8 Собственные функции и использование их в tidyverse
8.1 Напоминание: логические операции
Логическое “и”:
| & | TRUE | FALSE |
|---|---|---|
| TRUE | TRUE | FALSE |
| FALSE | FALSE | FALSE |
[1] TRUE[1] FALSEЛогическое “или”:
| | | TRUE | FALSE |
|---|---|---|
| TRUE | TRUE | TRUE |
| FALSE | TRUE | FALSE |
[1] TRUE[1] TRUEЛогическое “не”:
[1] FALSEСравнение:
[1] TRUE[1] FALSE[1] TRUE[1] FALSE TRUE8.2 Создание собственных функций
Собственные функции можно сделать с помощью функции function(). Ее можно записать в переменную и использовать:
[1] 3[1] 1Вообще, функции немного зависят от загруженных пакетов, так что безопаснее либо эксплицитно включать билиотеку внутри функции, или же говорить, из какой библиотеки функция:
Функцию можно вызывать внутри себя самой (рекурсия), вот так будет выглядеть функция, которая считает факториал:
[1] 6[1] 24[1] 40320[1] 1Напишите свою функцию, которая будет сравнивать, какое слово длиннее:
[1] "цветок"[1] "животное"[1] "воробей"8.3 Использование условий в tidyverse
8.3.1 Условия в строчках
Мы уже визуализировали данные из статьи на Pudding про английские пабы. Часть названий этих пабов имеет слово Inn, давайте построим график распределения 30 самых популярных пабов с этим словом в названии и без него. Используя известные нам инструменты можно получить что-то в этом роде:
uk_pubs <- read_csv("https://raw.githubusercontent.com/agricolamz/DS_for_DH/master/data/UK_pubs.csv")
uk_pubs %>%
count(pub_name, sort = TRUE) %>%
mutate(inn = str_detect(pub_name, "Inn")) %>%
group_by(inn) %>%
slice(1:20) %>%
ggplot(aes(fct_reorder(pub_name, n), n))+
geom_col()+
coord_flip()+
facet_wrap(~inn, scale = "free")+
labs(x = "", y = "", caption = "https://pudding.cool/2019/10/pubs/")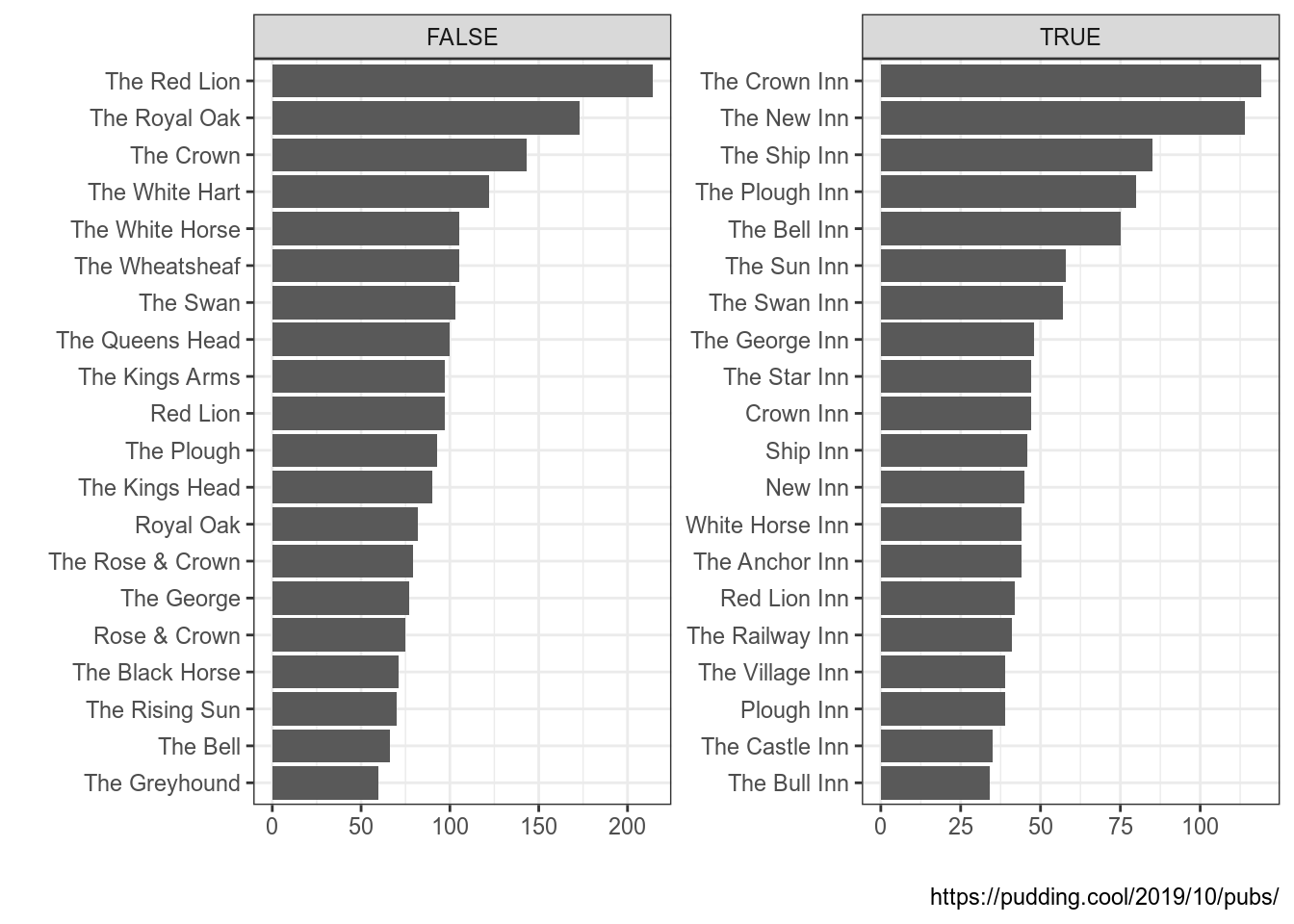
Получилось в целом то, что мы хотели, однако названия TRUE и FALSE не самые удачные. Исправить положение можно при помощи функции ifelse(), у которой три аргумента:
- условие,
- значение, если условие принимает значение
TRUE, - значение, если условие принимает значение
FALSE.
