5 Работа со строками
5.1 Работа со строками в R
Для работы со строками можно использовать:
- базовый R
- пакет
stringr(частьtidyverse) - пакет
stringi– отдельный пакет, так что не забудьте его установить:
Мы будем пользоваться в основном пакетами stingr и stringi, так как они в большинстве случаях удобнее. К счастью функции этих пакетов легко отличить от остальных: функции пакет stringr всегда начинаются с str_, а функции пакета stringi — c stri_.
Существует cheat sheet по stringr.
5.2 Как получить строку?
- следите за кавычками
## [1] "the quick brown fox jumps over the lazy dog"## [1] "the quick brown fox jumps over the lazy dog"## [1] "the quick 'brown' fox jumps over the lazy dog"## [1] "the quick \"brown\" fox jumps over the lazy dog"- пустая строка
## [1] ""## [1] ""## [1] "" "" ""- преобразование
## [1] "integer"## [1] "4" "5" "6" "7"- встроенные векторы
## [1] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l" "m" "n" "o" "p" "q" "r" "s"
## [20] "t" "u" "v" "w" "x" "y" "z"## [1] "A" "B" "C" "D" "E" "F" "G" "H" "I" "J" "K" "L" "M" "N" "O" "P" "Q" "R" "S"
## [20] "T" "U" "V" "W" "X" "Y" "Z"## [1] "January" "February" "March" "April" "May" "June"
## [7] "July" "August" "September" "October" "November" "December"- помните, что функции
data.frame(),read.csv(),read.csv2(),read.table()из базового R всегда по-умолчанию преобразуют строки в факторы, и чтобы это предотвратить нужно использовать аргументstringsAsFactors. Это много обсуждалось в сообществе R, можно, например, почитать про это вот этот блог пост Роджера Пенга.
## 'data.frame': 5 obs. of 2 variables:
## $ letters.6.10.: chr "f" "g" "h" "i" ...
## $ LETTERS.4.8. : chr "D" "E" "F" "G" ...## 'data.frame': 5 obs. of 2 variables:
## $ letters.6.10.: chr "f" "g" "h" "i" ...
## $ LETTERS.4.8. : chr "D" "E" "F" "G" ...Но этом курсе мы учим использовать сразу tibble(), read_csv(), read_csv2(), read_tsv(), read_delim() из пакета readr (входит в tidyverse).
- Создание рандомных строк
## [1] "uwHpd" "Wj8ehS" "ivFSwy7" "TYu8zw5V"
## [5] "OuRpjoOg0" "p0CubNR2yQ" "xtdycKLOm2k" "fAGVfylZqBGp"
## [9] "gE28DTCi0NV0a" "9MemYE55If0Cvv"- Перемешивает символы внутри строки
## [1] ",цо м,пюзгу сл аиъ—в кжряд,ыщьчебэн х—штё фй"## [1] "aJayunr" "eyrbraFu" "achMr" "Aplri" "ayM" "Jnue"
## [7] "uJly" "usuAgt" "tpebermSe" "tOecrbo" "oeNembvr" "Dmceerbe"- Генерирует псевдорандомный текст1
## [1] "Lorem ipsum dolor sit amet, donec sit nunc urna sed ultricies ac pharetra orci luctus iaculis, ac tincidunt cum. Neque eu semper at sociosqu hendrerit. Eu aliquet lacus, eu hendrerit donec aliquam eros. Risus nibh, quam in sit facilisi ipsum. Amet sem sed donec sed molestie scelerisque tincidunt. Nisl donec et facilisis interdum non sed dolor purus. In ipsum dignissim torquent velit nec aliquam pellentesque. Ac, adipiscing, neque et at torquent, vestibulum ullamcorper. Ad dictumst enim velit non nulla felis habitant. Egestas placerat consectetur, dictum nostra sed nec. Erat phasellus dolor libero aliquam viverra. Vestibulum leo et. Suscipit egestas in in montes, sapien gravida? Conubia purus varius ut nec feugiat."
