3 tidyverse: Загрузка и трансформация данных
tidyverse — это набор пакетов:
- ggplot2, для визуализации
- tibble, для работы с тибблами, современный вариант датафрейма
- tidyr, для формата tidy data
- readr, для чтения файлов в R
- purrr, для функционального программирования
- dplyr, для преобразованиия данных
- stringr, для работы со строковыми переменными
- forcats, для работы с переменными-факторами
Полезно также знать о следующих:
- readxl, для чтения .xls и .xlsx
- jsonlite, для работы с JSON
- rvest, для веб-скреппинга
- lubridate, для работы с временем
- tidytext, для работы с текстами и корпусами
- broom, для перевода в tidy формат статистические модели
## ── Attaching packages ──────────────────── tidyverse 1.3.0 ──## ✓ ggplot2 3.3.2 ✓ purrr 0.3.4
## ✓ tibble 3.0.3 ✓ dplyr 1.0.2
## ✓ tidyr 1.1.2 ✓ stringr 1.4.0
## ✓ readr 1.3.1 ✓ forcats 0.5.0## ── Conflicts ─────────────────────── tidyverse_conflicts() ──
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()3.1 Загрузка данных
3.1.1 Рабочая директория
Все в R происходит где-то. Нужно загружать файлы с данными, нужно их куда-то сохранять. Желательно иметь для каждого проекта некоторую отдельную папку на компьютере, куда складывать все, отнсящееся к этому проекту. Две команды позволят опредить текущую рабочую дерикторию (getwd()) и (setwd(.../path/to/your/directory)).
3.1.2 Форматы данных: .csv
Существет много форматов данных, которые придумали люди. Большинство из них можно загрузить в R. Так как центральный объект в R – таблица \(n \times k\), то и работать мы большую часть времени будем с таблицами. Наиболее распространенные способы хранить данные сейчас это .csv (разберем в данном разделе) и .json (разберем в разделе (???){lists}).
.csv (comma separated values) – является обычным текстовым файлом, в котором перечислены значения с некоторым фиксированным разделителем: запятой, табуляцией, точка с запятой, пробел и др. Такие файлы обычно легко открывает LibreOffice, а в Microsoft Excel нужны некоторые трюки.
3.1.3 Загрузка данных: readr, readxl
Стандартной функцией для чтения .csv файлов в R является функция read.csv(), но мы будем использовать функцию read_csv() из пакета readr.
Вместо многоточия может стоять:
- название файла (если он, есть в текущей рабочей дериктории)
- относительный путь к файлу (если он, верен для текущей рабочей дериктории)
- полный путь к файлу (если он, верен для текущей рабочей дериктории)
- интернет ссылка (тогда, компьютер должен быть подключен к интернету)
Для чтения других форматов .csv файлов используются другие функции:
read_tsv()– для файлов с табуляцией в качестве разделителяread_csv2()– для файлов с точкой с запятой в качестве разделителяread_delim(file = "...", delim = "...")– для файлов с любым разделителем, задаваемым аргументомdelim
Стандартной практикой является создавать первой строкой .csv файлов названия столбцов, поэтому по умолчанию функции read_...() будут создавать таблицу, считая первую строку названием столбцов. Чтобы изменить это поведение следует использовать аргумент col_names = FALSE.
Другая проблема при чтении файлов – кодировка и локаль. На разных компьютерах разные локали и дефолтные кодировки, так что имеет смысл знать про аргумент locale(encoding = "UTF-8").
Попробуйте корректно считать в R файл по этой ссылке.
Благодаря readxl пакету Также данные можно скачать напрямую из файлов .xls (функция read_xls) и .xlsx (функция read_xlsx), однако эти функции не умеют читать из интернета.