[1] "правильно"[1] "неправильно"Вставим эту функцию в уже написанные код:
uk_pubs %>%
count(pub_name, sort = TRUE) %>%
mutate(inn = ifelse(str_detect(pub_name, "Inn"),
"with 'inn'",
"without 'inn'")) %>%
group_by(inn) %>%
slice(1:20) %>%
ggplot(aes(fct_reorder(pub_name, n), n))+
geom_col()+
coord_flip()+
facet_wrap(~inn, scale = "free")+
labs(x = "", y = "", caption = "https://pudding.cool/2019/10/pubs/")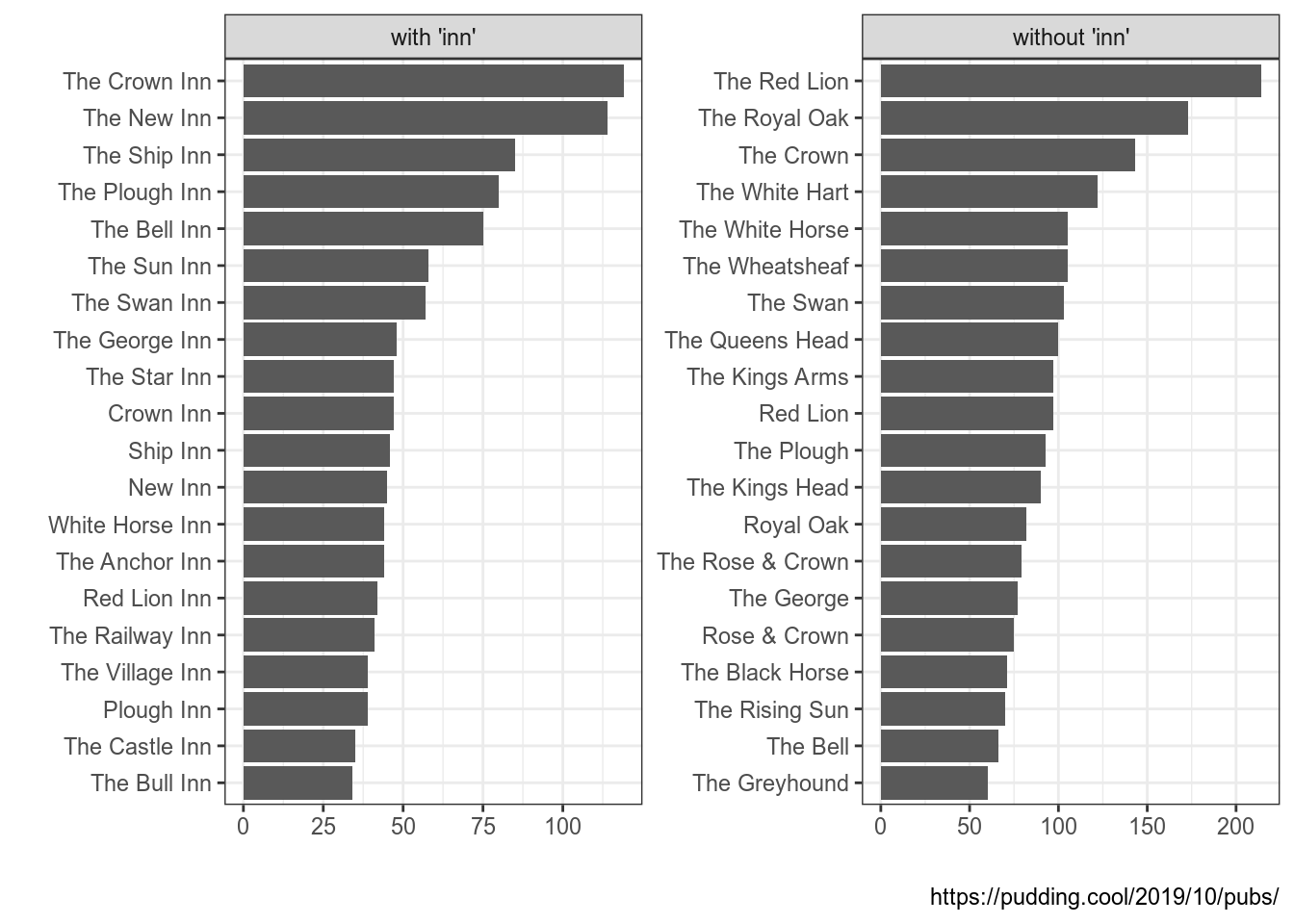
А что если условий больше? В целом, выражение ifelse() можно вложить в выражение ifelse(), однако для таких случаев придумали функцию case_when(). У нее немного необычный синтаксис:
case_when(
условие 1 ~ значение x,
условие 2 ~ значение y,
...