## [2] "Risus eleifend magnis neque diam, suspendisse ullamcorper nulla adipiscing malesuada massa, nisi sociosqu velit id et. Aliquam facilisis et aenean. Parturient vel ac in convallis, massa diam nibh. Nulla interdum cursus et. Natoque amet, ut praesent. Tortor ultrices a consectetur, augue natoque class faucibus? Ut sed arcu elementum magna. Dignissim ac facilisi quis ut nisl eu, massa."5.3 Соединение и разделение строк
Соединенить строки можно используя функцию str_c(), в которую, как и в функции с(), можно перечислять элементы через запятую:
Кроме того, если хочется, можно использовать особенный разделитель, указав его в аргументе sep:
tibble(upper = rev(LETTERS), smaller = letters) %>%
mutate(merge = str_c(upper, smaller, sep = "_"))Аналогичным образом, для разделение строки на подстроки можно использовать функцию separate(). Это функция разносит разделенные элементы строки в соответствующие столбцы. У функции три обязательных аргумента: col — колонка, которую следует разделить, into — вектор названий новых столбец, sep — разделитель.
tibble(upper = rev(LETTERS), smaller = letters) %>%
mutate(merge = str_c(upper, smaller, sep = "_")) %>%
separate(col = merge, into = c("column_1", "column_2"), sep = "_")Кроме того, есть инструмент str_split(), которая позволяет разбивать строки на подстроки, но возвращает список.
## [[1]]
## [1] "Janua" "y"
##
## [[2]]
## [1] "Feb" "ua" "y"
##
## [[3]]
## [1] "Ma" "ch"
##
## [[4]]
## [1] "Ap" "il"
##
## [[5]]
## [1] "May"
##
## [[6]]
## [1] "June"
##
## [[7]]
## [1] "July"
##
## [[8]]
## [1] "August"
##
## [[9]]
## [1] "Septembe" ""
##
## [[10]]
## [1] "Octobe" ""
##
## [[11]]
## [1] "Novembe" ""
##
## [[12]]
## [1] "Decembe" ""5.4 Количество символов
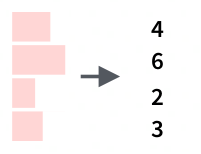
5.4.2 Подгонка количества символов
Можно обрезать строки, используя функцию str_trunc():
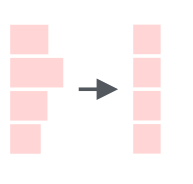
Можно решить с какой стороны обрезать, используя аргумент side:
Можно заменить многоточие, используя аргумент ellipsis:
Можно наоборот “раздуть” строку:
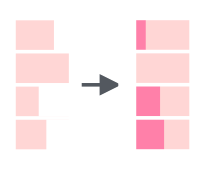
Опять же есть аргумент side:
Также можно выбрать, чем “раздувать строку”:
На Pudding вышла статья про английские пабы. Здесь лежит немного обработанный датасет, которые они использовали. Визуализируйте 40 самых частотоных названий пабов в Великобритании, отложив по оси x количество символов, а по оси y – количество баров с таким названием.
