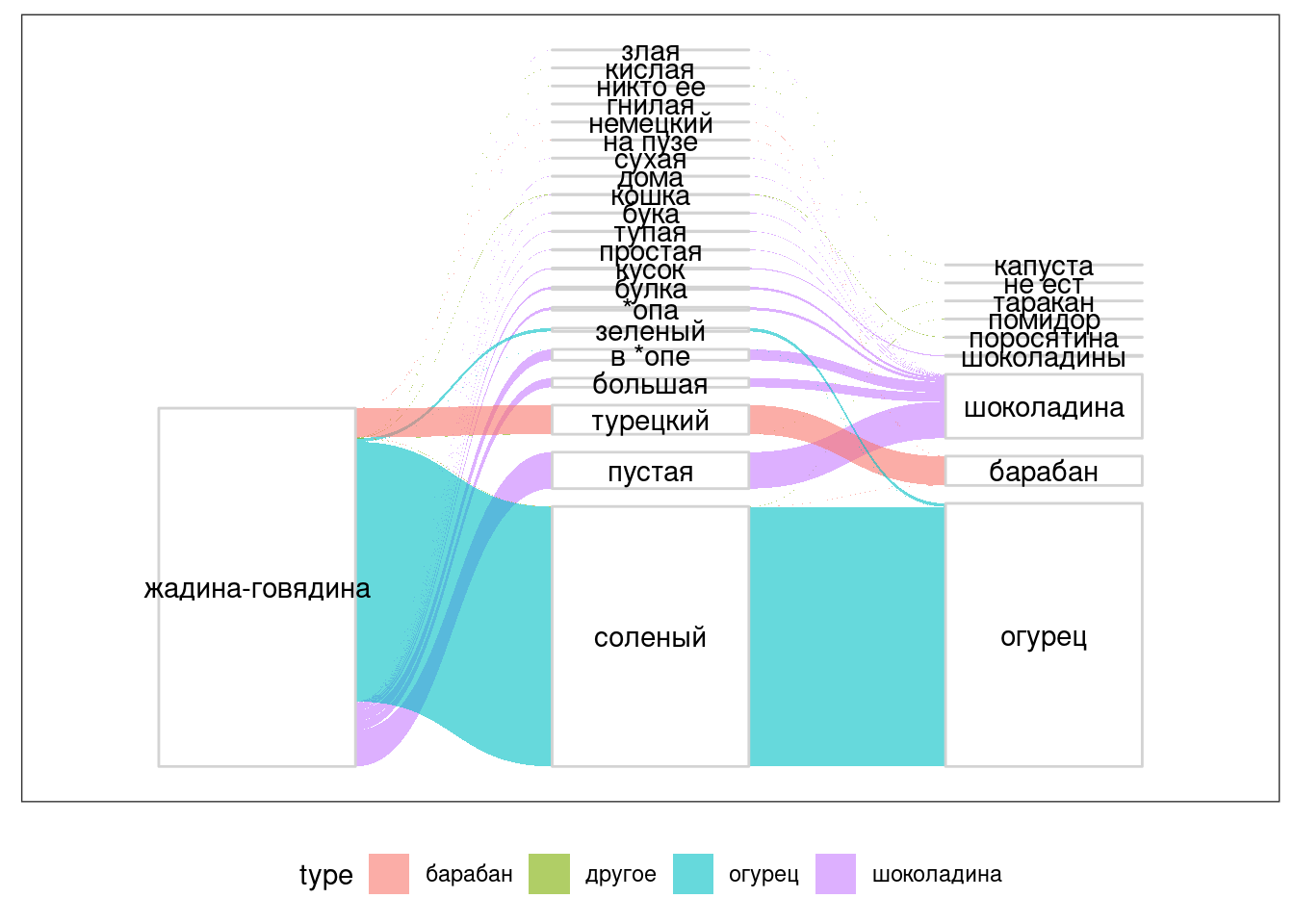
Можно донастроить, задав собственный порядок в аргументе levels функции factor().