условие n ~ значение z
)Давайте в том же датасете посмотрим на названия со словами Inn, Hotel, Bar, House и Tavern:
uk_pubs %>%
count(pub_name, sort = TRUE) %>%
mutate(place = case_when(
str_detect(pub_name, "Inn") ~ "inn",
str_detect(pub_name, "Hotel") ~ "hotel",
str_detect(pub_name, "Bar") ~ "bar",
str_detect(pub_name, "House") ~ "house",
str_detect(pub_name, "Tavern") ~ "tavern")) %>%
group_by(place) %>%
slice(1:10) %>%
ggplot(aes(fct_reorder(pub_name, n), n))+
geom_col()+
coord_flip()+
facet_wrap(~place, scale = "free")+
labs(x = "", y = "", caption = "https://pudding.cool/2019/10/pubs/")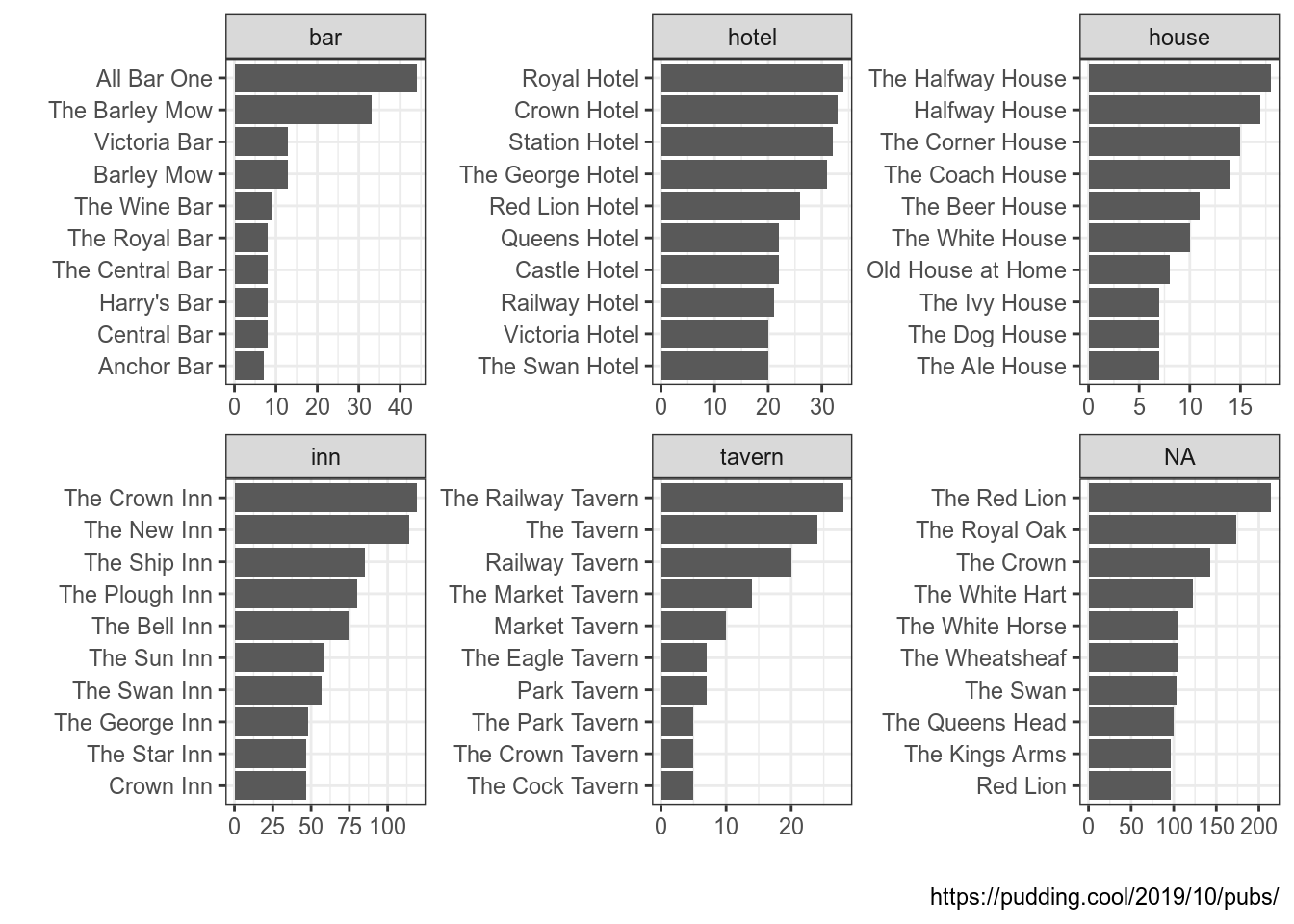
Варинат NA, как видно из графика, соответствует всем оставшимся вариантам, которые не подпали ни под одно из наших условий. Чтобы учесть и этот случай, нужно добавить условие TRUE:
uk_pubs %>%
count(pub_name, sort = TRUE) %>%
mutate(place = case_when(
str_detect(pub_name, "Inn") ~ "inn",