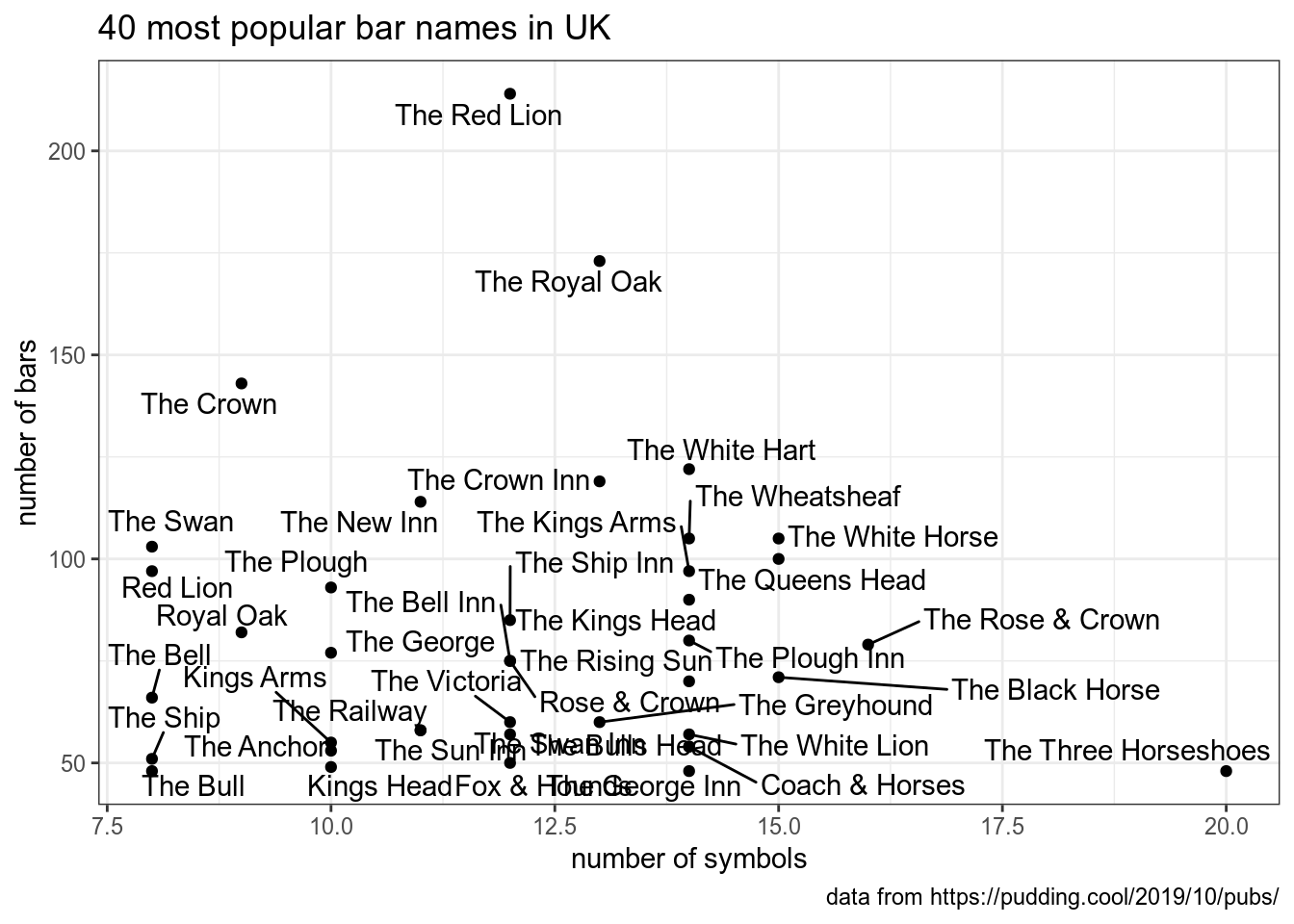
📋 список подсказок ➡
👁 Датасет скачался, что дальше? ➡
Перво-наперво следует создать переменную, в которой бы хранилось количество каждого из баров.👁 А как посчитать количество баров? ➡
Это можно сделать при помощи функцииcount(). 👁 Бары пересчитали, что дальше? ➡
Теперь нужно создать новую переменную, где бы хранилась информация о количестве символов.👁 Все переменные есть, теперь рисуем? ➡
Не совсем. Перед тем как рисовать нужно отфильтровать 50 самых популярных. 👁 Так, все готово, а какие geom_()? ➡
На графике geom_point() и geom_text_repel() из пакета ggrepel. 👁 А-а-а-а! could not find function "geom_text_repel" ➡
А вы включили библиотеку ggrepel? Если не включили, то функция, естественно будет недоступна. 👁 А-а-а-а! geom_text_repel requires the following missing aesthetics: label" ➡
Все, как написала программа: чтобы писать какой-то текст в функции aes() нужно добавить аргумент label = pub_name. Иначе откуда он узнает, что ему писать? 👁 Фуф! Все готово! ➡
А оси подписаны? А заголовок? А подпись про источник данных?5.5 Сортировка
Для сортировки существует базовая функция sort() и функция из stringr str_sort():
## [1] "♥" "I" "N" "Y"## [1] "♥" "I" "N" "Y"## [1] "♥" "I" "Y" "N"## [1] "i" "ж" "я"## [1] "ж" "я" "i"Список локалей на копмьютере можно посмотреть командой stringi::stri_locale_list(). Список всех локалей вообще приведен на этой странице. Еще полезные команды: stringi::stri_locale_info и stringi::stri_locale_set.