Существует еще один экстравагантный способ хранить данные: это формат файлов R .RData. Создадим data.frame:
Теперь можно сохранить файл…
удалить переменную…
## Error in eval(expr, envir, enclos): object 'my_df' not foundи загрузить все снова:
3.1.3.1 Misspelling dataset
Этот датасет я переработал из данных, собранных для статьи The Gyllenhaal Experiment, написанной Расселом Гольденбергом и Мэттом Дэниэлсом для издания pudding. Они анализировали ошибки в правописании при поиске имен и фамилий звезд.
misspellings <- read_csv("https://raw.githubusercontent.com/agricolamz/DS_for_DH/master/data/misspelling_dataset.csv")## Parsed with column specification:
## cols(
## correct = col_character(),
## spelling = col_character(),
## count = col_double()
## )В датасете следующие переменные:
correct– корректное написание фамилииspelling– написание, которое сделали пользователиcount– количество случаев такого написания
3.2 tibble
Пакет tibble – является альтернативой штатного датафрейма в R. Существует встроенная переменная month.name:
## [1] "January" "February" "March" "April" "May" "June"
## [7] "July" "August" "September" "October" "November" "December"Можно создать датафрейм таким образом:
## Error in nchar(months): cannot coerce type 'closure' to vector of type 'character'Однако переменная months не создана пользователем, так что данный код выдает ошибку. Корректный способ сделать это базовыми средствами:
Одно из отличий tibble от базового датафрейма – возможность использовать создаваемые “по ходу пьесы переменные”
Если в окружении пользователя уже есть переменная с датафреймом, его легко можно переделать в tibble при помощи функции as_tibble():
Функицонально tibble от data.frame ничем не отличается, однако существует ряд несущественных отличий. Кроме того стоит помнить, что многие функции из tidyverse возвращают именно tibble, а не data.frame.
3.3 dplyr
В сжатом виде содержание этого раздела хранится вот здесь или здесь.
3.3.1 dplyr::filter()
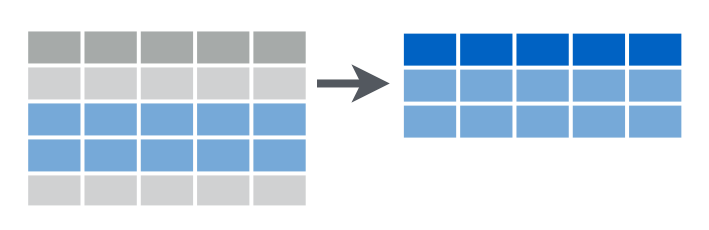
Эта функция фильтрует строчки по условиям, основанным на столбцах.
Сколько неправильных произношений, которые написали меньше 10 юзеров?
%>% — конвеер (pipe) отправляет результат работы одной функции в другую.
## [1] 0.9999951 0.9952926 0.9946649 0.9805088 0.9792468 0.9554817 0.9535709
## [8] 0.9173173 0.9146888 0.8699440 0.8665952 0.8105471 0.8064043 0.7375779
## [15] 0.7325114 0.6482029 0.6419646 0.5365662 0.5285977 0.3871398 0.3756594
## [22] 0.0940814## [1] 0.9999951 0.9952926 0.9946649 0.9805088 0.9792468 0.9554817 0.9535709
## [8] 0.9173173 0.9146888 0.8699440 0.8665952 0.8105471 0.8064043 0.7375779
## [15] 0.7325114 0.6482029 0.6419646 0.5365662 0.5285977 0.3871398 0.3756594
## [22] 0.0940814Конвееры в tidyverse пришли из пакета magrittr. Иногда они работают не корректно с функциями не из tidyverse.

3.3.3 dplyr::select()
Эта функция позволяет выбрать столбцы.
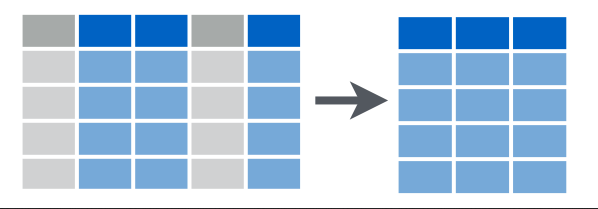
3.3.4 dplyr::arrange()
Эта функция сортирует (строки по алфавиту, а числа по порядку).
3.3.5 dplyr::distinct()
Эта функция возращает уникальные значения в столбце или комбинации столбцов.
Во встроенном в tidyverse датасете starwars отфильтруйте существ выше 180 (height) и весом меньше 80 (mass) и выведите уникальные значений мест, откуда они происходят (homeworld).