str_detect(pub_name, "Hotel") ~ "hotel",
str_detect(pub_name, "Bar") ~ "bar",
str_detect(pub_name, "House") ~ "house",
str_detect(pub_name, "Tavern") ~ "tavern",
TRUE ~ "other")) %>%
group_by(place) %>%
slice(1:10) %>%
ggplot(aes(fct_reorder(pub_name, n), n))+
geom_col()+
coord_flip()+
facet_wrap(~place, scale = "free")+
labs(x = "", y = "", caption = "https://pudding.cool/2019/10/pubs/")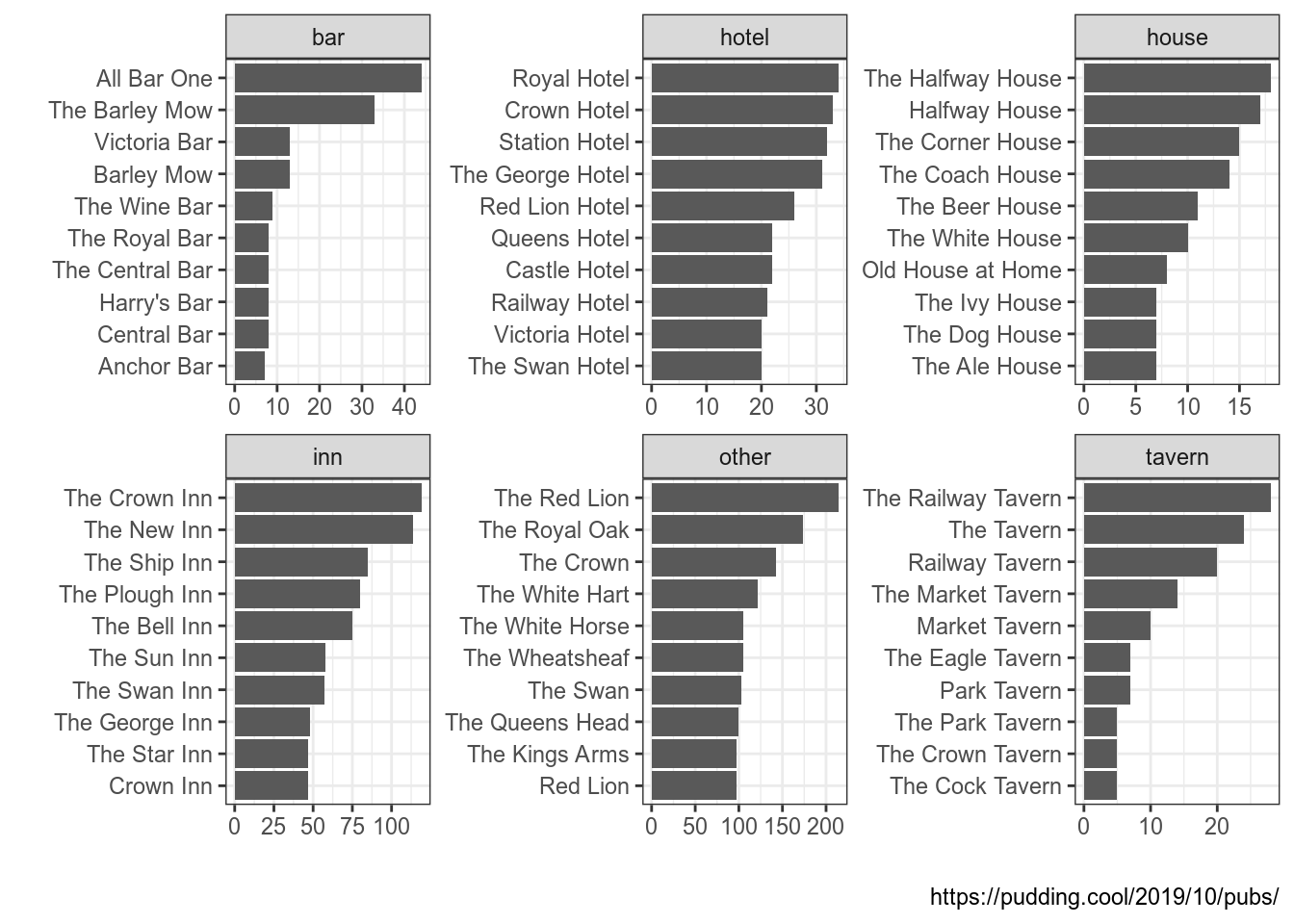
Мы уже визуализировали данные из статьи на Pudding “Finding Forever Homes”, заполните пропус, чтобы получить возростно-половую пирамиду собак в США. Когда построите приведенный график, раскомментируйте закомментированную строчку и посмотрите на результат.
dogs <- read_csv("https://raw.githubusercontent.com/r-classes/2019_2020_ds4dh_hw_2_dplyr_tidyr_ggplot2/master/data/dog_names.csv")
dogs %>%
filter(sex != "Unknown") %>%
count(sex, contact_state) %>%
group_by(contact_state) %>%
mutate(
...