Не углубляясь в разнообразие алгоритмов сортировки, отмечу, что алгоритм по-умолчанию хуже работает с большими данными:
## [1] "q" "e" "a" "y" "j" "d"## user system elapsed
## 7.359 0.024 7.383## user system elapsed
## 0.330 0.028 0.358## user system elapsed
## 6.566 0.072 6.679## user system elapsed
## 3.404 0.064 3.468Предварительный вывод: для больших данных – sort(..., method = "radix").
5.6 Поиск подстроки
Можно использовать функцию str_detect():
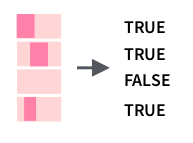
Кроме того, существует функция, которая возвращает индексы, а не значения TRUE/FALSE:
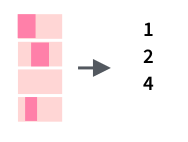
Также можно посчитать количество вхождений какой-то подстроки:
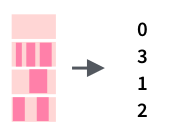
5.7 Изменение строк
5.7.1 Изменение регистра
latin <- "tHe QuIcK BrOwN fOx JuMpS OvEr ThE lAzY dOg"
cyrillic <- "лЮбЯ, сЪеШь ЩиПцЫ, — вЗдОхНёТ мЭр, — кАйФ жГуЧ"
str_to_upper(latin)## [1] "THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG"## [1] "любя, съешь щипцы, — вздохнёт мэр, — кайф жгуч"## [1] "The Quick Brown Fox Jumps Over The Lazy Dog"5.7.2 Выделение подстроки
Подстроку в строке можно выделить двумя способами: по индексам функцией str_sub(), и по подстроке функцией str_png().
extract(images/5.07_str_sub.png)
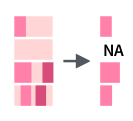
По умолчанию функция str_extract() возвращает первое вхождение подстроки, соответствующей шаблону. Также существует функция str_extract_all(), которая возвращает все вхождения подстрок, соответствующих шаблону, однако возвращает объект типа список.
## [[1]]
## [1] "r"
##
## [[2]]
## [1] "r" "r"
##
## [[3]]
## [1] "r"
##
## [[4]]
## [1] "r"
##
## [[5]]
## character(0)
##
## [[6]]
## character(0)
##
## [[7]]
## character(0)
##
## [[8]]
## character(0)
##
## [[9]]
## [1] "r"
##
## [[10]]
## [1] "r"
##
## [[11]]
## [1] "r"
##
## [[12]]
## [1] "r"5.7.3 Замена подстроки
Существует функция str_replace(), которая позволяет заменить одну подстроку в строке на другую:
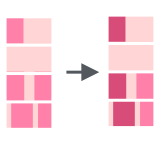
Как и другие функции str_replace() делает лишь одну замену, чтобы заменить все вхождения подстроки следует использовать функцию str_replace_all():
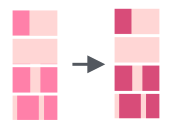
5.7.4 Удаление подстроки
Для удаления подстроки на основе шаблона, используется функция str_remove() и str_remove_all()
5.7.5 Транслитерация строк
В пакете stringi сууществует достаточно много методов транслитераций строк, которые можно вывести командой stri_trans_list(). Вот пример использования некоторых из них:
## [1] "стринги"## [1] "syrniki"## [1] "στριγγι"## [1] "ստրինգի"Вот два датасета:
Определите сколько городов называется обычным словом русского языка (например, город Орёл)? Не забудьте поменять ё на е.