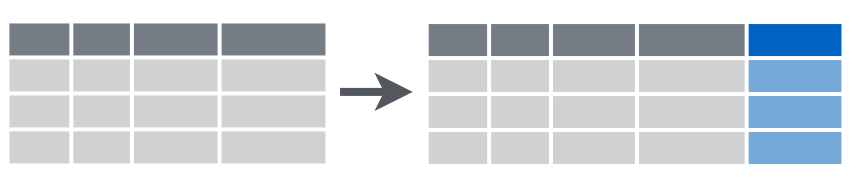
3.3.6 dplyr::mutate()
Эта функция позволяет создать новые переменные.
starwars. Сколько героев страдают ожирением (т. е. имеют индекс массы тела больше 30)? (Не забудьте перевести рост из сантиметров в метры).
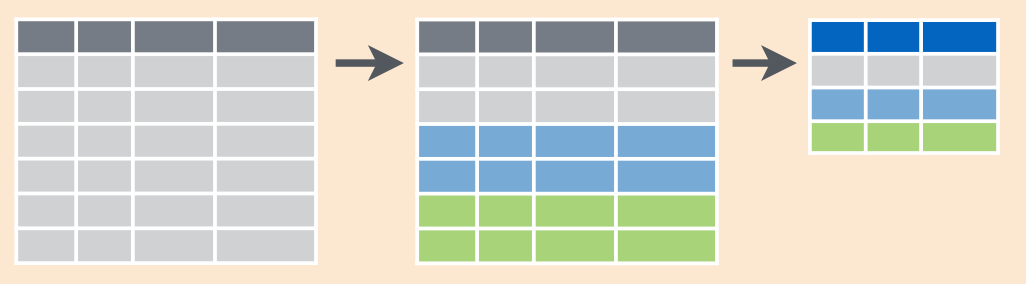
3.3.7 dplyr::group_by(...) %>% summarise(...)
Эта функция позволяет сгруппировать переменные по какому-то из столбцов и получить какой-нибудь вывод из описательной статистики (максимум, минимум, последний, первый, среднее, медиану и т. п.).
## `summarise()` ungrouping output (override with `.groups` argument)## `summarise()` ungrouping output (override with `.groups` argument)Если нужно посчитать количество вхождений, то можно использовать функцию n() в summarise() или же функцию count():
## `summarise()` ungrouping output (override with `.groups` argument)
А что будет, если в датасете misspellings создать переменную n и зоставить отсортировать по переменным correct и n?
Можно даже отсортировать результат:
Если вы хотите создать не какое-то саммари, а целый дополнительный столбец с этим саммари вместо функции summarise() нужно использовать функцию mutate():
Схематически это выглядит так:
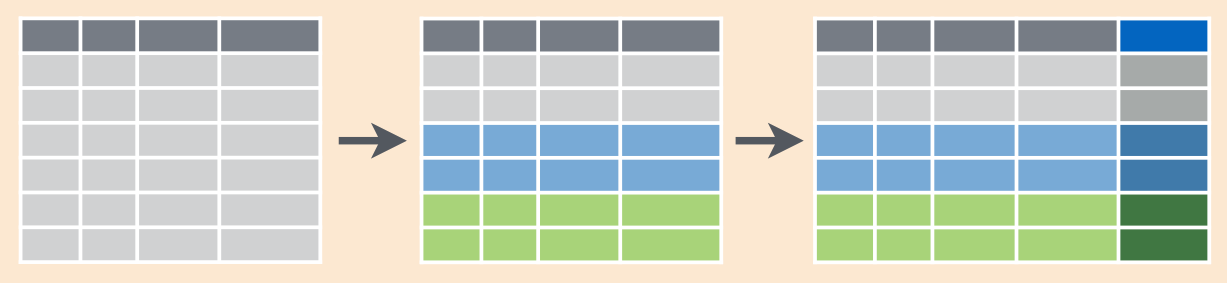
В датасете starwars запишите в отдельную переменную среднее значение роста (height) по каждой расе (species).
3.4 Соединение датафреймов
3.4.1 bind_...