) %>%
ggplot(aes(fct_reorder(contact_state, sum), n, fill = sex))+
geom_col()+
# scale_y_continuous(breaks = -2:2*1000, labels = abs(-2:2)*1000)+
coord_flip()+
labs(x = "", y = "", caption = "data from https://pudding.cool/2019/10/shelters/")+
scale_fill_brewer(palette ="Dark2")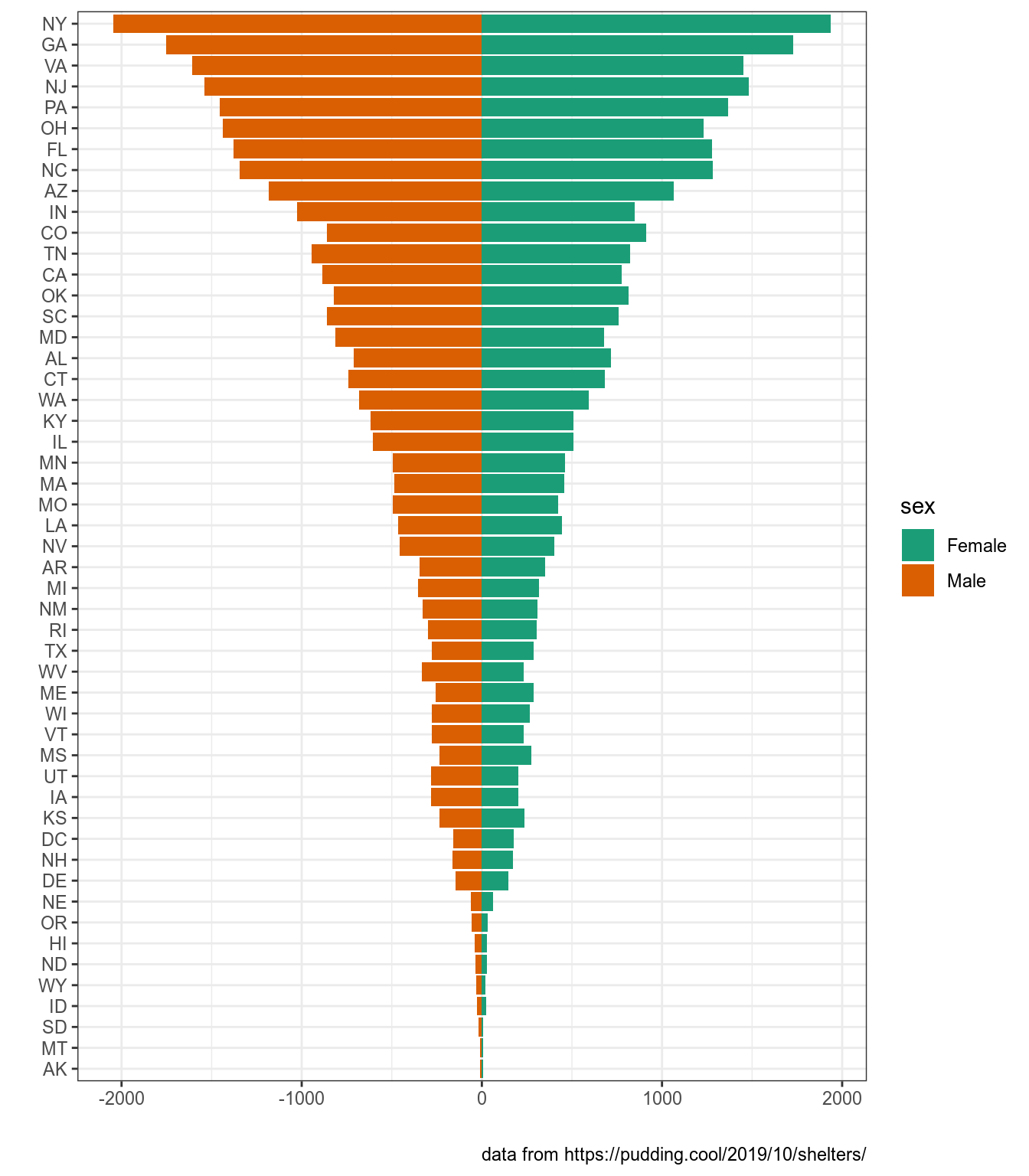
8.3.2 Условия в столбцах
Что если хочется применить summarise() или mutate() лишь к определенным колонкам? Для этого можно использовать функции summarise_at() или mutate_at().Например, посчитать среднее во всех колонках датасета iris, которые начинаются со слова “Sepal”.
На месте функции starts_with() могут быть и другие:
ends_with()– заканчивается
matches()– соответствует регулярному выражению
one_off()– из предложенного вектора значений
Так же, используя функцию summarise_if(), можно применять какую-то операцию к каждой колонке, если она соответствует какому-то условию (обычно это используют для проверки типов переменных):
Вот несколько примеров с mutate_..():
Вместо mean и sqrt может быть любая другая функция, в том числе созданная вами:
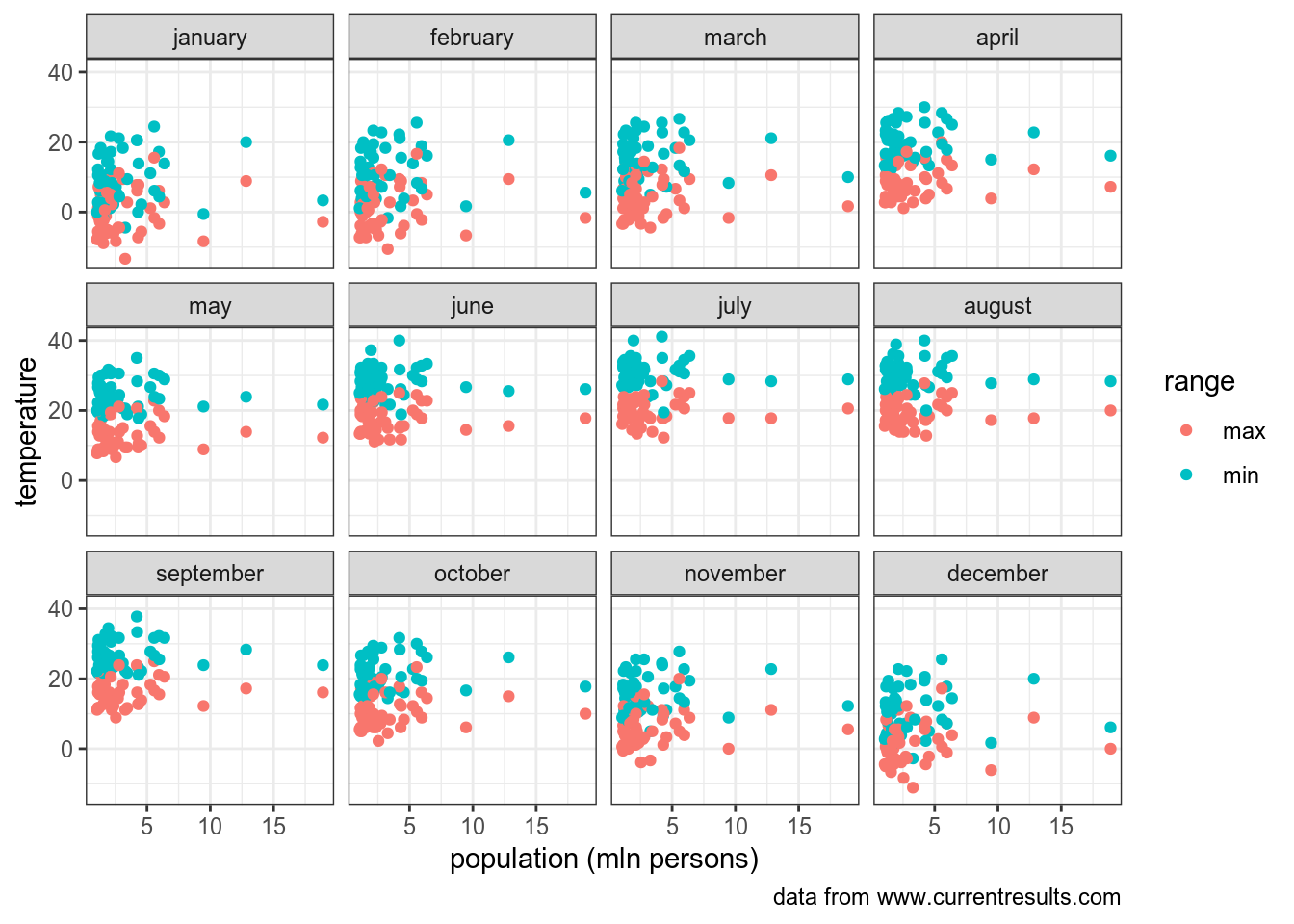
Вот здесь лежат данные по 51 американскому городу, количеству человек в них, а также ежемесячная средняя температура в Фаренгейтах. Преобразуйте фарингейты в цельсий и найдите значение минимальной температуры в датасете.
\[^0C = \frac{5}{9} \times (^0F-32)\]
8.4 Reinvent the map function
В разделе про работу со списками мы обсуждали функию map(), оказывается в нее можно вставлять любую функцию, например, пересчитаем все цены в датасете diamonds в рубли:
Можно прочитать все файлы в одной папке:
[1] "2019.01_levada_countries.csv"
[2] "anscombe.csv"
[3] "article_24_from_UDHR.csv"
[4] "character-deaths.csv"
[5] "chekhov_zoshenko.csv"
[6] "cities_of_russia.csv"
[7] "datasaurus.csv"
[8] "death_of_migrants_and_refugees_from_the_Unwelcomed_project.csv"
[9] "dialect_forms_fake.csv"
[10] "dialect_forms_repeated_fake.csv"
[11] "first_scatterplot.csv"
[12] "freq_dict_2011.csv"
[13] "gospel_freq_words.csv"
[14] "icelandic.csv"
[15] "languages_in_india.csv"
[16] "mad_questionary.csv"
[17] "misspelling_dataset.csv"
[18] "moscow_average_temperature.csv"
[19] "MVC_Russia.csv"
[20] "obamacare.csv"
[21] "perceptions_of_probability.csv"
[22] "popovets_l_2019_colors_of_classic.csv"
[23] "russian_sentiment.csv"
[24] "scary_letters.csv"
[25] "shakespeare_all.csv"
[26] "shakespeare_to_check.csv"
[27] "test_correlation_dataset.csv"
[28] "tidy_zoshenko.csv"
[29] "UK_pubs.csv"
[30] "us_city_average_temperature.csv"
[31] "visa_question.csv"
[32] "zhadina.csv"
[33] "zoshenko.csv" all_datasets <- map(str_c("data/", list.files("data/", pattern = ".csv")), read_csv)
str(all_datasets, max.level = 1)List of 33
$ : tibble [521 × 5] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. date = col_character(),
.. .. good = col_double(),
.. .. bad = col_double(),
.. .. no_answer = col_double(),
.. .. towards = col_character()
.. .. )
$ : tibble [44 × 4] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. id = col_double(),
.. .. dataset = col_double(),
.. .. x = col_double(),
.. .. y = col_double()
.. .. )
$ : tibble [6 × 1] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. article_text = col_character()
.. .. )
$ : tibble [917 × 13] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. Name = col_character(),
.. .. Allegiances = col_character(),
.. .. `Death Year` = col_double(),
.. .. `Book of Death` = col_double(),
.. .. `Death Chapter` = col_double(),
.. .. `Book Intro Chapter` = col_double(),
.. .. Gender = col_double(),
.. .. Nobility = col_double(),