📋 список подсказок ➡
👁 Датасеты скачались, что дальше? ➡
Надо их преобразовать к нужному виду и объединить.👁 А как их соединить? Что у них общего? ➡
В одном датасете есть переменная
city, в другом – переменная lemma. Все города начинаются с большой буквы, все леммы с маленькой буквы. Я бы уменьшил букву в датасете с городами, сделал бы новый столбец в датасете с городами (например, town), соединил бы датасеты и посчитал бы сколько в результирующем датасете значений town.
👁 А как соеднить? ➡
Я бы использовалdict %>% ... %>% inner_join(cities). Если в датасетах разные названия столбцов, то следует указывать какие столбцы, каким соответствуют:dict %>% ... %>% inner_join(cities, by = c("lemma" = "city"))
👁 Соединилось вроде… А как посчитать? ➡
Я бы, как обычно, использовал функциюcount().
5.8 Регулярные выражения
Большинство функций из раздела об операциях над векторами (str_detect(), str_extract(), str_remove() и т. п.) имеют следующую структуру:
- строка, с которой работает функция
- образец (pattern)
Дальше мы будем использовать функцию str_view_all(), которая позволяет показывать, выделенное образцом в исходной строке.
5.8.1 Экранирование метасимволов
5.8.2 Классы знаков
\\d– цифры.\\D– не цифры.
\\s– пробелы.\\S– не пробелы.
\\w– не пробелы и не знаки препинания.\\W– пробелы и знаки препинания.
- произвольная группа символов и обратная к ней
- встроенные группы символов

- выбор из нескольких групп
- произвольный символ
str_view_all("Везет Сенька Саньку с Сонькой на санках. Санки скок, Сеньку с ног, Соньку в лоб, все — в сугроб", "[Сс].н")- знак начала и конца строки
- есть еще другие группы и другие обозначения уже приведенных групп, см.
?regex

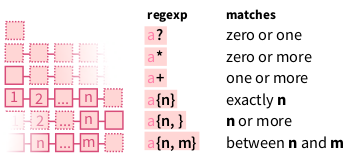
5.8.3 Квантификация
?– ноль или один раз
*– ноль и более раз
+– один и более раз
{n}–nраз
{n,}–nраз и более
{n,m}– отnдоm. Отсутствие пробела важно:{1,2}– правильно,{1,␣2}– неправильно.
- группировка символов
- жадный vs. нежадный алоритмы
5.8.4 Позиционная проверка (look arounds)
Позиционная проверка – выглядит достаточно непоследовательно даже в свете остальных регулярных выражений.
Давайте найдем все а перед р:
А теперь все а перед р или л:
Давайте найдем все а после р
А теперь все а после р или л:
Также у этих выражений есть формы с отрицанием. Давайте найдем все р не перед а:
А теперь все р не после а:
Запомнить с ходу это достаточно сложно, так что подсматривайте сюда:
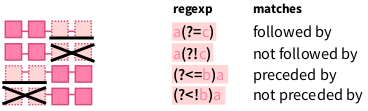
Вот отсюда можно скачать файл с текстом стихотворения Н. Заболоцкого “Меркнут знаки задиака”. Посчитайте долю женских (ударение падает на предпоследний слог рифмующихся слов) и мужских (ударение падает на последний слог рифмующихся слов) рифм в стихотворении.
📋 список подсказок ➡
👁 Датасеты скачивается с ошибкой, почему? ➡
Дело в том, что исходный файл в формате.txt, а не .csv. Его нужно скачивать, например, командой read_lines() 👁 Ошибка: ...applied to an object of class "character" ➡
Скачав файл Вы получили вектор со строками, где каждая элимент вектора – строка стихотворения. Создайте
tibble(), тогда можно будет применять стандартные инструменты tidyverse.
👁 Хорошо, tibble() создан, что дальше? ➡
Дальше нужно создать переменную, из которой будет понятно, мужская в каждой строке рифма, или женская.
👁 А как определить, какая рифма? Нужно с словарем сравнивать? ➡
Формально говоря, определять рифму можно по косвенным признакам. Все стихотворение написано четырехстопным хореем, значит в нем либо 7, либо 8 слогов. Значит, посчитав количество слогов, мы поймем, какая перед нами рифма.👁 А как посчитать гласные? ➡
Нужно написать регулярное выражение… вроде бы это тема нашего занятия…👁 Гласные посчитаны. А что дальше? ➡
Ну теперь нужно посчитать, сколько каких длин (в количестве слогов) бывает в стихотворении. Это можно сделать при помощи функцииcount().