Это семейство функций позволяет соединять разные датафреймы:
Чтобы соединить строчки датафреймов с одинаковым набором колонок:
Вместо отсутствующих колонок появятся NA:
Чтобы соединить строчки датафреймов с одинаковым набором строчек (если названия столбцов будут пересекаться, то они будут пронумерованы):
## New names:
## * a -> a...1
## * b -> b...2
## * a -> a...3
## * b -> b...4Соединяя датафреймы с разным количеством строк
## Error: Can't recycle `..1` (size 3) to match `..2` (size 2).3.4.2 dplyr::.._join()
Эти функции позволяют соединять датафреймы.
languages <- data_frame(
languages = c("Selkup", "French", "Chukchi", "Polish"),
countries = c("Russia", "France", "Russia", "Poland"),
iso = c("sel", "fra", "ckt", "pol")
)## Warning: `data_frame()` is deprecated as of tibble 1.1.0.
## Please use `tibble()` instead.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_warnings()` to see where this warning was generated.country_population <- data_frame(
countries = c("Russia", "Poland", "Finland"),
population_mln = c(143, 38, 5))
country_population## Joining, by = "countries"## Joining, by = "countries"## Joining, by = "countries"## Joining, by = "countries"## Joining, by = "countries"## Joining, by = "countries"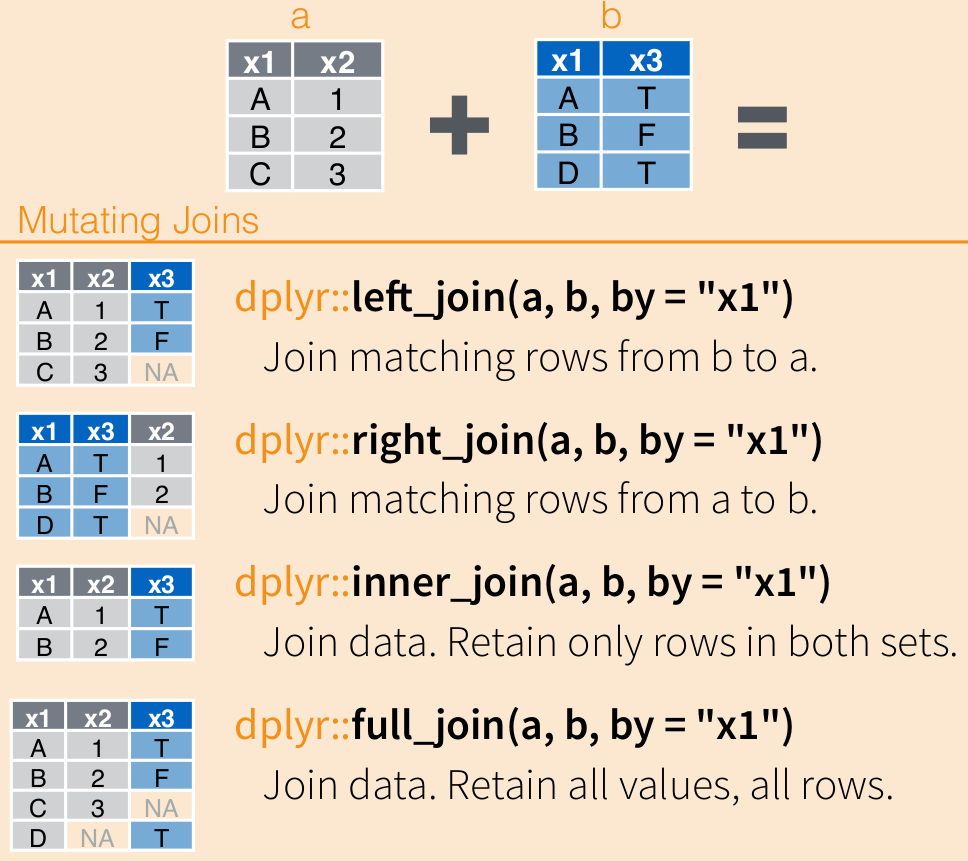
3.5 tidyr package
Давайте посмотрим на датасет с количеством носителей разных языков в Индии согласно переписи 2001 года (данные из Википедии):
langs_in_india_short <- read_csv("https://raw.githubusercontent.com/agricolamz/DS_for_DH/master/data/languages_in_india.csv")## Parsed with column specification:
## cols(
## language = col_character(),
## n_L1_sp = col_double(),
## n_L2_sp = col_double(),
## n_L3_sp = col_double(),
## n_all_sp = col_double()
## )- Short format
- Long format
- Short format → Long format:
tidyr::pivot_longer()
langs_in_india_short %>%
pivot_longer(names_to = "type", values_to = "n_speakers", n_L1_sp:n_all_sp)->
langs_in_india_long
langs_in_india_long- Long format → Short format:
tidyr::pivot_wider()
langs_in_india_long %>%
pivot_wider(names_from = "type", values_from = "n_speakers")->
langs_in_india_short
langs_in_india_short
Вот здесь лежит датасет, который содержит информацию о селах в Дагестане в формате .xlsx. Данные разделены по разным листам и содержат следующие переменные (данные получены из разных источников, поэтому имеют суффикс _s1 – первый источник и _s2 – второй источник):
-
id_s1– (s1) идентификационный номер из первого источника; -
name_1885– (s1) название селения из переписи 1885 -
census_1885– (s1) число людей из переписи 1885 -
name_1895– (s1) название селения из переписи 1895 -