.. .. GoT = col_double(),
.. .. CoK = col_double(),
.. .. SoS = col_double(),
.. .. FfC = col_double(),
.. .. DwD = col_double()
.. .. )
$ : tibble [379 × 70] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. titles = col_character(),
.. .. text_author = col_character(),
.. .. а = col_double(),
.. .. без = col_double(),
.. .. бы = col_double(),
.. .. был = col_double(),
.. .. было = col_double(),
.. .. быть = col_double(),
.. .. в = col_double(),
.. .. вам = col_double(),
.. .. вас = col_double(),
.. .. во = col_double(),
.. .. вот = col_double(),
.. .. все = col_double(),
.. .. вы = col_double(),
.. .. да = col_double(),
.. .. даже = col_double(),
.. .. для = col_double(),
.. .. до = col_double(),
.. .. его = col_double(),
.. .. ее = col_double(),
.. .. ему = col_double(),
.. .. если = col_double(),
.. .. есть = col_double(),
.. .. еще = col_double(),
.. .. же = col_double(),
.. .. за = col_double(),
.. .. и = col_double(),
.. .. из = col_double(),
.. .. или = col_double(),
.. .. к = col_double(),
.. .. как = col_double(),
.. .. когда = col_double(),
.. .. ли = col_double(),
.. .. меня = col_double(),
.. .. мне = col_double(),
.. .. мы = col_double(),
.. .. на = col_double(),
.. .. не = col_double(),
.. .. него = col_double(),
.. .. нет = col_double(),
.. .. ни = col_double(),
.. .. ничего = col_double(),
.. .. но = col_double(),
.. .. ну = col_double(),
.. .. о = col_double(),
.. .. он = col_double(),
.. .. она = col_double(),
.. .. от = col_double(),
.. .. по = col_double(),
.. .. под = col_double(),
.. .. раз = col_double(),
.. .. с = col_double(),
.. .. себе = col_double(),
.. .. себя = col_double(),
.. .. со = col_double(),
.. .. так = col_double(),
.. .. теперь = col_double(),
.. .. то = col_double(),
.. .. только = col_double(),
.. .. тут = col_double(),
.. .. ты = col_double(),
.. .. у = col_double(),
.. .. уже = col_double(),
.. .. чего = col_double(),
.. .. человек = col_double(),
.. .. чем = col_double(),
.. .. что = col_double(),
.. .. это = col_double(),
.. .. я = col_double()
.. .. )
$ : tibble [1,097 × 1] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. city = col_character()
.. .. )
$ : tibble [1,846 × 3] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. dataset = col_character(),
.. .. x = col_double(),
.. .. y = col_double()
.. .. )
$ : tibble [5,506 × 10] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. id = col_double(),
.. .. date = col_character(),
.. .. total_death_missing = col_double(),
.. .. location = col_character(),
.. .. lat = col_double(),
.. .. lon = col_double(),
.. .. collapsed_region = col_character(),
.. .. region = col_character(),
.. .. collapsed_cause = col_character(),
.. .. cause_of_death = col_character()
.. .. )
$ : tibble [319 × 2] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. form = col_character(),
.. .. gender = col_character()
.. .. )
$ : tibble [70 × 2] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. feature = col_character(),
.. .. time = col_character()
.. .. )
$ : tibble [464 × 2] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. x = col_double(),
.. .. y = col_double()
.. .. )
$ : tibble [52,138 × 1] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. `lemma pos freq_ipm` = col_character()
.. .. )
$ : tibble [472 × 5] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. word = col_character(),
.. .. John = col_double(),
.. .. Luke = col_double(),
.. .. Mark = col_double(),
.. .. Matthew = col_double()
.. .. )
$ : tibble [175 × 2] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. vowel.dur = col_double(),