6.10.2 UpSet Plot
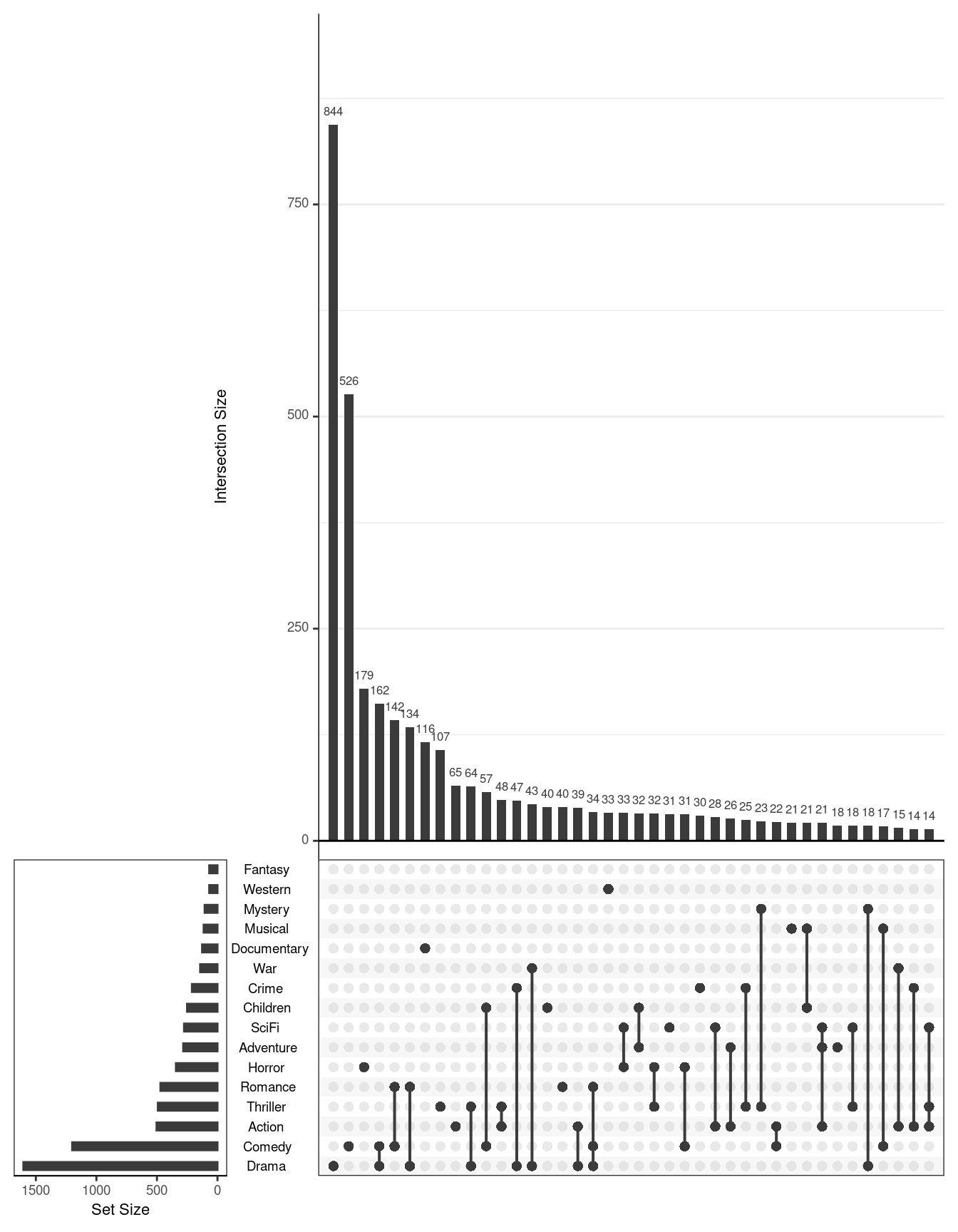
Если диаграмма Sankey визуализирует попарные отношения между переменными, то график UpSet потенциально может визуализировать все возможные комбинации и является хорошей альтернативой диаграмме Вена, с большим количеством переменных (см. эту статью Лауры Эллис).
library(UpSetR)
movies <- read.csv( system.file("extdata", "movies.csv", package = "UpSetR"), header=TRUE, sep=";" )
str(movies)## 'data.frame': 3883 obs. of 21 variables:
## $ Name : chr "Toy Story (1995)" "Jumanji (1995)" "Grumpier Old Men (1995)" "Waiting to Exhale (1995)" ...
## $ ReleaseDate: int 1995 1995 1995 1995 1995 1995 1995 1995 1995 1995 ...
## $ Action : int 0 0 0 0 0 1 0 0 1 1 ...
## $ Adventure : int 0 1 0 0 0 0 0 1 0 1 ...
## $ Children : int 1 1 0 0 0 0 0 1 0 0 ...
## $ Comedy : int 1 0 1 1 1 0 1 0 0 0 ...
## $ Crime : int 0 0 0 0 0 1 0 0 0 0 ...
## $ Documentary: int 0 0 0 0 0 0 0 0 0 0 ...
## $ Drama : int 0 0 0 1 0 0 0 0 0 0 ...
## $ Fantasy : int 0 1 0 0 0 0 0 0 0 0 ...
## $ Noir : int 0 0 0 0 0 0 0 0 0 0 ...
## $ Horror : int 0 0 0 0 0 0 0 0 0 0 ...
## $ Musical : int 0 0 0 0 0 0 0 0 0 0 ...
## $ Mystery : int 0 0 0 0 0 0 0 0 0 0 ...
## $ Romance : int 0 0 1 0 0 0 1 0 0 0 ...
## $ SciFi : int 0 0 0 0 0 0 0 0 0 0 ...
## $ Thriller : int 0 0 0 0 0 1 0 0 0 1 ...
## $ War : int 0 0 0 0 0 0 0 0 0 0 ...
## $ Western : int 0 0 0 0 0 0 0 0 0 0 ...
## $ AvgRating : num 4.15 3.2 3.02 2.73 3.01 3.88 3.41 3.01 2.66 3.54 ...
## $ Watches : int 2077 701 478 170 296 940 458 68 102 888 ...upset(movies[,3:19], nsets = 16, order.by = "freq")