census_1895– (s1) число людей из переписи 1895 -
name_1926– (s1) название селения из переписи 1926 -
language_s1– (s1) язык данного селения согласно первому источнику -
census_1926– (s1) число людей из переписи 1926 -
name_2010– (s1) название селения из переписи 2010 -
census_2010– (s1) число людей из переписи 2010 -
name_s2– (s2) название селения согласно второму источнику -
language_s2– (s2) язык данного селения согласно первому источнику -
Lat– (s2) широта селения -
Lon– (s2) долгота селения -
elevation– (s2) высота селения над уровнем моря
Во-первых, объедините все листы .xlsx воедино:
Во-вторых, посчитайте, относительно скольких селений первый и второй источник согласуются относительно языка селения.
В-третьих, посчитайте среднюю высоту над уровнем моря для языков из первого источника. Какой выше всех?
В-четвертых, посчитайте количество населения, которое говорило на каждом из языков из второго датасета, согласно каждой переписи. Приведите значения для лакского языка (Lak).
3.6 Полезные надстройки
Существует достаточно много пакетов надстроек для tidyverse.
tidylog– делает лог пайпов:
##
## Attaching package: 'tidylog'## The following objects are masked from 'package:dplyr':
##
## add_count, add_tally, anti_join, count, distinct, distinct_all,
## distinct_at, distinct_if, filter, filter_all, filter_at, filter_if,
## full_join, group_by, group_by_all, group_by_at, group_by_if,
## inner_join, left_join, mutate, mutate_all, mutate_at, mutate_if,
## relocate, rename, rename_all, rename_at, rename_if, rename_with,
## right_join, sample_frac, sample_n, select, select_all, select_at,
## select_if, semi_join, slice, slice_head, slice_max, slice_min,
## slice_sample, slice_tail, summarise, summarise_all, summarise_at,
## summarise_if, summarize, summarize_all, summarize_at, summarize_if,
## tally, top_frac, top_n, transmute, transmute_all, transmute_at,
## transmute_if, ungroup## The following objects are masked from 'package:tidyr':
##
## drop_na, fill, gather, pivot_longer, pivot_wider, replace_na,
## spread, uncount## The following object is masked from 'package:stats':
##
## filtermtcars %>%
group_by(cyl, gear) %>%
summarise(mean_mpg = mean(mpg)) %>%
pivot_wider(names_from = gear, values_from = mean_mpg)## group_by: 2 grouping variables (cyl, gear)## summarise: now 8 rows and 3 columns, one group variable remaining (cyl)## pivot_wider: reorganized (gear, mean_mpg) into (3, 4, 5) [was 8x3, now 3x4]dtplyr– позволяет вызывать функцииdplyr, но используяdata.tableвнутри. Это полезно для работы с большими датасетами.sparklyr– связывает R с Apache Spark (инструмент для кластерных вычислений)…