.. .. aspiration = col_character()
.. .. )
$ : tibble [12 × 5] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. language = col_character(),
.. .. n_L1_sp = col_double(),
.. .. n_L2_sp = col_double(),
.. .. n_L3_sp = col_double(),
.. .. n_all_sp = col_double()
.. .. )
$ : tibble [106 × 12] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. name = col_character(),
.. .. age = col_character(),
.. .. sex = col_character(),
.. .. town_of_birth = col_character(),
.. .. phone = col_character(),
.. .. favourite_book = col_character(),
.. .. favourite_dish = col_character(),
.. .. favourite_drink = col_character(),
.. .. favourite_film = col_character(),
.. .. favourite_activity = col_character(),
.. .. frequency_be_in_the_fresh_air = col_character(),
.. .. fear_of_the_dark = col_character()
.. .. )
$ : tibble [15,477 × 3] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. correct = col_character(),
.. .. spelling = col_character(),
.. .. count = col_double()
.. .. )
$ : tibble [24 × 3] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. id = col_character(),
.. .. type = col_character(),
.. .. non_normalised = col_double()
.. .. )
$ : tibble [2,508 × 4] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. name = col_character(),
.. .. code = col_double(),
.. .. latitude = col_double(),
.. .. longitude = col_double()
.. .. )
$ : tibble [52 × 3] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. state = col_character(),
.. .. uninsured_rate_2010 = col_double(),
.. .. uninsured_rate_2015 = col_double()
.. .. )
$ : tibble [46 × 17] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. `Almost Certainly` = col_double(),
.. .. `Highly Likely` = col_double(),
.. .. `Very Good Chance` = col_double(),
.. .. Probable = col_double(),
.. .. Likely = col_double(),
.. .. Probably = col_double(),
.. .. `We Believe` = col_double(),
.. .. `Better Than Even` = col_double(),
.. .. `About Even` = col_double(),
.. .. `We Doubt` = col_double(),
.. .. Improbable = col_double(),
.. .. Unlikely = col_double(),
.. .. `Probably Not` = col_double(),
.. .. `Little Chance` = col_double(),
.. .. `Almost No Chance` = col_double(),
.. .. `Highly Unlikely` = col_double(),
.. .. `Chances Are Slight` = col_double()
.. .. )
$ : tibble [9 × 27] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. writer = col_character(),
.. .. алый = col_double(),
.. .. `багровый/багряный` = col_double(),
.. .. бежевый = col_double(),
.. .. `белый/белесый` = col_double(),
.. .. голубой = col_double(),
.. .. жёлтый = col_double(),
.. .. `зелёный/изумрудный` = col_double(),
.. .. золотой = col_double(),
.. .. карий = col_double(),
.. .. коралловый = col_double(),
.. .. `коричневый/каштановый` = col_double(),
.. .. красный = col_double(),
.. .. лазурный = col_double(),
.. .. лиловый = col_double(),
.. .. малиновый = col_double(),
.. .. `оранжевый/рыжий` = col_double(),
.. .. пурпурный = col_double(),
.. .. розовый = col_double(),
.. .. русый = col_double(),
.. .. серебристый = col_double(),
.. .. серый = col_double(),
.. .. сизый = col_double(),
.. .. синий = col_double(),
.. .. сиреневый = col_double(),
.. .. фиолетовый = col_double(),
.. .. чёрный = col_double()
.. .. )
$ : tibble [7,640 × 2] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. word = col_character(),
.. .. score = col_double()
.. .. )
$ : tibble [3 × 1] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. `cyrillic;ipa_symbols;greek` = col_character()
.. .. )
$ : tibble [138,691 × 2] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. title = col_character(),