👁 А почему у меня есть строки длины 0 слогов ➡
Ну, видимо, в стихотворении были пустые строки. Они использовались для разделения строф.👁 А почему у меня есть строки длины 6 слогов ➡
Ну, видимо, Вы написали регулярное выражение, которое не учитывает, что гласные буквы могут быть еще и в начале строки, а значит написаны с большой буквы.
В ходе анализа данных чаще всего бороться со строками и регулярными выражениями приходится в процессе обработки неаккуратнособранных анкет. Предлагаю обработать переменные sex и age такой вот неудачно собранной анкеты и построить следующий график:
📋 список подсказок ➡
👁 А что это за geom_...()? ➡
Это geom_dotplot() с аргументом method = "histodot" и с удаленной осью y при помощи команды scale_y_continuous(NULL, breaks = NULL)
👁 Почему на графике рисутеся каждое значение возраста? ➡
Если Вы все правильно преобразовали, должно помочь преобразование строковой переменной age в числовую при помощи функции as.integer().5.9 Определение языка
Для определения языка существует два пакета cld2 (вероятностный) и cld3 (нейросеть).
udhr_24 <- read_csv("https://raw.githubusercontent.com/agricolamz/DS_for_DH/master/data/article_24_from_UDHR.csv")## Parsed with column specification:
## cols(
## article_text = col_character()
## )## [1] "ru" "en" "fr" "es" "ar" "zh"## [1] "RUSSIAN" "ENGLISH" "FRENCH" "SPANISH" "ARABIC" "CHINESE"## [1] "ru" "en" "fr" "es" "ar" "zh"## [1] "bg"## [1] NAcld2::detect_language("Варкалось. Хливкие шорьки пырялись по наве, и хрюкотали зелюки, как мюмзики в мове.")## [1] "ru"cld3::detect_language("Варкалось. Хливкие шорьки пырялись по наве, и хрюкотали зелюки, как мюмзики в мове.")## [1] "ru"cld2::detect_language("Варчилось… Хлив'язкі тхурки викрули, свербчись навкрузі, жасумновілі худоки гривіли зехряки в чузі.")## [1] "uk"cld3::detect_language("Варчилось… Хлив'язкі тхурки викрули, свербчись навкрузі, жасумновілі худоки гривіли зехряки в чузі.")## [1] "uk"cld2::detect_language_mixed("Многие в нашей команде OpenDataScience занимаются state-of-the-art технологиями машинного обучения: DL-фреймворками, байесовскими методами машинного обучения, вероятностным программированием и не только.")## $classificaton
## language code latin proportion
## 1 RUSSIAN ru FALSE 0.87
## 2 ENGLISH en TRUE 0.11
## 3 UNKNOWN un TRUE 0.00
##
## $bytes
## [1] 353
##
## $reliabale
## [1] TRUEcld3::detect_language_mixed("Многие в нашей команде OpenDataScience занимаются state-of-the-art технологиями машинного обучения: DL-фреймворками, байесовскими методами машинного обучения, вероятностным программированием и не только.")5.10 Расстояния между строками
Существует много разных метрик для измерения расстояния между строками (см. ?`stringdist-metrics`), в примерах используется расстояние Дамерау — Левенштейна. Данное расстояние получается при подсчете количества операций, которые нужно сделать, чтобы перевести одну строку в другую.
- вставка ab → aNb
- удаление aOb → ab
- замена символа aOb → aNb
- перестановка символов ab → ba
##
## Attaching package: 'stringdist'## The following object is masked from 'package:tidyr':
##
## extract## [1] 0## [1] 4 6 6 1 5## [1] 2 4Lorem ipsum — классический текст-заполнитель на основе трактата Марка Туллия Цицерона “О пределах добра и зла”. Его используют, чтобы посмотреть, как страница смотриться, когда заполнена текстом↩︎