.. .. text = col_character()
.. .. )
$ : tibble [13,861 × 4] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. title = col_character(),
.. .. words = col_character(),
.. .. n = col_double(),
.. .. n_text = col_double()
.. .. )
$ : tibble [21 × 3] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. x = col_double(),
.. .. y = col_double(),
.. .. type = col_character()
.. .. )
$ : tibble [46,658 × 1] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. `titles word n n_words` = col_character()
.. .. )
$ : tibble [41,097 × 3] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. pub_ID = col_double(),
.. .. pub_name = col_character(),
.. .. pub_town = col_character()
.. .. )
$ : tibble [51 × 26] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. city = col_character(),
.. .. population_2010 = col_double(),
.. .. min_january = col_double(),
.. .. min_february = col_double(),
.. .. min_march = col_double(),
.. .. min_april = col_double(),
.. .. min_may = col_double(),
.. .. min_june = col_double(),
.. .. min_july = col_double(),
.. .. min_august = col_double(),
.. .. min_september = col_double(),
.. .. min_october = col_double(),
.. .. min_november = col_double(),
.. .. min_december = col_double(),
.. .. max_january = col_double(),
.. .. max_february = col_double(),
.. .. max_march = col_double(),
.. .. max_april = col_double(),
.. .. max_may = col_double(),
.. .. max_june = col_double(),
.. .. max_july = col_double(),
.. .. max_august = col_double(),
.. .. max_september = col_double(),
.. .. max_october = col_double(),
.. .. max_november = col_double(),
.. .. max_december = col_double()
.. .. )
$ : tibble [8 × 2] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. from = col_character(),
.. .. to = col_character()
.. .. )
$ : tibble [26 × 5] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. word_1 = col_character(),
.. .. word_2 = col_character(),
.. .. word_3 = col_character(),
.. .. type = col_character(),
.. .. n = col_double()
.. .. )
$ : tibble [3,142 × 2] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
..- attr(*, "spec")=
.. .. cols(
.. .. text = col_character(),
.. .. title = col_character()
.. .. )Можно прочитать все листы из .xlsx файла:
[1] "2005" "2006" "2007" "2008" "2009" "2010" "2011" "2012" "2013" "2014"
[11] "2015" "2016" "2017" "2018" "2019"excel_sheets("data/seattle_public_library_checkouts.xlsx") %>%
map(~read_xlsx("data/seattle_public_library_checkouts.xlsx", .)) ->
seatle
str(seatle, max.level = 1)List of 15
$ : tibble [3,864 × 5] (S3: tbl_df/tbl/data.frame)
$ : tibble [11,197 × 5] (S3: tbl_df/tbl/data.frame)
$ : tibble [12,141 × 5] (S3: tbl_df/tbl/data.frame)
$ : tibble [15,526 × 5] (S3: tbl_df/tbl/data.frame)
$ : tibble [16,821 × 5] (S3: tbl_df/tbl/data.frame)
$ : tibble [15,046 × 5] (S3: tbl_df/tbl/data.frame)
$ : tibble [13,793 × 5] (S3: tbl_df/tbl/data.frame)
$ : tibble [13,091 × 5] (S3: tbl_df/tbl/data.frame)
$ : tibble [15,092 × 5] (S3: tbl_df/tbl/data.frame)
$ : tibble [14,197 × 5] (S3: tbl_df/tbl/data.frame)
$ : tibble [12,313 × 5] (S3: tbl_df/tbl/data.frame)
$ : tibble [10,705 × 5] (S3: tbl_df/tbl/data.frame)
$ : tibble [10,485 × 5] (S3: tbl_df/tbl/data.frame)
$ : tibble [9,593 × 5] (S3: tbl_df/tbl/data.frame)
$ : tibble [6,631 × 5] (S3: tbl_df/tbl/data.frame)Получился список, можно использовать map_df(), которая еще и соединит все в один датафрейм.
excel_sheets("data/seattle_public_library_checkouts.xlsx") %>%
map_df(~read_xlsx("data/seattle_public_library_checkouts.xlsx", .)) ->
seatle
str(seatle, max.level = 1)tibble [180,495 × 5] (S3: tbl_df/tbl/data.frame)